【吴恩达深度学习】——NLP和Word Embedding
NLP和词嵌入
- 思维导图
- 词汇表征
- one-hot表征
- 特征表征:词嵌入
- 使用word Embeddings
- 命名实体识别的例子:
- 词嵌入的迁移学习:
- 词嵌入和人脸编码
- 词嵌入的特性
- 类比推理的特性
- 相似度函数:
- 嵌入矩阵
- 学习词嵌入
- 其它的上下文和目标词对
- Word2Vec
- Skip-grams:
- 模型流程
- 存在的问题
- 如何采样上下文
思维导图

词汇表征
在前面的学习内容中,我们来表征一个词汇是直接使用英文单词来进行表征的,但是对于计算就而言,是无法直接识别单词的,为了让计算机能更好的理解人类语言,建立更好的语言模型,我们需要对词汇进行表征,下面是几种不同的词汇表征方式
one-hot表征
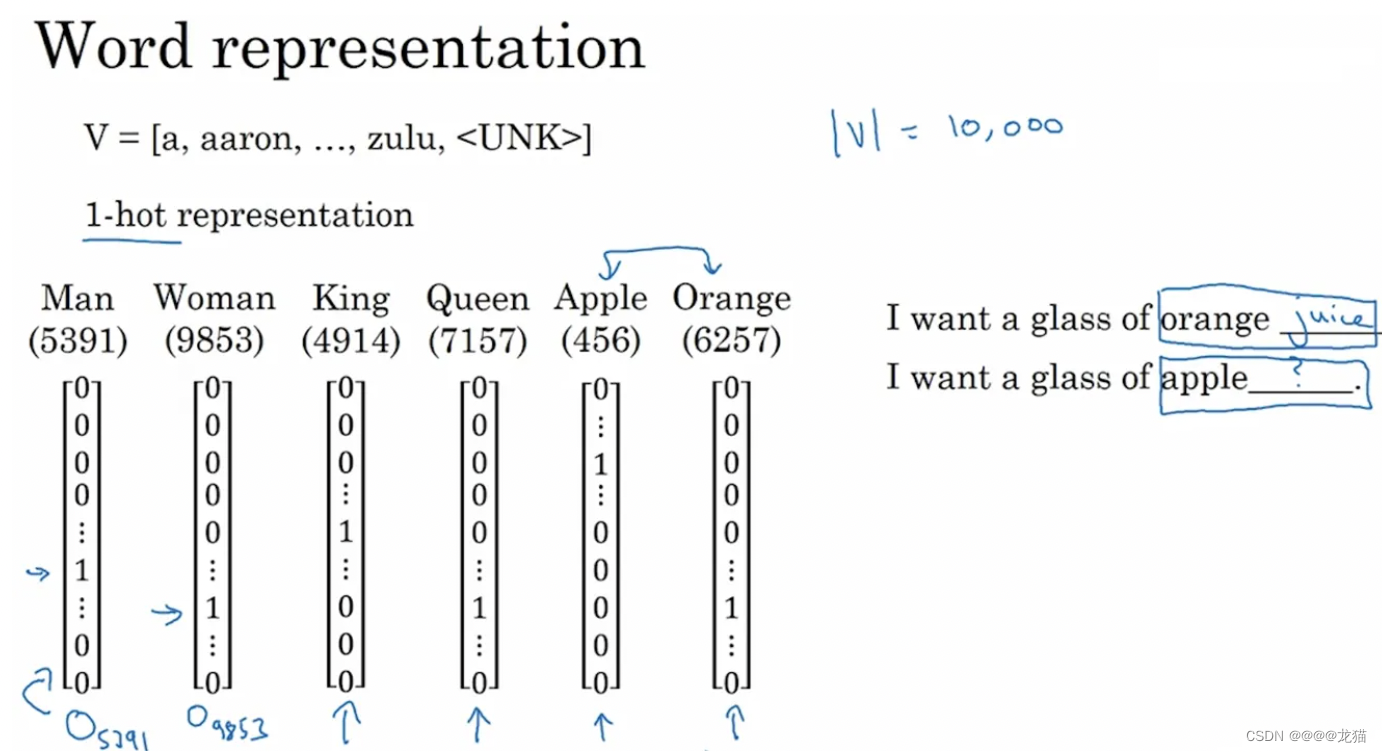
我们用one-hot表征的方式对模型字典中的单词进行表征,对应的单词的位置用1表示,其余位置用0去表示,如下图所示:
缺点:
以10000个词为例,每个单词需要用10000维来表示,而且只有一个数是0,其它维度都是1,造成非常冗余,存储量大
每个词表示的向量相乘都为0,导致没能够表示出词汇之间的联系,比如orange和apple应该是联系紧密的,但是用上面的词典表示无法体现出这一点
特征表征:词嵌入
用不同的特征来对各个词汇进行表征,相对于不同的特征,不同的单词均有不同的值
这种表征方式使得词与词之间的相似性很容易表征出来,这样对于不同的单词,模型的泛化性能会好很多,下面使用t-SNE算法将高维的词向量映射到2维空间,进而对词向量进行可视化,很明显可以看出对于相似的词总是聚集在一块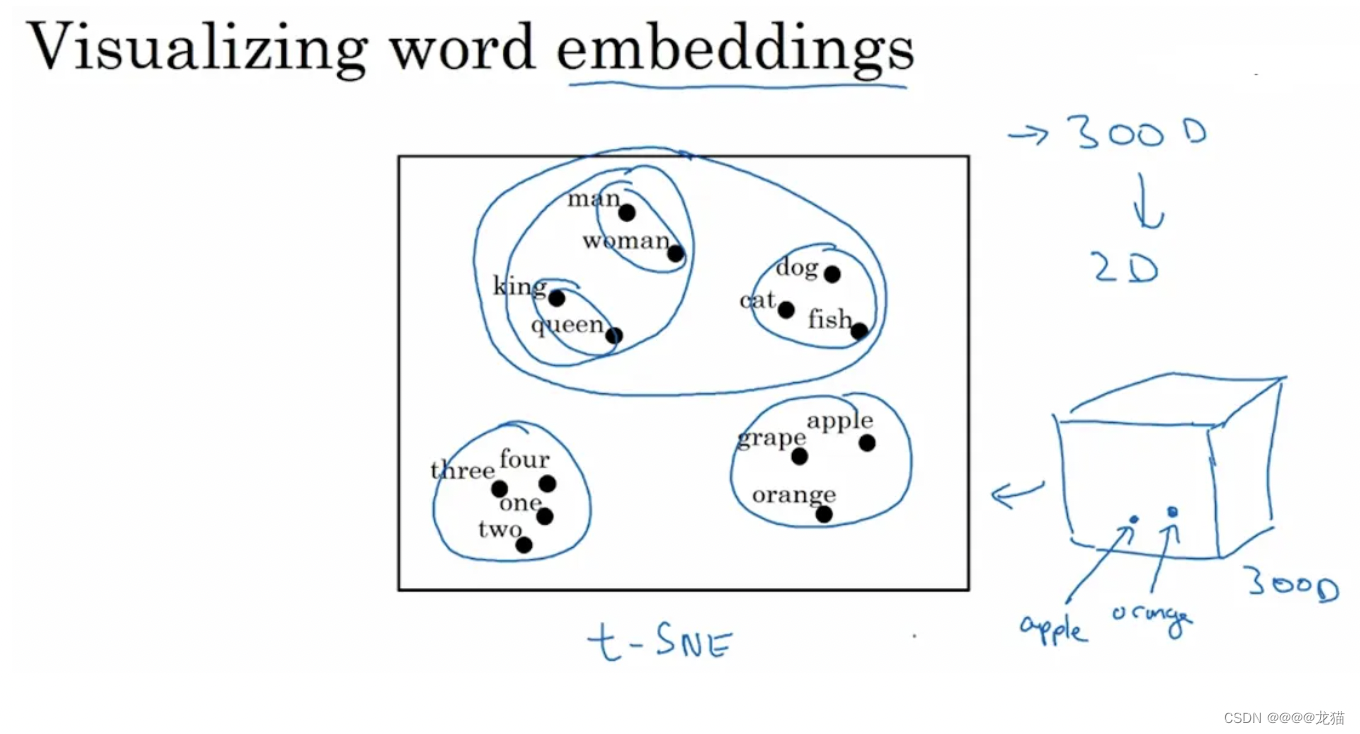
使用word Embeddings
Word Embeddings对不同单词进行了特征化的表示,那如何将这种表示方法应用到自然语言处理的应用中呢?
命名实体识别的例子:
如下面的一个句子中名字实体的定位识别问题,假如我们有一个比较小的数据集,可能不包含durain(榴莲)和cultivator(培育家)这样的词汇,那么我们就很难从包含这两个词汇的句子中识别名字实体。但是如果我们从网上的其他地方获取了一个学习好的word Embedding,它将告诉我们榴莲是一种水果,并且培育家和农民相似,那么我们就有可能从我们少量的训练集中,归纳出没有见过的词汇中的名字实体。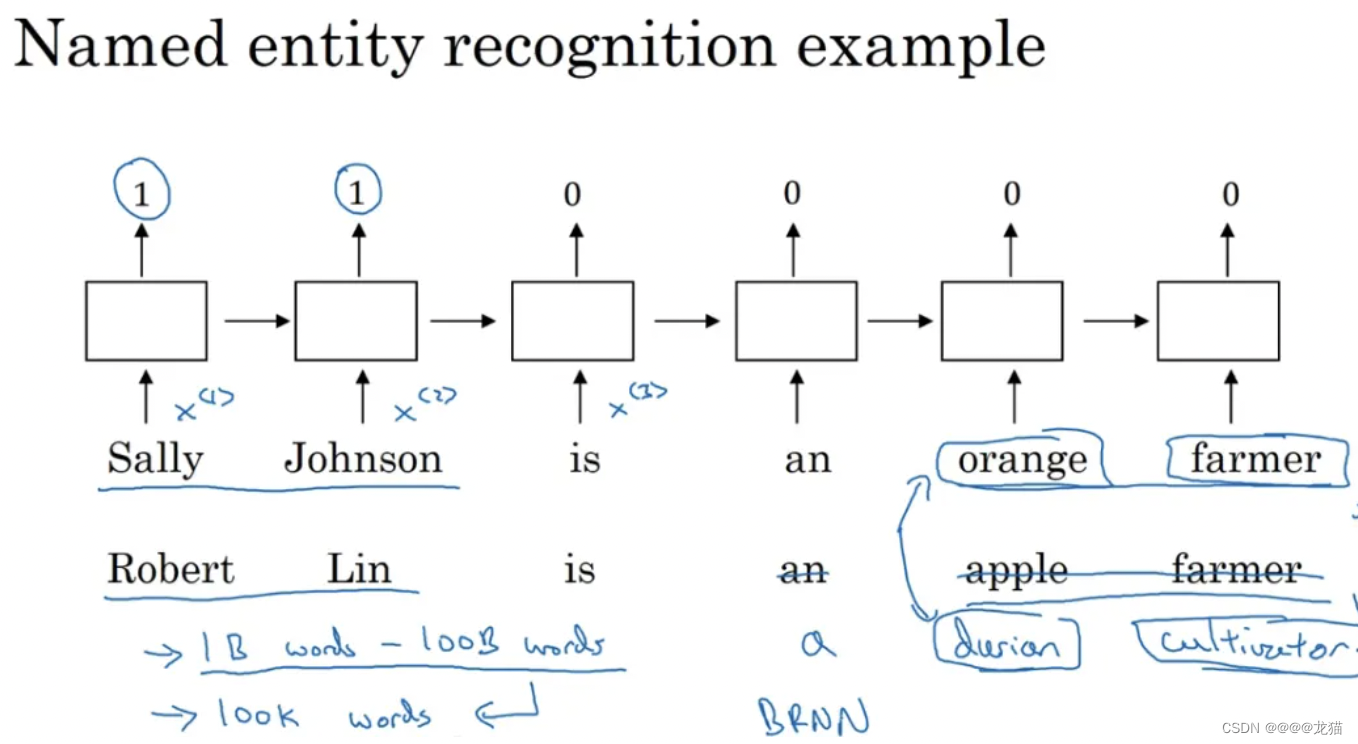
词嵌入的迁移学习:
有了词嵌入,我们就可以使用迁移学习,通过网上大量的无标签的文本中学习到知识,应用到我们少量文本训练集的任务中,下面是做迁移学习的步骤:
第一步:先从大量文本集合中学习词嵌入(词嵌入就是用一些特征来表示一个词汇,而不是通过one-hot表示),当然也可以直接使用别人预训练好的词嵌入模型
第二部:将词嵌入模型迁移到我们小训练集的新任务集
第三步:根据新任务的数据量来决定是否还要调整这些词嵌入,如果数据量很少的话,直接使用之前的词嵌入,数据多的话可以使用新的标记数据对词嵌入模型继续进行微调
词嵌入和人脸编码
词嵌入和人脸编码之间有很奇妙的联系,在人脸识别领域,我们会将人脸图片预编码成不同的编码向量,以表示不同的人脸,进而在识别的过程中使用编码来进行比对识别。词嵌入和人脸编码是有一定的相似性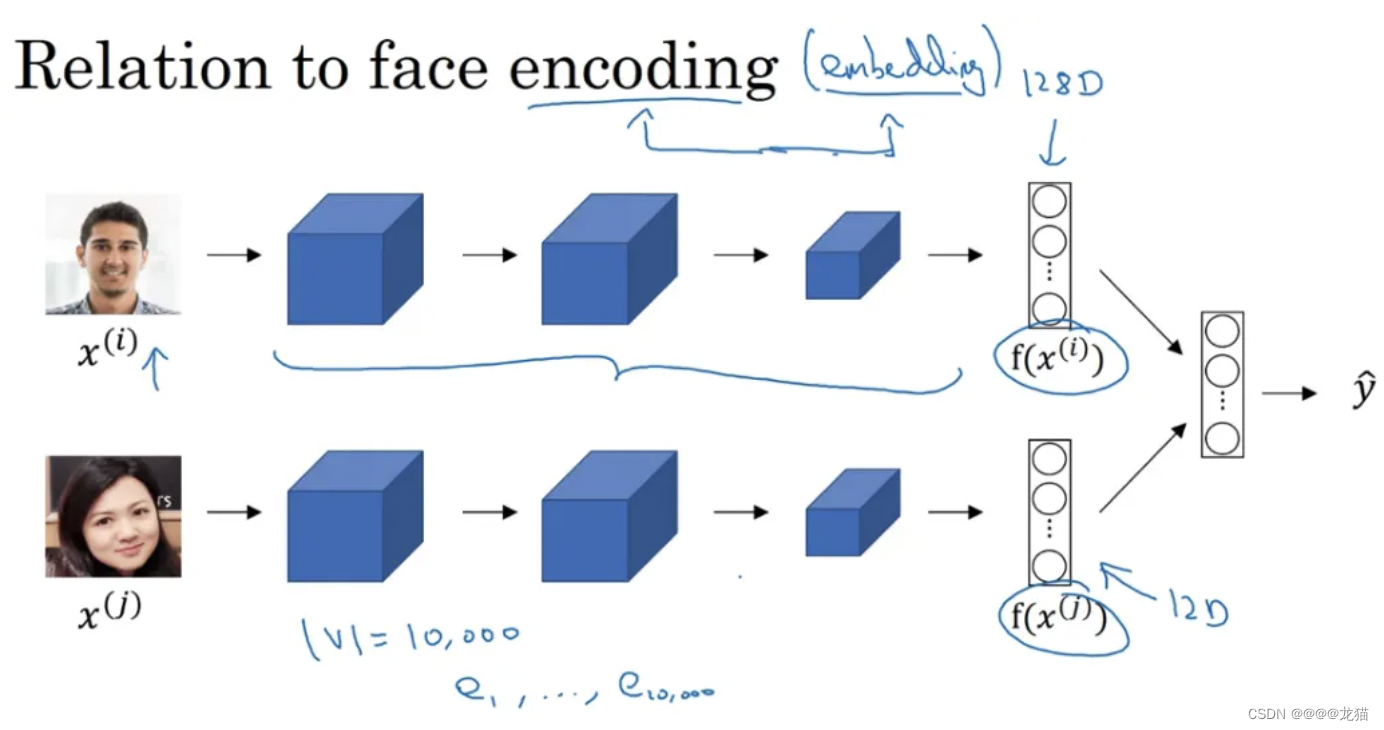
区别:
对于人脸识别,我们可以将任意一个没有见过的人脸照片输入到我们到我们构建的网络中,则可输出一个对应的人脸编码,而在词嵌入模型中,所有词汇的编码是在一个固定的词汇表中进行学习单词的编码以及其之间的关系
词嵌入的特性
类比推理的特性
词嵌入还有一个重要的特性,它能够帮助实现类比推理,如下面的例子中,通过不同词向量之间的相减计算,可以发现不同词之间的类比关系,man-woman,king-queen,如下图所示:
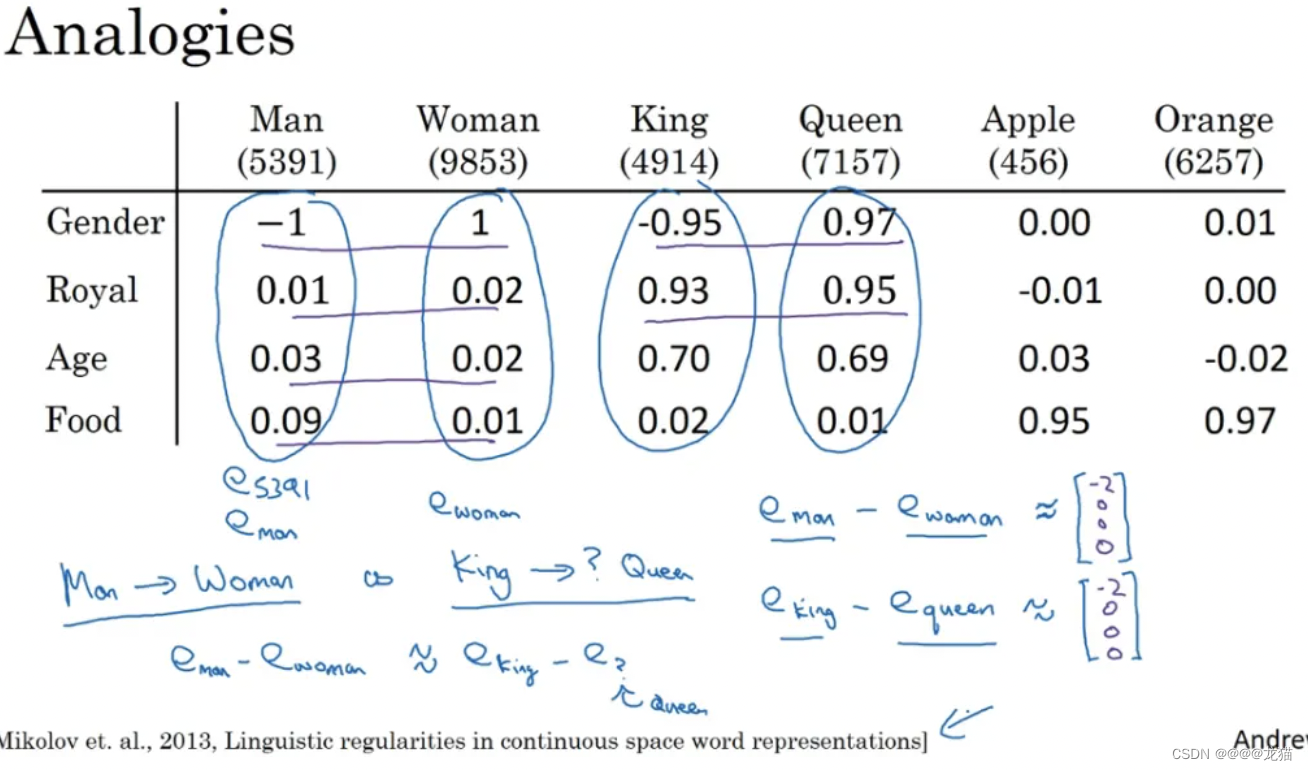
这种思想帮助研究者们对词嵌入建立更加深刻的理解和认识
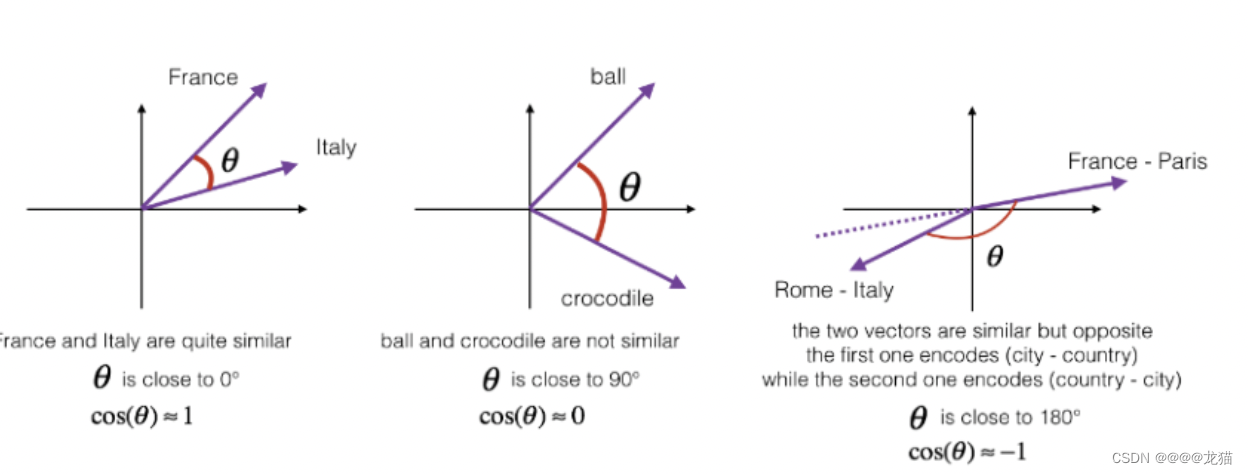
计算词与词之间的相似度,实际是在多维空间中,寻找词向量之间各个维度的距离相似度。

以上面的单词:
e
m
a
n
−
e
w
o
m
a
n
≈
e
k
i
n
g
−
e
?
e_{man}-e_{woman} \approx e_{king}-e_?
eman−ewoman≈eking−e?
对于上面的式子,我们寻找
e
?
e_?
e?,则相当于寻找下面两个结果的向量之间的最大相似度:
a
r
g
m
a
x
s
i
m
(
e
?
,
e
k
i
n
g
−
e
m
a
n
+
e
w
o
m
a
n
)
argmax sim(e_?,e_{king}-e_{man}+e_{woman})
argmaxsim(e?,eking−eman+ewoman)
相似度函数:
余弦相似度函数:也就是向量
u
u
u和
v
v
v的内积
s
i
m
(
u
,
v
)
=
u
T
v
∣
∣
u
∣
∣
2
∣
∣
v
∣
∣
2
sim(u,v)=\frac{u^{T}v }{||u||_{2}||v||_2 }
sim(u,v)=∣∣u∣∣2∣∣v∣∣2uTv
欧式距离:
∣
∣
u
−
v
∣
∣
2
||u-v||^2
∣∣u−v∣∣2
嵌入矩阵
如果词汇量是10000,每个词汇由300个特征表示,那么嵌入矩阵就是一个300*10000的矩阵,嵌入矩阵与某个词汇的one-hot表示的向量相乘会得到该词汇的嵌入表示(即300维表示)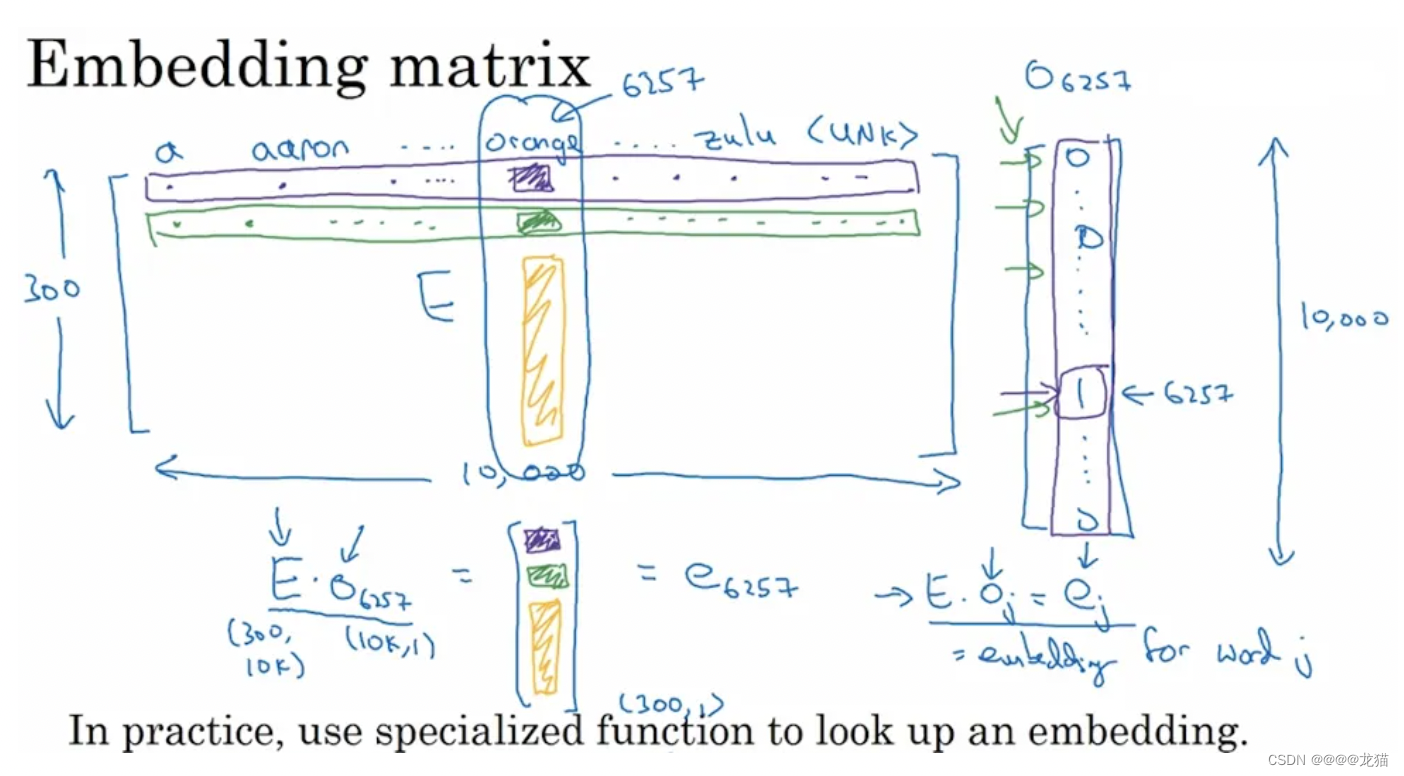
上面的相乘由于one-hot只有特定的值是1,所以相乘的本质是取出该词汇在嵌入矩阵的位置的那一列,实际中不会进行这么复杂的矩阵乘法运算,而是用其它方法直接取出那一列
学习词嵌入
词嵌入的学习算法随着时间的进行逐渐变得越来越简单
早期的学习算法:
- 通过将每个单词的one-hot向量与嵌入矩阵相乘,得到相应的Embedding
- 利用窗口控制影响预测结果的单词数量,并将窗口内的单词Embedding堆叠起来,输入到神经网络中
- 最后通过softmax层输出曾哥词汇表各个单词的概率
- 其中,隐藏层和softmax层都有自己的参数,假设词汇表的大小为10000,每个单词的Embedding的大小是300,历史窗口的大小是4,那么输入的大小就是1200,softmax的输出大小就是词汇表的大小
- 整个模型的参数就是嵌入矩阵E,以及隐藏层和softmax层的参数 w [ 1 ] , b [ 1 ] , w [ 2 ] , b [ 2 ] w^{[1]},b^{[1]},w^{[2]},b^{[2]} w[1],b[1],w[2],b[2]
- 可以利用反向传播算法进行梯度下降,最大化训练极大似然函数,不断地从语料库中预测最后一个词的输出
在不断训练的过程中,算法会发现想要最好拟合训练集,就要使得一些特性相似的词汇具有相似的特征向量,从而得到最后的词嵌入矩阵E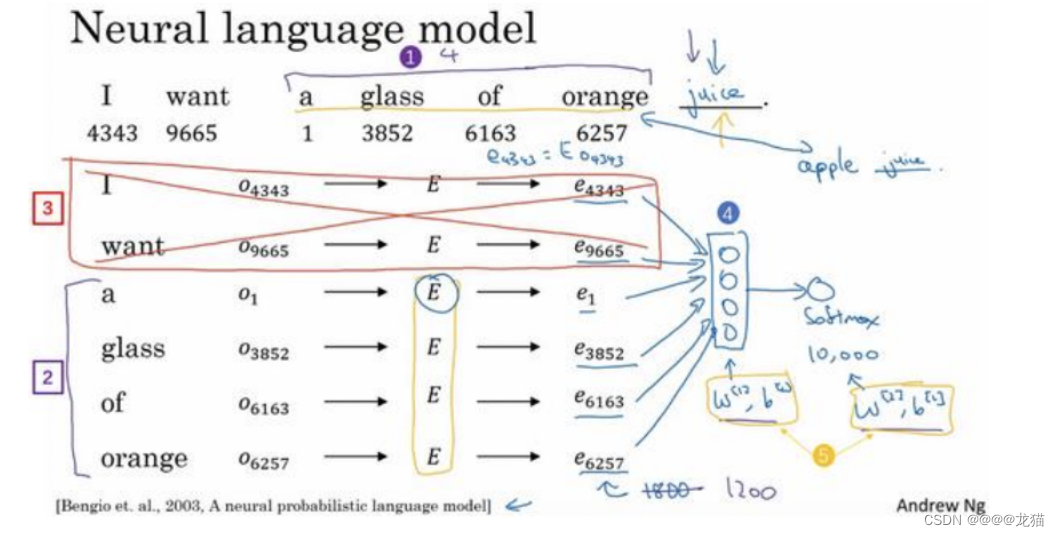
其它的上下文和目标词对
我们把将要预测的单词称为目标词,通过上下文推测出来的,对于不同的问题,上下文的大小和长度以及选择的方法有所不同
选取目标词之前的几个词;
选取目标词前后的几个词;
选取目标词前的一个词;
选取目标词附近的一个词,(一种Skip-Gram模型的思想)
Word2Vec
Word2Vec算法是一种简单的计算,并以更加高效的方式实现对词嵌入的学习
Skip-grams:
在Skip-grams模型中,我们需要抽取上下文和目标词配对,来构造一个监督学习问题
上下文不一定是要目标词前面或者后面离得最近的几个单词,而是随机选择一个词作为上下文,同时在上下文的一定距离范围内随机选择另外一个词作为目标词。
构造这样一个监督学习问题的目的,并不是想要解决监督学习问题的本身,而是想要使用这个问题来学习一个好的词嵌入模型
模型流程
- 使用一个具有大量词汇的词汇表,如Vocab size =10000k;
- 构建基本的监督学习问题,也就是构建上下文(C)和目标词(T)的映射关系:C——T
- o c o_c oc(one-hot)——E(词嵌入矩阵)—— e c = E ∗ o c e_c=E*o_c ec=E∗oc(词嵌入)——Softmax层——y^
- s o f t m a x : p ( t ∣ c ) = e Θ t T e c ∑ j = 1 10000 e Θ t T e c softmax:p(t|c)=\frac{e^{\Theta _{t}^{T}e_c } }{\sum_{j=1}^{10000}e^{\Theta _{t}^{T}e_c } } softmax:p(t∣c)=∑j=110000eΘtTeceΘtTec,其中 Θ t \Theta _{t} Θt是与输出t有关的参数
- 损失函数: L ( y ^ , y ) = − ∑ i = 1 10000 y i l o g y i ^ L(\hat{y} ,y)=-\sum_{i=1}^{10000} y_ilog\hat{y_i} L(y^,y)=−∑i=110000yilogyi^,这是在目标词y表示为one-hot向量时,常用的softmax损失函数
- 通过反向传播梯度下降训练过程,可以得到模型的参数E和softmax的参数
存在的问题
采用上面的算法有一个问题就是计算量非常大,比如在上面softmax单元中,我们需要对10000个整个词汇表的词做求和计算,计算量庞大,计算速度慢,解决的方法有分级的softmax分类器和负采样
分级的思路是(以10000个词汇为例),第一个分类器先告诉你目标词在前5000还是后5000,然后第二个分类器告诉你是前2500还是后2500,这样计算复杂度是词汇输取对数,而不是线性的。另外所形成的树一般常见的词在比较浅的地方,少见的词在更深的地方,不是一个平衡二叉树
如何采样上下文
1.对语料库均匀且随机地采样:使得如the、of、a等这样的一些词会出现的相当频繁,导致上下文和目标词对经常出现这类词汇,但我们想要的目标词却很少出现。
2.采用不同的启发来平衡常见和不常见的词进行采样。这种方法是实际使用的方法。