【CVPR2018】PSMNet:一个基于金字塔的端到端立体匹配网络
PSMNet:一个基于金字塔的端到端双目立体匹配网络
1.简介
在本研究中,我们提出了一种新的金字塔立体匹配网络(PSMNet)来利用立体匹配中的全局上下文信息。空间金字塔池(SPP)和扩张卷积用于扩大接受域。通过这种方式,PSMNet将像素级特征扩展到具有不同接受域尺度的区域级特征;由此得到的全局和局部特征线索被用来形成可靠的视差估计的成本量。此外,我们设计了一个堆叠沙漏三维CNN结合中间监督,以规范成本量。堆叠的沙漏3D CNN以自上而下/自下而上的方式重复处理成本量,以进一步提高对全局上下文信息的利用率。
我们的主要贡献如下:
- 提出了一个没有任何后处理的立体声匹配的端到端学习框架。
- 引入了一个金字塔池化模块,用于将全局上下文信息合并到图像特征中。
- 提出了一个堆叠沙漏三维CNN,以扩展上下文信息的区域支持。
- 2018年测试在KITTI数据集上实现了最先进的精度。
论文:https://arxiv.org/abs/1803.08669
代码:https://github.com/JiaRenChang/PSMNet
效果如下:

使用场景流测试数据进行性能评估。(a)左侧立体图像对的图像,(b)地面真实视差,以及使用PSMNet估计的©视差图
2.概述
立体图像的深度估计对于计算机视觉应用至关重要,包括车辆自动驾驶、三维模型重建、目标检测和识别。给定一对校正后的立体图像,深度估计的目标是计算参考图像中每个像素的视差d。差是指左右图像上一对对应像素之间的水平位移。对于左侧图像中的像素(x,y),如果在右侧图像中的(x−d,y)处找到其对应的点,则该像素通过fB/d计算其深度,其中f为相机的焦距,B为两个相机中心之间的距离。
一个典型的立体匹配算法包括四个步骤:匹配成本计算、成本聚合、优化和视差细化。
一些研究主要集中在视差图的后处理上:DRR网络通过检测不正确的标签,用新的标签替换不正确的标签,并改进更新的标签来改进标签;SGM-Net 学会了预测SGM惩罚,而不是手动调整的正则化惩罚。
端到端方法利用多尺度特征进行视差估计:DispNet、GC-Net:一个使用三维卷积进行成本体积正则化的端到端网络,应用编码器-解码器架构来规范成本量。
3.Pyramid Stereo Matching Network
- 我们提出了PSMNet,它由一个用于有效合并全局上下文的SPP]模块和一个用于成本体积正则化的堆叠沙漏模块(
encoder-decoder architecture/编-解码器)组成。PSMNet的体系结构如下图所示。
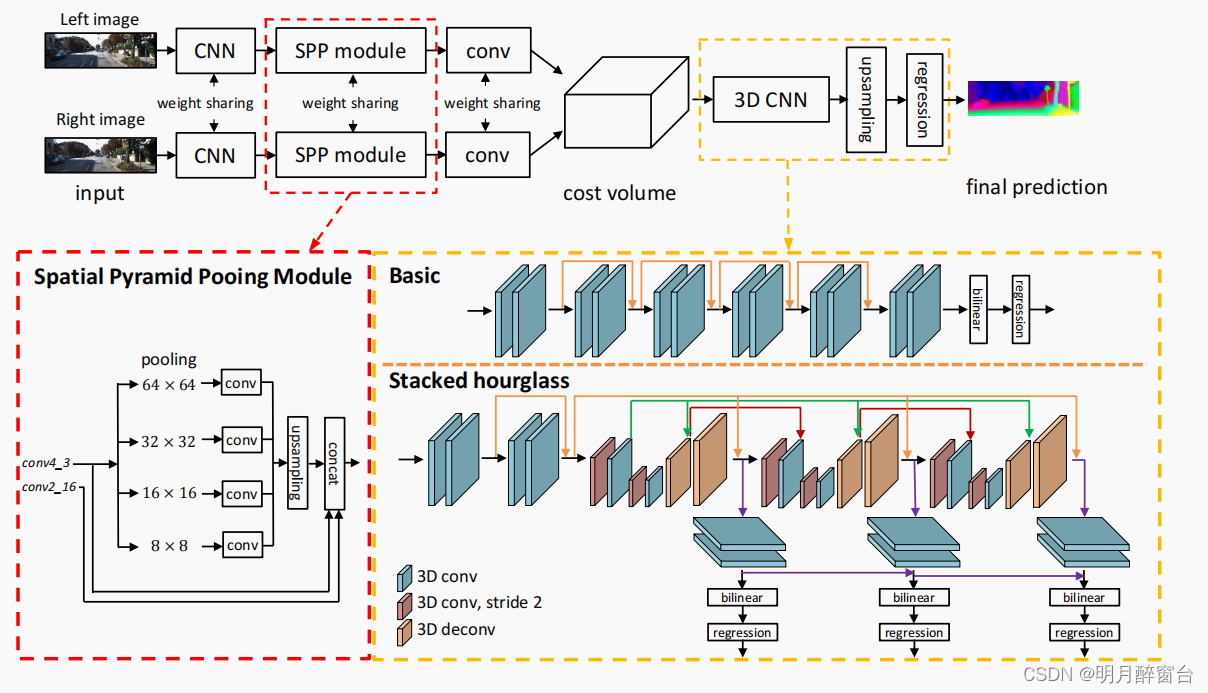
PSMNet流程如下:
- 输入图像:来自左、右两个相机的图像;
- 特征提取:采用参数共享的卷积网络进行特征提取,包含用于提取多分辨率特征的下采样和金字塔结构 ,也包括在扩大感受野的同时保持特征图分辨率不变的空洞卷积;
- Cost Volume构建:采用左、右两个图像经过卷积网络后得到的特征图构建Cost Volume;
- 特征融合:采用3D卷积提取左、右特征图及不同视差级别之间的信息,得到特征融合后的Cost Volume;
- 视差计算:将特征融合后的Cost Volume上采样到原始分辨率,找到匹配误差最小的视差值。
3.1 网络架构
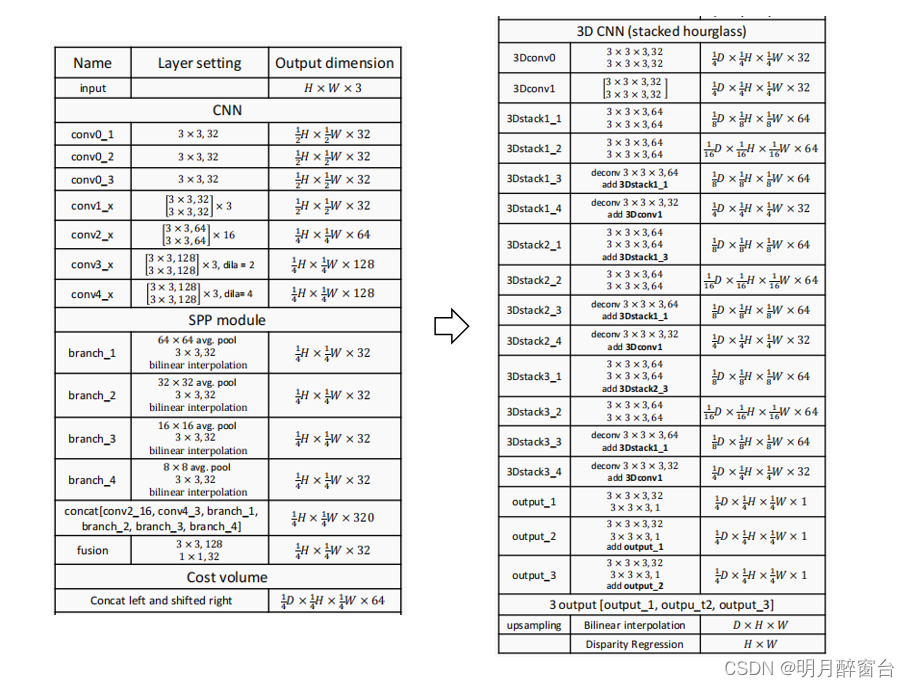
表1为建议的PSMNet体系结构的参数。残余块的执行在括号中指定,其中包括堆叠块的数量。降采样由conv0_1和conv2_1执行,步幅为2。批处理规范化和ReLU的使用遵循ResNet ,除了PSMNet在求和后不应用ReLU。H和W分别表示输入图像的高度和宽度,D表示最大视差。
所提出的PSMNet的参数详见上表1。与其他研究中的第一个卷积层应用大滤波器(7×7)相比,三个小卷积滤波器(3×3)被级联,以构建具有相同接受域的更深的网络。conv1 x、conv2 x、conv3 x和conv4 x是学习一元特征提取的基本残差块。对于conv3 x和conv4 x,采用扩张卷积来进一步扩大接受域。输出特征图大小为输入图像大小的1 4 ×1 4 ,如表所示。然后,将应用如图1所示的SPP模块来收集上下文信息。我们将左右特征映射连接到一个成本量中,并输入一个三维CNN进行正则化。最后,应用回归方法计算输出视差图。SPP模块、成本量、3D CNN和视差回归将在后面的章节中描述。
3.2 金字塔池化模块( Spatial Pyramid Pooling Module)
在目前的工作中,我们为SPP设计了4个固定大小的平均池化块: 64×64、32×32、16×16和8×8,如图1和表1所示。使用自适应平均池将特征压缩成四个尺度,然后进行1×1的卷积来降低特征维数,然后通过双线性插值,将低维特征图上采样到与原始特征图相同的大小。不同级别的特征映射被连接为最终的SPP特征映射。
3.3 成本量(Cost Volume)
MC-CNN 和GC-Net 方法不是使用距离度量,而是将左右特征连接起来,以学习使用深度网络的匹配成本估计。我们采用SPP特征,通过在每个视差级别上将左侧特征图与其对应的右侧特征图连接起来,形成一个成本体积,从而得到一个4D体积(高度×宽度×视差×特征大小)。
3.4 3D CNN
SPP模块通过涉及不同级别的特性来促进立体声匹配。为了沿着视差维度和空间维度聚合特征信息,我们提出了两种用于成本体积的三维CNN正则化结构:基本结构和堆叠沙漏结构。在基本的体系结构中,如图1所示,网络只是简单地使用剩余块来构建的。基本架构包含12个3×3×3卷积层。然后,我们通过双线性插值将成本体积上采样到H×W×D的大小。最后,我们应用回归计算大小为H×W的视差图,这在第3.5节中介绍。- 为了学习更多的上下文信息,我们使用了堆叠沙漏(编码器-解码器)架构,包括重复的自上而下/自下向上的处理以及中间监督,如图1所示。堆叠的沙漏架构有三个主要的沙漏网络,每个网络都生成一个视差图。也就是说,堆叠的沙漏体系结构有三个输出和损失(损失1、损失2和损失3)。损失函数详见第3.6节。在训练阶段,总损失计算为三个上采样回归双线性回归上采样连续损失的加权和。最终的视差图是三个输出中的最后一个。在我们的消融研究中,我们使用了基本结构来评估
SPP模块的性能,因为基本结构不像[End-to-end learning of geometry and context for deep stereo regression]中那样通过编码/解码过程学习额外的上下文信息。
3.5 视差回归(Disparity Regression)
我们使用在[End-to-end learning of geometry and context for deep stereo regression]中的视差回归来估计连续的视差图。每个视差d的概率是通过softmax操作σ(·)从预测的成本cd中计算出来的。预测的视差dˆ计算为每个视差d的概率之和,加权为:
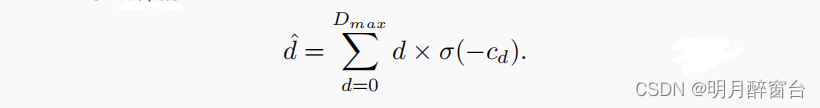
上述视差回归比基于分类的立体匹配方法更鲁棒。请注意,上面的方程类似于软注意力机制的方程。
3.6 损失函数(Loss)
由于视差回归,我们采用平滑的L1损失函数来训练所提出的PSMNet。与L2损失相比,平滑L1损失由于其鲁棒性和对异常值的敏感性低,被广泛用于目标检测的边界盒回归。
PSMNet的损失函数定义为:

4.实验
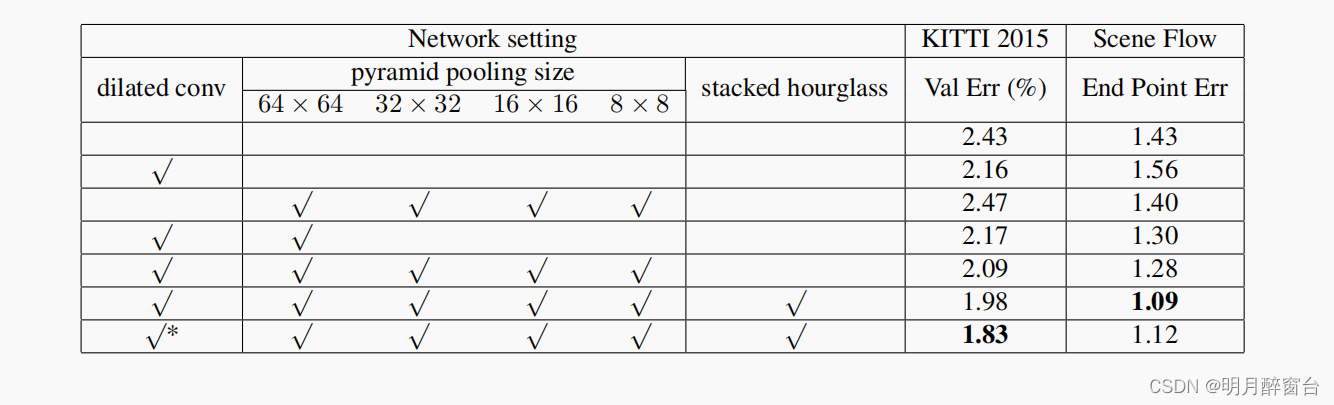
我们在三个立体数据集上评估了我们的方法:场景流,KITTI 2012,和KITTI 2015。我们还使用KITTI 2015和我们的架构设置进行了消融研究,以评估扩张卷积、不同大小的金字塔池和堆叠沙漏3D CNN对性能的影响。实验设置和网络实现情况见第4.1节,然后是对本研究中使用的三个立体数据集的评估结果。
- 场景流:一个大规模的合成数据集,包含35454张训练图像和4370张测试图像,使用H = 540和W = 960。这个数据集提供了密集和复杂的视差地图作为地面真相。一些像素有较大的视差,如果视差大于我们在实验中设置的极限,则被排除在损失计算中。
- KITTI 2015:一个真实的数据集的街景从驾驶汽车。它包含了200对使用激光雷达获得的具有稀疏地真差异的训练立体图像对,以及另外200对没有地真差异的测试图像对。图像大小为H = 376和W = 1240。我们进一步将整个训练数据划分为一个训练集(80%)和一个验证集(20%)。
- KITTI 2012:一个真实世界的数据集,从驾驶汽车的街景。它包含194个具有稀疏雷达稀疏地真差异的训练立体图像对和195个无地真差异的测试图像对。图像大小为H = 376和W = 1240。我们进一步将整个训练数据划分为一个训练集(160个图像对)和一个验证集(34个图像对)。本研究采用了KITTI 2012的彩色图像。
PSMNet架构是使用PyTorch实现的。所有模型均采用Adam(β1 = 0.9,β2 = 0.999)进行端到端训练。我们对整个数据集进行了颜色归一化,以进行数据预处理。在训练过程中,图像被随机裁剪到H = 256和W = 512的大小。最大视差(D)被设置为192。我们使用场景流数据集从零开始训练我们的模型,在10个时期的恒定学习率为0.001。对于场景流,训练后的模型直接用于测试。对于KITTI,我们在对KITTI训练集进行了300个时代的微调后,使用了使用场景流数据训练的模型。这种微调的学习率在前200个阶段为0.001,在剩下的100个时代为0.0001。对于4个nNvidiaTitan-Xpgpu(每个3个)的训练,批量大小设置为12。场景流数据集的训练过程约为13小时,KITTI数据集的训练过程约为5小时。此外,我们将训练过程延长到1000个epochs,以获得最终的模型和测试结果。
- 表2.对不同设置下的PSMNet的评估。我们计算了KITTI 2015验证集上的三像素误差的百分比,以及场景流测试集上的终点误差。*表示我们使用扩张卷积的扩张率的一半。
- 损失1、损失2和损失3的权重值对验证误差的影响。我们根据经验发现,0.5/0.7/1.0的性能最好。
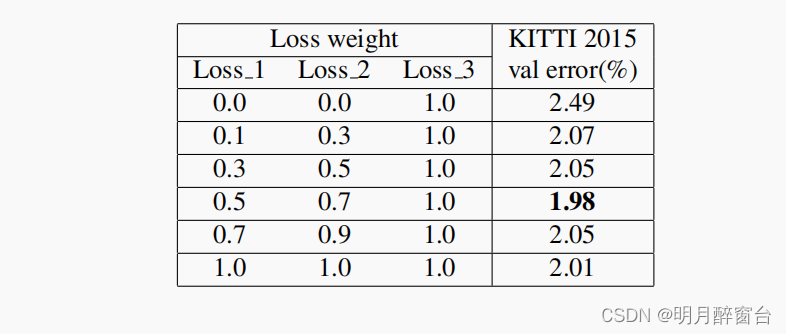
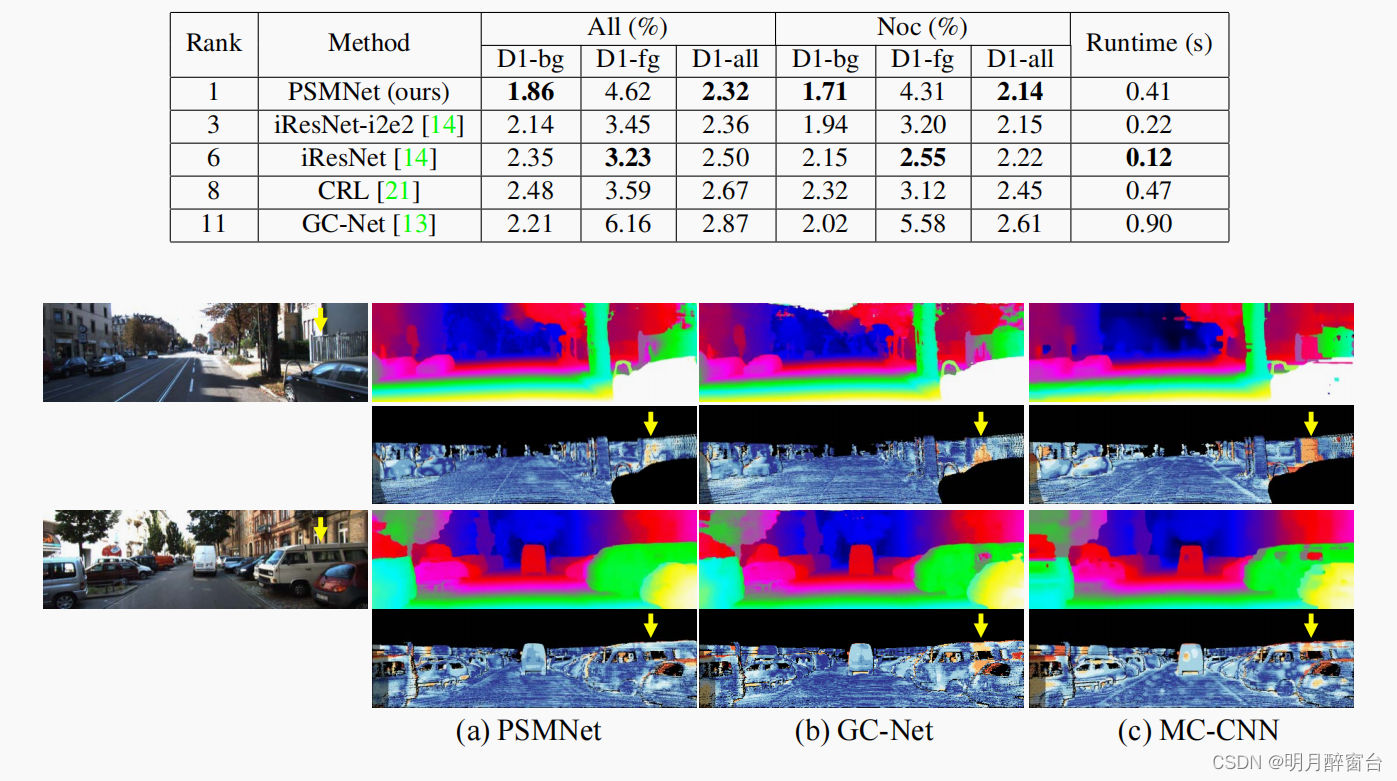
- 2015年3月18日,KITTI排行榜发布。结果显示,在所有测试图像中,误差超过3个像素的像素的百分比或视差误差的5%。只列出了已发布的方法以供比较。
- 与场景流测试集的性能比较。EPE:端点错误

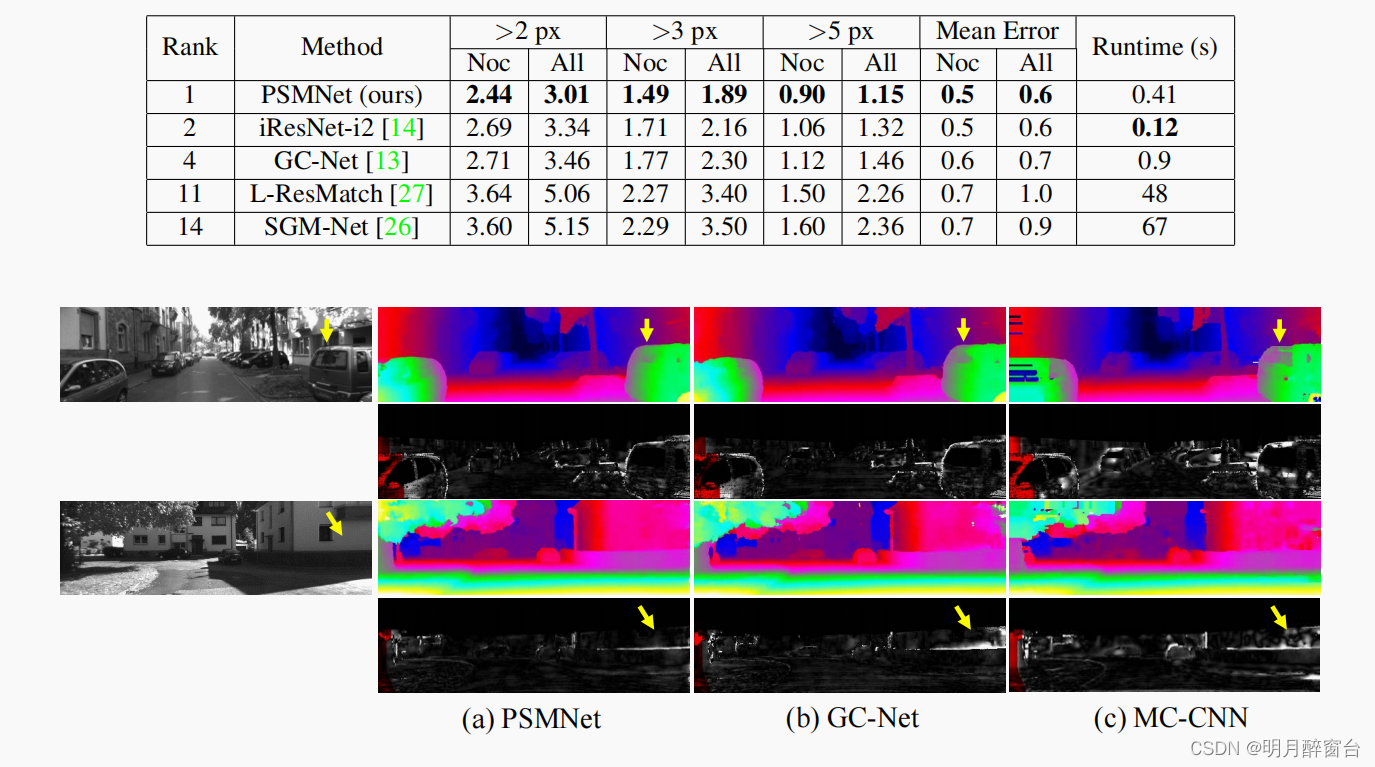
- 2018年3月18日发布了KITTI 2012的排行榜。除运行时外,PSMNet在所有评估标准下都获得了最佳的结果。只列出了已发布的方法以供比较。
5.结论
近年来,利用cnn进行立体匹配的研究取得了显著的性能。然而,要估计固有的不适状态地区的差异仍然很难。在这项工作中,我们提出了PSMNet,一种新的立体视觉端端CNN架构,它由两个主要模块来利用上下文信息:SPP模块和3D CNN。SPP模块包含了不同级别的特性映射,以形成一个成本量。3D CNN通过重复的自上而下/自下而上的过程进一步学习了规范成本量。在我们的实验中,PSMNet优于其他最先进的方法。在2018年3月18日之前,PSMNet在2012年和2015年的KITTI排行榜上都排名第一。估计的视差图清楚地表明,PSMNet显著减少了不适态区域的误差。