数据导入与预处理-第6章-01数据清理
数据导入与预处理-第6章-01数据清理
- 1 数据集成概述
- 1.1 数据集成需要关注的问题
- 2 基于Pandas实现数据集成
- 2.1 主键合并数据merge
- 2.2 堆叠合并数据concat
- 2.3 重叠合并数据combine_first
- 2.4 追加合并数据append
- 2.5 基于索引合并join
- 3 思考题
1 数据集成概述
1.1 数据集成需要关注的问题
数据集成期间的数据问题,包括:
实体识别
冗余属性识别
元组重复等
数据分析中需要的数据往往来自不同的途径,这些数据的格式、特点、质量千差万别,给数据分析或挖掘增加了难度。为提高数据分析的效率,多个数据源的数据需要合并到一个数据源,形成一致的数据存储,这一过程就是数据集成。
1.实体识别
实体识别指从不同数据源中识别出现实世界的实体,主要用于统一不同数据源的矛盾之处,常见的矛盾包括同名异义、异名同义、单位不统一等。
实体识别问题是数据集成中的首要问题,因为来自多个信息源的现实世界的等价实体才能匹配。例如,如何确定一个数据库中的“custom_id”与另一个数据库中的“custome_number”是否表示同一实体。
实体识别中的单位不统一也会带来问题。例如,重量属性在一个系统中采用公制,而在另一个系统中却采用英制;价格属性在不同地点采用不同的货币单位。这些语义的差异为数据集成带来许多问题。
2.冗余属性级相关分析识别
冗余属性是数据集成期间极易产生的问题,冗余是数据集成的另一重要问题。如果一个属性能由另一个或另一组属性值“推导”出,则这个属性可能是冗余的。属性命名不一致也会导致结果数据集中的冗余,属性命名会导致同一属性多次出现。例如,一个顾客数据表中的平均月收入属性就是冗余属性,显然它可以根据月收入属性计算出来。此外,属性命名的不一致也会导致集成后的数据集出现数据冗余问题。
有些冗余可以被相关分析检测到,对于标称属性,使用卡方检验,对于数值属性,可以使用相关系数(correlation coefficient)和 协方差( covariance)评估属性间的相关性。
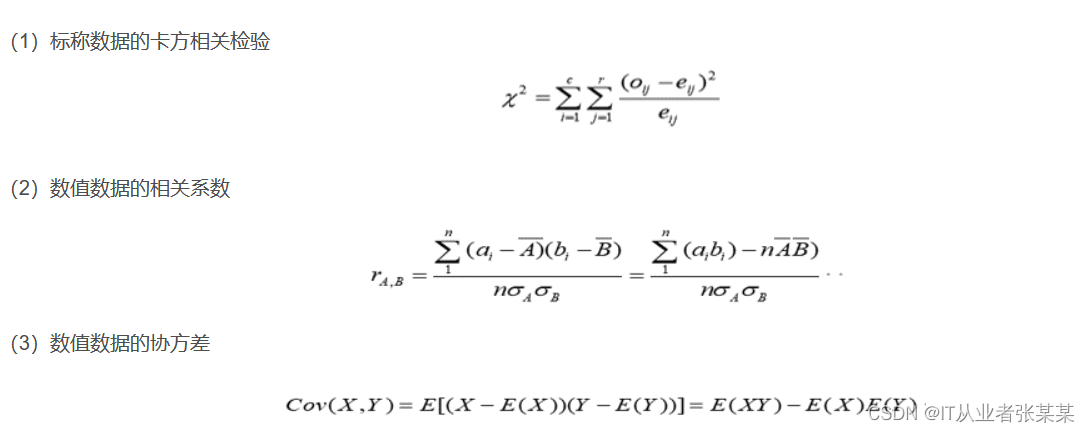
协方差和相关系数检测:
import pandas as pd
import numpy as np
a=[47, 83, 81, 18, 72, 41, 50, 66, 47, 20, 96, 21, 16, 60, 37, 59, 22, 16, 32, 63]
b=[56, 96, 84, 21, 87, 67, 43, 64, 85, 67, 68, 64, 95, 58, 56, 75, 6, 11, 68, 63]
# 数组转置(T)
data = np.array([a,b]).T
dfab = pd.DataFrame(data,columns = ['A','B'])
# display(dfab)
print('属性A和B的协方差:',dfab.A.cov(dfab.B))
print('属性A和B的相关系数:',dfab.A.corr(dfab.B))
# 属性A和B的协方差: 310.2157894736842
# 属性A和B的相关系数: 0.49924871046524394
如果数据成正比,那么相关系数为1:
import pandas as pd
import numpy as np
a=[47, 83, 81, 18, 72, 41, 50, 66, 47, 20, 96, 21, 16, 60, 37, 59, 22, 16, 32, 63]
b = []
for i in a:
tmp = i*2
b.append(tmp)
print(b)
# 数组转置(T)
data = np.array([a,b]).T
dfab = pd.DataFrame(data,columns = ['A','B'])
# display(dfab)
print('属性A和B的协方差:',dfab.A.cov(dfab.B))
print('属性A和B的相关系数:',dfab.A.corr(dfab.B))
# [94, 166, 162, 36, 144, 82, 100, 132, 94, 40, 192, 42, 32, 120, 74, 118, 44, 32, 64, 126]
# 属性A和B的协方差: 1217.7421052631578
# 属性A和B的相关系数: 1.0
3.元组重复
元组重复是数据集成期间另一个容易产生的数据冗余问题,这一问题主要是因为录入错误或未及时更新造成的。
数据集成之后可能需要经过数据清理,以便清除可能存在的实体识别、冗余属性识别和元组重复问题。pandas中有关数据集成的操作是合并数据,并为该操作提供了丰富的函数或方法。
2 基于Pandas实现数据集成
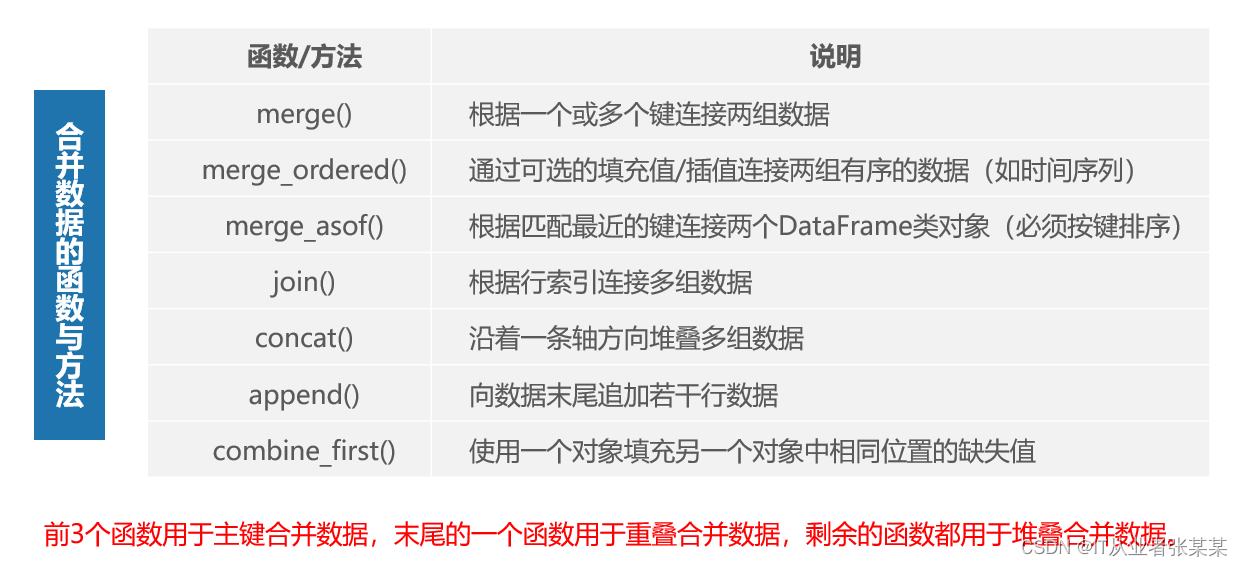
pandas中内置了许多能轻松地合并数据的函数与方法,通过这些函数与方法可以将Series类对象或DataFrame类对象进行符合各种逻辑关系的合并操作,合并后生成一个整合的Series或DataFrame类对象。基于这些方法实现主键合并数据、重叠合并数据和堆叠合并数据操作。
常用的合并数据的函数包括:
2.1 主键合并数据merge
主键合并数据类似于关系型数据库的连接操作,主要通过指定一个或多个键将两组数据进行连接,通常以两组数据中重复的列索引为合并键。
pd.merge(left, right, how='inner', on=None, left_on=None,
right_on=None, left_index=False, right_index=False, sort=False,
suffixes='_x', '_y', copy=True, indicator=False, validate=None)
参数含义如下:
left,right:参与合并的Series或DataFrame类对象。
how:表示数据合并的方式,支持’inner’(默认值)、‘left’、‘right’、'outer’共4个取值。
on:表示left与right合并的键。
sort:表示按键对应一列的顺序对合并结果进行排序,默认为True。
how参数的取值‘inner’代表基于left与right的共有的键合并,类似于数据库的内连接操作;'left’代表基于left的键合并,类似于数据库的左外连接操作;'right’代表基于right的键合并,类似于数据库的右外连接操作;'outer’代表基于所有left与right的键合并,类似于数据库的全外连接操作。
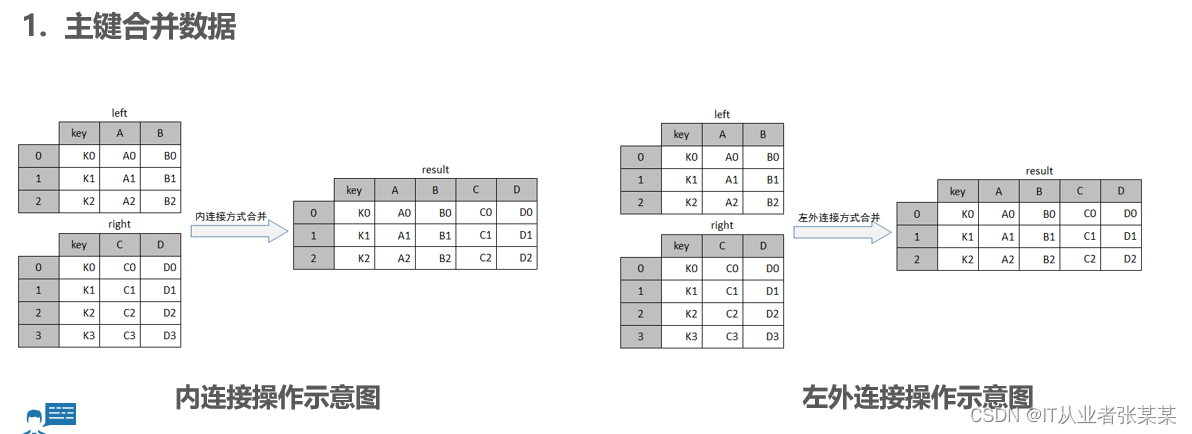
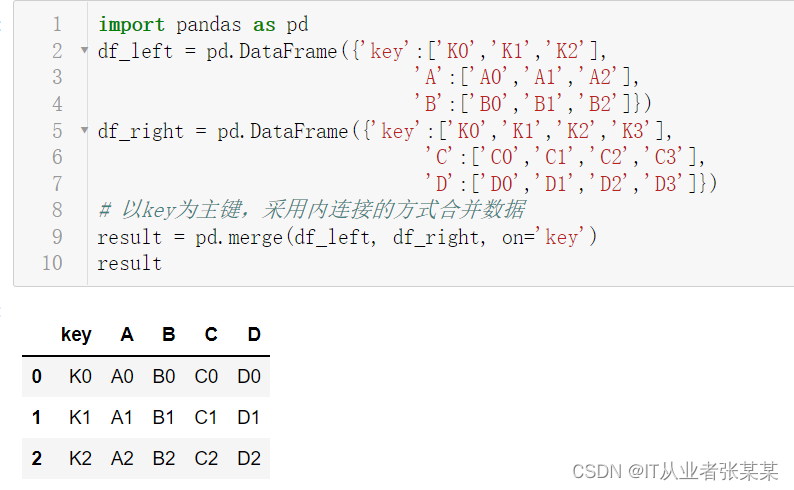
观察上图可知,result是一个3行5列的表格数据,且保留了key列交集部分的数据。
观察上图可知,result是一个4行5列的表格数据,且保留了key列并集部分的数据,由于A、B两列只有3行数据,C、D两列有4行数据,合并后A、B两列没有数据的位置填充为NaN。
示例代码如下:
内连接的方式合并数据:
import pandas as pd
df_left = pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
df_right = pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
# 以key为主键,采用内连接的方式合并数据
result = pd.merge(df_left, df_right, on='key')
result
输出为:
左外连接的方式合并数据
# 以key为主键,采用左外连接的方式合并数据
result = pd.merge(df_left, df_right, on='key', how='left')
result
输出为:

右外连接的方式合并数据:
# 以key为主键,采用右外连接的方式合并数据
result = pd.merge(df_left, df_right, on='key', how='right')
result
输出为:

全外连接的方式合并数据:
# 以key为主键,采用全外连接的方式合并数据
result = pd.merge(df_left, df_right, on='key', how='outer')
result
输出为:

在on参数中,也可以传入多个键:
df_left = pd.DataFrame({'k1':['K0','K1','K2'],
'k2':['A0','A1','A2'],
'B':['B0','B1','B2']})
df_left
输出为:

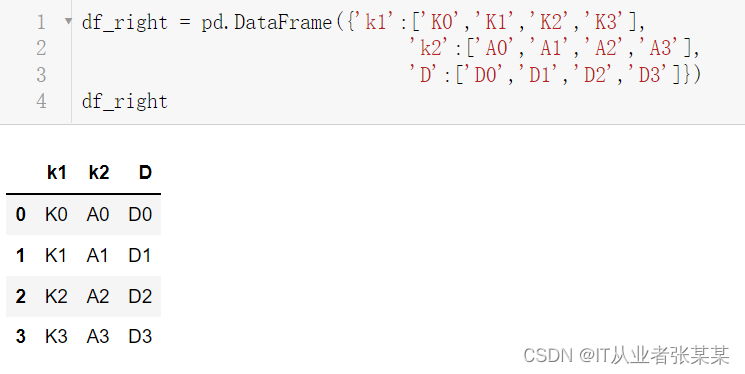
df_right = pd.DataFrame({'k1':['K0','K1','K2','K3'],
'k2':['A0','A1','A2','A3'],
'D':['D0','D1','D2','D3']})
df_right
输出为:
pd.merge(df_left,df_right,on=['k1','k2'], how='outer')
输出为:

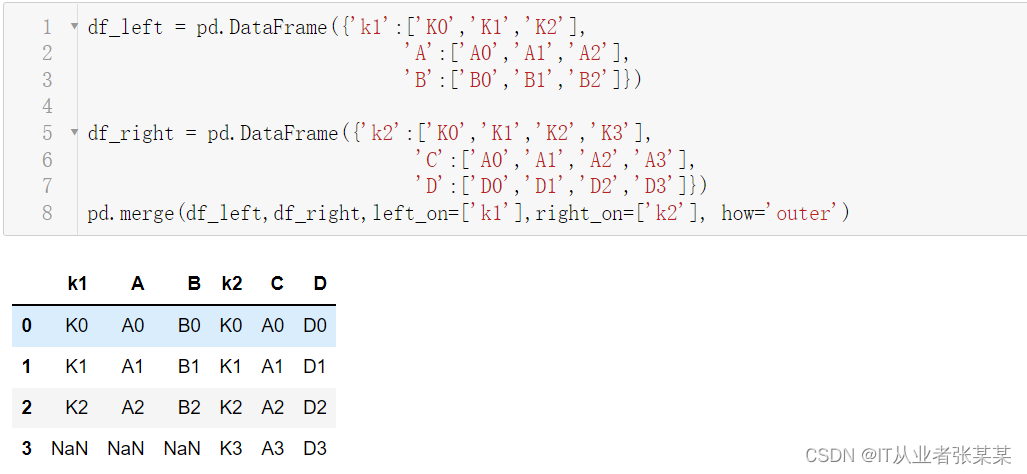
如果两个对象的列名不同,可以使用left_on,right_on分别指定:
df_left = pd.DataFrame({'k1':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
df_right = pd.DataFrame({'k2':['K0','K1','K2','K3'],
'C':['A0','A1','A2','A3'],
'D':['D0','D1','D2','D3']})
pd.merge(df_left,df_right,left_on=['k1'],right_on=['k2'], how='outer')
输出为:
2.2 堆叠合并数据concat
堆叠合并数据类似于数据库中合并数据表的操作,主要沿着某个轴将多个对象进行拼接。
pandas.concat(objs, axis=0, join='outer', join_axes=None,
ignore_index=False, keys=None, levels=None, names=None,
verify_integrity=False, sort=None, copy=True)
参数含义如下:
join:表示合并的方式,可以取值为’inner’或’outer’(默认值),其中’inner’表示内连接,即合并结果为多个对象重叠部分的索引及数据,没有数据的位置填充为NaN;'outer’表示外连接,即合并结果为多个对象各自的索引及数据,没有数据的位置填充为NaN。
ignore_index:是否忽略索引,可以取值为True或False(默认值)。若设为True,则会在清除结果对象的现有索引后生成一组新的索引。
axis轴的说明:
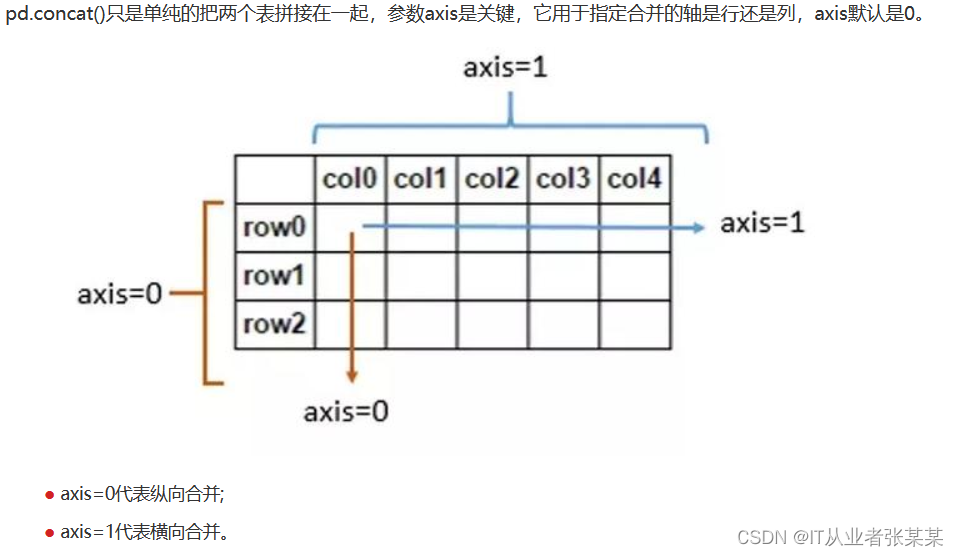
行合并:
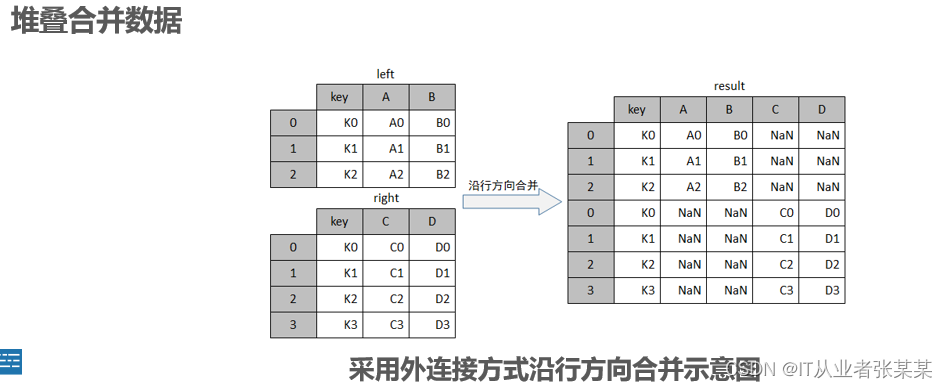
观察上图可知,result对象由left与right上下拼接而成,其行索引与列索引为left与right的索引,由于left没有C、D 两个列索引,right没有A、B两个列索引,所以这两列中相应的位置上填充了NaN。
列合并:
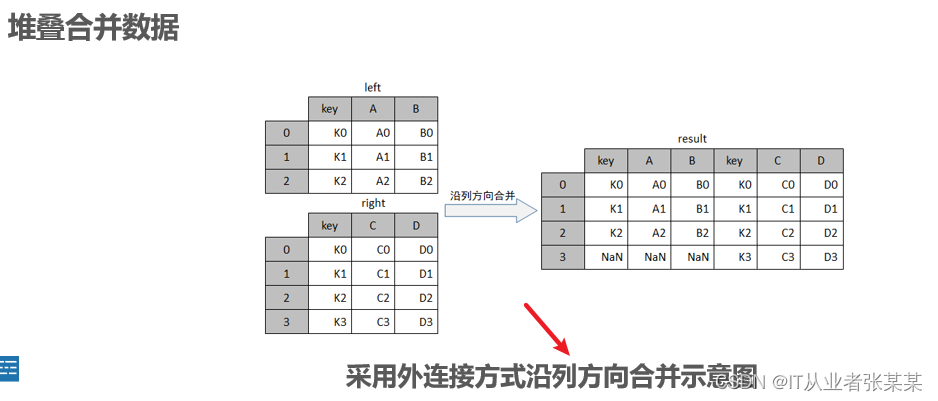
观察上图可知,result对象由left与right左右拼接而成,由于left没有3这个行索引,所以这行相应的位置上填充了NaN。
示例代码如下:
import pandas as pd
df_left = pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
df_right = pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
# 采用外连接方式,沿行方向合并数据
result = pd.concat([df_left, df_right], axis=0)
result
输出为:

2.3 重叠合并数据combine_first
当两组数据的索引完全重合或部分重合,且数据中存在缺失值时,可以采用重叠合并的方式组合数据。重叠合并数据是一种并不常见的操作,它主要将一组数据的空值填充为另一组数据中对应位置的值。pandas中可使用combine_first()方法实现重叠合并数据的操作。
combine_first(other)
参数含义如下:
other参数:表示填充空值的Series类或DataFrame类对象。
import numpy as np
from numpy import NAN
import pandas as pd
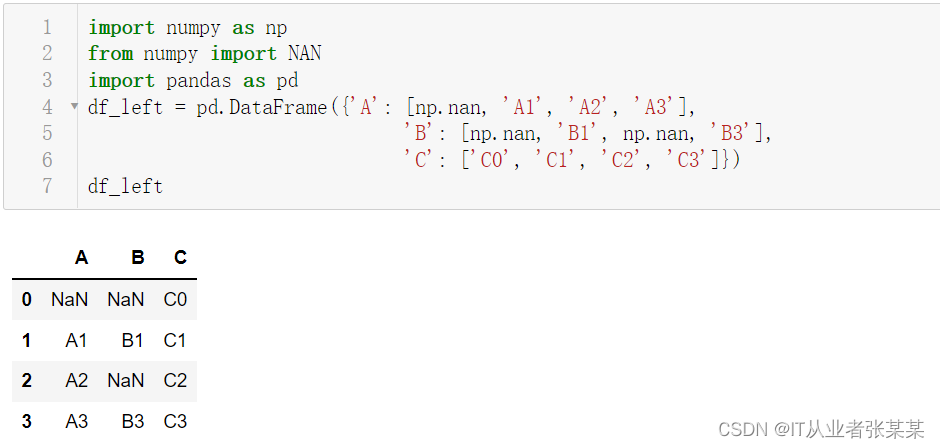
df_left = pd.DataFrame({'A': [np.nan, 'A1', 'A2', 'A3'],
'B': [np.nan, 'B1', np.nan, 'B3'],
'C': ['C0', 'C1', 'C2', 'C3']})
df_left
输出为:
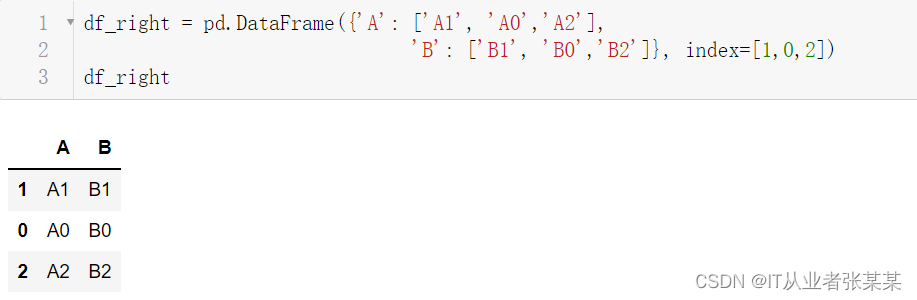
df_right = pd.DataFrame({'A': ['A1', 'A0','A2'],
'B': ['B1', 'B0','B2']}, index=[1,0,2])
df_right
输出为:
# 采用重叠合并的方式组合数据
result = df_left.combine_first(df_right)
result
输出为:

2.4 追加合并数据append
Pandas可以通过append实现纵向追加:
df1 = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
print(df1)
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
print(df2)
# 纵向追加
df1.append(df2, ignore_index=True)
输出如下:

Pandas可以通过append实现纵向追加,忽略索引:
# 忽略原来的索引ignore_index=True
df1.append(df2, ignore_index=True)
输出为:

2.5 基于索引合并join
join函数如下:
DataFrame.join(self, other, on=None, how=“left”, lsuffix="", rsuffix="", sort=False)
其中
other:DataFrame, Series, or list of DataFrame,另外一个dataframe, series,或者dataframe list。
on: 参与join的列,与sql中的on参数类似。
how: {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘left’, 与sql中的join方式类似。
lsuffix: 左DataFrame中重复列的后缀
rsuffix: 右DataFrame中重复列的后缀
sort: 按字典序对结果在连接键上排序
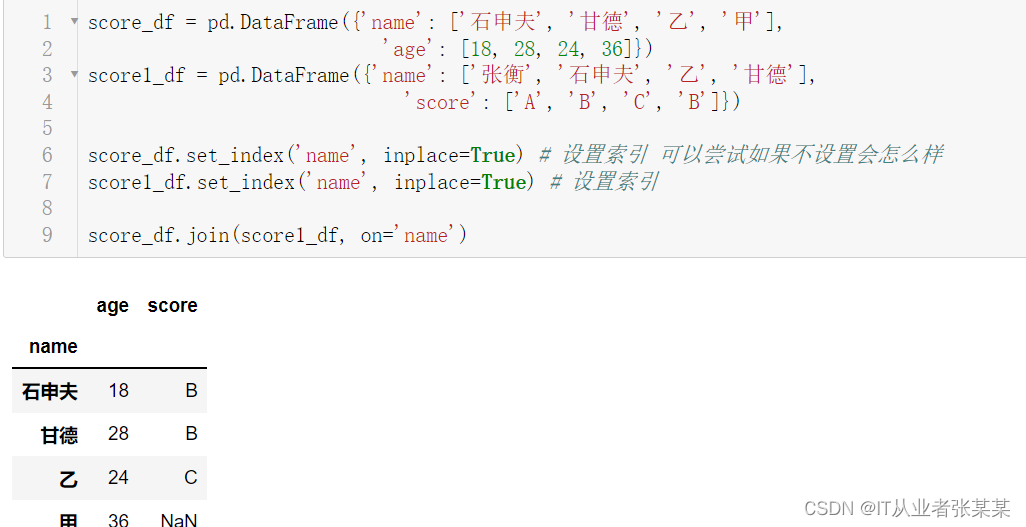
join方式为按某个相同列进行join:
score_df = pd.DataFrame({'name': ['石申夫', '甘德', '乙', '甲'],
'age': [18, 28, 24, 36]})
score1_df = pd.DataFrame({'name': ['张衡', '石申夫', '乙', '甘德'],
'score': ['A', 'B', 'C', 'B']})
score_df.set_index('name', inplace=True) # 设置索引 可以尝试如果不设置会怎么样
score1_df.set_index('name', inplace=True) # 设置索引
score_df.join(score1_df, on='name')
输出为:
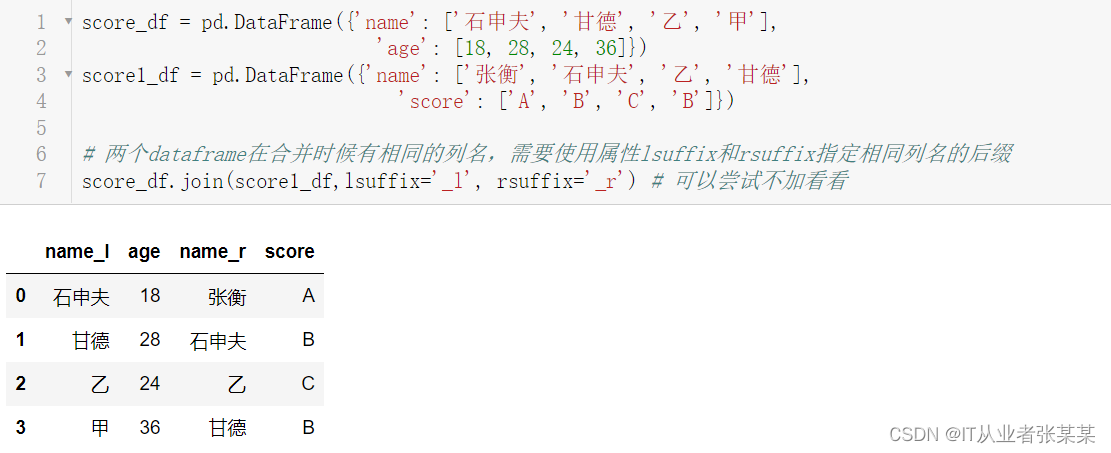
两个dataframe在合并时候有相同的列名join操作:
score_df = pd.DataFrame({'name': ['石申夫', '甘德', '乙', '甲'],
'age': [18, 28, 24, 36]})
score1_df = pd.DataFrame({'name': ['张衡', '石申夫', '乙', '甘德'],
'score': ['A', 'B', 'C', 'B']})
# 两个dataframe在合并时候有相同的列名,需要使用属性lsuffix和rsuffix指定相同列名的后缀
score_df.join(score1_df,lsuffix='_l', rsuffix='_r') # 可以尝试不加看看
输出为:
总结:
pandas包中,进行数据合并有join()、merge()、concat(), append()四种方法。它们的区别是:
df.join() 相同行索引的数据被合并在一起,因此拼接后的行数不会增加(可能会减少)、列数增加;
df.merge()通过指定的列索引进行合并,行列都有可能增加;merge也可以指定行索引进行合并;
pd.concat()通过axis参数指定在水平还是垂直方向拼接;
df.append()在DataFrame的末尾添加一行或多行;大致等价于pd.concat([df1,df2],axis=0,join=‘outer’)。
join 最简单,主要用于基于索引的横向合并拼接
merge 最常用,主要用于基于指定列的横向合并拼接
concat最强大,可用于横向和纵向合并拼接
append,主要用于纵向追加
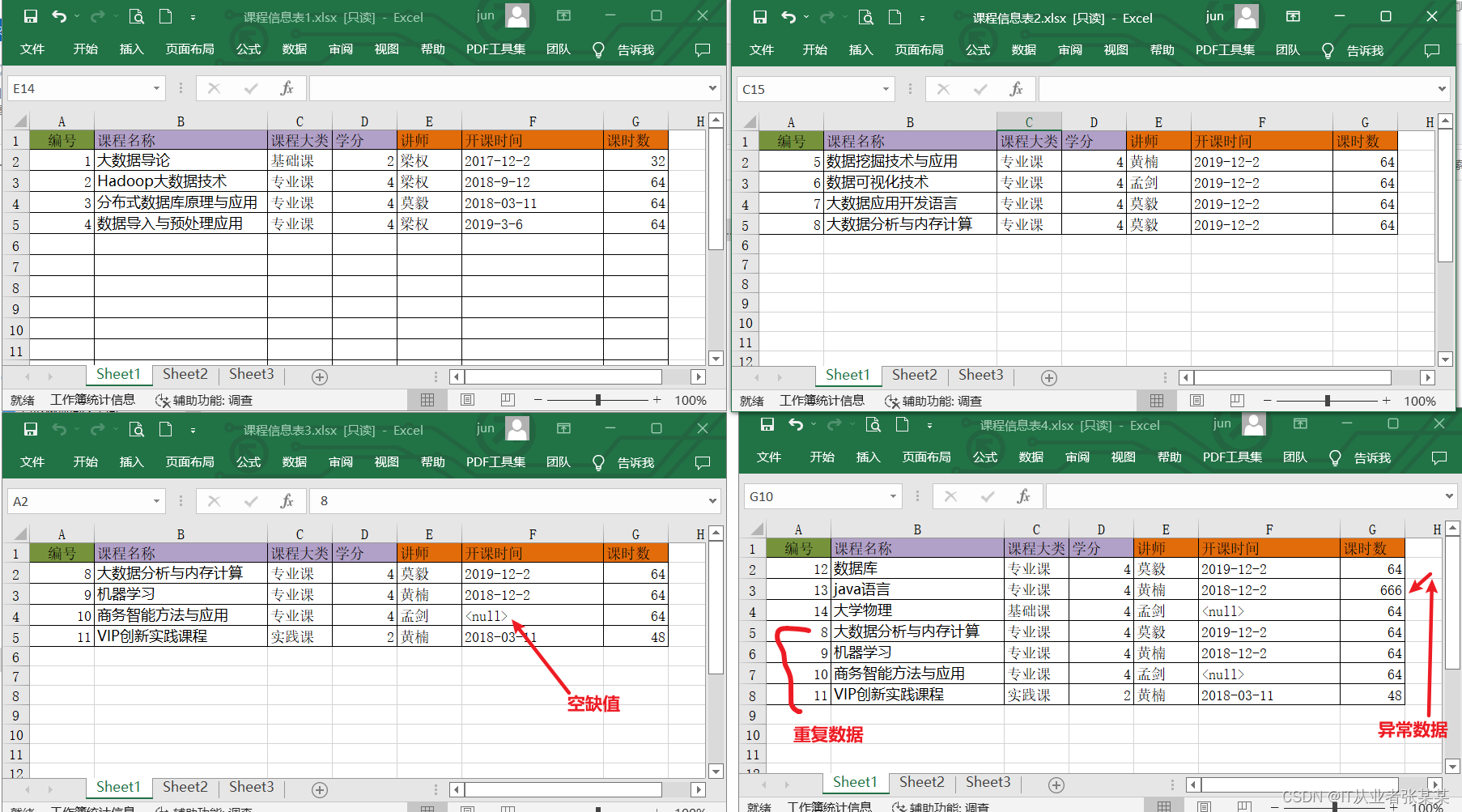
3 思考题
给出多个excel,如何合并成一个excel中:
案例数据如下:
https://download.csdn.net/download/m0_38139250/86751566
数据目录结构如下:
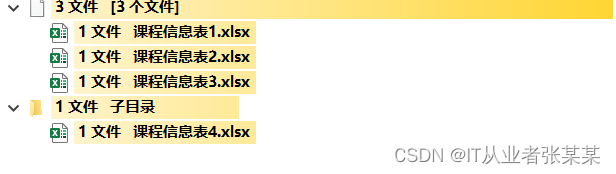 数据内容如下:
数据内容如下: