2022年全国大学生数学建模美赛E题NPP数据获取
今年的数学建模美赛终于开始了!令我感到欣喜的是,今年E题竟然和地理遥感专业息息相关。E题是分析生态环境方面的!因此,有很多小伙伴来询问咨询如何解决这道题目。有些小伙伴,还咨询如何使用CASA软件来计算NPP数据!哈哈真的是令我感到惊讶!很多小伙伴都没学过gis遥感,竟然直接就上手来自己计算NPP。遇到了很多问题。

casa计算NPP软件获取链接:
E题题型怎么理解
E题环境科学,大体上会集中在环境污染、资源短缺、可持续发展、生态保护等几个方面。对问题的背景有一定的提示作用,但是范围仍然很广,模型、方法没有明显的特征。
所以,显然无法仅仅根据这些提示就进行选题,至多是,排除某个题目不考虑(如,计算能力差的队可以不选C题)。如果仅从选题的角度出发,搞清楚MCM竞赛与ICM竞赛的区别,可能更有帮助。
针对于E题的NPP计算流程,小编便出个流程教学。
一、数据准备
在软件运行之前,需要准备以下数据月平均温度栅格文件,单位为℃,由气象数据插值得到,时间范围与 NDVI 一致。 月总降水量栅格文件,单位为 mm,由气象数据插值得到,时间范围与 NDVI 一致。
月太阳总辐射 :栅格文件:单位为 MJ/m2,由气象数据插值得到,时间范围与 NDVI 一致。
NDVI 时间序列数据:栅格文件,由遥感数据计算得到。可以是一个时间序列,如:12 个月的 NDVI 数据。
植被类型图:栅格文件,确定各植被类型的空间分布。 静态参数文件该文件配置各植被类型的 NDVI 最大值、NDVI 最小值、SR 最大值、SR 最小值以及最大光能利用率(gC/MJ)。
二、设置结果文件存放路径
设置结果存放文件夹,所有结果都会输出到该文件夹下面。默认情况下,会输出年度植被净初级生产力(npp_sum)和植被年平均覆盖率(veg_cov_mean),如果勾选了“同时输出 NPP 及植被覆盖度时间序列文件”复选框,则还会额外输出每个月的植被 NPP及植被覆盖度。
三、实验过程
1.数据来源及说明
遥感数据:来源于地理遥感生态网所提供的 2020年的 NDVI 影像。该数据集经过最大值合成法 MVC(Maximum Value Composites) 处理,空间分辨率为 1km,时间分辨率为逐月。
气象数据:来源于地理遥感生态网 2020 年的月降水量、月平均气温和月总太阳辐射数据,共覆盖东北地区的 107 个气象站点。为保持气象和遥感数据在空间上的一致性,利用插值工具将点数据转换为空间分辨率为 1km 的面栅格数据。文中所有数据均使用以 WGS 84 为基准面的 Albers 等面积圆锥投影。
植被类型图:植被类型图为来源于地理遥感生态网 的 2020年30m精度中国植被类型图。
2.数据处理
(1)月平均温度空间插值(克里金插值法必做) 启动 ArcGIS,并加载气象(温度和降水)站点数据和东北地区边界数据,在 ArcGIS 中加载温度数据(excel 格式)。气象(温度和降水)站点数据属性表与温度数据(excel 格式)属性表建立连接。
(2)降水量插值
(3)辐射量插值
(4)启动 ENVI 软件,选择 File→Open,打开 12 个月的温度插值数据。在 Toolbox 工具箱中,双击 Raster Management→Layer stacking 进行波段叠加,打开 Layer Stacking Parameters 窗口。单击 Import File…按钮,弹出 Layer Stacking Input File 窗口,选中 12 个月的温度插值数据,单击 OK。输入的文件将出现在 Selected Files for Layers Stacking 列表中,如果不一致可通过 Reorder Files…按钮来调整波段顺序。数据加载进来后,会自动读出图像投影信息和像元大小。Resampling(重采样)方法使用缺省值,即 Nearest Neighbor。单击 Inclusive 和 Exclusive,选择输出文件范围。如果选择 Inclusive,输出图像的地理范围将是所有输入文件范围的并集;如果选择 Exclusive,输出图像的地理范围仅包含所有输入文件的重叠范围。此处选用缺省值 Inclusive。设置文件名及存储路径,单击 OK。波段叠加后,band1 表示 1 月的气温数据,band2 表示 2 月的气温数据。
(5)NDVI 时间序列
在 ENVI 中打开 2020 年 NDVI 时间序列数据时,由于背景值为-9999,像元值范围在[0,1](NDVI 值范围在[-1,1],该数据已经去除由于云、积雪等影响而出现的负值),数值之间差距太大,图像呈现为黑色。在 Toolbox 工具箱中,双击 Raster Management→Edit ENVI Header 工具,在 Data Ignore Value 文本框中填入-9999,忽略背景值影响。
(6)植被类型图
根据实验需求,在 ENVI 中打开经处理后的东北地区植被类型图,如图所示。植被类型主要有:针叶林、阔叶林、针阔混交林、灌丛、草地、栽培植被、沼泽、荒漠和非植被。
(7)静态参数文件生成
引用朱文泉教授研究结果,配置 9 类植被类型的 NDVImax、NDVImin、SRmax、SRmin 和 Emax(理想状态下最大光能利用率)参数。 其中 NDVImax 和 SRmax 的计算需要东北地区植被类型图和 NDVI 时间序列最大值数据。
①NDVI 时间序列最大值计算方法:在 ENVI 中打开 NDVI 时间序列数据 ,在 Toolbox 工具箱中,双击 Band Algebra→Band Math 工具,打开 Band Math 对话框。在 Enter an expression(运算表达式输入框)中输入表达式:b1>b2>b3>b4>b5>b6>b7>b8>b9>b10>b11>b12 。单击 Add to List 按钮,将表达式添加到列表中。单击 OK 按钮,打开 Variables to Bands Pairings 对话框,为运算表达式中各个变量赋予图像文件或者图像波段。在 Variables used in expression 列表框中选择变量 b1,在 Available Bands List 中为 b1 指定一个波段。利用同样的方法分别为所有变量指定波段。单击 Choose 按钮,选择文件名及路径保存结果,单击 OK 按钮,执行运算。
b1:选择 northeast_ndvi_2001 文件的第 1 个波段
b2:选择 northeast_ndvi_2001 文件的第 2 个波段
b3:选择 northeast_ndvi_2001 文件的第 3 个波段
b4:选择 northeast_ndvi_2001 文件的第 4 个波段
b5:选择 northeast_ndvi_2001 文件的第 5 个波段
b6:选择 northeast_ndvi_2001 文件的第 6 个波段
b7:选择 northeast_ndvi_2001 文件的第 7 个波段
b8:选择 northeast_ndvi_2001 文件的第 8 个波段
b9:选择 northeast_ndvi_2001 文件的第 9 个波段
b10:选择 northeast_ndvi_2001 文件的第 10 个波段
b11:选择 northeast_ndvi_2001 文件的第 11 个波段
b12:选择 northeast_ndvi_2001 文件的第 12 个波段
② 启动 ENVI Classic 经典版本,单击实用函数→NPP 估算,在植被 NPP 计算设置窗口中,选择配置静态参数按钮。在 npp 及植被覆盖度计算静态参数设置窗口中,选择计算 NDVImax,SRmax 按钮,依次选择东北地区植被类型图和 NDVI 时间序列最大值。在输入分类精度窗口中,输入 70,单击确定。得到 NDVImax 和 SRmax 结果,如图所示。
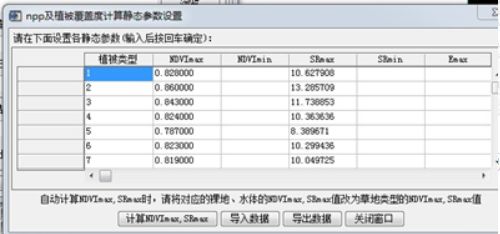
引用朱文泉研究结果,手动输入 NDVImin、SRmin 和 Emax 数据,如表 1 所示。完成后单击导出数据按钮,设置文件名(命名规则:静态参数设置 2020)和存放路径,生成 cfg 格式的静态参数文件。

(8)NPP 反演
启动 ENVI Classic 经典版本,单击实用函数→NPP 估算,在植被 NPP 计算设置窗口中,依次选入准备好的数据,单击完成,如图所示。
程序运行完成后,会弹出 npp 及植被覆盖度计算完成提示框(图 30)。 NPP 计算结果 经过程序计算后,会生成 4 个文件,如下所示: npp_sum:年度植被净初级生产力npp_time_series:每个月的植被 NPP veg_cov_mean:植被年平均覆盖率 veg_cov_time_series:每个月的植被覆盖度
实验结果制图输出

更多GIS教程学习与数据获取,可以关注地理遥感生态网
同时,地理遥感生态网上分享了很多地理遥感领域的科学数据(土地利用数据、npp净初级生产力数据数据、NDVI数据、气象数据(降雨量、气温、蒸散量、辐射、湿度、日照时数、风速、水汽压数据)、径流量数据、夜间灯光数据、统计年鉴、道路网、POI兴趣点数据、GDP分布、人口密度分布、三级流域矢量边界、地质灾害分布数据、土壤类型、土壤质地、土壤有机质、土壤PH值、土壤质地、土壤侵蚀、植被类型、自然保护区分布、建筑轮廓分布等等地理数据,以及关于gis、遥感从方面的操作教程)可以关注获取。
那么这一篇文章就讲到这里.大家动个小手帮忙点赞分享!
赶紧三连关注下, 数据获取途径如下:
