Mysql数据备份(mysqldump的操作)
数据备份
所有备份数据都应放在非数据库本地,(得用远程存储,如ftp,nfs)而且建议有多份副本。
备份的作用
能够防止由于机械故障以及人为误操作带来的数据丢失,如,将数据库文件保存在了其它地方。
冗余
数据有多份冗余,但不等备份,只能防止机械故障还来的数据丢失,如主备模式、数据库集群。
备份过程中必须考虑因素:
1. 数据的一致性(数据备份的时候是什么样,恢复之后就是什么样)
2. 服务的可用性(在备份数据的时候能不能同时给客户端通过服务,比如冷备份就不可以)
数据库里的备份分类
物理备份
逻辑备份
冷备份
热备份
| 物理备份的工具 | |
| tar,cp | 里面的库可以cp一份保存下来,或者打个tar包(强烈不介意) |
| mysqlhotcopy | 只能用于备份MyISAM |
| xtrabackup | 物理备份(在公司可能用得到,) |
| inbackup | 备份 |
| lvm snapshot | Lvm快照实现物理备份 + binlog (logical volumn manager) |
物理备份: 直接复制数据库文件,适用于大型数据库环境,不受存储引擎的限制,但不能恢复到不同的MySQL版本。如:cp,先打tar包再cp。
本质是备份文件,将来不管用到什么备份,如果是物理备份,基本就是备份文件。
物理备份和逻辑备份的区别?
逻辑备份就是备份命令,物理备份就是备份文件。
| 逻辑备份的工具 | |
| mysqldump | 适合做表的备份,库的备份,完整备份(命令行的管理工具,可以写脚本)是装好mysql自带的,不需要额外安装 |
| binlog | 用于备份恢复数据(命令行的管理工具,可以写脚本) |
| mydumper | 支持多线程恢复(不用记) |
| phpmyadmin | web界面的mysql管理工具,有界面可以点点,运维基本不用,开发用 |
| 导入导出 | 数据可以单独的导出成文本文件,也可以从文本文件把数据导入到数据库里面去(用的少) |
逻辑备份: 备份的是建表、建库、插入等操作所执行SQL语句(DDL DML DCL),其实就是备份的写操作。适用于中小型数据库,效率相对较低。( mysql就是中小型数据库,Oracle、SQL Server 才是大型的,之所以mysql流行是因为不要钱)
就比如binlog日志,备份的不是id=1这个数据,备份的不是存储数据的表空间文件,备份的是一条命令,恢复数据的时候是重新执行这条命令,而不是把备份的文件拷过来。像这种备份数据的方法就是逻辑备份。
xtrabackup备份和mysqldump备份的区别
xtrabackup是物理备份,mysqldump是逻辑备份。物理备份永远要比逻辑的效率高,物理备份的是文件,拷贝文件的速度肯定比执行命令的速度要快,比如一万条命令去执行,肯定比拷贝一万条数据花的时间要长,一万条数据放在一个文件里面也没多少瞬间拷完了,但一万条命令执行起来得执行好一会。
冷备份,热备份
冷备份和热备份本身没有直接的联系这是另外一种分类,在这个分类里最大的区别就是冷和热。
冷备份
指数据库在备份数据的时候需要关库
热备份
指服务被客户端访问的情况下做数据的备份
mysqldump的语法:
mysqldump --help 查看帮助
 1.mysqldump +database(数据库的名称/目录的名称) 后面的表可写可不写
1.mysqldump +database(数据库的名称/目录的名称) 后面的表可写可不写
2.mysqldump + - -database(这是选项一个参数)后边是库的名称
3.--all-databases 所有的库
操作
mysqldump -uroot -p1 db1 t1 打印到屏幕了,和二进制文件有点像,前面的东西都是注释。往下翻看配置文件。
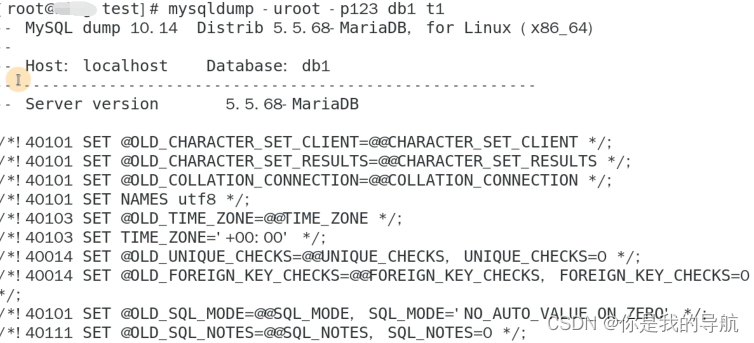
 drop如果t1表存在,就把它干掉,这里的create table t1其实就是创建t1的命令,系统给补充了一下。
drop如果t1表存在,就把它干掉,这里的create table t1其实就是创建t1的命令,系统给补充了一下。

把t1表的write锁上,(我要操作表,别人不能操作,只能我操作)
数据库的表,在同一时刻,这个表被写入数据的时候,不能让别的客户端连进来打开这个表去写东西,不然我给id字段的第一条记录赋值1,你赋值2,它就混乱了。所以它有锁表的操作。
insert into 把这个数据插入进去了
unlock tables;解锁
看看里面有什么东西

mysqldump -uroot -p1 db1 t1 回忆一下刚才这条命令,展示出来的东西。现在是展示到屏幕上的,把它重定向到随便一个文本文件里边。比如# mysqldump -uroot -p1 db1 t1 > db1.t1.sql。这就是备份数据,这个数据就备份好了。
刚才的内容:
1.先查看了一下t1是否存在,如果存在把它干掉,如果不存在什么都不干
2.它创建了一个表叫t1
3.它把t1表锁了,插入数据,unlock
两种方法恢复数据库表
一、指定库
进入mysql,把db1.t1删掉,恢复它
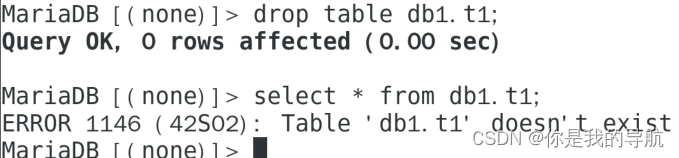
查看有没有备份数据
![]()
把mysql客户端执行一下,指定一下恢复到哪个数据库
mysql -u root -p123 db1 < db1.t1.sql![]()
数据就有了

二、修改配置文件
vim db1.t1.sql

进去配置文件,输入use db1;(就可以自己编辑配置文件大小写不重要)这时就不用加库了
mysql -uroot -p123 < db1.t1.sql

备份多张表

cat db1.t1.2.sql 看备份文件,t1 t2都有了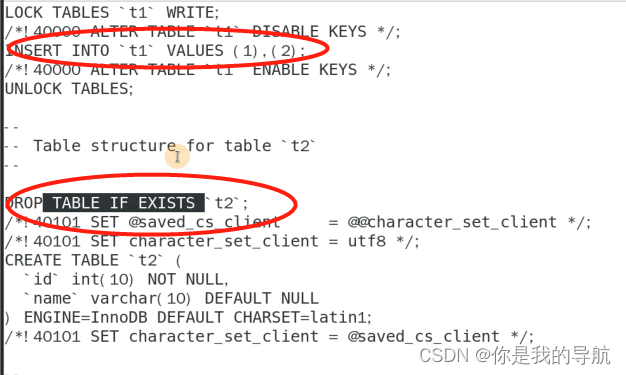
现在把t1 t2全删了,可以用这个表恢复,如果现在我就有这一个备份文件,里面备份了t1和t2但是只把t2丢了,t1还在怎么办?
因为db1.t1.2.sql 这个文件都是文本文件,可以拷贝一份,拷贝成dbt12.sql

编辑第一个文件,把注释文件留着,t1文件中间的删了

删掉之后,写上use db1;
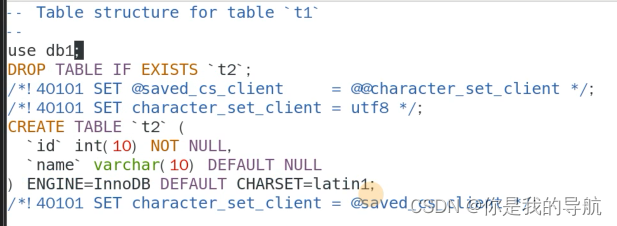

t2就回来了

备份表
# mysqldump -uroot -p1 db1 t1 > db1.t1.sql 重定向到 备份db1里面的t1表
备份多个表
# mysqldump -u root -p1 db1 t1 t2 > /db1.t1.2.sql
备份一个库
# mysqldump -u root -p1 db1 > db1.sql 把表去掉就是单独一个库,一般备份文件都是以.sql结尾
备份多个库 加-B 专门用来备库
# mysqldump -u root -p1 -B db1 db2 db3 > db123.sql
备份所有的库
#mysqldump -u root -p1 -A > /alldb.bak -A不需要指定想备份什么东西会备份所有的库,包括mysql库(授权表的库)也会做备份。
恢复数据库
为保证数据一致性,应在恢复数据之前停止数据库对外的服务,停止binlog日志
因为恢复数据库就是把那些sql语句重新再执行一遍,binlog日志里面原来已经记录了一遍,再记录一遍就浪费了。binlog日志会记录所有写操作,恢复数据也是写操作,所以没必要再记录。
mysql> set sql_log_bin=0 在mysql客户端内部临时设置关闭binlog日志
1vim db1.sql 恢复的时候它是直接创建表,没库,得手动创建库,
进去配置文件去最前面
create database db1;
use db1;
mysql -uroot -p123 < db1.sql 这条命令主要是用来备份表的,在恢复的时候先切换成一个库,才能备份表,所以需要稍微改一下配置文件
2#mysql -u root -p1 -D db1 < db1.t1.bak
模拟:完全 + 增量 binlog
完整备份:
不管数据库里有什么,统统都做备份。(-A)缺点:天天做重复的东西在浪费,服务器的性能是有限的。一般情况下,不会天天做完整备份,所以会配合其他的备份方式。
一般情况下,一个月,或者半个月做一次完整备份。看公司是怎么定的。这么做也有问题,比如一个月做一次完整备份,每个月的1号12点开始做完整备份。但是15号-18号的数据坏了,恢复的时候得恢复整个月的数据。假如单独的有15,16,17,18的日志,就可以单独的恢复。所以叫完整备份+增量binlog。
平时一个月做一次完整备份,每天都要做一次binlog日志的备份,一天刷新一个新文件,一天一个binlog日志,假如18号的数据坏了,就把18号那天的binlog日志那个文件拿出来恢复就完了。
增量备份:
每天都备份全新的东西,不在备份旧的东西了。比如今天的binlog日志我备份到12点,12点之后会产生一个全新的binlog日志文件备份第二天的,第二天的12点又产生一个全新的binlog日志备份第三天的。总之一个binlog日志备份一整天的数据,这就是每次都是备份新的,这种备份方式叫做增量备份。
流程
用mysqldump做完整备份,binlog做增量备份
在备份之前我有一个库叫school,有一张表是t1。t1里面有1和2两条数据。
在备份的时候用mysqldump做备份
操作的时候
恢复的流程:
恢复完全备份,恢复增量备份,恢复配置文件(cp或者打个tar包),创建所需的目录及权限(有什么新的目录需要改权限,给它创建好)
为什么会有,恢复配置文件,创建所需的目录及权限这两个操作?
因为很有可能换了一台全新的机器,新装的mysql服务,要恢复数据,里面的原来配置文件也没了,得恢复过来,存储数据,日志的目录都没了,得创建好。