一文搞懂大数据入门之 Hadoop,HDFS,Hbase,Hive
经常听到这些大数据的名词, Hadoop,HDFS,Hbase,Hive等,这次就一探究竟。
- Hadoop:是泛指大数据生态,实际上基本包括 存储(HDFS) + 计算(MapReduce);
- HDFS: Hadoop分布式文件系统,主要是解决存储的问题;
- Hbase: 基于Hadoop的高性能nosql数据库;
- Hive: 最常用的数据仓库;
文章目录
- What is 大数据 ?
- What is Hadoop ?
- HDFS 基础架构
- HDFS写流程
- HDFS读流程
- 实战HDFS操作
- MapReduce计算
- What is Hbase ?
- Hive ?
- what is 数据仓库 ?
- 什么是Hive
- 安装Hive
- Hive操作
- 内表
- 外表
- 列存储VS行存储
- Hbase VS Hive
- 区别
- 联系
- 参考
What is 大数据 ?
大数据是以Hadoop为代表的大数据平台框架上进行各种数据采集,数据整理,数据分析的技术,Hadoop只是一个框架。
What is Hadoop ?
Hadoop 生态图:
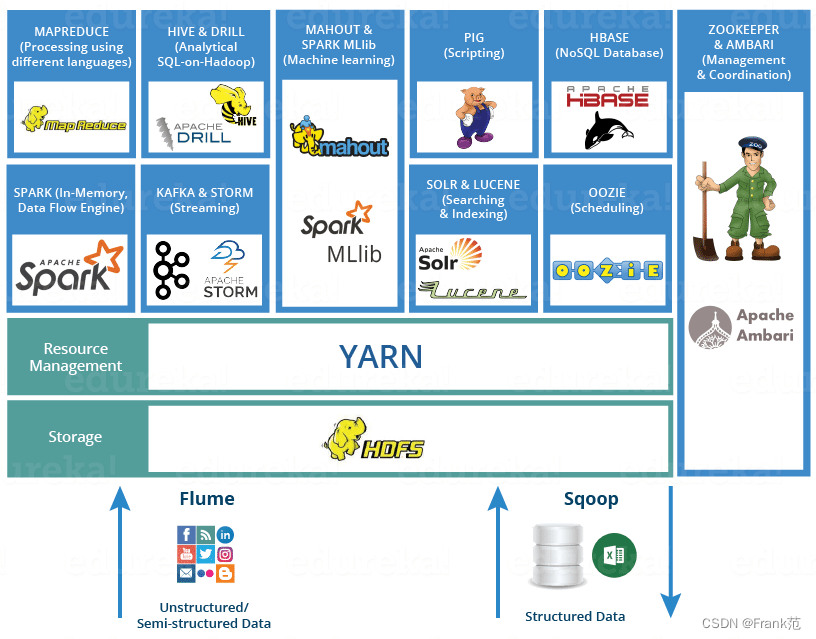
- 是一个开源的大数据框架,它是一个生态,是分布式计算的解决方案
- 一般认为的Hadoop = HDFS(分布式文件系统,存储) + MapReduce(分布式计算,计算)
HDFS 基础架构
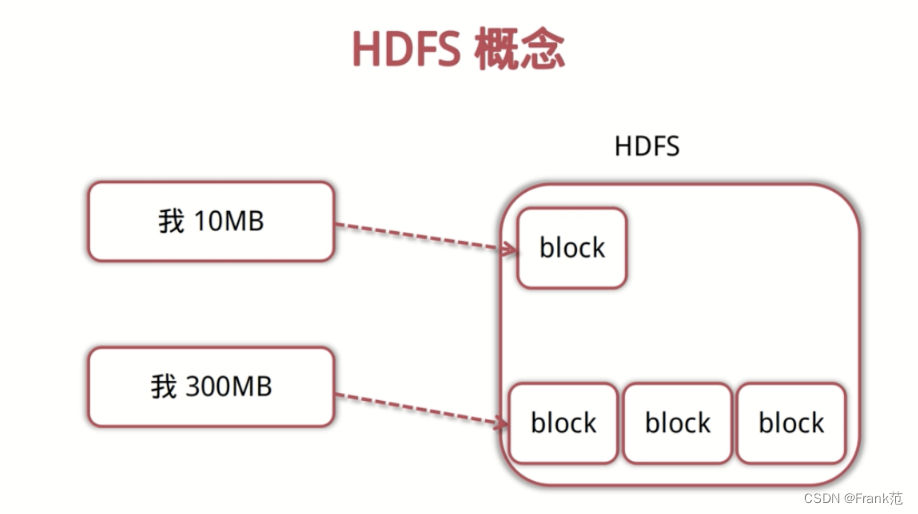
- 文件是按照数据块存储,而非整个文件作为存储单元。每个文件分成多个固定大小的存储块,存储在不同的节点上。
- NameNode,管理文件系统的命名空间,存放文件元数据,维护文件系统所有文件和目录,文件与数据块的映射。
- DataNode:存储并检索数据块,向name node 更新检索信息,是真正存数据的node。
HDFS写流程
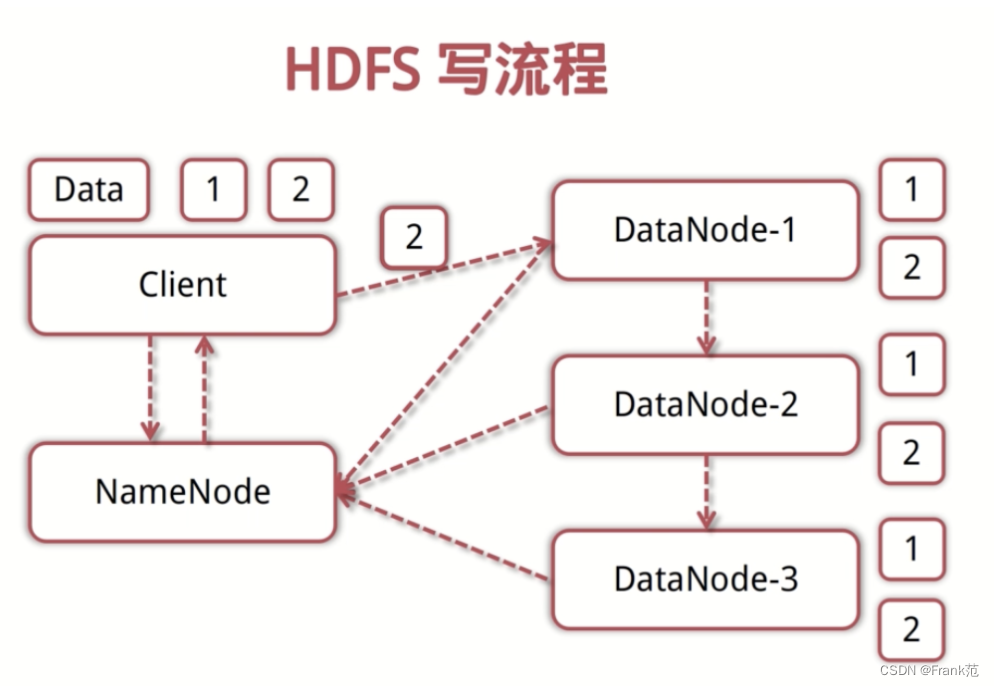
- client向NameNode发起写数据请求
- Namenode分块写入DataNode,DataNode自动完成3副本备份。
- DataNode向NameNode汇报存储完成。
- Namenode通知client.
HDFS读流程
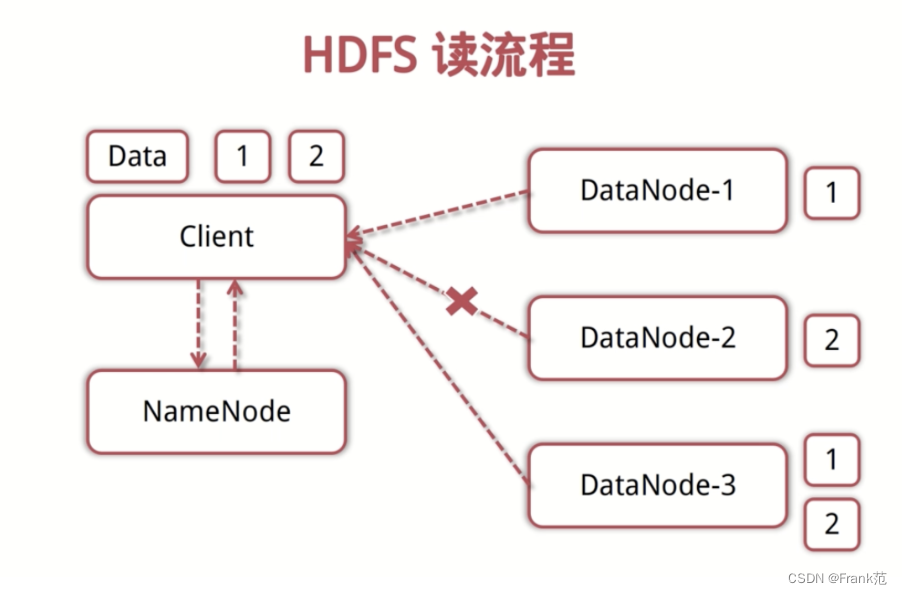
- Client向NameNode发起读数据请求。
- NameNode找出距离最近的DataNode节点信息,并将信息发送给Client。
- Client从DataNode分块下载文件。
实战HDFS操作
可以通过shell或者pytohn操作HDFS,进行文件的存储到HDFS,并下载。
MapReduce计算
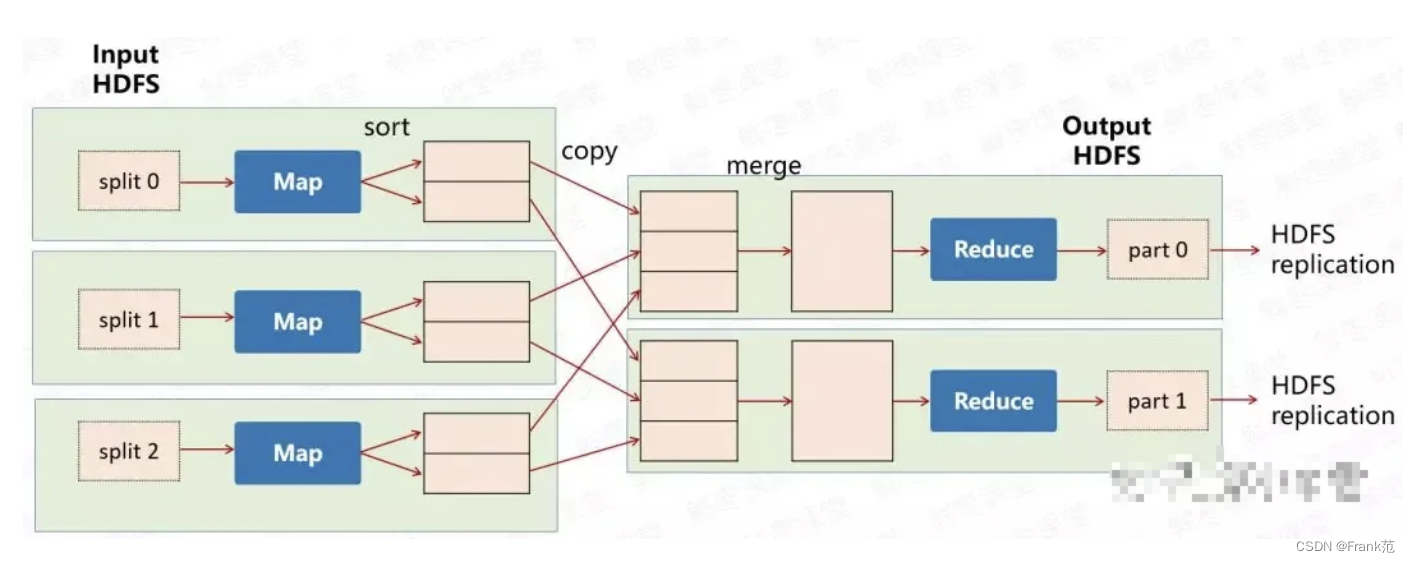
Hadoop提供最基本的MapReduce计算模型。
- Map: 输入一个大文件,通过split,分成多个分片,到单独的机器去处理,Map任务完成后,会生成一些中间文件,这些中间文件将会作为Reduce的输入数据。
- Reduce: 把各个机器Map的输出结果进行汇总并得到最终的结果。
所以,Hadoop其实是一个生态,最主要的是存储HDFS+计算MapReduce,Hadoop本身的计算比较鸡肋,所以有了Spark计算引擎。
What is Hbase ?
- 来源于Google的BigTable。
- 高可靠,高性能,面向列,可伸缩,实时读写的分布式数据库。
- 利用HDFS作为文件存储系统,支持MapReduce。
- 存储非结构化和半结构化数据。
- 基于Hadoop的数据库
Hive ?
what is 数据仓库 ?
数据仓库是将多个数据源的数据经过ETL处理后,按照一定的主题集成起来提供决策支持和联动分析应用的结构化数据环境。
ETL: Extract + Tranform + Load
什么是Hive
- 是第一个基于Hadoop的sql处理引擎,是当前基于Hadoop构建数据仓的最常用方案,是对存储在HDFS的文件进行查询。
- Hive是将文件数据映射成DB和table,库和表的元数据信息一般存在关系型数据库。
- 以MapReduce作为计算引擎,HDFS作为存储系统,提供超大数据的计算扩展能力。
- Hive数据存储:Hive的数据是存储在HDFS上的,Hive的库和表是对HDFS上数据的映射。
- Hive元数据存储:元数据存储是在外部关系库MySql
- Hive SQL的执行过程:将HQL转成MapReduce任务,所以比较慢。而如今,Apache Hive还能够将查询转换Spark作业,提供运行速度。
安装Hive
- 下载hive
- 修改conf配置,指定数据存放的HDFS目录
- 下载mysql java
- 创建metastore schema
- 启动meatastore,show databases 可以看到default DB.
Hive操作
内表
导入数据时,将数据移动到hive指定的目录文件中,删除表时,数据也会删除;
建表:
CREATE TABLE table1 (
id int,
name string,
interest array<string>,
score map<string,string>
)
row format delimited fields terminated by ',' --列分割
collection items terminated by '-' --array分割
map keys terminated by ':' --map分割
stored AS textfile; --保存
import data:
load data local inpath '/opt/data/test' overwrite into table table1;
外表
建表时添加关键字external,并指定位置,删除表时不会删除源数据
create external table table2(
id int,name string,interest array<string>,
score map<string,string>)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':' location '/testtable';
desc formatted table2;
Hive可以通过partition,bucket对海量数据进行区分。
列存储VS行存储
- 行存储:是按照行来把数据存储到disk上,一般的用于app的元数据存储,因为要获取某一行的所有数据,这样如果有索引的话,可以通过索引直接知道对应的某一行在disk上的位置。
- 列存储,对于大数据而言,往往要进行数据分析,所以不太需要某一行的数据,更多的是某一列,比如:取分数前10名等。所以列存储,对于这种场景下,效率更高。
Hbase VS Hive
名字看上去是很相似的,其实他们本质上是不一样的,一个是数据仓库,一个是数据库。
区别
- Hive,Hive是基于Hadoop的一个数据仓库工具,本身并不存储和计算数据,只是把sql转成MapReduce程序运行。
- Hbase,是Hadoop的数据库,一个分布式、可扩展、大数据的存储。
联系
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
在大数据架构中,Hive和HBase是协作关系,数据流一般:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- Hive清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbasei,数据应用从HBase查询数据;
- 如果不是随机查询场景,可以直接从Hive中获取数据。
参考
- https://www.imooc.com/video/16286
- https://www.imooc.com/video/19271
- https://zhuanlan.zhihu.com/p/333682189