【数据结构与算法】什么是链表?并用代码手动实现一个单向链表
文章目录
- 一、链表是什么
- 二、链表的作用
- 三、链表与数组的区别
- 四、如何理解链表
- 五、单链表完整代码
一、链表是什么
-
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,有一系列结点(地址)组成,结点可动态的生成。
-
结点包括两个部分:
(1)存储数据元素的数据域(内存空间)
(2)存储指向下一个结点地址的指针域。 -
相对于线性表顺序结构,操作复杂。
-
链表分为 :
(1)单链表
(2)双链表
(3)单向循环链表
(4)双向循环链表
二、链表的作用
-
实现数据元素的存储按一定顺序储存,允许在任意位置插入和删除结点。
-
包括单向结点,双向结点,循环接点。
三、链表与数组的区别
说到链表那肯定要聊一下数组,为什么会出现链表呢?
-
数组:使用一块连续的内存空间地址去存放数据,但
例如:
int a[5]={1,2,3,4,5} 突然我想继续加两个数据进去,但是已经定义好的数组不能往后加,只能通过定义新的数组
int b[7]={1,2,3,4,5,6,7} 这样就相当不方便比较浪费内存资源,对数据的增删不好操作。 -
链表:使用多个不连续的内存空间去存储数据, 可以 节省内存资源(只有需要存储数据时,才去划分新的空间),对数据的增删比较方便。
四、如何理解链表
理论的东西我就不说太多了,下面我将以代码+图形的方式让大家很通俗易懂的理解链表。
- 单链表的结构体
struct node
{
int data;//存放数据
struct node *next; //地址域 (与节点的类型地址相匹配)
}
可以把这个结构体理解成这个样子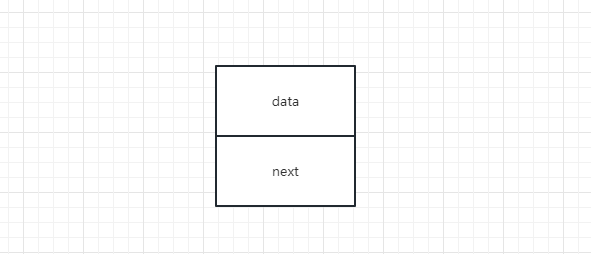
- 创建链表的新节点
struct node *creat_node(int data)
{
struct node *new = malloc(sizeof(struct node));
new->data = data;
new->next = NULL;
return new;
}
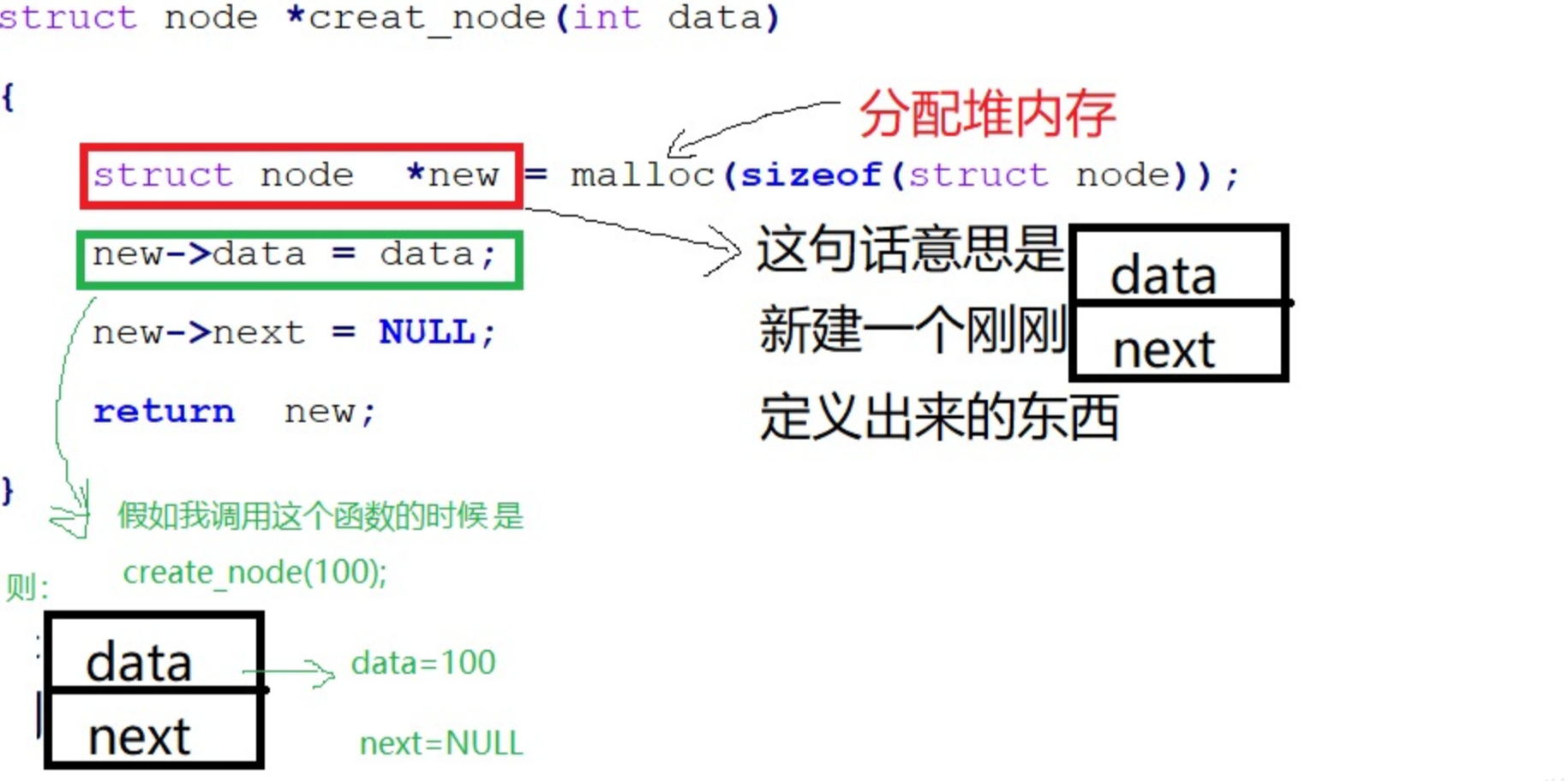
- 插入节点
struct node* insert_node(struct node*p,struct node*new)
{
p->next = new;
}
- 显示链表
void show(struct node *p)
{
while(1)
{
if(p== NULL) //假设p已经为NULL则返回
{
return ;
}
printf("p=%d\n",p->data);
p = p->next; //链表的重要知识点!!! 遍历节点向下走
}
}
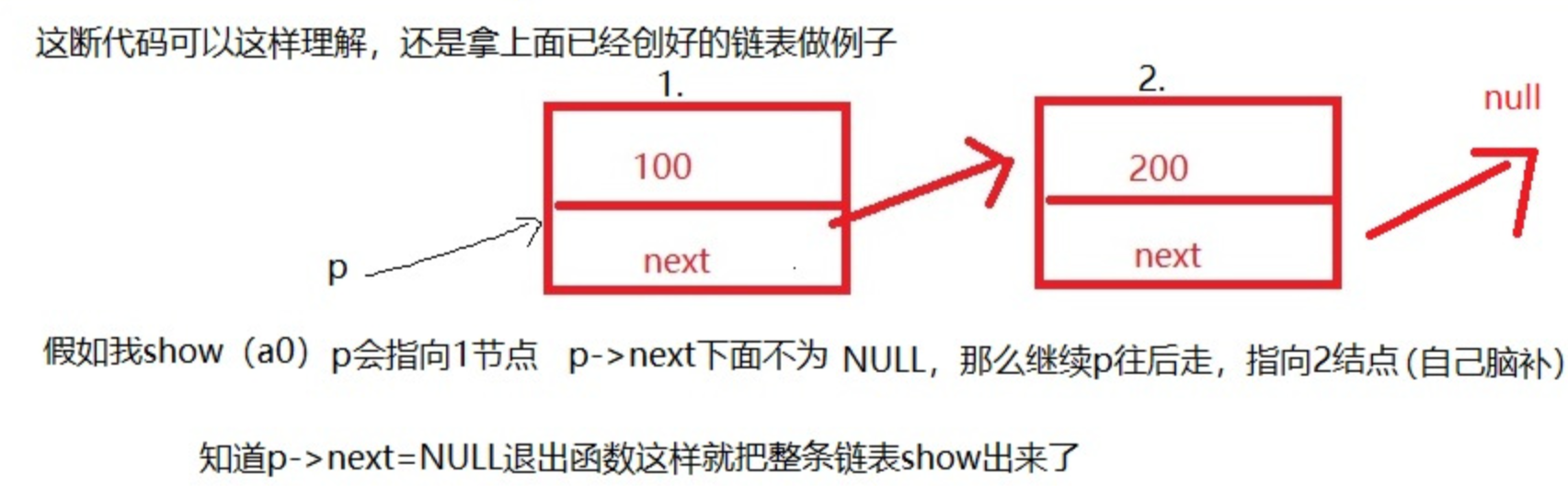
有了以上三个步骤我们就可以做出一条简单的单链表。
五、单链表完整代码
list.c
#include <stdio.h>
#include <stdlib.h>
//设计链表的节点
struct node
{
int data;//存放数据
struct node *next; //存放地址 (与节点的类型地址相匹配)
};
//创建节点
struct node *creat_node(int data)
{
struct node *new = malloc(sizeof(struct node));
new->data = data;
new->next = NULL;
return new;
}
//插入节点 (链接节点)
struct node* insert_node(struct node*p,struct node*new)
{
p->next = new;
}
//显示节点数据 (遍历节点)
void show(struct node *p)
{
while(1)
{
if(p== NULL) //假设p已经为NULL则返回
{
return ;
}
printf("p=%d\n",p->data);
p = p->next; //链表的重要知识点!!! 遍历节点向下走
}
}
int main()
{
//1.分配节点空间
struct node *a0 = creat_node(100);
struct node *a1 = creat_node(200);
struct node *a2 = creat_node(300);
inser_node(a0,a1);
inser_node(a1,a2);
//通过a0 访问a0 a1 a2的数据 //3.访问节点中的数据
//printf("a0=%d,a1=%d,a2=%d\n",a0.data,a0.next->data,a0.next->next->data);
show(a0);
}