图像类找工作面试题(二)——常见问题大总结
文章目录
- 一、深度学习问题
- 1、目标检测系列
- (1)介绍目标检测网络YOLO以及SSD系列原理。
- (2)YOLO对小目标检测效果不好的原因,怎么改善?
- (3)怎么防止过拟合
- (4)DropOut层的作用是什么?
- (5)BN层的原理和作用分别是什么?
- (6)YOLO与RCNN网络的区别
- (7)目标检测中的评价指标是什么?
- (8)anchor、grounding truth, bounding box、候选框这些都是什么??
- 2、目标追踪系列
- (1)说一下deepsort算法的原理
- (2)说一下FairMOT的原理
- (3)仔细说一下FairMOT算法的网络结构(三个头)
- (4)FairMOT算法损失函数的表示形式是怎么样的??
- (5)DLA网络是什么?
- 3、身份识别
- (1)说一下身份重识别的原理
- (2)数据集怎么样?
- 4、其他深度学习问题
- (1)说一下损失函数的作用以及其准确的原理
- (2)说一下二分交叉熵损失函数和多分交叉熵损失函数
- (3)anchor-based和anchor-free有什么区别?
- (4)batch_size和epoch可以设置为多少?
- (5)池化层的作用是什么?
- (6)全连接层的作用
- (7)Python装饰器是什么?
- (8)batch-normalization的过程是怎么样的?
- (9)Softmax层的作用是什么?
- (10)CNN的平移不变性是什么?怎么实现?
- (11)VGG、GoogleNet、ResNet之间的区别是什么?
- (12)残差网络为什么能解决梯度消失问题?
- (13)LSTM为什么能解决梯度消失和梯度爆炸问题?
- (14)常见的模型加速方法
- (15)怎么解决目标检测中前景多背景少的问题?
- (16)detection你认为还有什么可以做的?
- 二、传统图像识别问题
- 1、图像处理的基本步骤
- 2、怎么使用传统图像处理办法识别我手中的一瓶水?
- 3、霍夫变换的基本原理
- 4、SIFT/SURF的基本原理能否说清(这个较难,因为比较多)
- 5、谈谈深度学习与机器视觉的区别
- 6、谈谈图像的滤波
- 7、数据预处理的步骤有哪些(可以分普通数据与图像数据)
- 三、综合面试问题
- 1、未来五年的职业规划
- 2、谈谈自己性格的优缺点
- 3、为什么选择我们公司
一、深度学习问题
1、目标检测系列
(1)介绍目标检测网络YOLO以及SSD系列原理。
目前比较具有代表性的目标检测算法可以分为两大流派,一个是以fasterRCNN为主的二阶段算法,第二个是以YOLO和SSD为主的一阶段算法(one-stage)。fasterRCNN的原理是先用一个RPN(region proposal network)提取region proposal,再用一个分类网络判断RP中是否含有目标,所以fasterRCNN的检测阶段其实是分类问题。
YOLO:
YOLOv1:是one-stage的开山之作,它将目标检测看成了回归问题,直接从图像像素得到边界框坐标和类别概率。不同于RCNN只对某个RP预测,YOLOv1可以看到整张图像,所以预测错误的概率比fasterRCNN要小,YOlov1的预测结果,精确率高,但是召回率低,定位误差多。YOLOv1的 损失函数由:回归框loss、置信度loss和分类loss三个部分组成。
YOLOv2:解决了YOLOv1定位误差多,召回率低的问题。相比于v1,它做了如下改进:
(1)增加BN层,移除dropout层,这一操作可增加mAP
(2)使用高分辨率的分类器,v2使用448X448的分辨率微调分类网络,使模型在检测数据集之前适应了高分辨率输入。
(3)增加了anchor box,v1用的是全连接预测bbox的位置坐标;v2借鉴了FasterRCNN中RPN网络的anchor box策略,移除了YOLOv1的全连接层,采用了卷积和anchor boxes来预测边界框,提高定位精度。值得一提的是,v2的检测模型输入是416X416维度,经过32倍的下采样,会很容易找到中心点。对于一些大物体,它们中心点往往落入图片中心的位置,这样我们就可以通过中心点预测它的边界框。YOLOv1只预测7X7X2=98个框,v2预测的边框个数为13X13Xanchor_num,这样虽然损失了一点map,但是召回率提高了不少。
YOLOv3是原作者在YOLOv2上的一些改进,首先将骨干网络从Darknet19改进为DarkNet-53,利用特征金字塔实现了多尺度检测,使用逻辑回归代替了softmax层。
Darnet53与19相比,主要做出了如下改进:
- 引入了残差网路的思想
- 在网络中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的
引入了FPN网络,解决了小目标检测效果不好的问题,骨干网络使用DarkNet53,分类器由softmax改为了sigmoid。SSD
SSD算法是一种直接预测目标类别和bbox的多目标检测算法。传统的做法是先把图像转换成不同大小(图像金字塔),然后分辨检测,最后使用NMS。而SSD则利用不同卷积层的feature map进行总和也能达到同样效果。
算法的骨干网络是VGG-16,不过它将最后两个全连接层(FC)改成了卷积层,随后增加了4个卷积层来构造网络结果。对其中5中不同的卷积层输入(feature map)分别用两个不同的3X3卷积核进行卷积。一个输出的是分类用的置信度(confidence),每个bbox可生成21个类别confidence;一个输出回归用的localization,每个bbox生成4个坐标(x, y, w, h)。
多尺度feature map预测:接下来进行预测的时候,会对接下来的六个不同的尺寸分别进行预测,这六种不同的尺寸输出也就是后续检测层的输入。这六种尺寸分别包括6个不同大小的feature map,分别是38*38,19*19,10*10,5*5,3*3,1*1.
(2)YOLO对小目标检测效果不好的原因,怎么改善?
小目标像素特征少,不明显。小目标检测率低,这个在任何算法上都无法避免。目标检测算法对小目标检测效果不好的原因,在于卷积网络结果的最后一层feature map太小,例如3232的目标经过VGG网络会变成22,这就导致之后的检测和回归无法满足要求。卷积网络越深语义信息越强,越低则是描述的局部外观信息越多。相比于YOLO,SSD是多尺度特征图提取,它更稳定;YOLO只是通过全局特征直接得到预测结果,完全靠数据堆积,因此对于小目标可以考虑减少池化。
如果物体过小,在训练阶段,GT可能没有办法找到相应的default box与它匹配,效果肯定不好。可以考虑调低尺度或者进行多尺度预测。YOLOv2里边就是使用多尺度预测。
(1)小目标往往更依赖浅层特征,因为浅层特征有更高的分辨率,但是语义区分较差
(2)YOLOv1为了速度,本来是全卷积网络,但是却固定了尺寸,因此它对大图中的小物体检测效果较差。
(3)怎么防止过拟合
在数据层面,做数据增广,筛选高质量的特征
在网络层面,选择简单的模型,网络剪枝,加入正则项,加入drop-out层,加入BN层。
在训练操作界面,使用early stopping(早停法)
过拟合的表现形式:模型在训练数据中损失函数较小,预测准确率高;但在测试数据中损失函数较大,预测准确率较低。Dropout层可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
(4)DropOut层的作用是什么?
dropout层的主要作用就是为了防止过拟合,那么为什么可以防止过拟合呢?
(1)取平均的作用:我们用相同的训练数据训练5个不同的结果,此时可以采用“5个结果取均值”或者“多数取胜的投票策略”决定最终结果。例如3个网络判断结果为9,其他两个网络给出错误结果,那么很有可能这个结果就是9,这就是取平均的道理。同时因为不同的网络可能产生不同的过拟合,取平均可以让一些“相反的”拟合相互抵消。dropout掉不同的隐藏神经元,这种互为“反向”的拟合相互抵消就可以达到整体上的减少过拟合。
(2)减少神经元之间复杂的共适应关系:
(3)增加稀疏性:在数据量较小的时候,可以通过稀疏性,来增加特征的区分度。
(5)BN层的原理和作用分别是什么?
BN层的作用主要有三个:
(1)加快网络的训练和收敛的速度
在深度神经网络中,如果每层的数据分布都不一样的话,将会导致网络非常难收敛和训练,而如果把每层的数据都转换为均值为0,方差为1的状态下,这样每层的数据分布都是一样的,训练会比较容易收敛。
(2)控制梯度爆炸和防止梯度消失
梯度爆炸:
梯度消失:
(3)防止过拟合
(6)YOLO与RCNN网络的区别
首先,YOLOv1是anchor-free的one-stage目标检测算法;Faster:anchor-based是two-stage的目标检测算法
(1)YOLOv1并没有预先设置anchor,而是直接预测bbox,并针对每一个特征点,只预测2个候选框;FasterRCNN是feature map上的特征点预先设置9中尺寸的anchor,之后引入RPN网络,基于预先设置的anchor预测候选框的偏移(使预设的anchor在偏移后能更接近Ground Truth)。总的来说,YOLO的bbox和faster的anchor本质上不同。
(2)YOLO中的NMS算法仅在预测的时候使用;fasterRCNN是在训练RPN网络的时候已经用了NMS。总的来说,两个算法对于NMS的使用不同,这也和他们bbox和anchor的定义和使用有关。
(3)YOLO采用预测相对于当前grid cell左上角坐标的offset,宽高也是相对于特征图大小的值。而fasterRCNN首先预设了9中不同尺寸的anchor,fasterRCNN在预测中心点是是基于这些预设anchor的中心点进行计算偏移得到的。
(4)损失函数区别很大,YOLOv1的损失函数由5部分组成,
(7)目标检测中的评价指标是什么?
(0)TP:正样本,预测结果为正;FP:正样本,预测结果为负;
(0)TN:负样本,预测结果为正;FN:负样本,预测结果为负;
(1)精确率:又叫precision、查准率。就是预测是正例的结果中,确实是正例的比例。
TP+TN/(TP + FP + TN +FN)
(2)召回率:Recall、查全率。就是所有正例的样本中,被找出的比例。
TP/(TP + FN)
(3)PR曲线:查准率和查全率是一对矛盾的度量,所以引入PR曲线。
(4)top值:top1 & top3 & top5:
如果模型给出的最大概率值显示为狗,那这就是Top-1;
如果狗的预测概率值在给出的所有概率值中排在前5,那就是Top-5。
(5)map:AP是某一PR曲线下的面积;mAP是所有类别的AP值取平均。
(6)F1指数:精确率(prediction)和召回率(recall)的调和均值。
F1 = 2TP/(2TP + FP + FN)
(8)anchor、grounding truth, bounding box、候选框这些都是什么??
边界框(Bounding box)
它输出的是框的位置(中心坐标与宽高), confidence以及N个类别。用来表示物体的位置,一般有(xyxy)和(xywh)两种表现形式。
锚框(anchor box)
只是一个尺度即只有宽高;它与物体边界框不同,是由人们假想出来的一种框;先设定好锚框的大小和形状,再以图像上某一个点画出矩形框。在目标检测中,通常会以某种规则在图片上生成一系列锚框,将这些锚框当成可能的候选区域。模型对这些候选区域是否包含物体进行检测,如果包含目标物体,则还需要进一步预测出物体所属的类别。锚框不一定和物体边界框重合,所以需要模型进行预测微调的幅度。
预测框(prediction box)
是锚框微调后的结果,其结果更贴近真实框。
候选区域
每个锚框都有可能是候选区域,一张图片中会有很多锚框,想要判定哪个锚框是我们需要的,主要考虑三个方面:
(1)objectness标签:锚框中是否包含物体,可看成一个二分类问题 【是否包含】
(2)location标签:如果锚框包含物体,那么它对应的预测框中心位置和大小应该是多少。【位置】
(3)label标签:如果锚框包含物体,那么具体类别是什么? 【类别】
2、目标追踪系列
(1)说一下deepsort算法的原理
首先DeepSort算法的原理就是为了改善遮挡情况下的目标追踪效果,同时也可以减少目标ID跳变的问题。
多目标追踪大概可以分为以下几个步骤:
(1)给定视频原始帧
(2)运行目标检测器,如FasterRCNN、SSD、YOLO等目标检测,并获取目标检测框
(3)将所有目标框中对应的目标抠出来,进行特征提取(包括表观特征和运动特征)
(4)进行相似度计算,计算前两帧目标之间的匹配程度(前后属于同一个目标的之间距离小,不同目标距离较大)
(5)数据关联,为每个对象分配目标的ID。
因此,绝大多数MOT算法无外乎四个步骤(1)检测(2)特征提取(3)相似度计算(4)数据关联
Deep Sort算法在SORT算法的基础上增加了级联分配和新轨迹确认,它的总体流程如下:
(1)卡尔曼滤波预测轨迹Tracks
(2)使用匈牙利算法将预测的轨迹Tracks和当前帧中的detection进行匹配(级联匹配和IOU匹配)
(3)卡尔曼滤波更新,重复(1)
(2)说一下FairMOT的原理
FairMOT将整个任务分为目标检测分支和ReID分支,但是通过一个网络实现的;这里的骨干网络采用ResNet-34。同时为了适应不同规模的对象,将深层聚合网络(DLA)的一种变体用于骨干网。此外,上采样模块的所有卷积层都由可变形的卷积层代替,以便他们可以根据物体的尺寸和姿势动态调整感受野。这样生成的模型是DLA-34。这个网络可以为检测和重识别提供公平特征。
(3)仔细说一下FairMOT算法的网络结构(三个头)
三个头指的是FairMOT算法中的目标检测分支,三个头分别是热力图(heatmap head)、位置偏移(box offset head)和尺寸偏移头(size head)。
(4)FairMOT算法损失函数的表示形式是怎么样的??
FairMOT的损失函数由两部分组成,分别代表两个分支:目标检测分支和ReID分支。
目标检测分支基于centerNet,有三个头,分别用来估算热图、目标中心偏移和bbox尺寸。将对象检测视为高分辨率特征图上基于中心点的回归任务。通过对DLA-34的输出特征图应用3X3卷积(具有256个通道)来实现每个head,然后通过1X1卷积层来生成最终目标。
- 目标检测分支
(1)Heatmap head(作用是估计对象中心位置)
(2)Box Offset Head and size head
Box offset的作用是更精确的定位对象,估计每个像素相对于对象中心的连续偏移
size head的作用是负责估计每个位置上的目标边界框的高度/宽度

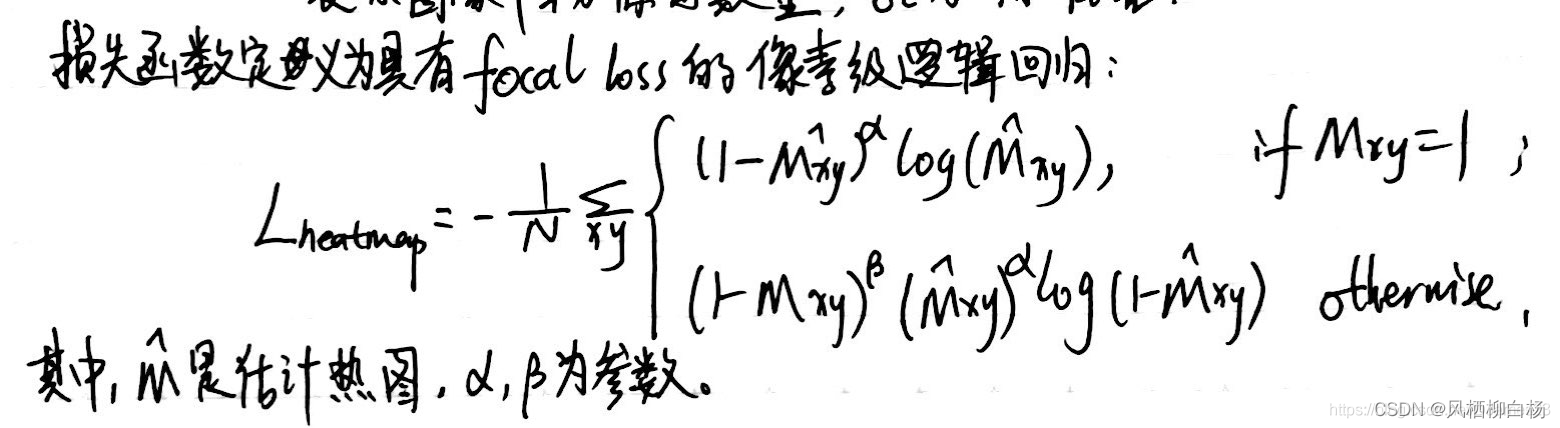

- ReID分支
ReID分支的目标是生成区分不同对象的特征。理想特征下,不同目标之间的距离大于同一目标之间的距离。【求相似度】
Re-ID loss
我们通过一个分类任务来学习ReID特征。训练集中具有相同身份的所有目标实例都被视为相同类别。

- 训练FairMOT使用的整体损失函数
加入以上三个损失函数后联合训练检测和ReID分支。特别地,我们使用不确定损失来自动平衡检测和ReID任务。

(5)DLA网络是什么?
更深层的神经网络可以提取更多的语义信息和全局特征,但这不代表最后一层是任务的最终表示,跳跃连接就已经证明了这一点,跳跃连接对分类和回归以及结构化任务是有效的
DLA是一种通用而有效的深度视觉网络拓展技术。DLA的使用可以在现有的ResNet、ResNetXt、DenseNet 网络结构的基础上再提升模型的性能、减少参数数量以及显存开销。
3、身份识别
(1)说一下身份重识别的原理
身份重识别使用的网络是ResNet50或者ResNet101。
(1)首先用标注好的图像训练ResNet网络,得到一个训练好的模型。
(2)其次将场景中可能出现的人的图像输入进网络模型,提取得到关键特征,并将关键特征存到mat矩阵中。
(3)测试时,使用YOLO等目标检测算法把多人图像中的单人图像提取出来,并通过训练好的模型得到单人图像特征。
(2)数据集怎么样?
身份识别的数据集就是图片【迁移训练等、数据扩充等】
4、其他深度学习问题
(1)说一下损失函数的作用以及其准确的原理
损失函数用来评价模型的预测值与真实值不一样的程度,损失函数越好,通用模型的性能越好。不同的模型用的损失函数一般也不一样。损失函数的作用也就是计算神经网络每次迭代的前向计算结果与真实值的差距,从而知道下一步的训练向正确的方向进行。
(2)说一下二分交叉熵损失函数和多分交叉熵损失函数
两者一般用来作为分类损失函数
交叉熵的表示一般是相对熵与信息熵的差值,二分交叉熵损失函数的值;
假设有y1个y2两个类别。那么二分交叉熵损失函数就是真实模型的概率分布与训练模型概率分布求log值的乘积。如果是两个类别,那就累加。之后在式子上加上负号,因为信息量(预测的结果)与它对应的概率是成反比的。
(3)anchor-based和anchor-free有什么区别?
通过anchor中有没有认识的目标和目标框偏移参考框的偏移量完成目标检测。两阶段和单阶段目标检测算法都有使用。
anchor-free是将目标检测转换为关键点检测问题,不同训练之前对当前训练数据聚类出多个宽高的anchor参数了,基于anchor-free的目标检测有两种方式:关键点检测、目标物体的中心点定位。
两个东西的区别:
(1)分类方式不同
anchor-based:首先计算来自不同尺度的anchor box与gt的IOU来确定正负样本,对于每个目标在所有IOU大于阈值K的anchor中,选择最大的作为正样本,所有IOU小于K的anchor作为负样本,其余忽略不计;最后针对正样本的anchor回归计算bbox的偏移量。
(2)回归方式不同
anchor-free:使用空间和尺度约束将anchor点分配到不同尺度上,通过判断特征图上的点是否落入GT来确认正负样本,即将物体边框内所有位置都定义为正样本;最后通过4个距离值和1个中心点的分数来检测物体。
(4)batch_size和epoch可以设置为多少?
设置batch_size为全数据集或者设置为1都有各自的缺点。设置合适的batch_size和样本有一定的关系,样本量少的时候会带来很大的方差,而这个大方差恰好会导致我们在梯度下降到很差的局部最优点。
(1)batch太小会导致训练速度变慢,训练不容易收敛
(2)具体的batch选取与训练集的样本数目相关。
(5)池化层的作用是什么?
在卷积神经网络中通常会在相邻的卷积层之间加入一个池化层,池化层可以有效的缩小参数矩阵的尺寸,从而减少最后连接层的中的参数数量。所以加入池化层可以加快计算速度和防止过拟合的作用。
池化的原理或者是过程:pooling是在不同的通道上分开执行的(就是池化操作不改变通道数),且不需要参数控制。然后根据窗口大小进行相应的操作。 一般有max pooling、average pooling等。
(1)首要作用,下采样(downsamping)
(2)降维、去除冗余信息、对特征进行压缩、简化网络复杂度、减小计算量、减小内存消耗等等。各种说辞吧,总的理解就是减少参数量。
(3)实现非线性(这个可以想一下,relu函数,是不是有点类似的感觉?)。
(4)可以扩大感知野。
(6)全连接层的作用
(1)一般位于卷积神经网络的最后,负责将卷积输出的二维特征图转换为一维的向量,由此实现端到端的学习过程。全连接层的每一个结点都与上一层的所有结点相连,因而称为全连接层。由于其全连接的特性,一般全连接层的参数也是最多的。
(2)卷积神经网络经过池化后,尺寸会大大削减,这个时候如果我们再使用一两层的全连接,计算量会大大减少。
(3)全连接就是组合特征和分类器的功能。
(7)Python装饰器是什么?
简言之,python装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使用python装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能。
(8)batch-normalization的过程是怎么样的?
BN解决的问题:
网络一旦训练起来,那么参数就会发生更新,除了输入层的数据外,后面网络每一层的输入数据分布是一直都在变化的,因为在训练的时候,前面层村联参数的更新导致了后面层输入数据分布发生变化。BN的提出,就是要解决在训练过程中,中间层数据分布发生改变的情况。事实上,在任何位置都可以进行数据归一化。
BN步骤主要分为4步:
(1)求每一个训练批次数据的均值
(2)求每一个训练批次数据的方差
(3)使用求得的均值与方差对该批次的训练数据做归一化,获得(0,1)正态分布。
(4)尺度变换与偏移,这是为了防止归一化后的输入被限制在(0,1)之间,使得网络变大能力下降。
经过上述几步变换,数据归一化就可以用下面的形式来进行表达:


(9)Softmax层的作用是什么?
SoftMax可以被看成是一个函数,一般用于处理分类任务中初始输出结果。
对于一个分类任务,它的输出一般是一个向量。因为可以通过向量的方式来表示某个类别。分类网络的输出结果是一个向量,只不过这个向量里边可以是任何值,而不是像label一样那么有规律。那么我们就可以使用分类网络的输出结果与label进行cross entropy来计算损失。softmax层的作用就是将任何与之连接的向量转换为(0,1)之间的数,这些数相加是等于1的。
(10)CNN的平移不变性是什么?怎么实现?
简单地说,图像经过平移,相应的特征图上的表达也是平移的。输入图像的左下角有一个人脸,经过卷积,人脸的特征(眼睛,鼻子)也位于特征图的左下角。假如人脸特征在图像的左上角,那么卷积后对应的特征也在特征图的左上角。
在神经网络中,卷积被定义为不同位置的特征检测器,也就意味着,无论目标出现在图像中的哪个位置,它都会检测到同样的这些特征,输出同样的响应。比如人脸被移动到了图像左下角,卷积核直到移动到左下角的位置才会检测到它的特征。
(11)VGG、GoogleNet、ResNet之间的区别是什么?
AlexNet :AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。整个AlexNet有8个需要训练参数的层(不包括池化层和LRN层),前5层为卷积层,后3层为全连接层,AlexNet最后一层是有1000类输出的Softmax层用作分类。
GoogLeNet:该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。使用1x1的卷积块(NIN)来减少特征数量,这通常被称为“瓶颈”,可以减少深层神经网络的计算负担。每个池化层之前,增加feature maps, 增加每一层的宽度来增多特征的组合性
VGGNet :VGG的巨大进展是通过依次采用多个3X3卷积,能够模拟出更大的感受野(receptive field)的效果,两个3X3卷积可以模拟出55的感受野,三个3X3的卷积可以模拟出77的感受野。VGGNet拥有5段卷积,每一段内有2~3个卷积层,同时每段尾部会连接一个最大池化层用来缩小图片尺寸。每段内的卷积核数量一样,越靠后的段的卷积核数量越多:64 – 128 – 256 – 512 – 512。
ResNet :ResNet声名鹊起的一个很重要的原因是,它提出了残差学习的思想。与普通的CNN相比,ResNet 最大的不同在于 ResNet 有很多的旁路直线将输入直接连到网络后面的层中,使得网络后面的层也可以直接学习残差,这种网络结构成为 shortcut 或 skip connection。这样做解决了传统CNN在信息传递时,或多或少会丢失原始信息的问题,保护数据的完整性,整个网络只需要学习输入、输出差别的一部分,简化了学习的难度和目标。
DenseNet :它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。
MobileNet:MobileNet 的基本单元是深度级可分离卷积(depthwise separable convolution——DSC),其实这种结构之前已经被使用在Inception模型中。从概念上来说,MobileNetV1正试图实现两个基本目标,以构建移动第一计算视觉模型:1,较小的模型,参数数量更少;2,较小的复杂度,运算中乘法和加法更少。遵循这些原则,MobileNet V1 是一个小型,低延迟,低功耗的参数化模型,可以满足各种用例的资源约束。它们可以用于实现:分类,检测,嵌入和分割等功能。
(12)残差网络为什么能解决梯度消失问题?
(1)残差网络提出跳层连接,也就是ResBlock。残差连接使得信息前后向传播更加通肠,由此解决了网络的退化问题。
ResNet的主要作用机理是跳跃连接的存在使得求导时可以将倒数直接回传到上一层,实现梯度的跨层传播。
(2)从梯度大小的角度解释,不管网络结构有多深,残差网络可以令靠近数据层(输入)的权重W保持一个较大的值,避免了梯度消失。
(3)因为在前向传播的时候添加了y = x+y(就是上图中右边的两个线),相当于添加了“高速公路”,在反向传播计算梯度的时候,不需要再经过那些权重层,也就不用从网络块中进行反向计算,因此更新的更快,也就收敛速度更快。

(13)LSTM为什么能解决梯度消失和梯度爆炸问题?
(14)常见的模型加速方法
从模型设计时就采用一些轻量化的思想,例如采用深度可分离卷积、分组卷积等轻量卷积方式,减少卷积过程的计算量。此外,利用全局池化来取代全连接层,利用1×1卷积实现特征的通道降维,也可以降低模型的计算量,这两点在众多网络中已经得到了应用。
对于轻量化的网络设计,目前较为流行的有SqueezeNet、MobileNet及ShuffleNet等结构。其中,SqueezeNet采用了精心设计的压缩再扩展的结构,MobileNet使用了效率更高的深度可分离卷积,而ShuffleNet提出了通道混洗的操作,进一步降低了模型的计算量。
(2)BN层合并
(3)网络剪枝
模型加速方法
(15)怎么解决目标检测中前景多背景少的问题?
为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
采用two stage的方式,用rpn先筛一遍。
(16)detection你认为还有什么可以做的?
就比如密集场景下的行人检测任务,上述的目标检测均不能得到很好的结果,由于人与人之间的遮挡,和人群分布的多样性,就算拟合能力无限强这样只会导致过拟合,在训练集上的效果好。这些算法无法解决两个同类之间的边框的偏移和NMS的误杀情况。
二、传统图像识别问题
1、图像处理的基本步骤
2、怎么使用传统图像处理办法识别我手中的一瓶水?
个人理解:
(1)拿到图像先滤波(一般用高斯,如果椒盐噪声比较多,先中值)。
(2)对图像进行直方图均衡化,提高图像的对比度,使特征更加明显。
(3)使用canny算子将图像转换成二值图像
(4)使用霍夫变换检测二值图像中的线条,并筛选固定的区域,得到一瓶水的线条
(5)rectangle画框,或者circle画圆,可视化。
3、霍夫变换的基本原理
简单的说,霍夫变换就是投票问题;但是如果往高深的说,霍夫变换是映射问题。
比如一条直线,在笛卡尔空间上,是若干个点表示的;但是如果把这条直线表示为ρ和 θ \theta θ的格式,在横坐标是 θ \theta θ,纵坐标为 ρ ρ ρ的坐标轴上,变现形式是很多条正弦曲线。
我们可以找正弦曲线的交点,正弦曲线的交点对应的ρ和 θ \theta θ就是我们想要找到的直线,同时也可以将其表示出来。
4、SIFT/SURF的基本原理能否说清(这个较难,因为比较多)
可以说Harris和Shi-Tomas角点检测。
5、谈谈深度学习与机器视觉的区别
6、谈谈图像的滤波
图像滤波可以大致分为线性滤波和非线性滤波
线性滤波:
(1)均值滤波
(2)高斯滤波
非线性滤波:
(1)中值滤波
(2)双边滤波
7、数据预处理的步骤有哪些(可以分普通数据与图像数据)
普通数据:
(1)数据清理:处理缺失数据、噪声数据等
删除数据,度量填补缺失值,预测填补缺失值
对噪声数据进行光滑操作,分箱操作。主要思想是将每个数据用其邻近的(箱或桶)代替,这样既可以光滑有序数据值,还可以使数据保持独有特点。回归处理,通过一个映像函数拟合多个属性数据,从而达到光滑数据的效果。离群点分析,聚类可以将相似的值归为同一“簇”,因此主要使用聚类等技术检测离群点。
(2)数据集成
数据集成就是将多个数据源合并存放在一个一致的数据存储(数据仓库)中的过程。在实际应用中,数据集成解决3类问题:实体识别、冗余和相关分析,以及数值冲突的检测和处理。
(3)数据变换,常用的数据变换操作有:数据规范化、数据离散化、概念分层等
三、综合面试问题
1、未来五年的职业规划
结合自身特点与职位需求。
(1)因为我的研究方向并不是纯粹的目标检测,但是YOLO等我也都完整的复现过,各种版本的论文我也都看过。所以如果有幸可以通过面试的话,我会在研三的大半年时间,把研究的内容向目标检测这方面侧重;我们这边的老师也有很多是从事目标检测方向的,有什么比较特殊的问题,都方便请教。
(2)如果有幸进入公司,我会抓紧时间适应工作,尽快上手。
(3)我会从现在开始,关注一些比较前沿的目标检测和图像处理知识。在入职之后,如果当前检测算法相对完善的话,可以对其进行维护和小trick;如果不太完善,我会去阅读大量论文,去寻找一种能适应当前场景的高效算法。
(4)XX是一个很漂亮的城市,希望可以在那里扎根
2、谈谈自己性格的优缺点
优点:
(1)勤奋:为什么选择考研?其实自己最注重的并不是学历的提升,而是自身知识储备量的提升;一个普通本科毕业能干什么??国内普本的教育其实是非常失败的,管理太松,以至于让学生觉得大学其实学习并不是第一位的。这也就导致很多本科毕业生基础不够扎实,专业技能掌握的不太好。我也是一样,但是幸运的是,我意识到这一点的时间比较早,于是我就开始考研。知识改变命运,这句话我是一直相信的。
(2)脾气好
我的父亲平常喜欢玩一些乐器,他的脾气很好,并且总是给我灌输“上善若水”的思想;所以我很少跟别人发脾气。
缺点:
(1)执拗:我还是比较喜欢搞研究的,如果一件事情不是很容易就能搞出来的话,我可能会废寝忘食。举个例子,为了配置GPU版本的OpenCV,好几天都没有回宿舍,累了就趴在桌子上睡一会儿。上班的时候,我会收敛一点,会以当前手头工作为主。
(2)缺少社会经验:毕竟没有真正的踏进过社会,虽然说与人交流不胆怯,但是有时候说话可能会不合时宜。但这到后面应该会改善的。
3、为什么选择我们公司
1、地点
2、