[深度学习] 名词解释--正则化
正则化
花书的定义:凡是可以减少泛化误差(过拟合)而不是减少训练误差的方法,都叫正则化方法。
目的:拟合训练数据,防止模型过拟合,通常使用L2正则化.用各种方法规范模型参数的方法.
什么是神经网络的过拟合:
在最小化损失函数的前提下,最优的一组w和b并不是唯一的。最后的最优的w和b是什么很依赖你输入的初始w和b。若初始过大,则最优的也相对较大。
所以,如何我们只在训练集里使用我们的神经网络,则w和b是大是小都没有太大关系,但要在一个新的测试集里使用我们的神经网络,那新数据在和这个较大的参数相乘后会得到一个比较大的数值。如果没有误差,没有噪声,这一切看起来也没有问题,但这是不可能的,所以这个误差和噪声在经过大的权重相乘后也会被放大,这就很容易对判断结果造成影响。
所以我们的目的是控制参数范围,不让它过大(正则化的目的):
我们重点约束w就行,因为最后的模型过拟合还是不过拟合,重点还是在w身上,所以正则化重点考虑w。更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀)
L1正则化
L1损失函数如下,首先,L1是通过稀疏参数(减少参数的数量)来降低复杂度 :

上式可知,当w大于0时,更新的参数w变小;当w小于0时,更新的参数w变大;所以,L1正则化容易使参数变为0,即特征稀疏化
L2正则化
L2正则化的损失函数为:

由上式可知,正则化的更新参数相比于未含正则项的更新参数多了  项,当w趋向于0时,参数减小的非常缓慢,因此L2正则化使参数减小到很小的范围,但不为0。
项,当w趋向于0时,参数减小的非常缓慢,因此L2正则化使参数减小到很小的范围,但不为0。
Lp范数:

所以从这里可以看出,当p>1时,才是个凸函数,其可行域都是凸集,所以也才是一个凸优化问题。
L0和L1之间的区别
L0范数是指向量中非0的元素的个数。如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。
个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。所以尽管L1范数和L0范数都可以实现稀疏,但L1因具有比L0更好的优化求解特性而被广泛应用。
L1和L2之间的区别及适用场景
L1在优化的时候,w在更新的时候,更偏向于收敛到0。也就是L1会趋向于产生少量的特征,而其他的特征都是0,使用L1可以得到稀疏的权值;所以L1适用于特征之间有关联的情况。 而L2在收敛的时候更偏向于收敛到到很小的参数,但一般不会是0。也就是L2会选择更多的特征,这些特征都会接近于0,使用L2可以得到平滑的权值;所以L2适用于特征之间没有关联的情况。 这个是什么缘由呢?其实就是,L2的求导后为一阶函数,对于大的w参数,惩罚作用大,对于小的w参数,惩罚作用小,很难惩罚到0,实际上起到了把大参数和小参数趋向于平均的作用;L1求导后为常数,无论对于大小参数,其惩罚作用一样,所以可以把小参数惩罚到0。
从拉格朗日对偶角度理解正则化:
这里J表示损失函数,
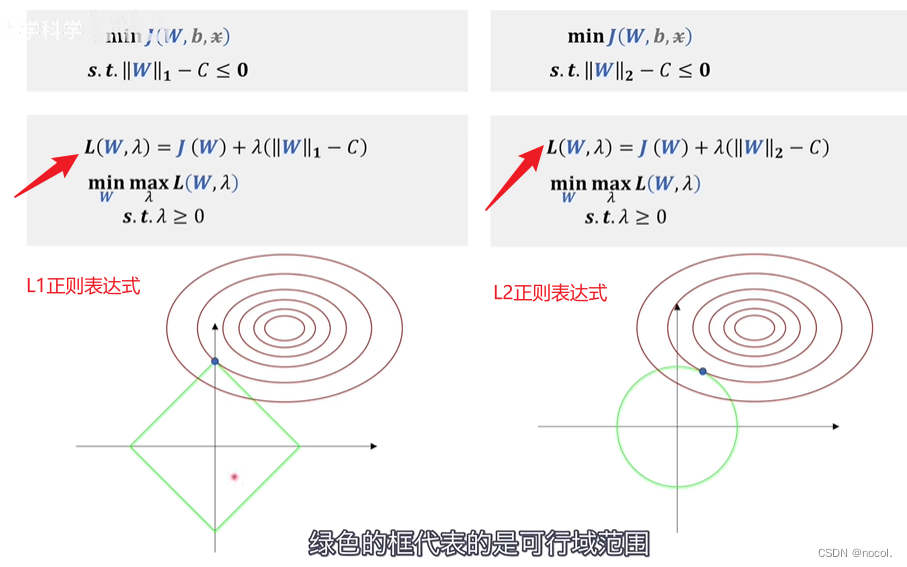
其中绿色是可行域范围,红色是损失函数等高线。
L1范数和L2范数的可行域都是凸集,所以这也是一个凸优化问题。
到这还不是我们经常看到的正则表达式的格式我们还需要将上式展开,以L2为例:


红色的梯度是损失函数J的梯度,绿色的是约束条件的对应可行域范围,也就是后面那一项的梯度。两者的梯度应该是方向相反的。就是用来控制两者的半径寻找切点,也就是我们的极值点的。

这里L1的极值点更多的分布在坐标轴上也就证明了为什么L1正则化更会造成w矩阵稀疏性的原因。
从权重衰减角度理解正则化:
什么是梯度下降法:梯度下降法其实就是对损失函数求梯度,得到的梯度乘以学习率,然后对原来的系数进行更新,更新之后得到新的权重参数值。
原来的权重更新的表达式和正则化后权重更新的表达式对比,n代表学习率:

区别就是前面w的系数变了,
从这可以看到,每一步权重的更新,W的值都会先进行一定程度的缩小,再减去本来应该学习的梯度值
所以,权重衰减就衰减到了W的系数上了。
权重衰减就是增加了一个惩罚项,每一次权重更新对权重W都惩罚一点,从而使权重不会太大
可是为什么加了惩罚项之后就可以避免过拟合呢?
神经网络的本质就是感知机的叠加去拟合各种曲线,

这样看着其实就过拟合了。

这样的可能才是刚刚好,泛化能力更好。 这个图是不是可以理解为:W越小,泰勒展开式的高阶导数越趋于0,那右边函数的曲线越光滑,也就是越不容易过拟合!
所以我们的目的是减少神经网络里面过多的弯弯绕绕,防止过拟合。
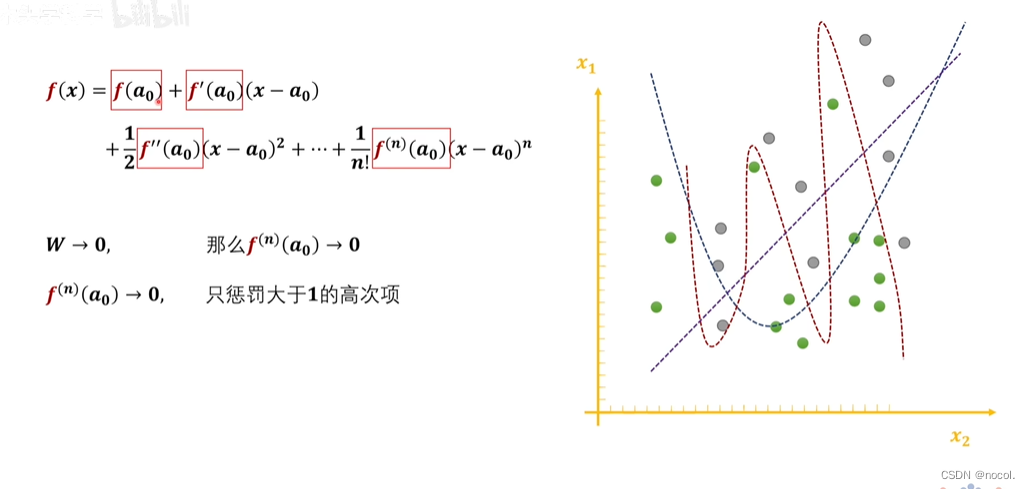
我们将曲线的函数表达式泰勒展开,高次项越多证明越弯曲,所以我们应该尽可能减少高次项对函数的影响。即控制高次项的系数。其实当我们控制了w不要太大,也就控制了高次项的系数越小。但是,经过正则化后的损失函数和原损失函数会存在一定的误差。