经典回顾 | 一种跨模态多媒体检索的新方法
2016年经典回顾 | 一种跨模态多媒体检索的新方法
最近闲来无事,为大家整理了深度学习、多模态、计算机视觉相关的必读论文和视频教程,已开源到Github上,欢迎大家使用:https://github.com/xmu-xiaoma666/FightingCV-Course。项目会长期保持更新,也欢迎大家联系笔者,加入更多教程,促进大家学习。项目在线笔记见:https://www.wolai.com/2ZvDcyvLF2FrHjnujeJzmK,更新会更加及时。
【写在前面】
多媒体文档的文本和图像组件的联合建模问题被广泛研究。文本组件表示为来自隐藏主题模型的样本,通过潜在 Dirichlet 分配学习,图像表示为视觉包 (SIFT) 特征。目前研究了两个假设:1)显式建模两个组件之间的相关性有好处,2)这种建模在具有更高抽象级别的特征空间中更有效。两个组件之间的相关性是通过典型相关分析(CCA)来学习的。抽象是通过在更一般的语义级别上表示文本和图像来实现的。在跨模态文档检索任务的背景下研究了这两个假设。这包括检索与查询图像最匹配的文本,或检索与查询文本最匹配的图像。结果表明,考虑跨模态相关性和语义抽象都可以提高检索准确性。跨模态模型也被证明在单模态检索任务上优于最先进的图像检索系统
1. 论文和代码地址

A new approach to cross-modal multimedia retrieval
论文地址:https://dl.acm.org/doi/10.1145/1873951.1873987
代码地址:https://github.com/emanuetre/crossmodal
2. Motivation
在过去的十年中,网络上的多媒体内容出现了大规模爆炸式增长。这次多媒体内容爆炸没有使得多媒体内容建模技术的复杂性也相应提高。今天,搜索多媒体存储库的流行工具仍然是基于文本的,例如搜索引擎,例如 Google 或 Bing。为了解决这个问题,学术界致力于设计能够解释多种内容模态的模型。在计算机视觉中,已经投入了大量精力来解决图像标注问题。多媒体社区已经开始了许多大规模的研究和评估工作,例如 TRECVID和 imageCLEF,涉及图像或视频数据以及注释、隐藏式字幕信息或语音识别记录。这些文献中提出了许多技术来自动增强带有标题或标签的图像,并检索和分类使用来自这些模态的信息增强的图像。
在这些领域取得进一步进展的一个重要要求是为多种内容模态开发复杂的联合模型。尤其重要的是开发支持对多模态内容进行推理的模型。这些模型不仅将图像随附的文本视为图像分类的关键字来源,而且还利用将文本正文与许多图像或视频片段配对的文档的完整结构。此类文档(包括网页、报纸文章和技术文章)的可用性随着基于互联网的信息的爆炸式增长而蓬勃发展。在这项工作中,作者考虑了这些多媒体模型的设计。专注于包含文本和图像的文档,尽管许多想法将适用于其他模态。作者从有关文本和图像分析的大量文献开始,包括将文档表示为特征包(文本的单词直方图,图像的 SIFT 直方图),以及主题模型的使用(例如潜在 Dirichlet 分配)从文档语料库中提取低维泛化。作者基于这些表示来设计图像和文本的联合模型。
该模型的性能是在跨模态检索问题上评估的,该问题包括两个任务:1)检索文本文档以响应查询图像,以及 2)检索图像以响应查询文本。这些任务是许多实际应用的核心,例如在网络上找到最能说明给定文本的图片(例如,说明故事书的页面),找到与给定图片最匹配的文本(例如,一组关于给定地标的假期帐户),或搜索文本和图像的组合。在本研究中集中讨论模型设计问题。作者使用检索任务的性能作为模型质量的间接衡量标准,直觉是最好的模型应该产生最高的检索精度。
关于模型设计,作者研究了两个假设。首先是图像和文本之间相关性的显式建模很重要。作者提出了使用典型相关分析 (CCA) 明确解释跨模态相关性的模型,并将它们的性能与两种模态独立建模的模型进行比较。第二个是抽象可以发挥有用的作用——这里定义为跨越来越普遍的语义层的分层推理。各种结果表明,这种表示可以提高多媒体任务的性能,例如使用分层主题模型进行文本聚类或使用分层语义表示进行图像检索。作者在这里考虑的检索问题适用于这种抽象层次结构的设计:例如,将特征分组到文档中,这些文档本身又分组到类或主题中,从而形成语料库。通过将图像和文档建模为关于一组预定义文档类的后验概率向量,通过逻辑回归计算,为视觉和文本提出了抽象表示。
作者研究了图像和文本表示的各种组合的检索性能,这些组合涵盖了两个指导假设的所有可能性。本文的结果表明,抽象和跨模态相关建模都有好处。最佳结果是通过将图像和文本的语义抽象与联合空间中互相关的显式建模相结合的模型获得的。作者还通过使用提出的联合模型将最先进的图像检索系统与解释每个图像附带的文本的图像检索系统的性能进行比较来证明联合文本和图像建模的好处。结果表明,后者具有显着更高的检索精度。
3. 方法
在本节中,作者提出了一种新的跨模态检索方法。尽管基本思想适用于任何内容形式的组合,但作者将讨论限制在包含图像和文本的文档上。目标是支持真正的跨模式查询:检索文本文章以响应查询图像,反之亦然。
3.1 The problem
数据库 D = { D 1 , … , D ∣ D ∣ } \mathcal{D}=\left\{D_{1}, \ldots, D_{|D|}\right\} D={D1,…,D∣D∣}包含图像和文本组件的文档。在实践中,这些组件可以是多种多样的:从单个文本由一个或多个图像补充的文档(例如,一篇报纸文章)到包含多个图片和文本(例如,维基百科)。为简单起见,作者考虑每个文档由图像及其随附文本组成的情况,即 D i = ( I i , T i ) D_{i}=\left(I_{i}, T_{i}\right) Di=(Ii,Ti)。图像和文本分别表示为特征空间 ℜ I \Re^{I} ℜI和 ℜ T \Re^{T} ℜT上的向量。这样,每个文档在文本和图像空间中的点之间建立了一对一的映射关系。给定一个文本(图像)查询 T q ∈ ℜ T ( I q ∈ ℜ I ) T_{q} \in \Re^{T}\left(I_{q} \in \Re^{I}\right) Tq∈ℜT(Iq∈ℜI),跨模态检索的目标是返回图像(文本)空间中最接近的匹配项 ℜ I ( ℜ T ) \Re^{I}\left(\Re^{T}\right) ℜI(ℜT)。
3.2 Matching images and text
每当图像和文本空间具有自然对应关系时,跨模态检索就归结为经典检索问题。 M : ℜ T → ℜ I \mathcal{M}: \Re^{T} \rightarrow \Re^{I} M:ℜT→ℜI表示两个空间之间的可逆映射。给定 ℜ T \Re^{T} ℜT中的查询 T q T_{q} Tq,找到与 M ( T q ) \mathcal{M}\left(T_{q}\right) M(Tq)在 ℜ T \Re^{T} ℜT中最近的邻居就足够了。类似地,给定一个 ℜ I \Re^{I} ℜI中的查询 I q I_{q} Iq,它可以用来找到 M − 1 ( I q ) \mathcal{M}^{-1}\left(I_{q}\right) M−1(Iq)的最近邻。在这种情况下,跨模态检索系统的设计简化为用于确定最近邻的有效相似度函数的设计。
由于图像和文本倾向于采用不同的表示形式,因此通常在 ℜ I \Re^{I} ℜI和 ℜ T \Re^{T} ℜT之间没有自然对应关系。在这种情况下,映射 M 必须从示例中学习。作者在这项工作中追求的一种可能性是将这两个表示映射到两个具有自然对应关系的中间空间 U I \mathcal{U}^{I} UI和 U T \mathcal{U}^{T} UT中。设 M I : ℜ I → U I \mathcal{M}_{I}: \Re^{I} \rightarrow \mathcal{U}^{I} MI:ℜI→UI和 M T : ℜ T → U T \mathcal{M}_{T}: \Re^{T} \rightarrow \mathcal{U}^{T} MT:ℜT→UT是从每个图像和文本空间到两个同构空间 U I \mathcal{U}^{I} UI和 U T \mathcal{U}^{T} UT的可逆映射,因此存在可逆映射:
M : U T → U I \mathcal{M}: \mathcal{U}^{T} \rightarrow \mathcal{U}^{I} M:UT→UI
给定 ℜ T \Re^{T} ℜT中的查询 T q T_{q} Tq,跨模态检索操作简化为在 ℜ I \Re^{I} ℜI中找到 M I − 1 ∘ M ∘ M T ( T q ) \mathcal{M}_{I}^{-1} \circ \mathcal{M} \circ \mathcal{M}_{T}\left(T_{q}\right) MI−1∘M∘MT(Tq)的最近邻。类似地,给定一个 R I \mathfrak{R}^{I} RI中的查询 I q I_{q} Iq,目标是找到 ℜ T \Re^{T} ℜT中 M T − 1 ∘ M − 1 ∘ M I ( I q ) \mathcal{M}_{T}^{-1} \circ \mathcal{M}^{-1} \circ \mathcal{M}_{I}\left(I_{q}\right) MT−1∘M−1∘MI(Iq)的最近邻。
在这种方法下,跨模态检索系统设计的主要问题是学习中间空间 U I \mathcal{U}^{I} UI和 U T \mathcal{U}^{T} UT 。在这项工作中,作者考虑了两种主要程序组合产生的三种可能性。在第一种情况下,两个线性投影学习将 ℜ I \Re^{I} ℜI分别 ℜ T \Re^{T} ℜT映射到相关的 d 维子空间 U I \mathcal{U}^{I} UI 和 U T \mathcal{U}^{T} UT上。:
P T : ℜ T → U T \mathcal{P}_{T}: \Re^{T} \rightarrow \mathcal{U}^{T} PT:ℜT→UT
P I : ℜ T → U I \mathcal{P}_{I}: \Re^{T} \rightarrow \mathcal{U}^{I} PI:ℜT→UI
这保持了表示的抽象级别。在第二种情况下,一对非线性变换用于将图像和文本空间映射到一对语义空间 S T , S I \mathcal{S}^{T}, \mathcal{S}^{I} ST,SI 使得 S T = S I \mathcal{S}^{T}=\mathcal{S}^{I} ST=SI。
3.3 Correlation matching
学习 U T , U I \mathcal{U}^{T}, \mathcal{U}^{I} UT,UI需要一些关于文本和图像空间中的表示之间的最佳对应关系的概念。一种可能性是依赖子空间学习。这是一个学习框架,是文本和视觉文献中一些非常流行的降维方法的基础,例如潜在语义索引或主成分分析 (PCA)。从计算的角度来看,子空间学习方法通常是有效的,并且产生易于概念化、实现和部署的线性变换。在这种情况下,图像和文本子空间之间对应关系的自然度量是它们的相关性。这表明典型相关分析(CCA) 作为跨模态建模的自然子空间表示。
典型相关分析(CCA)是一种类似于PCA的数据分析和降维方法。虽然 PCA 只处理一个数据空间,但 CCA 是一种跨两个(或多个)空间联合降维的技术,提供相同数据的异构表示。假设是这两个空间中的表示包含一些联合信息,这些信息反映在它们之间的相关性中。 CCA 学习 d 维子空间 U I ⊂ ℜ I \mathcal{U}^{I} \subset \Re^{I} UI⊂ℜI和 U T ⊂ ℜ T \mathcal{U}^{T} \subset \Re^{T} UT⊂ℜT最大化两种模态之间的相关性。
与 PCA 中的主成分类似,CCA 学习规范成分的基础,即数据最大相关的方向 w i ∈ ℜ I w_{i} \in \Re^{I} wi∈ℜI和 w t ∈ ℜ T w_{t} \in \Re^{T} wt∈ℜT,即:
max w i ≠ 0 , w t ≠ 0 w i T Σ I T w t w i T Σ I I w i w t T Σ T T w t \max _{w_{i} \neq 0, w_{t} \neq 0} \frac{w_{i}^{T} \Sigma_{I T} w_{t}}{\sqrt{w_{i}^{T} \Sigma_{I I} w_{i}} \sqrt{w_{t}^{T} \Sigma_{T T} w_{t}}} wi=0,wt=0maxwiTΣIIwiwtTΣTTwtwiTΣITwt
其中 Σ I I \Sigma_{I I} ΣII和 Σ T T \Sigma_{T T} ΣTT表示图像 { I 1 , … , I ∣ D ∣ } \left\{I_{1}, \ldots, I_{|D|}\right\} {I1,…,I∣D∣}和文本 { T 1 , … , T ∣ D ∣ } \left\{T_{1}, \ldots, T_{|D|}\right\} {T1,…,T∣D∣},而 Σ I T = Σ T I T \Sigma_{I T}=\Sigma_{T I}^{T} ΣIT=ΣTIT表示它们之间的互协方差矩阵。优化可以解决为广义特征值问题 (GEV):
( 0 Σ I T Σ T I 0 ) ( w i w t ) = λ ( Σ I I 0 0 Σ T T ) ( w i w t ) \left(\begin{array}{cc}0 & \Sigma_{I T} \\ \Sigma_{T I} & 0\end{array}\right)\left(\begin{array}{l}w_{i} \\ w_{t}\end{array}\right)=\lambda\left(\begin{array}{cc}\Sigma_{I I} & 0 \\ 0 & \Sigma_{T T}\end{array}\right)\left(\begin{array}{l}w_{i} \\ w_{t}\end{array}\right) (0ΣTIΣIT0)(wiwt)=λ(ΣII00ΣTT)(wiwt)
广义特征向量确定一组不相关的规范分量,相应的广义特征值指示解释的相关性。 GEV 可以像常规特征值问题一样有效地解决。

前 d 个规范分量 { w i , k } k = 1 d \left\{w_{i, k}\right\}_{k=1}^{d} {wi,k}k=1d和 { w t , k } k = 1 d \left\{w_{t, k}\right\}_{k=1}^{d} {wt,k}k=1d定义了用于在子空间 U I \mathcal{U}^{I} UI和 U T \mathcal{U}^{T} UT上分别投影 ℜ I \Re^{I} ℜI和 ℜ T \Re^{T} ℜT的基础。这两个投影之间的自然可逆映射来自最大交叉模态相关性的 d 维基之间的对应关系,如 w i , 1 ↔ w t , 1 , … , w i , d ↔ w t , d w_{i, 1} \leftrightarrow w_{t, 1}, \ldots, w_{i, d} \leftrightarrow w_{t, d} wi,1↔wt,1,…,wi,d↔wt,d。对于跨模态检索,每个文本 T ∈ ℜ T T \in \Re^{T} T∈ℜT都映射到它的投影 p T = P T ( T ) p_{T}=\mathcal{P}_{T}(T) pT=PT(T)到 { w t , k } k = 1 d \left\{w_{t, k}\right\}_{k=1}^{d} {wt,k}k=1d,每个图像都映射到它的投影 p I = P I ( I ) p_{I}=\mathcal{P}_{I}(I) pI=PI(I)到 { w i , k } k = 1 d \left\{w_{i, k}\right\}_{k=1}^{d} {wi,k}k=1d。这导致了两种模态的紧凑、有效的表示。由于向量 p T p_{T} pT和 p I p_{I} pI是两个等距的 d 维子空间中的坐标,因此可以认为它们属于单个空间 U,通过重叠 U I \mathcal{U}^{I} UI和 U T \mathcal{U}^{T} UT获得。上图展示了示意图,其中 CCA 为跨模态检索定义了一个公共子空间 (U)。
给定投影 p I = P ( I q ) p_{I}=\mathcal{P}\left(I_{q}\right) pI=P(Iq)的图像查询 I q I_{q} Iq,与它最匹配的文本 T ∈ ℜ T T \in \Re^{T} T∈ℜT 需要最小化:
D ( I , T ) = d ( p I , p T ) D(I, T)=d\left(p_{I}, p_{T}\right) D(I,T)=d(pI,pT)
对于在 d 维向量空间中的一些合适的距离 d(·,·) 度量。类似地,给定一个带有投影 p T = P ( T q ) p_{T}=\mathcal{P}\left(T_{q}\right) pT=P(Tq)的查询文本 T q T_{q} Tq,最接近的图像 I ∈ ℜ I I \in \Re^{I} I∈ℜI最小化了 d ( p I , p T ) d\left(p_{I}, p_{T}\right) d(pI,pT)。
3.4 Semantic matching
子空间学习的一种替代方法是在更高的抽象层次上表示文档,以便文本和图像空间之间存在自然的对应关系。这是通过使用词汇表 V = { v 1 , … , v K } \mathcal{V}=\left\{v_{1}, \ldots, v_{K}\right\} V={v1,…,vK}的语义概念。这些是广泛的文档类别,例如“历史”或“生物学”,单个文档被分组到其中。然后分别借助文本和图像的两个分类器来实现两个映射 L T \mathcal{L}_{T} LT和 L I \mathcal{L}_{I} LI。 L T \mathcal{L}_{T} LT 将文本 T ∈ ℜ T T \in \Re^{T} T∈ℜT映射到后验概率向量 P V ∣ T ( v i ∣ T ) , i ∈ { 1 , … , K } P_{V \mid T}\left(v_{i} \mid T\right), i \in \{1, \ldots, K\} PV∣T(vi∣T),i∈{1,…,K}相对于 V 中的每个类。这些后验向量的空间 S T \mathcal{S}^{T} ST被称为文本的语义空间,概率 P V ∣ T ( v i ∣ T ) P_{V \mid T}\left(v_{i} \mid T\right) PV∣T(vi∣T) 是语义文本特征。类似地, L I \mathcal{L}_{I} LI将图像 I 映射到语义图像特征向量 P V ∣ I ( v i ∣ I ) , i ∈ { 1 , … , K } P_{V \mid I}\left(v_{i} \mid I\right), i \in\{1, \ldots, K\} PV∣I(vi∣I),i∈{1,…,K}在语义图像空间 $ S^I $中。
计算后验概率分布的一种可能性是通过多类逻辑回归。这会产生一个具有概率解释的线性分类器。逻辑回归通过将数据拟合到逻辑函数来计算 j 类的后验概率:
P V ∣ X ( j ∣ x ; w ) = 1 Z ( x , w ) exp ( w j T x ) P_{V \mid X}(j \mid x ; w)=\frac{1}{Z(x, w)} \exp \left(w_{j}^{T} x\right) PV∣X(j∣x;w)=Z(x,w)1exp(wjTx)
其中 Z ( x , w ) = ∑ j exp ( w j T x ) Z(x, w)=\sum_{j} \exp \left(w_{j}^{T} x\right) Z(x,w)=∑jexp(wjTx) 是归一化常数,V 是类标签,X 是输入空间中的特征向量, w = { w 1 , … , w K } w=\left\{w_{1}, \ldots, w_{K}\right\} w={w1,…,wK}, w j w_{j} wj是类 j 的参数向量。通过使 X 分别成为图像和文本表示 I ∈ ℜ I I \in \Re^{I} I∈ℜI 和 T ∈ ℜ T T \in \Re^{T} T∈ℜT来学习文本和图像模态的多类逻辑回归。
语义建模对于跨模态检索有两个优点。首先,它提供了更高层次的抽象。虽然 ℜ T \Re^{T} ℜT 和 ℜ I \Re^{I} ℜI中的标准特征是无监督学习的结果,并且通常没有明显的解释(例如图像特征往往是边缘、边缘方向或频率基),但 S I \mathcal{S}^{I} SI和 S T \mathcal{S}^{T} ST中的特征是语义概念概率(例如图像属于“历史”或“生物学”文档类的概率)。以前的工作表明,这种增加的抽象可以为图像检索等任务带来更好的泛化。其次,语义空间 S I \mathcal{S}^{I} SI和 S T \mathcal{S}^{T} ST是同构的:在这两种情况下,图像和文本都表示为关于相同文档类的后验概率向量。因此,空间可以被认为是相同的,即 S T = S I \mathcal{S}^{T}=\mathcal{S}^{I} ST=SI。
给定一个查询图像 I q I_{q} Iq,由概率向量 π I ∈ S I \pi_{I} \in \mathcal{S}^{I} πI∈SI表示,检索包括找到由概率向量 π T ∈ S T \pi_{T} \in \mathcal{S}^{T} πT∈ST发送的文本 T T T,它最小化:
D ( I , T ) = d ( π I , π T ) D(I, T)=d\left(\pi_{I}, \pi_{T}\right) D(I,T)=d(πI,πT)
对于概率分布之间的距离 d 的某种合适的度量。作者将这种类型的检索称为语义匹配
3.5 Semantic correlation matching
也可以结合子空间和语义建模。在这种情况下,逻辑回归在两个最大相关子空间内执行。CCA 建模首先应用于学习最大相关子空间 U I ⊂ ℜ I \mathcal{U}^{I} \subset \Re^{I} UI⊂ℜI和 U T ⊂ ℜ T \mathcal{U}^{T} \subset \Re^{T} UT⊂ℜT 。然后在这些子空间中的每一个中学习逻辑回归量 L I \mathcal{L}_{I} LI和 L T \mathcal{L}_{T} LT 以分别生成语义空间 S I \mathcal{S}^{I} SI和 S T S^{T} ST 。检索最终基于 图文距离 D ( I , T ) D(I, T) D(I,T),基于投影到 U I U^I UI 和 U T U^T UT 。我们将这种类型的检索称为语义相关匹配。
3.6 Text and Image Representation
在这项工作中,文本在 ℜ T \Re^{T} ℜT上的表示源自潜在狄利克雷分配 (LDA) 模型。 LDA 是文本语料库的生成模型,其中文本的语义内容或“要点”被概括为主题的混合。更准确地说,文本被建模为 K 个主题的多项分布,每个主题又被建模为单词的多项分布。文本 D i D_i Di中的每个单词是通过首先从特定于文本的主题分布中采样一个主题 z,然后从该主题的多项式中采样一个单词来生成的。在 ℜ T \Re^{T} ℜT 中,文本文档由它们的主题分配概率分布表示。
在 ℜ I \Re^{I} ℜI 中,图像表示基于流行的尺度不变特征变换(SIFT)。首先从训练集中的每个图像中提取一袋 SIFT 描述符(使用 LEAR 的 SIFT 实现)。然后使用 k-means 聚类算法学习视觉词的代码本或字典。从每个图像中提取的 SIFT 描述符使用此码本进行矢量量化,并且图像由由此量化产生的 SIFT 描述符直方图表示。
4.实验

维基百科数据集的总结。

每个类别的 MAP 性能。

提出的跨模式检索方法的分类。

不同的距离度量(MAP 分数)。

检索性能(MAP 分数)。

文本查询的两个示例和 SCM 检索的top图像。
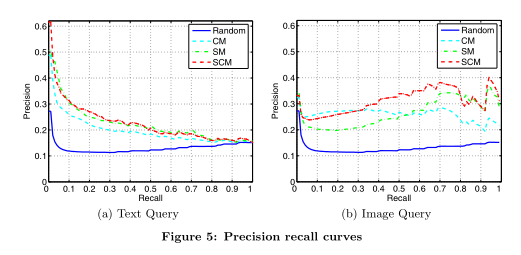
精确召回曲线。

通过将查询分类到最高 MAP 类计算的类别级混淆矩阵。

基于内容的图像检索。

图像查询的一些示例(最左列上的框架图像是查询对象)和相应的顶部检索图像(按文本相似度排名)。
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

“点个在看,月薪十万!”
“学会点赞,身价千万!”