python代码学习——递归函数
python代码学习——递归函数
- 函数的调用
- 变量名解析(查找)原则:LEGB
- 函数的执行流程
- 函数调用的字节码
- 递归(Recursion)
- 斐波那契数列的递归实现方式
- 递归的要求
- 递归的性能
- 斐波那契数列,递归方式的改进
- 间接递归
- 递归的总结
- 递归函数的例题
- 函数的相互调用
函数的调用
变量名解析(查找)原则:LEGB
- Local 本地作用域,局部作用于的local命名空间,变量在函数调用(非函数定义,定义指的是函数中的传参)时创建,调用结束后消亡
- Enclosing:python2.2引入了嵌套函数,实现了闭包,这个就是嵌套函数的外部函数的命名空间
- Global: 全局作用于,即一个模块(一个py文件)的命名空间,变量在模块被import时创建,解释器退出时消亡(运行的python环境run已经结束了,才会销毁)
- Bulid-in:内置模块的命名空间,变量的生命周期从python解释器启动时创建到解释器退出时消亡,例如print(open)、print和open都是内置的变量
- 因此,一个标识符的查找顺序是LEGB
- 所以,在代码中定义了一个和内置函数相同名称的函数,在调用时找到的就是自定义的函数,而非内置函数
- nonlocal函数只能用在嵌套函数的内层函数中,如果他用在嵌套函数的外层函数,引用global中的变量时会报错,nonlocal后的变量,不会在本地寻找,直接上上一层函数中寻找,但是只到嵌套函数的最外层函数

函数的执行流程
def foo1(b,b1=3):
print("foo1 called",b,b1)
def foo2(c):
foo3(c)
print("foo2 called", c)
def foo3(d):
print("foo3 called", d)
def main():
print("main called")
foo1(100,101)
foo2(200)
print("main ending")
main()
====================run_result==============
main called
foo1 called 100 101
foo3 called 200
foo2 called 200
main ending
【解析】
-
全局模块中定义了foo1、foo2、foo3、main四个函数
-
main函数调用
-
语句:
print("main called")
1.main函数中查找内建函数print压栈,
2.将字面常量字符串压栈,调用函数后弹出栈顶 -
语句:
foo1(100,101)
1.main中全局查找函数foo1压栈,将常量100和101压栈,
2.调用函数foo1,创建栈帧
3.print函数压栈,字符串和变量b,b1压栈,调用函数,弹出栈顶,返回值 -
语句:
foo2(200)
1.main中全局查找函数foo2压栈,将常量200压栈
2.调用函数foo2,创建栈帧
3.foo3函数压栈,变量c引用压栈
4.调用foo3,创建栈帧,foo3完成后print调用并返回,弹出栈顶
5.foo2恢复调用,执行print后,返回值
6.main中foo2调用结束弹出栈顶
7.main继续执行print函数调用,弹出栈顶,main函数返回 -
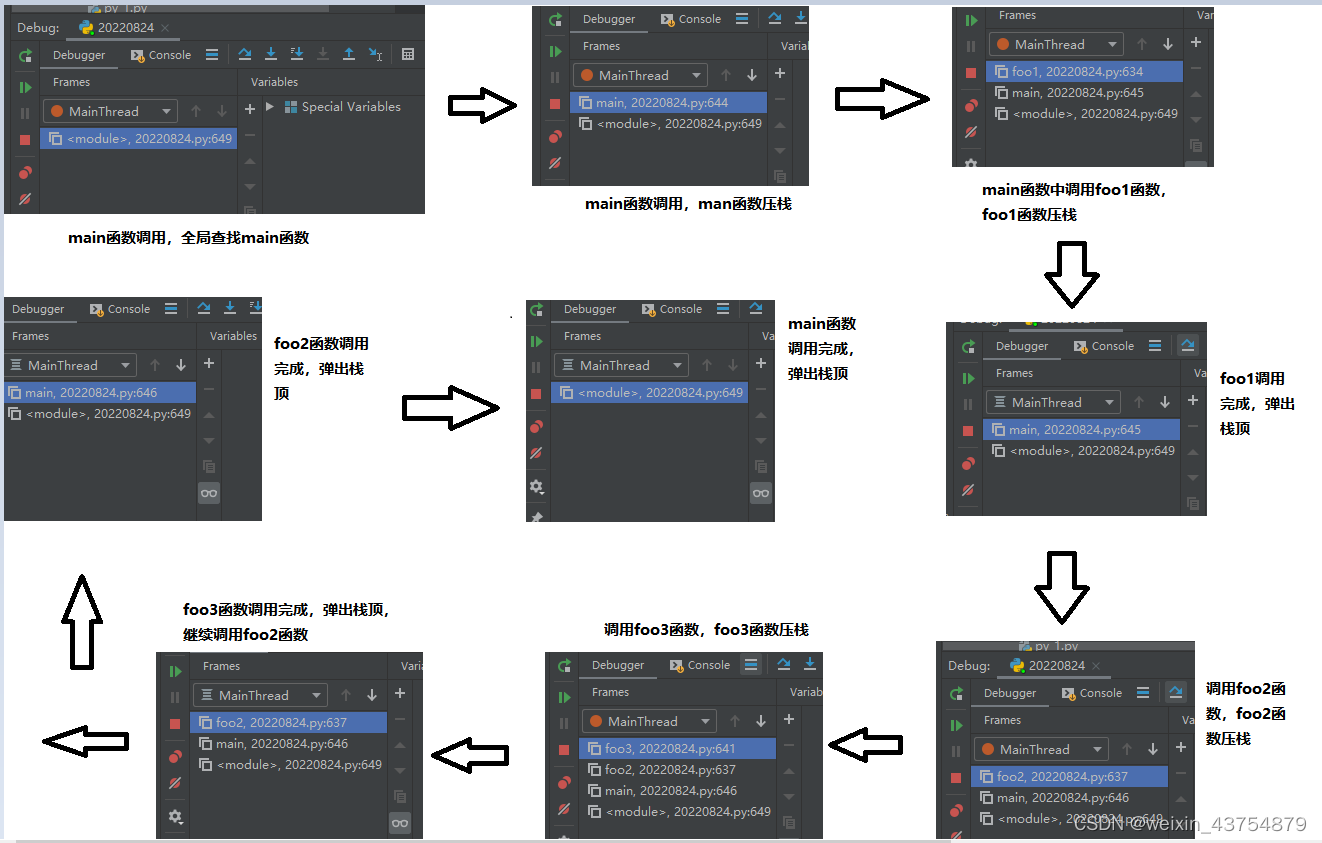
补充:栈的简单介绍
1.内存中是分栈和堆的
2.对于函数来说,用到的是栈,就相当于落盘子,只能从上面拿,不能从底部抽。
3.栈的原则:先进后出,后进先出
4.如果函数A在调用后还未释放的情况下,需要调用新的函数B,可以先将A函数保存后压入栈中,再调用B函数的数据压栈,代码执行后数据释放完毕,即可将函数B弹出栈顶,然后夹在A函数,继续执行A函数的代码 -
程序执行过程中,压栈的情况详见下方截图
函数调用的字节码
- 目标代码:
def foo(b,b1=1):
print("foo1 called",b,b1)
foo2(1)
def foo2(a):
pass
foo(2)
- 调用foo函数时,字节吗如下:

【名词解析】 - LOAD_GLOBAL :全局作用域
- LOAD_COUST:字面常量
- LOAD_FAST:变量
- CALL_FUNCTION:函数调用,调用完成之后弹出所有的函数参数,函数本身关闭堆栈,并推送返回值
- POP_TOP:删除顶部(TOS)项目,可以理解为删除正在执行的函数
- RETURN_VALUE 返回值
【foo1函数的内存执行步骤】
- 第一步:到全局作用域中查找print函数,然后压栈
- 第二步:将字面常量:“foo1 called”压入栈中
- 第三步:将变量b压入栈中
- 第四步: 将变量b1压入栈中
- 第五步:调用函数,函数调用完成之后关闭变量和常量的堆栈,并推送返回值
- 第六步:删除正在执行的函数(print函数)
- 第七步:全局查找函数foo2
- 第八步:将变量2压入栈中
- 第九步:调用函数,函数完成之后将常量的堆栈,并推送返回值
- 第十步:删除正在执行的函数(foo2函数)
- 第十一步:将返回值None压入栈中(None是默认返回值)
- 第十二步:将返回值返回
递归(Recursion)
- 函数直接或者间接调用自身就是递归:
- 递归需要有边界条件,递归前进段和递归返回段;递归不能无限调用
- 递归一定要有边界条件
- 当边界条件不满足时,递归前进(可以理解为函数在执行过程中的依次压栈)
- 当边界条件满足时,递归返回(可以理解为函数执行完成之后,依次弹出栈顶)
斐波那契数列的递归实现方式
- 斐波那契数列:1,1,2,3,5,8,13,21,34,55,89,144……
- 如果设F(n)为该数列的第n项,那么斐波那契数列可以写为:F(n)=F(n-1)+F(n-2)
- F(0)=0 F(1) F(n)=F(n-1)+F(n-2)
- 斐波那契数列非递归的实现方式如下:
pre = 0
cur = 1
print(pre,cur,end=" ")
n=4
for i in range(n-1):
pre,cur = cur,pre+cur
print(cur,end=" ")
- 斐波那契数列的递归解决方式
#函数定义
def fib(n):
return 1 if n<2 else fib(n-1)+fib(n-2)#三元表达式
#函数调用
for i in range(10):#i=0,1,2,3,4
print(fib(i),end=" ")
【解析】
- fib(1)是边界,因为fib(1)进来之后,n就小于2了,这样就直接
return 1 - 先将n=4带入fib函数
- 4不小于2,返回fib(3)+fib(2)
- 然后fib(3)调用时返回fib(2)+fib(1)
- fib(2)调用时返回fib(1),具体执行如下:

递归的要求
- 递归函数一定要有退出条件,递归调用是一定要执行到这个退出条件,没有退出条件的递归调用,就是无限调用
- 递归调用深度不宜过深
- python对地柜的深度做了限制,用来保护解释器
- 超过递归深度限制,抛出
RecursionError: maximum recursion depth exceeded in comparison超出最大深度 - 查看递归深度:
sys.getrecursionlimit(),可以修改正这个值,使用sys.setrecursionlimit()函数,括号中传入要设置的深度值,但是,一般情况下,请不要修改这个值
import sys
def fib(n):
if n<2:
return 1
else:
return fib(n-1)+fib(n-2)
a = fib(4)
print(a)
print(sys.getrecursionlimit())
================run_result===============
5
1000 #表示递归的最大深度是1000
递归的性能
- 疑问:以上关于斐波那契数列的递归和非递归的代码,哪种性能更优?
- 答复:相较而言,使用递归的效率更加慢一点
递归的性能有以下特点:
- 循环稍微复杂一点,但是不要时死循环,可以使用多次迭代直至算出结果
- fib函数代码极简易懂,但是只能获取到最外层的函数调用,内部诋毁结果都是中间结果。而且给定一个n,都要进行2n次递归,深度越深,效率越低,为了获取斐波那契数列需要在外面嵌套一个n次的循环,效率就更加低了
- 递归还有深度限制,如果递归复杂,函数需要反复压栈,栈内存很快就溢出了
斐波那契数列,递归方式的改进
【改进策略】
- 代码中的fib函数和循环的思想类似
- 参数n是边界条件,用n来计数
- 上一次的计算结果直接作为函数的实参
- 效率很高
- 和循环相比,性能相近,所以并不是说递归一定效率低下,但是递归有深度限制
- 具体代码如下:
pre = 0
cur = 1 #numb 1
print(pre,cur,end= " ")
def fib(n,pre=0,cur =1):#首次进来,pre=0,cur=1
pre,cur = cur,pre + cur
print(cur,end=" ")
#前面的数pre已经计算过了,直接打印后面的cur,即计算出的两数之和
if n ==2:#n=2推出循环
return #返回None
fib(n-1,pre,cur)
#执行完以后,n-1,将上面计算之后的pre和cur作为实参传入
fib(10)
==============run_result==========
0 1 1 2 3 5 8 13 21 34 55
【注意】
- 上面代码中,当n=2时,return None后,然后让已经调用的函数出栈
- 查找上一个函数时,因为
fib(n-1,pre,cur)已经执行完毕(print打印),因此之前的函数就隐含返回了一个return None,因此之前调用函数的返回值就是None
间接递归
- 间接递归:是通过别的函数调用了函数自身
- 但是,如果构成了循环递归,调用是非常危险的,往往这种情况在打吗复杂的情况下,还是可能发生这种调用,要用代码的规范避免这种递归调用的产生
- 例如:以下代码就是一个循环间接递归的调用
def foo():
foo2()
def foo2():
foo()
foo()
递归的总结
- 递归是一种很自然的表达,符合逻辑思维
- 递归相对运行效率低,每一次调用函数都要开辟栈帧
- 递归有深度限制,如果递归层次太深,函数反复压栈,栈内存就很快溢出了
- 如果有限次数的递归,可以使用递归调用,或者使用循环代替,循环代码稍微复杂一点,但是只要不是死循环,可以多次迭代直至算出结果
- 绝大多数递归,都可以使用循环实现
- 即使递归代码间接,但是能不用,则不用递归
递归函数的例题
1.求n的阶乘
#初始做阶乘题目时,可以先将for循环写出来
#使用递归,传入参数时,传参是n-1,因此是按照range函数的倒序传参的
#也就是说:传入参数的顺序是5,4,3,2,1
#循环如下:
n=10
num = 1
for i in range(n,0,-1):
if i ==0:
num = 1
else:
num *= i
print(num)
#自己根据for循环代入递归写的解题代码
def get_jc(n,jc_r=1):#默认阶乘的初始值为1,如果为0,乘积时所有的结果全部是0
if n ==0:#当n=0为1时,阶乘的数值为1,因此直接在末尾乘以1
jc_r *= 1
else:
jc_r *= n#n不为0,阶乘的计算方式是:5*4*3*2*1
if n == 0:#这里是递归函数的退出条件,n=0就不需要往下执行了
print(jc_r)#打印所有数值乘积之后的阶乘
return
get_jc(n-1,jc_r)#递归调用函数
get_jc(10)
#递归实现的其他方式:
def jc_3(n,jc_v=1):
jc_v *= n
if n ==1:
return jc_v
return jc_3(n-1,jc_v)
a=jc_3(5)
print(a)
=======================run_result================
3628800
3628800
3628800
【jc_3代码解析】
- jc_3传入的参数,n控制一共几个数,jc_v为阶乘的值,默认值为1
- 每次调用函数之后,都将jc_v作为实参传入从下一次调用,然后n-1
- 当n等于1时,直接将jc_v return返回,用变量接收之后,可打印
2.将一个列表中的数,逆序放到新的列表中
#初始做阶乘题目时,可以先将for循环写出来,倒序的for循环如下:
l_d = [4,6,8,3]#原列表
e = len(l_d)
l_n = [1]* e
#新列表,这句话的意思是形成一个长度为e的新列表,列表的元素都是1
#注意,使用这种方式,列表中元素的内存地址默认指向同一个位置,引用类型,需要注意
for i in range(e,0,-1):
l_n[e-i] = l_d[i-1]
print(l_n)
#逆序放入列表的递归方式:
l_d = [4,6,8,3]
e = len(l_d)
l_n = [1] * e
def re_l(a=e):
l_n[e-a] = l_d[a-1]
if a == 1:
return
re_l(a-1)
re_l()
print(l_n)
print("****************** 第二种方式 ************")
#也可以将这种改成升序的形式,升序的for循环是:
l_d = [4,6,8,3]
e = len(l_d)
l_n = [1]* e
for i in range(e):
l_n[i] = l_d[e-1-i]
print(l_n)
#将其给成递归,就是:
l_d = [4,6,8,3]
e = len(l_d)
l_n = [1] * e
def re_l(a=0):
l_n[a] = l_d[e-1-a]
if a == e-1:
return
re_l(a+1)
re_l()
print(l_n)
===================run_result==================
[3, 8, 6, 4]
[3, 8, 6, 4]
[3, 8, 6, 4]
[3, 8, 6, 4]
【解析】
l_n[e-i] = l_d[i-1],这句话,是发现规律之后写的,倒序时,3对0,2对1,1对2.,0对3,因此当i在4,3,2,1循环递减是,e-i的索引对应0,1,2,3,新列表需要对应的索引是:3,2,1,0,因此索引就是i-1- 递归中传入的参数a,就相当于for循环中的变量i
【思考】
- 如果传入的不是列表,而是字符串,要怎么倒叙插入一个新的列表?
- 代码示例:
def str_d(num,flag = []):
if num:
flag.append(num[len(num)-1])#根据索引获取字符串中最后一个元素
str_d(num[:len(num)-1])#传入的参数为去掉最后一个元素之后的字符串
return flag
print(str_d(str(43299)))
===============run_result=================
['9', '9', '2', '3', '4']
3.解决猴子吃桃的问题:
猴子吃桃子:猴子摘了n个桃子,第一天吃了一半多一个,第二天吃剩下的一半多一个,以此类推,到了第10天就剩下一个,请问,猴子最初摘了多少个桃子?
#for循环代码
n=1
for i in range(1,10):
n=(n+1)*2
print(n)
#递归用法
#注意:n相当于for循环中的i,a相当于for循环中的n,计算桃子个数
def tz(a,n=1):
a = (a+1)*2
if n == 9:
print(a)
return
tz(a,n+1)
tz(1)
===================run_result===================
1534
1534
函数的相互调用
函数的相互调用是指在一个函数中调用另外一个函数,例如
def print_msg(content):
print('我想说 :{0}'.format(content))
def learn_language(name):
print("我正在学{}语言".format(name))
# 在一个函数中调用另外一个函数,“很难”为content的值
print_msg('很难')
learn_language('英语')
***********************run_result******************
我正在学英语语言
我想说 :很难
def print_msg(content):
print('我想说 :{0}'.format(content))
def learn_language(name,content):
print("我正在学{}语言".format(name))
# 在一个函数中调用另外一个函数,“很难”为content的值
#print_msg('很难')
print_msg(content)#调用时参数化被调用函数的参数
learn_language('Python','好难')
***********************run_result******************
我正在学Python语言
我想说 :好难
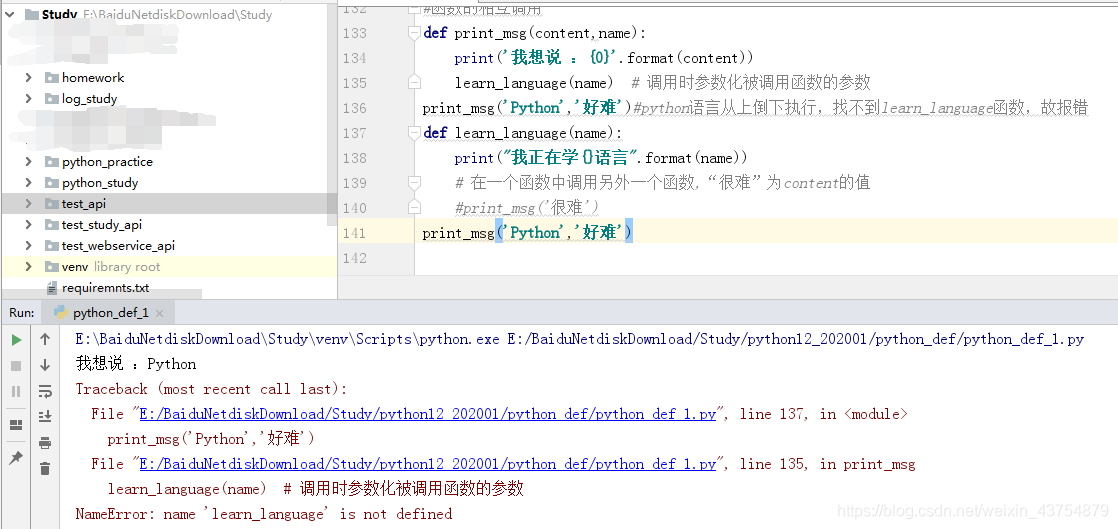
需要注意:
**python语言的执行是从上而下的,如果调用函数放在两个函数之间,会报错,**例如以下截图