数据同步工具—Sqoop
数据同步工具—Sqoop
1 Sqoop概述
传统的应用程序管理系统,即应用程序与使用RDBMS的关系数据库的交互,是产生大数据的来源之一。由RDBMS生成的这种大数据存储在关系数据库结构中的关系数据库服务器中。
当大数据存储和Hadoop生态系统的MapReduce,Hive,HBase,Cassandra,Pig等分析器出现时,他们需要一种工具来与关系数据库服务器进行交互,以导入和导出驻留在其中的数据。在这里,Sqoop在Hadoop生态系统中占据一席之地,以便在关系数据库服务器和Hadoop的HDFS之间提供可行的交互。
Sqoop是一个用于在Hadoop和关系数据库服务器之间传输数据的工具。它用于从关系数据库(如MySQL,Oracle)导入数据到Hadoop HDFS,并从Hadoop文件系统导出到关系数据库。它由Apache软件基金会提供。
需要注意的是Sqoop的1.x 和 2.x 的版本差异比较大,但是1.99算是2.x版本的,所以在使用的时候需要注意
Sqoop如何工作
下图描述了Sqoop的工作流程。
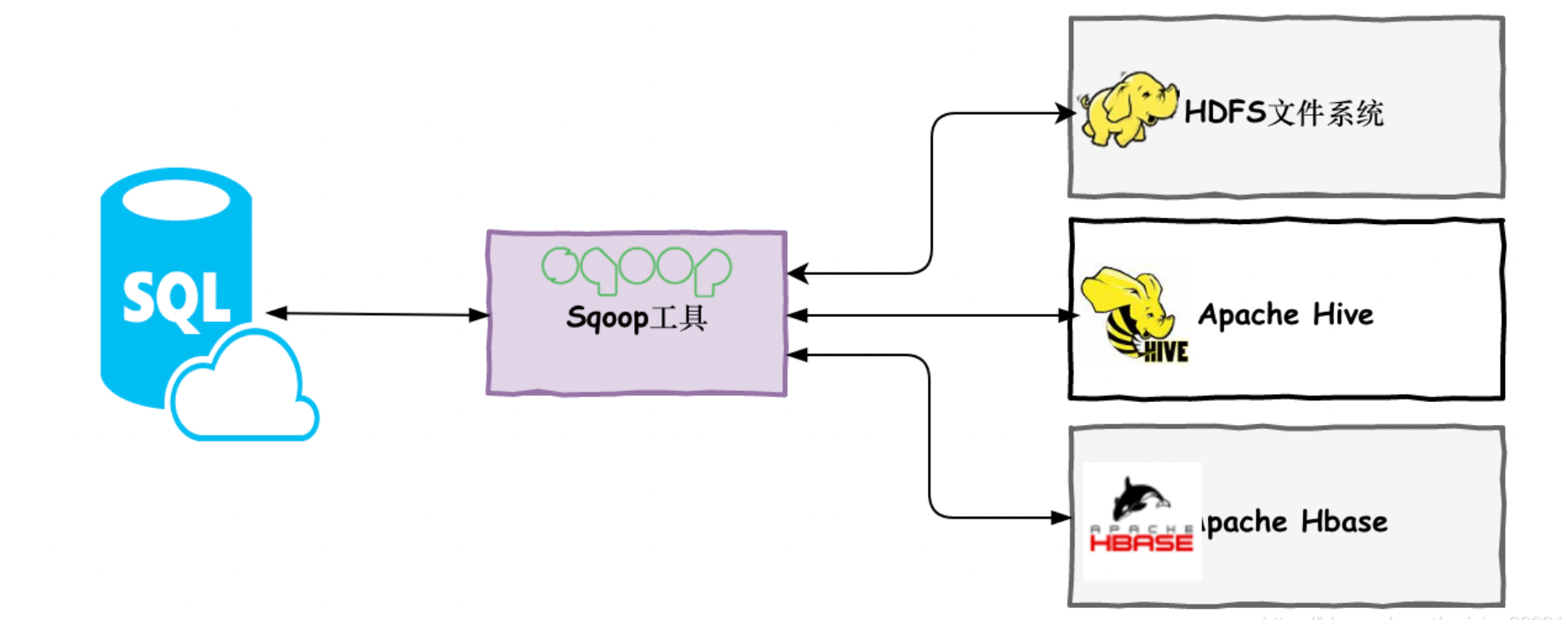
Sqoop导入
导入工具从RDBMS向HDFS导入单独的表。表中的每一行都被视为HDFS中的记录。所有记录都以文本文件的形式存储在文本文件中或作为Avro和Sequence文件中的二进制数据存储。
Sqoop导出
导出工具将一组文件从HDFS导出回RDBMS。给Sqoop输入的文件包含记录,这些记录在表中被称为行。这些被读取并解析成一组记录并用用户指定的分隔符分隔。
2 Sqoop安装
由于Sqoop是Hadoop的子项目,因此它只能在Linux操作系统上运行。按照以下步骤在您的系统上安装Sqoop。
1 安装java Hadoop
java和Hadoop的安装就不介绍了,可以自行百度
2 下载Sqoop
我们可以从以下链接下载最新版本的Sqoop 对于本教程,我们使用1.4.7版本,即sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz ,其实我们看到sqoop 已经很久没更新了,其实这主要两方面原因:
- sqoop已经很稳定了
- sqoop太老了,已经没有多少人在用了
3 安装Sqoop
以下命令用于提取sqoop的压缩包移动到/usr/local 目录下并解压
sudo cp ~/Downloads/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz /usr/local/
tar xvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
解压完成后配置环境变量,可以通过在~/.bash_profile文件中添加以下行来设置Sqoop环境,注意不同的shell 可能不一样,但是/etc/profile 肯定是可以的
vim ~/.bash_profile
# 添加环境变量
export SQOOP_HOME=/usr/local/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin
刷新环境变量source ~/.bash_profile,我们可以输入sqoop 后按tab 键,发现我们的环境变量已经生效了

4 配置Sqoop
为了能使得Sqoop正常工作,例如相关数据我们还需要配置大数据的相关环境,Sqoop同步原理是通过MR 来实现的,所以需要编辑sqoop-env.sh文件,该文件被放置在$ SQOOP_HOME/conf目录。首先,重定向到Sqoop config目录并使用以下命令复制模板文件 -
cd $SQOOP_HOME/conf
mv sqoop-env-template.sh sqoop-env.sh
打开sqoop-env.sh并编辑以下行 -
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
5 下载并配置mysql-connector-java
我们从以下maven 仓库下载该jar,然后 使用下面的命令移动jar 包到 $SQOOP_HOME/lib/
cp ~/Downloads/mysql-connector-java-5.1.49.jar $SQOOP_HOME/lib/
6 验证Sqoop
以下命令用于验证Sqoop版本。
sqoop-version
输出
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2022-09-30 14:59:15,766 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017
Sqoop安装完成,其实这里有一些告警信息,暂时不管,后面有问题再处理
Warning: /usr/local/sqoop-1.4.7.bin__hadoop-2.6.0/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4.7.bin__hadoop-2.6.0/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
3 Sqoop Import
下面绍如何将数据从MySQL数据库导入到Hadoop HDFS。Import从RDBMS将单个表导入HDFS。表中的每一行都被视为HDFS中的记录。所有记录均以文本数据的形式存储在文本文件中,或作为Avro和Sequence文件中的二进制数据存储。
数据准备
以下语法用于将数据导入HDFS。
$ sqoop import (generic-args) (import-args)
我们有一个world 库,里面有个表叫做city,数据如下
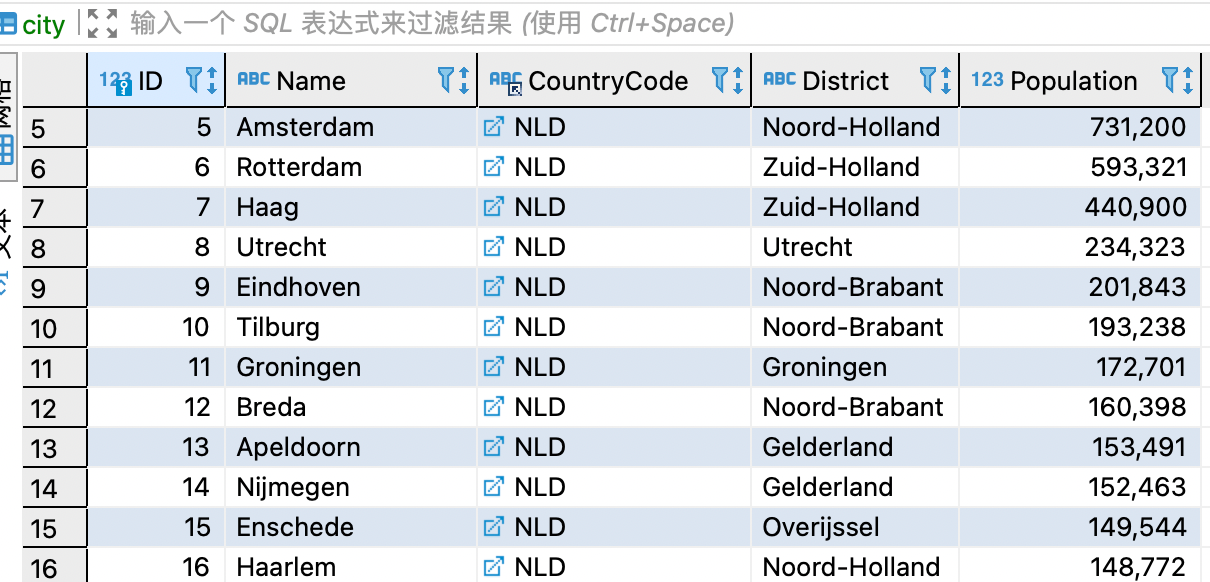
导入数据
Sqoop导入工具用于将表格数据从表格导入到Hadoop文件系统,作为文本文件或二进制文件。这里我们先尝试最小命令,也就是那些必须的参数,然后我们看看为了满足我们的目的可以使用哪些参数。
以下命令用于将world 库中的city表从MySQL数据库服务器导入到HDFS。
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--m 1
如果它成功执行,则会得到以下输出。
2022-09-30 16:46:40,311 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1664527475421_0001/
2022-09-30 16:46:40,312 INFO mapreduce.Job: Running job: job_1664527475421_0001
2022-09-30 16:46:48,463 INFO mapreduce.Job: Job job_1664527475421_0001 running in uber mode : false
2022-09-30 16:46:48,464 INFO mapreduce.Job: map 0% reduce 0%
2022-09-30 16:46:53,529 INFO mapreduce.Job: map 100% reduce 0%
2022-09-30 16:46:53,539 INFO mapreduce.Job: Job job_1664527475421_0001 completed successfully
2022-09-30 16:46:53,663 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=235070
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=144481
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=2420
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=2420
Total vcore-milliseconds taken by all map tasks=2420
Total megabyte-milliseconds taken by all map tasks=2478080
Map-Reduce Framework
Map input records=4079
Map output records=4079
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=32
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=317718528
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=144481
2022-09-30 16:46:53,667 INFO mapreduce.ImportJobBase: Transferred 141.0947 KB in 17.0677 seconds (8.2668 KB/sec)
2022-09-30 16:46:53,670 INFO mapreduce.ImportJobBase: Retrieved 4079 records.
我们可以看到这是一个没有reduce 的MR,我们输入输出数据是4079 条
Map input records=4079
Map output records=4079
其实上面我们并没有指定要将数据同步到HDFS 上的那个目录下去,那其实默认是在/user/XXX/city,其中 XXX 是用户名,city 是表名
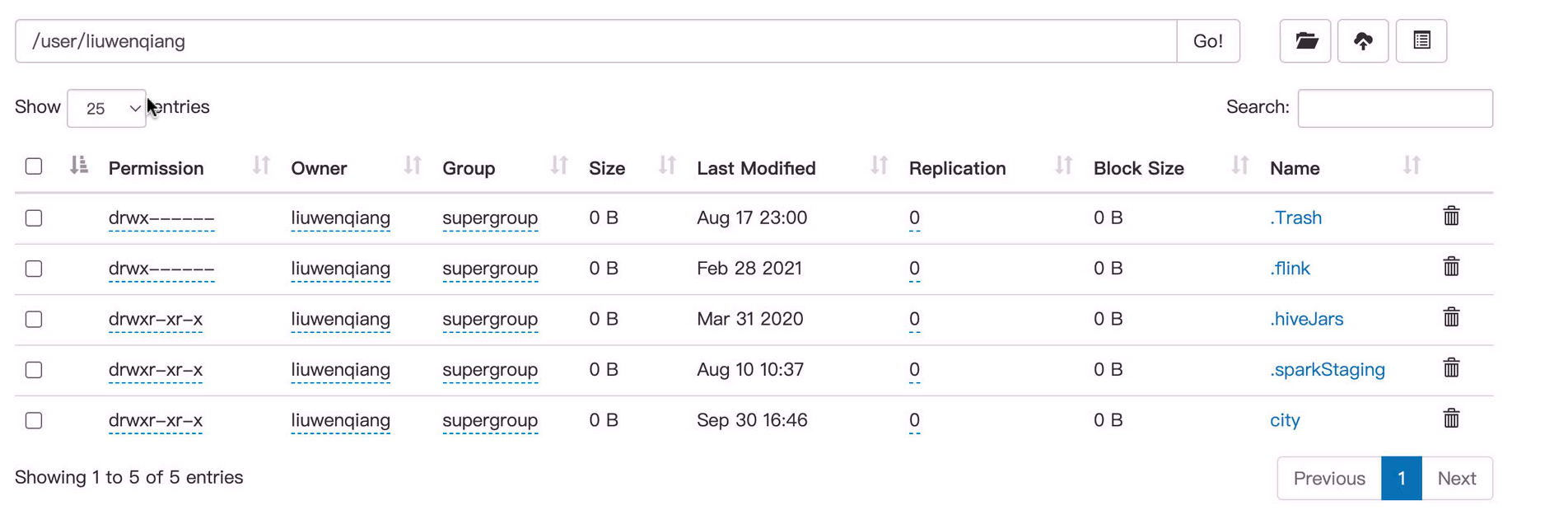
导入目标目录
我们可以在使用Sqoop将表中数据导入HDFS时指定目标目录。以下是将目标目录指定为Sqoop导入命令的选项的语法。
--target-dir <new or exist directory in HDFS>
以下命令用于将emp_add表数据导入到’/ queryresult’目录中。
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--m 1 \
--target-dir /tmp/city
我们可以看到数据已经在/tmp/city 目录中了
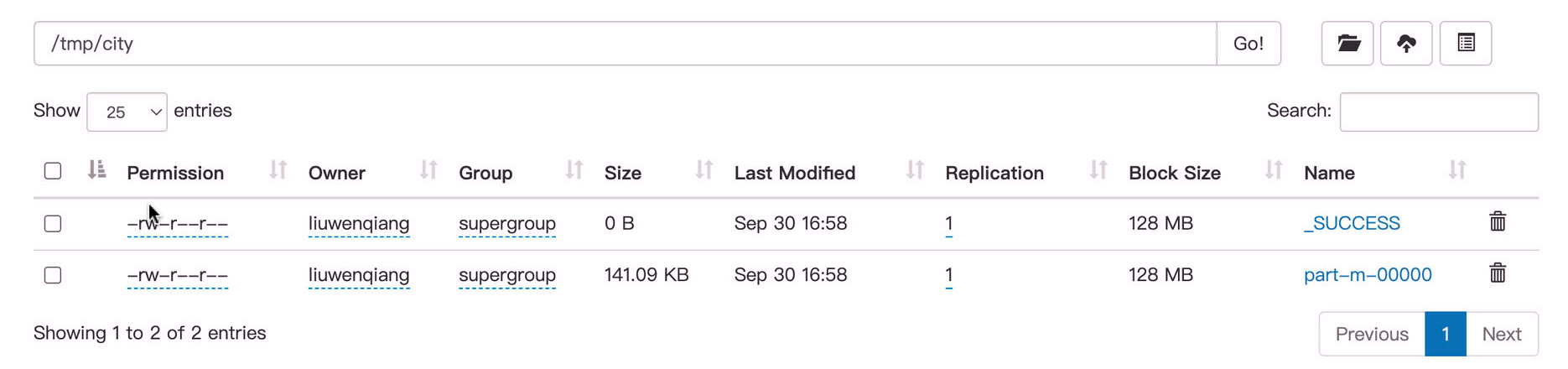
需要注意的是我们要保证/tmp/city目录不存在,否则就有下面的报错(这里演示的时候使用的是/tmp)
Import failed: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://kingcall:9000/tmp already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:164)

解决这个问题其实很简单,只需要添加一个选项--delete-target-dir 即可
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--delete-target-dir \
--m 1
# 或者
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--m 1 \
--delete-target-dir \
--target-dir /tmp/city
导入数据的子集
我们可以使用Sqoop的时候再where子句中加上一个过滤条件从而只导入我们想要的一部分,例如每天的增量数据。它在相应的数据库服务器中执行相应的SQL查询,并将结果存储在HDFS中的目标目录中。
where子句的语法如下。
--where <condition>
以下命令用于导入city表数据的子集。这里导入人口大于100万册城市
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--m 1 \
--where "Population>=1000000" \
--target-dir /tmp/city
我们明显看到数据文件小了很多
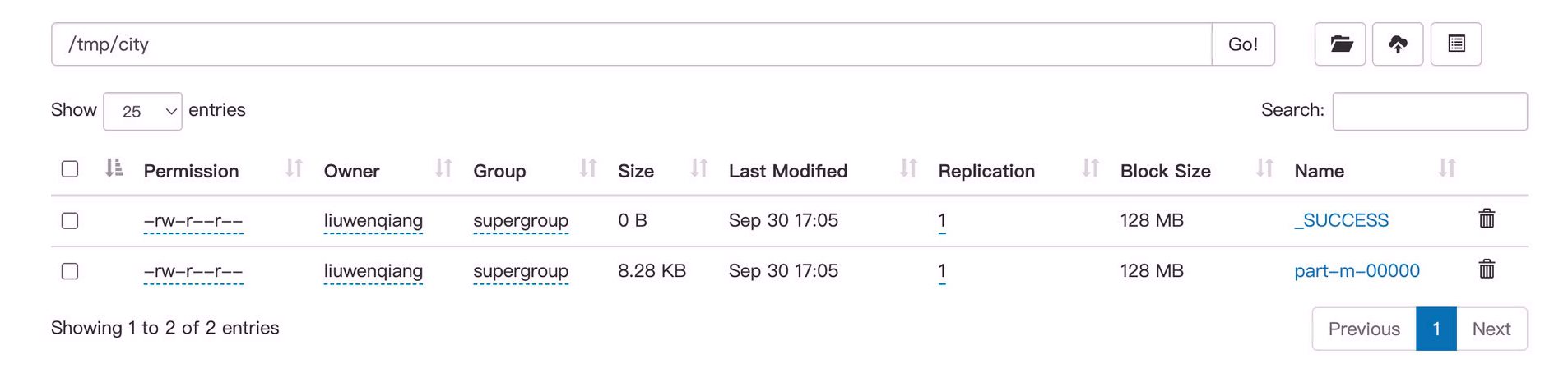
日志中也显示只有238条数据
Map-Reduce Framework
Map input records=238
Map output records=238
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=29
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=320864256
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=8481
增量导入
增量导入是一种仅导入表中新添加的行的技术。需要添加’incremental’,'check-column’和’last-value’选项来执行增量导入。
以下语法用于Sqoop导入命令中的增量选项。
--incremental <mode>
--check-column <column name>
--last value <last check column value>
我们的city 表是自增主键,我们假设上次把前4000条都同步进来了,那么我们的last-value 就是4000,其实我们知道总共有4079条数据,那么这次导入的应该是79条数据
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--m 1 \
--incremental append \
--check-column id \
--last-value 4000 \
--target-dir /tmp/city
首先我们看到数据同步进来了,而且文件小了很多,那是因为只有79条数据
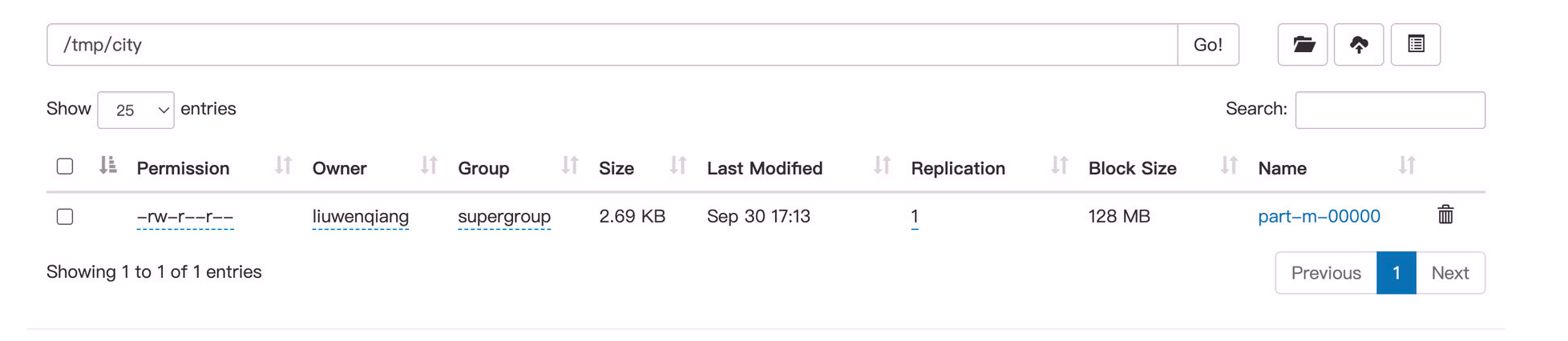
关于是否只有79条,我们可以看日志, Map input records=79 说明我们的假设没有问题
2022-09-30 17:13:15,148 INFO mapreduce.Job: Running job: job_1664527475421_0004
2022-09-30 17:13:21,254 INFO mapreduce.Job: Job job_1664527475421_0004 running in uber mode : false
2022-09-30 17:13:21,255 INFO mapreduce.Job: map 0% reduce 0%
2022-09-30 17:13:25,297 INFO mapreduce.Job: map 100% reduce 0%
2022-09-30 17:13:25,304 INFO mapreduce.Job: Job job_1664527475421_0004 completed successfully
2022-09-30 17:13:25,394 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=235302
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=2752
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=1918
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=1918
Total vcore-milliseconds taken by all map tasks=1918
Total megabyte-milliseconds taken by all map tasks=1964032
Map-Reduce Framework
Map input records=79
Map output records=79
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=33
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=327155712
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=2752
2022-09-30 17:13:25,401 INFO mapreduce.ImportJobBase: Transferred 2.6875 KB in 11.6835 seconds (235.5467 bytes/sec)
2022-09-30 17:13:25,403 INFO mapreduce.ImportJobBase: Retrieved 79 records.
2022-09-30 17:13:25,418 INFO util.AppendUtils: Creating missing output directory - city
2022-09-30 17:13:25,432 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments:
2022-09-30 17:13:25,432 INFO tool.ImportTool: --incremental append
2022-09-30 17:13:25,432 INFO tool.ImportTool: --check-column id
2022-09-30 17:13:25,432 INFO tool.ImportTool: --last-value 4079
2022-09-30 17:13:25,432 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
而且这个日志有意思的是告诉你了下次last-value 的值是4079 ,那其实我们会发现有点不合理的地方,那就是这个last-value 我们每次需要去手动维护,后面我们看这个问题如何解决。
需要注意的是增量作业,就不能和--delete-target-dir选项一起使用了,这很好理解如果你都将历史数据删除了(已经存在的),那还怎么增量呢
查询导入(query )
上面在导入数据的子集的时候演示了通过--where 选项导入部分数据,也就是满足条件的,下面我们通过--query 选项也可以导入子集,只不过使用--query的时候就不能使用--table 了,因为我们的数据是从--query 来的,这个很好理解
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--delete-target-dir \
--target-dir /tmp/city \
--query "SELECT * FROM city LIMIT 5" \
--m 1
不过需要注意的是我们必须要指定--target-dir,否则报错如下
Must specify destination with --target-dir
Try --help for usage instructions.
其实我们可以思考一下为什么,因为在使用--table 的时候,我们的数据文件夹有默认的名字也就是表名字,也有默认的路径,但是我们使用--query 的时候我们的数据文件夹是没有名字的,总不能搞一个随机的名字吧,既然没有默认的文件夹名字肯定就没有默认的目录了,所以需要我们指定。
下面的错误是因为--query 模式必须要跟一个CONDITIONS
2022-09-30 19:56:17,771 ERROR tool.ImportTool: Import failed: java.io.IOException: Query [SELECT * FROM city LIMIT 5] must contain '$CONDITIONS' in WHERE clause.
at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:332)
at org.apache.sqoop.orm.ClassWriter.getColumnTypes(ClassWriter.java:1872)
at org.apache.sqoop.orm.ClassWriter.generate(ClassWriter.java:1671)
at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:106)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:501)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
我们稍稍改造一下即可
sqoop import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--delete-target-dir \
--target-dir /tmp/city \
--query "SELECT * FROM city where \$CONDITIONS LIMIT 5" \
--m 1
可以看到导入了5条数据
Map-Reduce Framework
Map input records=5
Map output records=5
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=29
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=321388544
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=153
2022-09-30 20:07:31,549 INFO mapreduce.ImportJobBase: Transferred 153 bytes in 11.6347 seconds (13.1503 bytes/sec)
2022-09-30 20:07:31,551 INFO mapreduce.ImportJobBase: Retrieved 5 records.
既然table 可以导入子集合,为什么还要query 呢,因为query 更灵活,例如我们可以在query 中完成数据类型转换,运算,增加列、删除列操作
4 导入所有表
下面介绍如何将所有表从RDBMS数据库服务器导入到HDFS。每个表格数据存储在一个单独的目录中,并且目录名称与表格名称相同。
以下语法用于导入所有表。
$ sqoop import-all-tables (generic-args) (import-args)
world 库下面有三张表
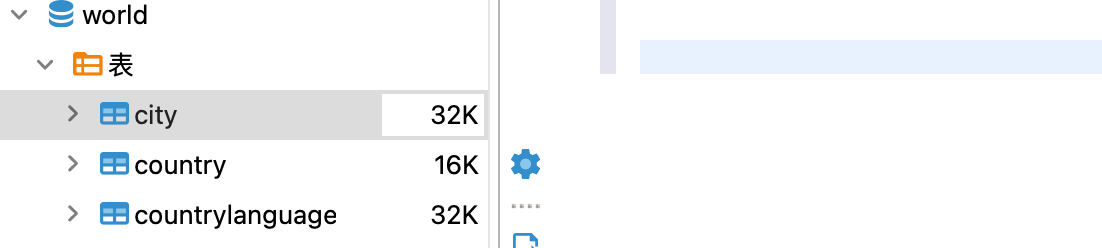
以下命令用于从userdb数据库中导入所有表。
sqoop import-all-tables \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234
由于我们没有指定目录,那么则会导入到当前用户的目录下, 但是我们看到报错了
2022-09-30 17:23:21,540 INFO db.DBInputFormat: Using read commited transaction isolation
2022-09-30 17:23:21,540 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`Code`), MAX(`Code`) FROM `country`
2022-09-30 17:23:21,546 INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/liuwenqiang/.staging/job_1664527475421_0006
2022-09-30 17:23:21,551 ERROR tool.ImportAllTablesTool: Encountered IOException running import job: java.io.IOException: Generating splits for a textual index column allowed only in case of "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" property passed as a parameter
就是说我们要允许对字符串类型的索引进行split,这是什么意思呢,如果你注意的话,发现我们前面一直有个参数--m 1 也就是启动只有一个Map 底MR 任务来完成抽数,由于我们这里没有指定所以Sqoop 就需要判断到底是启动几个Map 来完成抽数,判断标准就是对主键字段进行split ,但是由于我们的一个表的逐渐字段是字符串,所以导致出现了这个问题。
其实我们可以看到我们的city 表已经抽数成功了,只是在抽其他表的时候失败了
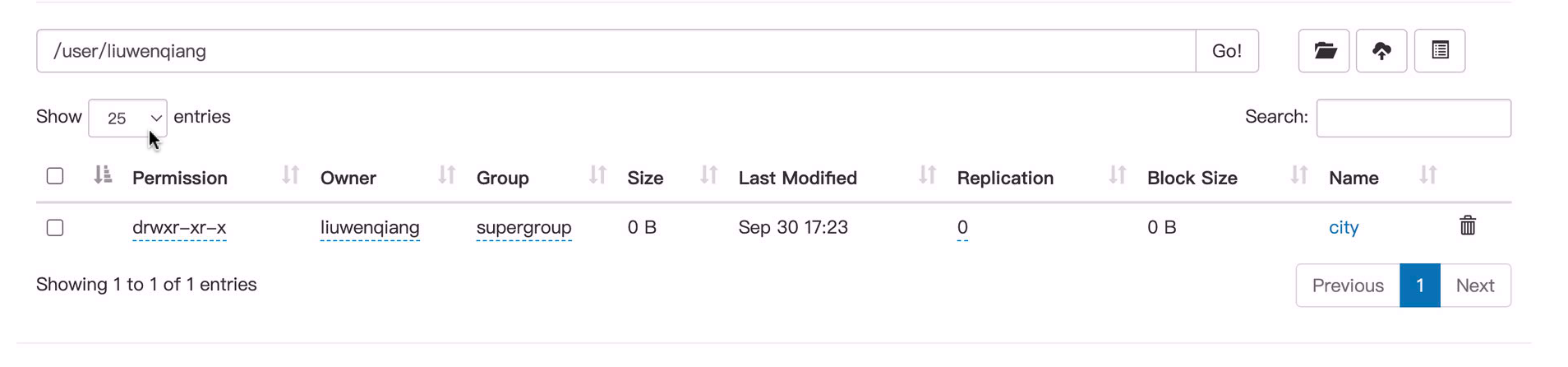
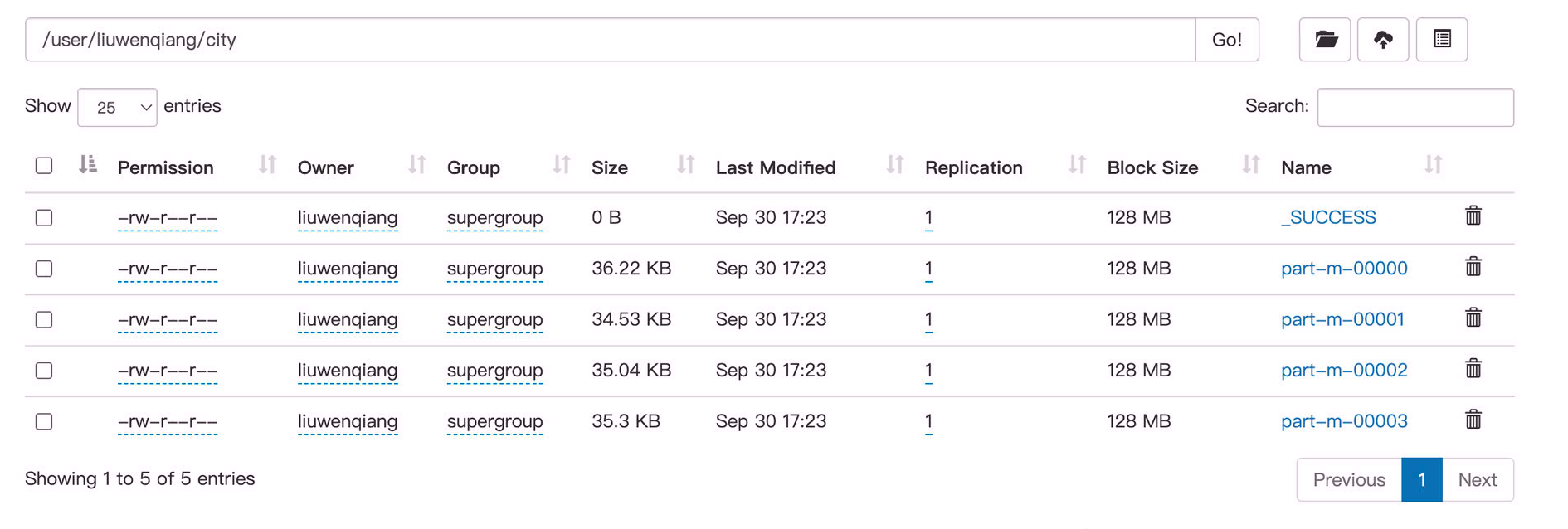
我们进入city表的目录,可以看到四个数据文件,那说明我们是通过4个map 抽数过来的,这一点也可以通过下面的日志印证
Job Counters
Launched map tasks=4
Other local map tasks=4
Total time spent by all maps in occupied slots (ms)=8254
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=8254
Total vcore-milliseconds taken by all map tasks=8254
Total megabyte-milliseconds taken by all map tasks=8452096
既然知道了原因,解决方案就很多了,例如改造主键,或者是我们直接指定使用一个map 来,这样就不用split 了
sqoop import-all-tables \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--m 1
数据已经被成功抽过来了
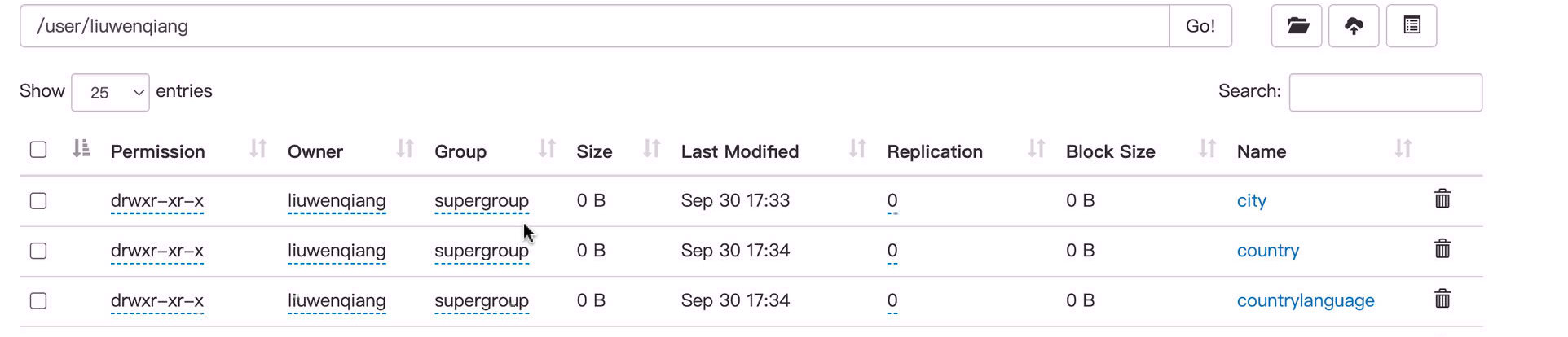
由于有三张表,所以我们看到启了三个任务,然后由于我们限制了map ,所以每个任务都只有一个map
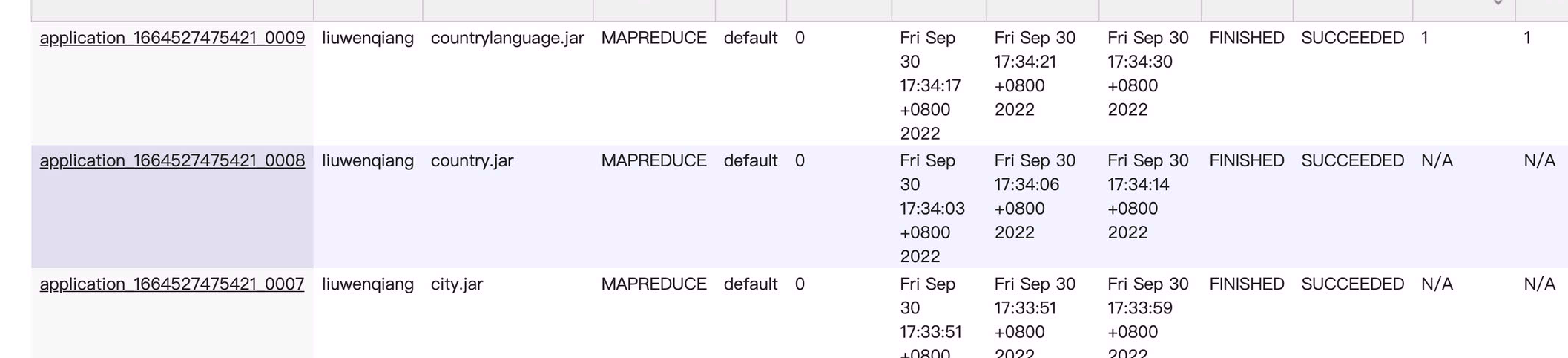
或者我们可以指定-Dorg.apache.sqoop.splitter.allow_text_splitter=true 选项,允许对字符串累类型的主键进行分割,不过这个时候要求所有的表都有主键
sqoop import-all-tables \
-Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234
我们看到数据已经被成功导入了
总结:
- 只使用一个map
- 有主键并且是数字类型
- 有主键如果是字符串,则指定
-Dorg.apache.sqoop.splitter.allow_text_splitter=true
5 Sqoop Export
下面如何将数据从HDFS导出回RDBMS数据库。目标表必须存在于目标数据库中。输入给Sqoop的文件包含记录,这些记录在表中称为行。这些被读取并解析成一组记录并用用户指定的分隔符分隔。
- 缺省操作是使用INSERT语句将输入文件中的所有记录插入到数据库表中。
- 在更新模式下,Sqoop生成将现有记录替换到数据库中的UPDATE语句。
以下是导出命令的语法。
sqoop export (generic-args) (export-args)
让我们以HDFS中的文件中的员工数据为例。雇员数据在HDFS的’/tmp/emp/'目录下的数据文件中,数据如下
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TP
1206, satish p, grp des, 20000, GR
必须手动创建要导出的表,并将其导出到数据库中。以下查询用于在mysql命令行中创建表’employee’。
$ mysql
mysql> use emp;
mysql> CREATE TABLE employee (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20),
deg VARCHAR(20),
salary INT,
dept VARCHAR(10));
以下命令用于将表数据(位于HDFS上的emp_data文件中)导出到Mysql数据库服务器的db数据库中的employee表中。
sqoop export \
--connect jdbc:mysql://localhost/emp \
--username root \
--password www1234 \
--table employee \
--export-dir /tmp/emp
以下命令用于验证mysql命令行中的表。
mysql>select * from employee;
可以看到数据已经成功导出
+------+--------------+-------------+-------------------+--------+
| Id | Name | Designation | Salary | Dept |
+------+--------------+-------------+-------------------+--------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | preader | 50000 | TP |
| 1203 | kalil | php dev | 30000 | AC |
| 1204 | prasanth | php dev | 30000 | AC |
| 1205 | kranthi | admin | 20000 | TP |
| 1206 | satish p | grp des | 20000 | GR |
+------+--------------+-------------+-------------------+--------+
6 Sqoop Job
前面我们介绍的都是直接在Sqoop 中输入一大串命令完成数据的导入导出,下面介绍如何创建和维护Sqoop作业,通过创建Sqoop作业保存导入和导出命令。
它指定参数来识别创建、调用作业。这种重新调用或重新执行主要用于增量导入,它可以将更新的行从RDBMS表导入HDFS,其实在前面我们在使用Sqoop进行增量同步的时候,是需要指定 last-value 的。但一般我们都是自动化进行数据同步的,这就需要有一个地方,能够自动记录和填充 上次增量同步的 last-value。
抛开手动维护这个last-value的繁琐,而且还很容易失败。所以Sqoop通过Job 这种方式解决了这个问题
以下是创建Sqoop作业的语法。
qoop job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]
创建作业(–create)
我们在这里创建一个名为myjob的作业,它可以将表数据从RDBMS表导入HDFS。以下命令用于创建将数据从db数据库中的employee表导入到HDFS文件的作业。
sqoop job --create job_import_city \
-- import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--m 1
遇到了一个报错,这主要是因为缺少java-json.jar
2022-09-30 18:25:05,552 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2022-09-30 18:25:05,910 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2022-09-30 18:25:05,935 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.NullPointerException
java.lang.NullPointerException
at org.json.JSONObject.<init>(JSONObject.java:144)
at org.apache.sqoop.util.SqoopJsonUtil.getJsonStringforMap(SqoopJsonUtil.java:43)
at org.apache.sqoop.SqoopOptions.writeProperties(SqoopOptions.java:785)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.createInternal(HsqldbJobStorage.java:399)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.create(HsqldbJobStorage.java:379)
at org.apache.sqoop.tool.JobTool.createJob(JobTool.java:181)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:294)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
我们从连接 下载这个依赖,然后放到$SQOOP_HOME/lib 目录下
cp ~/Downloads/java-json.jar $SQOOP_HOME/lib
当我们再次执行创建作业的时候又说作业已经存在

所以我们先删除一下,再创建
# 删除作业
sqoop job --delete job_import_city
# 创建作业
sqoop job --create job_import_city \
-- import \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--table city \
--m 1
这次我们就创建成功了

列出作业(–list)
--list参数可以列出创建的job
sqoop job --list
它显示保存的作业列表。
Available jobs:
job_import_city
检查作业(–show)
'–show’参数用于检查或验证特定作业及其细节
sqoop job --show job_import_city
它显示了job_import_city的详细信息,有一个输入密码的环节,由于我们没有设置秘密所以直接回车就好
2022-09-30 18:40:07,869 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
Job: job_import_city
Tool: import
Options:
----------------------------
verbose = false
hcatalog.drop.and.create.table = false
db.connect.string = jdbc:mysql://localhost/world
codegen.output.delimiters.escape = 0
codegen.output.delimiters.enclose.required = false
codegen.input.delimiters.field = 0
split.limit = null
hbase.create.table = false
mainframe.input.dataset.type = p
db.require.password = true
skip.dist.cache = false
hdfs.append.dir = false
db.table = city
codegen.input.delimiters.escape = 0
accumulo.create.table = false
import.fetch.size = null
codegen.input.delimiters.enclose.required = false
db.username = root
reset.onemapper = false
codegen.output.delimiters.record = 10
import.max.inline.lob.size = 16777216
sqoop.throwOnError = false
hbase.bulk.load.enabled = false
hcatalog.create.table = false
db.clear.staging.table = false
codegen.input.delimiters.record = 0
enable.compression = false
hive.overwrite.table = false
hive.import = false
codegen.input.delimiters.enclose = 0
accumulo.batch.size = 10240000
hive.drop.delims = false
customtool.options.jsonmap = {}
codegen.output.delimiters.enclose = 0
hdfs.delete-target.dir = false
codegen.output.dir = .
codegen.auto.compile.dir = true
relaxed.isolation = false
mapreduce.num.mappers = 1
accumulo.max.latency = 5000
import.direct.split.size = 0
sqlconnection.metadata.transaction.isolation.level = 2
codegen.output.delimiters.field = 44
export.new.update = UpdateOnly
incremental.mode = None
hdfs.file.format = TextFile
sqoop.oracle.escaping.disabled = true
codegen.compile.dir = /tmp/sqoop-liuwenqiang/compile/d7767a1386302f6e759aa443dfb7f8a4
direct.import = false
temporary.dirRoot = _sqoop
hive.fail.table.exists = false
db.batch = false
执行作业(–exec)
'–exec’选项用于执行保存的作业。以下命令用于执行名为job_import_city的作业。
sqoop job --exec job_import_city
然后报错了,信息如下,这主要是因为有一个输入密码的环节我直接回车了,不过从这个报错信息可以看出来是要我们输入数据源的密码

java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: NO)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:965)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3933)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3869)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:864)
at com.mysql.jdbc.MysqlIO.proceedHandshakeWithPluggableAuthentication(MysqlIO.ja
这个时候你可以看--show 的输出中并没有输出mysql 的密码信息,也就是说只保存了用户,所以当我们输入密码后我们的任务就执行成功了
既然又了作业(job),那我们就可以多次调用,不过由于我们没有添加--delete-target-dir 选项,多次调用会报错,因为目录已经存在

所以你创建job的时候需要将这个参数加上
删除作业( --delete )
我们可以通过下面的命令删除作业
sqoop job --delete job_import_city
手动输入密码的问题
我们前面已经遇到手动输入密码的问题了,现在我们看下这个问题的解决方案,sqoop 提供了--password-file 选项来解决这个问题,就是我们创建一个密码文件,然后放在hdfs 上,然后通过--password-file来提供给hdfs
# 创建密码文件
echo -n "www1234" > sqoop_world_db.pwd
# 创建hdfs目录
hdfs dfs -mkdir -p /sqoop/pwd
# 上传密码文件
hdfs dfs -put sqoop_world_db.pwd /sqoop/pwd
如下所示

删除前面的job ,重新创建,并且指定--password-file
# 删除作业
sqoop job --delete job_import_city
# 创建作业
sqoop job --create job_import_city \
-- import \
--connect jdbc:mysql://localhost/world \
--username root \
--table city \
--delete-target-dir \
--password-file /sqoop/pwd/sqoop_world_db.pwd \
--m 1
# 执行作业
sqoop job --exec job_import_city
这次我们发现任务成功执行
增量作业
前面我们说了Sqoop 的作业主要是为了解决增量的问题,我们看看它是如何解决的last-value的维护问题的,下面我们创建一个作业,指定last-value 是4000
sqoop job --create job_import_city_incremental \
-- import \
--connect jdbc:mysql://localhost/world \
--username root \
--table city \
--password-file /sqoop/pwd/sqoop_world_db.pwd \
--check-column id \
--last-value 4000 \
--incremental append \
--m 1
执行作业之前我们看一下当前的数据情况
执行作业
sqoop job --exec job_import_city_incremental
可以看到同步了79数据进来,这是正确的
2022-09-30 19:27:24,506 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=235899
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=2752
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=1880
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=1880
Total vcore-milliseconds taken by all map tasks=1880
Total megabyte-milliseconds taken by all map tasks=1925120
Map-Reduce Framework
Map input records=79
Map output records=79
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=28
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=324009984
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=2752
2022-09-30 19:27:24,509 INFO mapreduce.ImportJobBase: Transferred 2.6875 KB in 11.7101 seconds (235.0113 bytes/sec)
我们看一下执行了一次之后的数据情况,多了一个数据文件
如果我们再次执行作业还能同步79条数据进来的话,那说明我们的增量作业没有生效,也就是没有帮我们维护last-value ,因为我们目前没有新数据进来,我们发现执行后根本没有启动MR任务
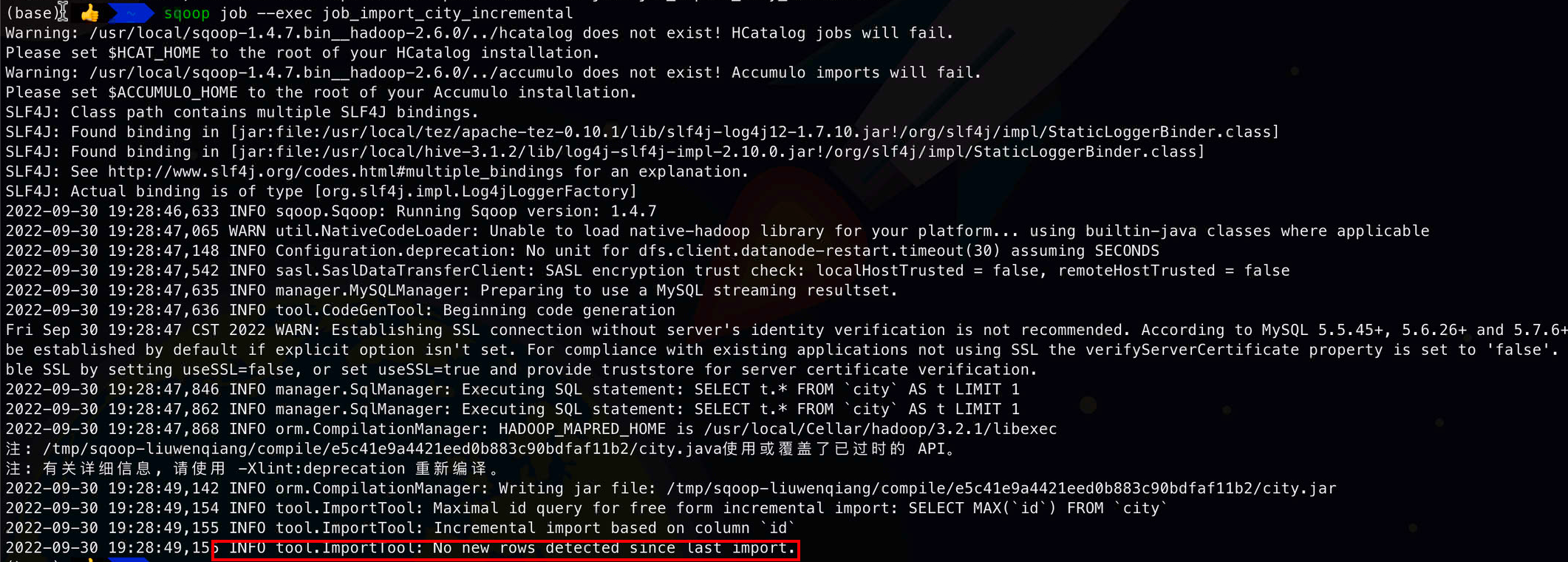
因为没有检测到有新的数据
2022-09-30 19:28:49,154 INFO tool.ImportTool: Maximal id query for free form incremental import: SELECT MAX(`id`) FROM `city`
2022-09-30 19:28:49,155 INFO tool.ImportTool: Incremental import based on column `id`
2022-09-30 19:28:49,155 INFO tool.ImportTool: No new rows detected since last import.
我们看一下作业的详细信息sqoop job --show job_import_city_incremental 我们发现last-value 是4079 ,也就是sqoop job 帮我们维护了这个值
verbose = false
hcatalog.drop.and.create.table = false
incremental.last.value = 4079
db.connect.string = jdbc:mysql://localhost/world
codegen.output.delimiters.escape = 0
codegen.output.delimiters.enclose.required = false
codegen.input.delimiters.field = 0
mainframe.input.dataset.type = p
split.limit = null
hbase.create.table = false
skip.dist.cache = false
hdfs.append.dir = true
db.table = city
7 Eval
下面介绍如何使用Sqoop 的 Eval 工具。它允许用户针对数据库服务器执行用户定义的查询,并在控制台中预览结果。所以,用户可以导入自定义查询的数据。使用eval,我们可以执行任何类型的SQL语句,可以是DDL或DML语句。以下语法用于Sqoop eval命令。
sqoop eval (generic-args) (eval-args)
查询语句
使用eval工具,我们可以评估任何类型的SQL查询。让我们举一个在db数据库的employee表中选择有限行的例子。以下命令用于评估使用SQL查询的给定示例。
sqoop eval \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234 \
--query "SELECT * FROM city LIMIT 5"
如果该命令执行成功,则它将在终端上产生以下输出。
---------------------------------------------------------------------------------
| ID | Name | CountryCode | District | Population |
---------------------------------------------------------------------------------
| 1 | Kabul | AFG | Kabol | 1780000 |
| 2 | Qandahar | AFG | Qandahar | 237500 |
| 3 | Herat | AFG | Herat | 186800 |
| 4 | Mazar-e-Sharif | AFG | Balkh | 127800 |
| 5 | Amsterdam | NLD | Noord-Holland | 731200 |
---------------------------------------------------------------------------------
插入语句
同理我们可以通过eval 执行插入,不过使用场景很少,上边的查询倒是经常用,不过主要是导出查询出的数据到HDFS的场景
8 列出数据库和表
这个没什么好介绍的,几乎不用,我们知道有这么个东西即可
列出数据库
sqoop list-databases \
--connect jdbc:mysql://localhost/ \
--username root \
--password www1234
information_schema
azkaban
batch
bdp
data_home
dolphinscheduler
......
列出特定库下面的表
sqoop list-tables \
--connect jdbc:mysql://localhost/world \
--username root \
--password www1234
结果如下
city
country
countrylanguage
扩展参数
由于sqoop 参数众多,所以我们在使用的时候可以根据具体情况去选择参数
import 参数
| 参数 | 说明 |
|---|---|
| –append | 将数据追加到hdfs中已经存在的dataset中。使用该参数,sqoop将把数据先导入到一个临时目录中,然后重新给文件命名到一个正式的目录中,以避免和该目录中已存在的文件重名。 |
| –as-avrodatafile | 将数据导入到一个Avro数据文件中 |
| –as-sequencefile | 将数据导入到一个sequence文件中 |
| –as-textfile | 将数据导入到一个普通文本文件中,生成该文本文件后,可以在hive中通过sql语句查询出结果。 |
| –boundary-query | 边界查询,也就是在导入前先通过SQL查询得到一个结果集,然后导入的数据就是该结果集内的数据,格式如:–boundary-query ‘select id,creationdate from person where id = 3’,表示导入的数据为id=3的记录,或者select min(), max() from ,注意查询的字段中不能有数据类型为字符串的字段,否则会报错:java.sql.SQLException: Invalid value for getLong()目前问题原因还未知
|
| –columns<col,col,col…> | 指定要导入的字段值,格式如:–columns id,username |
| –direct | 直接导入模式,使用的是关系数据库自带的导入导出工具。官网上是说这样导入会更快 |
| –direct-split-size | 在使用上面direct直接导入的基础上,对导入的流按字节数分块,特别是使用直连模式从PostgreSQL导入数据的时候,可以将一个到达设定大小的文件分为几个独立的文件。 |
| –inline-lob-limit | 设定大对象数据类型的最大值 |
| -m,–num-mappers | 启动N个map来并行导入数据,默认是4个,最好不要将数字设置为高于集群的节点数 |
| –query,-e | 从查询结果中导入数据,该参数使用时必须指定–target-dir、–hive-table,在查询语句中一定要有where条件且在where条件中需要包含$CONDITIONS,示例:–query ‘select * from person where $CONDITIONS ‘ –target-dir /user/hive/warehouse/person –hive-table person |
| –split-by | 表的列名,用来切分工作单元,一般后面跟主键ID |
| –table | 关系数据库表名,数据从该表中获取 |
| –target-dir
| 指定hdfs路径 |
| –warehouse-dir
| 与–target-dir不能同时使用,指定数据导入的存放目录,适用于hdfs导入,不适合导入hive目录 |
| –where | 从关系数据库导入数据时的查询条件,示例:–where ‘id = 2′ |
| -z,–compress | 压缩参数,默认情况下数据是没被压缩的,通过该参数可以使用gzip压缩算法对数据进行压缩,适用于SequenceFile, text文本文件, 和Avro文件 |
| –compression-codec | Hadoop压缩编码,默认是gzip |
| –null-string | 可选参数,如果没有指定,则字符串null将被使用 |
| –null-non-string | 可选参数,如果没有指定,则字符串null将被使用 |
增量导入 参数
| 参数 | 说明 |
|---|---|
| –check-column (col) | 用来作为判断的列名,如id |
| –incremental (mode) | append:追加,比如对大于last-value指定的值之后的记录进行追加导入。lastmodified:最后的修改时间,追加last-value指定的日期之后的记录 |
| –last-value (value) | 指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值 |
对incremental参数,如果是以日期作为追加导入的依据,则使用lastmodified,否则就使用append值。
export 参数
| 参数 | 说明 |
|---|---|
| –direct | 快速模式,利用了数据库的导入工具,如mysql的mysqlimport,可以比jdbc连接的方式更为高效的将数据导入到关系数据库中。 |
| –export-dir
| 存放数据的HDFS的源目录 |
| -m,–num-mappers | 启动N个map来并行导入数据,默认是4个,最好不要将数字设置为高于集群的最大Map数 |
| –table | 要导入到的关系数据库表 |
| –update-key | 后面接条件列名,通过该参数,可以将关系数据库中已经存在的数据进行更新操作,类似于关系数据库中的update操作 |
| –update-mode | 更新模式,有两个值updateonly和默认的allowinsert,该参数只能是在关系数据表里不存在要导入的记录时才能使用,比如要导入的hdfs中有一条id=1的记录,如果在表里已经有一条记录id=2,那么更新会失败。 |
| –input-null-string | 可选参数,如果没有指定,则字符串null将被使用 |
| –input-null-non-string | 可选参数,如果没有指定,则字符串null将被使用 |
| –staging-table | 该参数是用来保证在数据导入关系数据库表的过程中事务安全性的,因为在导入的过程中可能会有多个事务,那么一个事务失败会影响到其它事务,比如导入的数据会出现错误或出现重复的记录等等情况,那么通过该参数可以避免这种情况。创建一个与导入目标表同样的数据结构,保留该表为空在运行数据导入前,所有事务会将结果先存放在该表中,然后最后由该表通过一次事务将结果写入到目标表中。 |
| –clear-staging-table | 如果该staging-table非空,则通过该参数可以在运行导入前清除staging-table里的数据。 |
| –batch | 该模式用于执行基本语句(暂时还不太清楚含义) |
job 参数
| 参数 | 说明 |
|---|---|
| –create | 生成一个job |
| –delete | 删除一个jobsqoop job –delete myjob |
| –exec | 执行一个jobsqoop job –exec myjob |
| –help | 显示帮助说明 |
| –list | 显示所有的jobsqoop job –list |
| –meta-connect | 用来连接metastore服务,示例如:–meta-connect jdbc:hsqldb:hsql://localhost:16000/sqoop |
| –show | 显示一个job的各种参数sqoop job –show myjob |
| –verbose | 打印命令运行时的详细信息 |
总结
Sqoop 作为一个数据同步工具,主要用于关系型数据库和Hadoop的数据相互同步。
导入有两种模式:
- table 模式
- query 模式
job 主要解决了增量同步的元数据(last-value)维护问题,当然本身也可以用来做非增量的同步,ETL 中更常用的增量模式是通过query 来完成的,这是因为query 模式更加灵活