详解分库分表设计
详解分库分表设计
背景
在传统的单机数据库架构中,所有数据都存储在同一个数据库中,随着业务规模的不断扩大,数据量和并发量也会越来越大,这会给数据库的性能和可用性带来挑战。此外,当单机数据库的容量达到瓶颈时,无法继续扩展,这也限制了应用程序的可扩展性。
为了解决这些问题,分库分表技术应运而生。通过将数据分散存储在多个数据库或表中,可以减轻单一数据库的负载,提高系统的并发性能。此外,分库分表还可以支持水平扩展,使得系统能够随着业务的增长而不断扩展。
总之,分库分表是一种常用的数据库架构设计方案,可以解决数据库在数据量、并发性、可扩展性等方面面临的瓶颈问题,是大规模应用程序必不可少的技术之一。
为什么分库分表
-
数据量增大:当数据量逐渐增大时,单个数据库或表可能无法承载所有数据,导致性能下降,甚至崩溃。
分库分表可以将数据分散到多个数据库或表中,每个数据库或表都只负责一部分数据,从而提高系统的性能和可靠性。
-
提高并发能力:当多个用户同时访问同一个表时,容易造成数据库的性能瓶颈,导致响应变慢。
分库分表可以将数据分散到多个数据库或表中,从而提高并发访问能力,减少系统的瓶颈。
-
数据隔离:在多租户场景下,不同的租户需要使用不同的数据库或表,以保证彼此的数据隔离。分库分表可以将不同租户的数据分散到不同的数据库或表中,从而保证数据的隔离性。
-
降低单节点的压力:当系统需要支持大量数据的读写操作时,单个数据库或表可能无法承载,此时可以将数据分散到多个数据库或表中,从而降低单个节点的压力。
什么是分库分表
-
分库:将一个数据库拆分为多个数据库
-
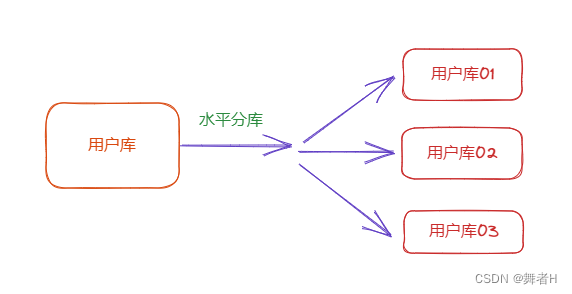
水平分库:指将一个大型数据库分成多个较小的、相似的数据库,每个数据库包含数据的不同部分
例如:将用户数据根据其 ID 值的范围分配到用户库DB1、用户库DB2中。
这种分片方式可以提高系统的扩展性和性能,因为可以将负载分散到多个数据库中
特点:
-
每个库的结构都一样,存储同一业务类型的数据
-
每个库的数据都不一样,没有交集
-
所有库的并集是全量数据
-
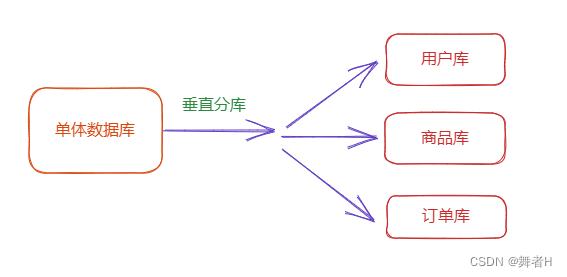
垂直分库:是指将一个大型数据库,根据业务关系分成多个较小的数据库。
例如,将用户数据存储在用户库,订单数据存储在订单库中。
这种分片方式可以提高系统的灵活性和可维护性,因为可以根据需要对不同的数据库进行单独的优化和维护
特点:
-
每个库的结构都不一样,存储不同业务类型的数据
-
每个库的数据都不一样,没有交集
-
所有库的并集是全量数据
水平分库和垂直分库并不是互斥的概念,两者可以结合使用来实现更高效的数据库分片方案
-
-
分表:将一个数据表拆分为多个数据表
-
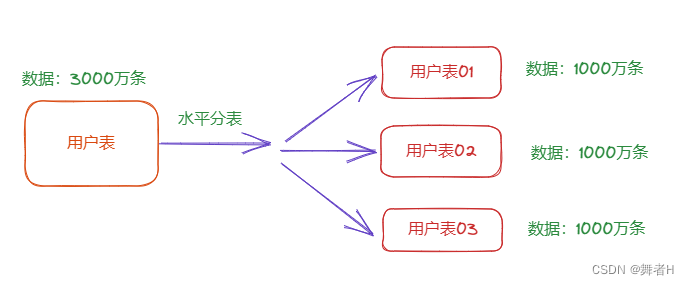
水平分表:是指将一个表中的数据按照某个规则分散到多个表中,这个规则通常是基于某个列的取值进行的
例如,可以根据用户ID,通过范围、Hash、取余等规则将用户表分成多个子表,每个子表中存储特定范围内的用户数据
水平分表可以提高数据查询效率,因为查询只需要在一个小的子表中执行,而不是在整个表中执行
-
特点:
1. 每个表的结构都一样,存储**同一实体、相同类型**的数据
2. 每个表存的数据都不一样,没有交集
3. 所有表的并集是全量数据
-
垂直分表:指将一个表按照列的方式进行分割,将一部分列存储到一个表中,另一部分列存储到另一个表中。这个分割通常是基于列的相关性进行的,典型的如主表和扩展表
例如,可以将一个包含用户主要信息、用户辅助信息的表分成两个表,一个包含用户主要信息,另一个包含用户辅助信息。
这可以提高数据的存储效率,因为每个表只包含必要的列,而不是整个表的所有列。

特点:
1. 每个表的结构都不一样,存储**同一实体、不同类型**的数据
2. 每个表存的数据都不一样,字段至少有一列交集,一般是主键,用于关联数据
3. 所有表的并集是全量数据
拆分策略
-
按范围切分:按照数据的某个范围将表拆分成多个子表。例如,可以按照时间范围将订单表拆分成每个月的子表。
优点:
水平扩展:按照范围进行分库分表可以实现水平扩展,当数据量增加时,可以方便地增加更多的数据库或表;比如以2000万标准拆分,超过2000万的转移到新表,而之前2000万内的记录就无需再做迁移了
缺点:
热点问题:如果某些数据访问频率很高,但是按范围切分后,又被分在同一个区段,这样大量请求会集中在这一区段,没有很好的负载均衡效果
-
按照哈希值切分:按照数据的哈希值将表拆分成多个子表。例如,可以使用用户ID的哈希值将用户表拆分成多个子表。
HASH取模策略:指定的路由key(一般是主键ID)对分表总数进行取模,把数据分散到各个表中
优点:
负载均衡,没有明显的热点倾斜问题
缺点:
扩展不灵活,如果一开始按照HASH取模分成4个表了,未来某个时候,表数据量又到瓶颈了,需要扩容至,这就比较棘手了,需要重新进行数据迁移
-
按照地理位置切分:如果数据与地理位置相关,则可以按照地理位置将表拆分成多个子表。例如,可以按照城市将商家表拆分成多个子表。
-
按照业务类型切分:如果数据有不同的业务类型,则可以按照业务类型将表拆分成多个子表。例如,可以按照产品类型将商品表拆分成多个子表。
-
按照访问频率切分:如果某些数据被频繁访问,则可以将其放入单独的表中,以便更快地访问。例如,可以将最近一年的订单数据放入单独的表中,以便更快地查询最近的订单。
分库分表工具
-
ShardingSphere:ShardingSphere是一套开源的分布式数据库中间件解决方案,支持分库分表、读写分离、数据加密等功能。
官网:https://shardingsphere.apache.org/index_zh.html
-
Mycat:Mycat是一款基于MySQL协议的开源分布式数据库中间件,支持分库分表、读写分离、数据分片等功能。
官网:http://www.mycat.org.cn/
-
TDDL:TDDL是阿里巴巴开源的一款分布式数据库中间件,支持MySQL、Oracle等数据库,提供了分库分表、读写分离、数据分片等功能。
-
Cobar:Cobar是阿里巴巴开源的一款分布式数据库中间件,支持MySQL、PostgreSQL等数据库,提供了分库分表、读写分离、数据分片等功能。
分库分表问题
-
主键(自增 ID)唯一性问题:在表设计时,经常会使用自增 ID 作为主键,这就导致后续在迁库迁表、或者分库分表操作时,会因为主键的变化或者主键不唯一产生问题,解决方案主要有
- 采用分布式全局统一 ID 生成机制:如 UUID、雪花算法、数据库号段等方式
-
分布式事务:由于数据被分散在多个数据库或表中,事务的处理会变得更加复杂。例如,如果一个事务涉及多个数据库或表,那么如何保证这些操作的原子性就需要更加细致的设计。
-
Join/分页查询:在分库分表的情况下,查询跨越多个数据库或表就变得更加复杂。例如,如果需要对一组数据进行全文搜索,那么就需要在多个数据库或表中执行查询,这可能会影响查询性能。
-
分开查询,再组装数据
-
冗余字段:如果每次join操作只是为了获取少量的字段,那么可以考虑直接将这些字段冗余到表上
-
数据同步:
将数据源之间的数据同步到一个单独的数据仓库中,然后在这个数据仓库中进行join操作。这种方法可以解决跨库跨表的join问题,但是需要额外的存储和同步成本,并且可能存在数据同步延迟和一致性问题
-
-
数据迁移:在分库分表的情况下,如果需要将数据迁移到新的数据库或表中,就需要考虑如何迁移数据,并且在迁移的过程中如何保证数据的一致性。
-
系统复杂度:由于分库分表需要管理多个数据库或表,系统的复杂度也会随之增加。例如,需要考虑如何监控每个数据库或表的状态,如何处理数据库或表的故障等等问题。
-
数据迁移:在分库分表的情况下,如果需要将数据迁移到新的数据库或表中,就需要考虑如何迁移数据,并且在迁移的过程中如何保证数据的一致性。
-
系统复杂度:由于分库分表需要管理多个数据库或表,系统的复杂度也会随之增加。例如,需要考虑如何监控每个数据库或表的状态,如何处理数据库或表的故障等等问题。