Redis的性能优化一些方案
Redis性能优化
客户端优化
- Pipeline批量操作
- 连接池的应用
设置合理的淘汰机制
- 设置合理的内存大小
- 设置合理的过期时间 (设置的太久,久而久之内存空间不够用了,设置的太短,key失效就会频繁的出现淘汰策略)
- 选择合适的淘汰策略
key与value的优化
Key设计
- 可读性和可管理性,以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如 业务名:表:id
- 简洁性,保证语义的前提下,控制key的长度,当key较多时,内存占有也不容忽视
- 不要包含特殊字符,比如:包含空格、换行、单双引号以及其他转义字符
Value设计
- 拒绝Bigkey(防止网卡流量、慢查询),string类型控制在10kb以内,hash、list、set、zset元素个数不要超过5000。
- 选择合适的数据类型
- 控制key的生命周期(设置有效时间),redis不是垃圾桶
BigKey的优化
什么样的Key才算是Big Key呢?
一般情况下,当key的值大于10Kb时就可以算是Big Key了。如下场景都是可能遇到Big key,比如:
- 粉丝列表
- 统计数据,比如PV或者UV统计
- 使用不当的数据缓存,比如通过String保存序列化后的用户数据等
出现了Big Key你也不用非常紧张,因为某些场景下不得不使用,下面我们看下如何进行发现与优化
发现Big Key
常规做法:redis-cli-bigkeys
优点:简单的扫描,不阻塞服务
缺点:信息量太少了 (只能看到元素的个数)
客户端访问cli
#无密码
./redis-cli --bigkeys
#有密码
./redis-cli -a 123456 --bigkeys
会返回两部分的内容,分别是: 上半部分的“扫描部分” 下面的是“统计部分”。
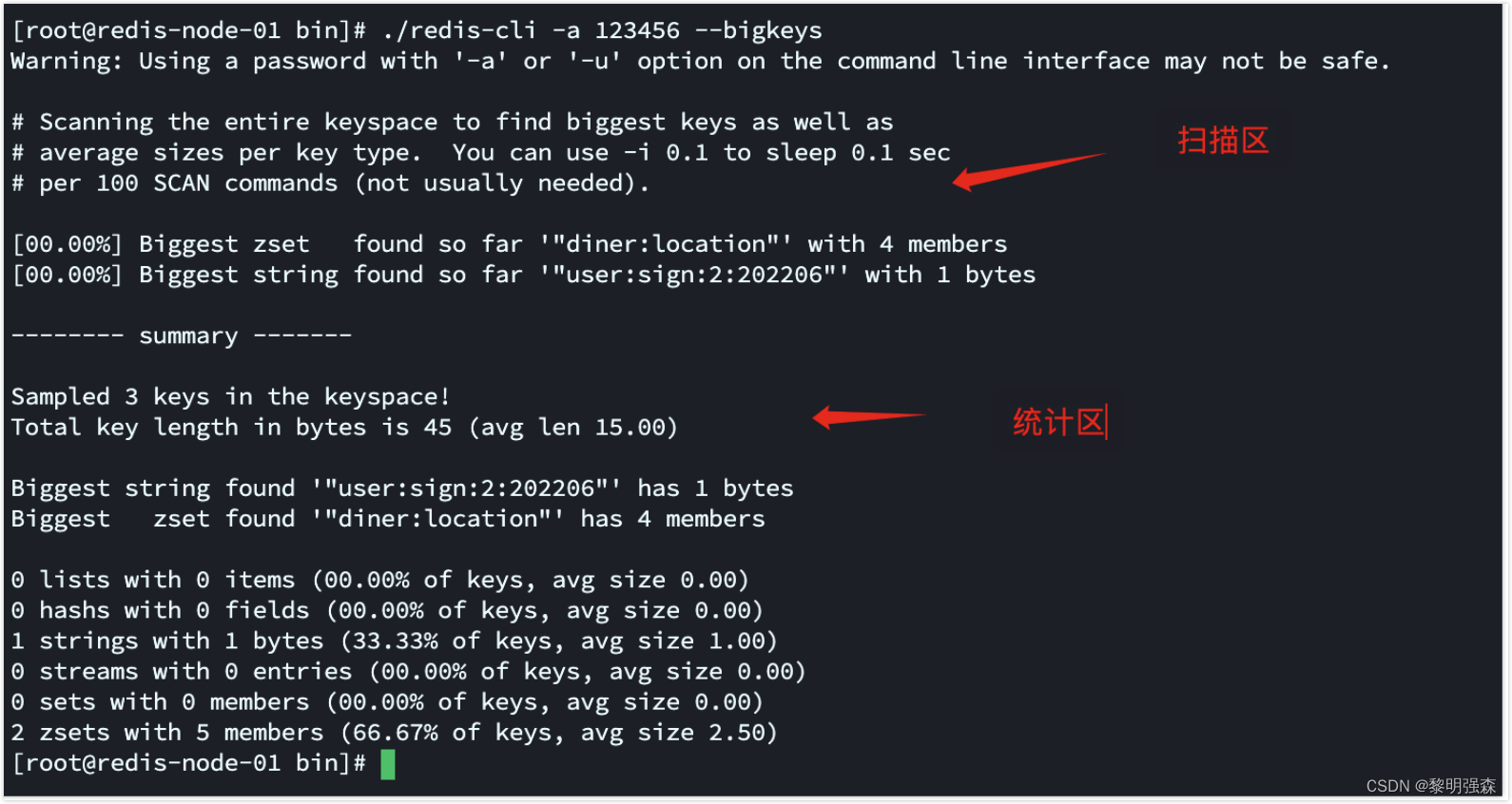
扫描区:会扫描当前redis最大的Key,(注意:但是并不代表它就是BigKey) ,只是告诉你当前环境最大的Key是比较大的。
比如上面的user:sign:202206 占了1个字节 。
Redis4.0之后的memory usage
命令 memory usage 给出

一个key和它值在RAM中占有的字节数,返回的结果是key的值以及为管理该key分配的内存总字节数。
所以查询Big key的手段就可以使用脚本进行查询,大概思路就是时使用scan游标查询key,然后使用memeory usage key 获取这个key与value的字节数,这样就能很方便的得出结论进行优化