CS231n Module2: CNN part1:Architecture
目录
1. 前言
2. Architecture Overview
3. Layers used to build ConvNets
3.1 Convolutional Layer
3.1.1 基本运算
3.1.2 卷积运算
3.1.3 卷积层的参数个数
3.1.4 zero-padding
3.1.5 stride
3.1.6 output volumn的大小
3.1.7 Summary
3.2 Pooling Layer
3.2.1 Pooling处理概要
3.2.2 Backpropagation
3.2.3 Getting rid of pooling
3.3 Normalization Layer
3.4 Fully-connected layer
3.5 Converting FC layers to CONV layers
4. ConvNet Architectures
4.1 Layer Patterns
4.1.1 小的卷积核比大的卷积核好
4.1.2 卷积神经网络结构变种
4.1.3 实践小贴士:能搞定ImageNet的卷网就是好卷网
4.2 Layer Sizing Patterns
4.3 Case studies
4.3.1 LeNet
4.3.2 AlexNet
4.3.3 ZF Net
4.3.4 GoogLeNet
4.3.5 VGGNet
4.3.6 ResNet
4.4 Computational Considerations
5. Additional Resources
1. 前言
本文编译自斯坦福大学的CS231n课程(2022) Module2:卷积神经网络。Module2包含3部分:
- part1: CNN: Architectures, Convolution / Pooling Layers
- layers, spatial arrangement, layer patterns, layer sizing patterns, AlexNet/ZFNet/VGGNet case studies, computational considerations
- part2: Understanding and Visualizing Convolutional Neural Networks
- tSNE embeddings, deconvnets, data gradients, fooling ConvNets, human comparisons
- part3: Transfer Learning and Fine-tuning Convolutional Neural Networks
本文是其中第一部分,介绍卷积神经网络的基本结构。原课件参见:CS231n Convolutional Neural Networks for Visual Recognition
本系列不是对原始课件网页内容的完全翻译,只是作为学习笔记的摘要总结,主要是自我参考,而且也可能夹带一些私货(自己的理解和延申,不保证准确性)。如果想要了解更具体的细节,还请服用原文。如果本摘要恰巧也对小伙伴们有所参考则纯属无心插柳概不认账^-^。Module1的内容参考:CS231n Module1: 神经网络1:Setting Up the Architecture。
卷积神经网络在很多方面与此前讨论的常规(全连接)神经网络(以下简记为DNN,D代表Dense,密集连接的意思)都相似:
(1) 都是由神经元构成,每个神经元有可学习的权重参数和bias
(2) 神经元接收输入数据执行点积运算并(optionally)后跟非线性激励函数
(3) 整个网络表达一个单一的可微score函数,一端输入由像素都成的图像数据,另一端输出分类分数
(4) 在最终层后有损失函数 (e.g. SVM/Softmax)计算
(5) 为常规神经网络训练所开发的小贴士/小技巧(tips/tricks)依然有效
那到底什么变化了呢?根本的变化是,CNN关于输入数据有一个明显的假设,即输入是图像数据,这就使得我们对神经网络结构进行特定的调整,使得前向计算更加高效并且极大幅度地减少参数个数。
2. Architecture Overview
在常规(全连接)神经网络中,同一层中的所有各节点之间是完全相互独立的。
常规(全连接)神经网络不适合于处理图像数据(don’t scale well to full images),因为参数太多了!在CIFAR-10中图像大小为 32x32x3 (32 wide, 32 high, 3 color channels), 所以第1个隐藏层的各节点将有32*32*3 = 3072个权重参数,这个数字看上去似乎还可以接受。但是考虑一张稍大一些的图像,200x200x3, 参数个数飙升为200*200*3 = 120,000。我的手机相机拍摄的图像尺寸为3072*4096*3,参数个数将达到惊人的37,748,736,而这仅仅是第1个隐藏层的一个节点的权重参数!
3D volumes of neurons
图像数据并不是3*W*H个随机的像素数据的排列,这些像素数据之间是存在一定的约束关系的。而CNN正是利用了图像数据的这一特征而采取了更加合理的神经网络结构。与常规(全连接)神经网络不同的是,CNN将神经元节点以三维的方式排列,即每个CNN层有三个维度:width, height, depth. (注意,这里的 depth 不是指整个神经网络的深度或者说层数,而是指 the third dimension of an activation volume) 。比如说,CIFAR-10的输入数据是32*32*3,可以看作是一个维度为 32x32x3 (width, height, depth respectively)的volumn(翻成啥合适呢?多维体?).
简而言之,CNN的每一层的作用就是基于某种可微函数(可能有参数也可能没有参数)将一个输入三维体(3D volume)变换成一个输出三维体 ,如下图所示:

左:常规3层神经网络;右:CNN的维度变化示意图
3. Layers used to build ConvNets
CNN也是一层一层堆叠起来的,三种主要的构建CNN的layers包括(当然,与DNN类似的是,所有中间隐藏层都带有激励函数层):
(1) 卷积层:Convolutional Layer
(2) 池化层:Pooling Layer
(3) 全连接层:Fully Connected Layer
比如说,一个用于CIFAR-10分类的卷积神经网络大致会具有这样的结构:[INPUT - CONV - RELU - POOL - FC]:
- INPUT [32x32x3] 代表输入层,它对应输入图片的大小.
- CONV层执行卷积核与其对应的input volumn之间的卷积运算,并执行沿深度这个维度的累加(其效果是将depth压缩为1);然后再将多个卷积核的卷积运算结构沿深度这个维度串联,重新扩张深度这个维度。举例来说,如果卷积层包括12个卷积核,它与大小为 [32x32x3]的input volumn运算后得到大小[32x32x12]的output volumn.
- RELU层的作用与在DNN中是一样,以elementwise的方式为每个神经元节点提供非线性,它不改变volumn size(dimensions)。
- POOL(池化)层相当于沿空间维度(spatial dimensions (width, height))做一个下采样处理,其作用是确保整个volumn的“体积”得到控制,不至于“爆炸”.
- FC (i.e. fully-connected) 全连接层用于计算class scores, 其结果为volume of size [1x1x10],其连接方式与在常规网络中相同(它的每个神经元都与上一层的所有神经元相连接)
RELU层和POOL层不包含参数。而CONV/FC层有参数用于学习。此外,CONV/FC/POOL还有额外的超参数,而RELU没有。如下图所示为一个迷你的VGG卷积神经网络的各层激活函数值示意图。最左侧的input volume储存原始图像数据,最后一层储存class scores。
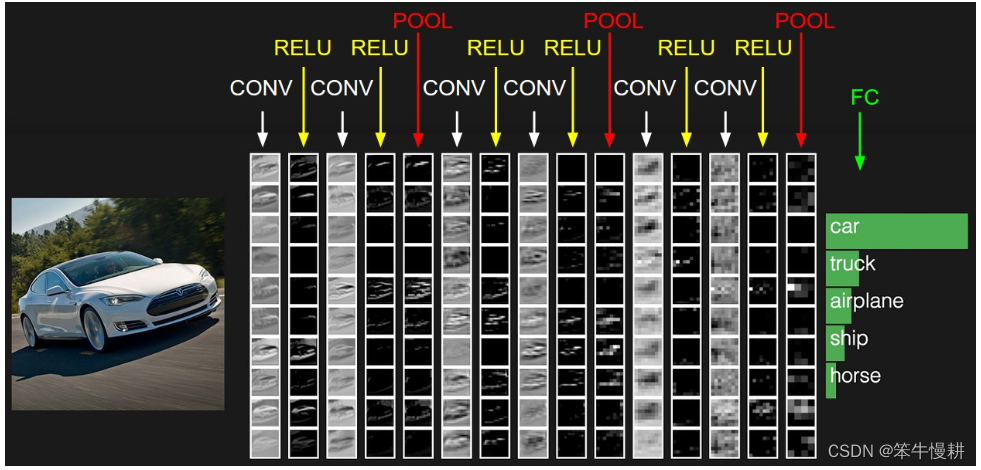
接下来针对各种CNN中各种常见的层分别进一步描述。
3.1 Convolutional Layer
3.1.1 基本运算
假定一个卷积层的输入是大小为[W1,H1,D1]的input volumn,卷积核的大小为[F,F]。那么该卷积核所执行的最基本的运算是从input volumn中取一个大小[F,F,D1]的(暂记为)local volumn,然后执行以下运算(其实就是一个dot-product):
其中,表示data point of local volumn,
表示卷积核中的参数元素,
表示bias。需要注意的是,当我们说“卷积核的大小为[F,F]”时,并不是说它是一个2维的东西,卷积核的深度跟随input volumn,所以实际上该卷积核的大小为[F,F,D1]。也正是应为其深度跟随input volumn(或者说由input volum决定),所以通常只用W和H这两个维度值来指代它。
3.1.2 卷积运算
以上运算只得到了一个数值。在W和H这两个维度以平移的方式取不同的local volumn与卷积核执行以上运算(反过来可以说,让卷积核在input volumn上沿W和H这两个维度平移并与对应位置的local volumn进行运算)即可得到一个2维的result volumn(注意不对depth这个维度进行遍历,depth这个维度在以上乘累加运算中被消灭了)。这就完成了一个卷积核与input volumn的卷积运算(从信号处理领域看过来的伙伴们会说,这算哪门子卷积嘛,这分明就是相关嘛。。。好吧,就这样,可能由于历史的原因,深度学习社区就是这么个叫法。到深度学习的地盘上来,得按深度学习的家伙们定的规矩办事^-^)。
一个卷积层通常有多个卷积核(假定记为K个),每个卷积核(分别有不同的参数)执行以上相同运算,每个卷积核都得到一个2维的result volumn,然后将这些2维的result volumn沿深度方向堆叠到一起就得到了一个3维的output volumn。
3.1.3 卷积层的参数个数
如果一个卷积层有K个大小为[F,F]的卷积核,而它的input volumn的深度为,则该卷积层的总的参数个数为(其中“+1”是因为每个卷积核有一个bias参数):
注意,卷积核的深度跟随input volumn的深度!
3.1.4 zero-padding
假定卷积核在input volumn的W和H两个维度上是逐个pixel移动,很显然如果卷积核只在input volumn的W和H这两个维度的框内移动的话,W这个维度不同的可能位置数只有个(H维度上同理),这样单个卷积核与input volumn进行卷积所得到的result volumn就是
,比input volumn的W/H维度的大小要小一些。通常,人们希望卷积输出与输入在W/H这两个维度保持相同,为此而采用的处理技巧叫zero-padding。对input volumn在W维度上左右两边分别填
个0,同理在H维度上左右两边分别填
个0,然后再执行以上卷积处理,这样就得到了大小为
的result volumn。
通用的深度学习库的CONV函数会带有一个指定是否进行zero-padding的参数,通常参数取值为‘same’和'valid',‘same’表示执行zero-padding,而‘valid’表示不执行。
3.1.5 stride
以上讨论,假定卷积核在input volumn的W和H两个维度上是逐个pixel移动。但是事实上,也可以跳着移动。跳的步幅称为stride。逐个pixel移动相当于stride=1。
事实上,由于stride的效果与后面要讲到的pooling的效果几乎相同。
3.1.6 output volumn的大小
卷积层的输出是由各个卷积核的处理结果沿depth这个维度堆叠而成。因此,output volumn的W和H这两个维度的大小由上面3.1.4和3.1.5的处理结果所决定,Depth这个温度的大小取决于所用的卷积核的个数K决定!
3.1.7 Summary
To summarize, the Conv Layer:
- Accept input volume of size W1×H1×D1
- 四个超参数:
- Number of filters K,
- their spatial extent F,
- the stride S,
- zero padding类型:'same'; 'valid'.
- Output volume size: W2×H2×D2, where:
(i.e. width and height are computed equally by symmetry)
- 其中P取决于zero padding类型,valid时P=0;same时P取值使得W2=W1, H2=H1
- 每个卷积核的参数个数为
,所以卷积层的总的参数个数为
.
一个常见的卷积核超参数配置是{ F=3,S=1,P=1},通常记为conv3x3。
3.2 Pooling Layer
3.2.1 Pooling处理概要
Pooling layer(池化层)的作用简单明了,就是降低representation volumn在W和H这两个维度的大小,并因此减少参数数量,降低模型复杂度和运算量,也有助于帮助克服过拟合。
Pooling层同样有F(filter spatial extent)和S(stride)超参数也有,但是没有zero-padding。Pooling层所做的“滤波”处理通常有:
(1) Max,取最大值
(2) Average,取平均值
(3) others,such as L2-norm pooling
但是,最常用的就是Max-pooling,后两者都很少见。
Pooling{F,S}的输入为,其输出volumn的大小为
:
Pooling层没有可学习参数,它对输入执行固定的函数处理。
常见的{F,S}的两种取值为 (1) F=3,S=2 (also called overlapping pooling); (2) F=2,S=2。后者更为常见。
Polling层处理示意图如下:
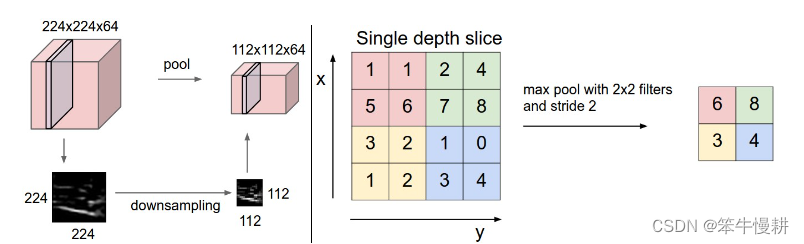
Pooling层对input volumn的W/H这两个维度进行等效于下采样的处理。
左: 对 input volume of size [224x224x64] 进行[F=2,S=2]的pooling处理,得到 output volume of size [112x112x64]。注意,pooling处理不影响volume depth.
右:max pooling, 取pooling核当前“视野”中的最大值.
3.2.2 Backpropagation
在前面章节我们已经知道了,对于max(x,y)处理的反向传播处理有一个很简明的解释:routing the gradient to the input that had the highest value in the forward pass,即将关于在forward pass中所选取的最大值的梯度向后传播。因此,在forward pass中,通常会将pooling layer所选取的最大值的索引保存下来以提高backward pass处理效率。
3.2.3 Getting rid of pooling
有些研究者在考虑去除掉pooling层,比如说, Striving for Simplicity: The All Convolutional Net。在这种情况下,通过将stride设为大于1来达到pooling相同的降低representation volumn的大小的目的。此外,研究者还发现抛弃pooling层对于像VAEs、GANs等生成模型的训练很重要。未来的卷积神经网络结构也许会更少甚至于完全不使用pooling层。
3.3 Normalization Layer
面向卷积神经网络有过很多种normalization layers的提案,但是都被证明没有什么显著的好处。关于各种类型的normalizations, 可参考 Alex Krizhevsky’s cuda-convnet library API.
3.4 Fully-connected layer
顾名思义,全连接层(或者也有称密集连接层)就是当前层的每个节点都与前一层的所有层都连接的神经网络层。通常在卷积神经网络的最后阶段需要使用全连接层将特征信息转换成常规学习任务所需要的信息。
3.5 Converting FC layers to CONV layers
卷积层之区别于全连接层的关键的两点:
(1) 卷积层的每个神经元只与上一层的局部区域连接
(2) 卷积层的神经元之间有参数共享
除此之外,它们的计算方式非常相似,都是计算点积(dot products)。因此,全连接层和卷积层之间可以进行相互转换。
- 对于任何卷积层,都能找到一个实现等价功能的全连接层。只不过等价全连接层的权重矩阵将是一个非常大的稀疏矩阵(对应于上述局部连接),而且很多局部块的参数都一样(对应上述参数共享特征).
- 反过来,任何全连接层都能转换为等价的卷积层。以一个K=4096,输入volumn为{7,7,512}的全连接层为例,可以等价地表达为卷积层{F=7,P=0,S=1,K=4096} 。其中,卷积层的kernel size对应于输入volumn的{W,H},然后卷积核个数则等于全连接层的神经元个数。
关于将AlexNet的最后几层全连接层转化为卷积层的实现例参见原文。
但是,这种转换的实用价值在哪儿呢?
4. ConvNet Architectures
根据以上讨论,我们知道卷积神经网络通常由卷积层(CONV)、池化层(POOL,缺省使用MaxPool,除非特别指明)和全连接层(FC)。有时也把激励函数比如说RELU列为单独的层。本节讨论如果将这些不同的层堆叠起来构成卷积神经网络。
4.1 Layer Patterns
最常见的卷积神经网络结构如下所示:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
其中:
* 表示重复
POOL? 表示可选的POOL层
通常来说, N >= 0 (and usually N <= 3), M >= 0, K >= 0 (and usually K < 3).
以下为几个常见的例子:
INPUT -> FC, implements a linear classifier. HereN = M = K = 0.INPUT -> CONV -> RELU -> FCINPUT -> [CONV -> RELU -> POOL]*2 -> FC -> RELU -> FC:每个卷积层后都跟POOL层INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL]*3 -> [FC -> RELU]*2 -> FC:每两个卷积层后跟一个POOL层.
4.1.1 小的卷积核比大的卷积核好
以CONV{3,3}和CONV{7,7}的对比为例。
三个CONV{3,3}的级联可以得到和一个CONV{7,7}相当的“视野(receptive field)”。但是:
首先,由于三个CONV{3,3}之间可以插入两个非线性激励函数,所以可以获得比CONV{7,7}更强的表现能力(表现能力主要就是靠非线性激励函数贡献的)。
其次,考虑所有的中间的volumns都是C个通道。一个CONV{7,7}的参数个数为;另一方面,三个CONV{3,3}级联的话,总的参数个数为
。小的卷积核级联的方案的总参数个数更少。
用更少的可学习参数来获得更好的表现能力,简直就是“既要马儿跑的好,又要马儿不吃草”。当然,没有免费的午餐,小卷积核级联方案当然必需有它的缺点:在反向传播中需要更多的内存来存储各层的信息(反向传播所需要的信息必需每层存储,而级联方案显然有更多的层数)。
4.1.2 卷积神经网络结构变种
在后面的case-study中我们将看到研究者们在以上线性堆叠基本结构的几处提出了一些有趣的变种,比如说Google’s Inception architectures,微软亚洲的Residual Networks等等.
4.1.3 实践小贴士:能搞定ImageNet的卷网就是好卷网
卷积神经网络结构设计中,绝大多数情况下不需要重新发明轮子,不需要去当英雄(“don’t be a hero”)。找当前在ImageNet上表现最好的网络结构就好了。下载一个预训练模型,然后针对你自己的数据做一些微调。。。工程应用开发的绝大多数场合下这就够了。
4.2 Layer Sizing Patterns
卷积神经网络的设计中,确定基本结构之后就需要需要确定各层的volumn size的调节。这里size主要是指spatial dimensions(即{W,H}),可以看作是超参数。
常规的做法是:
(1) 输入层的(W,H)应该是偶数
(2) 使用较小的卷积核,比如说3x3 或者偶尔5x5,使用S=1(stride),使用“same”模式(zero padding使得输出volumn的(W,H)等于输入volumn的(W,H)),即是说,, with F is odd。Padding不仅仅是用于保持输入输出volumn size不变,而且还有现实的性能的好处,因为zero-padding能够避免边沿的信息受损失
(3) 使用POOL{2,2}用于降低input volumn的spatial dimensions(即{W,H})
(4) 根据内存约束进行折中取舍。卷积神经网络训练中,内存通常是一个制约瓶颈。考虑一个输入图像大小为224x224x3,用64个CONV{3,3}构成的卷积层进行处理将产生[224x224x64]大小的输出volumn,考虑前向传播的数据和反向传播的梯度的存储,每张图像需要大约72MB的内存。所以考虑网络结构(w.r.t layer sizing)必需把可用内存资源的因素考虑进去。
4.3 Case studies
有很多卷积神经网络结构由于它们在卷积神经网络发展历史上的影响力而获得了专有的名字,最常见的有以下几种:
4.3.1 LeNet
第一个成功的卷积神经网络,由Yann LeCun(2018年图灵奖得主之一)开发。是面向用于邮政系统识别zip codes, digits等而开发的。
4.3.2 AlexNet
AlexNet由Alex Krizhevsky, Ilya Sutskever and Geoff Hinton(2018年图灵奖得主之一)开发。在 the ImageNet ILSVRC challenge in 2012取得了突破性的成绩(top 5 error of 16% compared to runner-up with 26% error),并由此掀起了卷积神经网络热潮。
AlexNet的结构与LeNet相似,但是更深、更大,采用多层堆叠的结构(在此之前的卷积神经网络基本上都是只有一个卷积层加一个POOL层)。
4.3.3 ZF Net
The ILSVRC 2013 winner was a Convolutional Network from Matthew Zeiler and Rob Fergus. It became known as the ZFNet (short for Zeiler & Fergus Net). It was an improvement on AlexNet by tweaking the architecture hyperparameters, in particular by expanding the size of the middle convolutional layers and making the stride and filter size on the first layer smaller.
4.3.4 GoogLeNet
The ILSVRC 2014 winner was a Convolutional Network from Szegedy et al. from Google. Its main contribution was the development of an Inception Module that dramatically reduced the number of parameters in the network (4M, compared to AlexNet with 60M). Additionally, this paper uses Average Pooling instead of Fully Connected layers at the top of the ConvNet, eliminating a large amount of parameters that do not seem to matter much. There are also several followup versions to the GoogLeNet, most recently Inception-v4.
4.3.5 VGGNet
The runner-up in ILSVRC 2014 was the network from Karen Simonyan and Andrew Zisserman that became known as the VGGNet. Its main contribution was in showing that the depth of the network is a critical component for good performance. Their final best network contains 16 CONV/FC layers and, appealingly, features an extremely homogeneous architecture that only performs 3x3 convolutions and 2x2 pooling from the beginning to the end. Their pretrained model is available for plug and play use in Caffe. A downside of the VGGNet is that it is more expensive to evaluate and uses a lot more memory and parameters (140M). Most of these parameters are in the first fully connected layer, and it was since found that these FC layers can be removed with no performance downgrade, significantly reducing the number of necessary parameters.
VGGNet 由很多CONV{F=3,S=1,P=1}以及 MaxPOOL{F=2, S=2, P=0}构成,它的主要结构参数如下所示:
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
如上所示,与绝大多数其它卷积神经网络结构相同的是,绝大多数的内存需求(相应地,计算时间)都被前面几级CONV层所消耗,而参数个数的绝大部分则是最后几级FC层所贡献。在本例中,第一个FC层的参数个数达到100M(1亿!)个,而整个网络的总的参数量则是140M(1.4亿)。
4.3.6 ResNet
ResNet是由 Kaiming He et al等开发,是 ILSVRC 2015 的优胜者。它的特点在于以下两点:
(1) special skip connections
(2) 大量使用了 batch normalization.
此外,ResNet还取消了最后的全连接层。
参考:Kaiming’s presentation (video, slides), some recent experiments that reproduce these networks in Torch, Kaiming He et al. Identity Mappings in Deep Residual Networks (published March 2016), 等等
4.4 Computational Considerations
卷积神经网络实现的最大瓶颈是内存瓶颈(memory bottleneck)。主要有以下三个因素决定卷积神经网络所需要的内存:
- 中间层volumn大小(intermediate volume sizes): 这个对应于各卷积层的原始激励输出数以及各自对应的梯度值。通常来说,靠前的卷积层(比如说,第一级)的激励输出数占主要部分。这些数据必须保存下来用于反向传播计算。But, a clever implementation that runs a ConvNet only at test time could in principle reduce this by a huge amount, by only storing the current activations at any layer and discarding the previous activations on layers below.
- 参数量(个数): 针对每个参数,必需要存储参数本身,梯度(反向传播),以及当使用momentum, Adagrad, or RMSProp等参数更新方法时还需要存储对应的step值。因因此参数相关的内存需求大致为(#参数个数 * 3)
- 其它各种存储需求,比如说用于存储image data batches、可能还有它们对对应的增强数据等等
一旦根据卷积神经网络结构大致确定了内存需求后,先转换为字节单位的数值(一个浮点数值占32比特,4个字节;一个双精度数值占64比特,8个字节,等等)并除以1024一次或多次以得到KB(千字节)、MB(兆字节)、GB(Giga字节)、单位的数值,然后与训练机器的内存容量做对比(GPUs 通常有数GB的内存,有的甚至有十几GB的内存)。
如果内存需求超过了GPU的内存容量,那你需要采取什么措施。最常用的办法就是降低batch size,因为通常来说最耗内存的就是激励输出
5. Additional Resources
Additional resources related to implementation:
- Soumith benchmarks for CONV performance
- ConvNetJS CIFAR-10 demo allows you to play with ConvNet architectures and see the results and computations in real time, in the browser.
- Caffe, one of the popular ConvNet libraries.
- State of the art ResNets in Torch7