【数据结构】TopK,堆排序, --堆的初始化与应用

Halo,这里是Ppeua。平时主要更新C语言,C++,数据结构算法......感兴趣就关注我吧!你定不会失望。
🌈个人主页:主页链接
🌈算法专栏:专栏链接
我会一直往里填充内容哒!
🌈LeetCode专栏:专栏链接
目前在刷初级算法的LeetBook 。若每日一题当中有力所能及的题目,也会当天做完发出
🌈代码仓库:Gitee链接
🌈点击关注=收获更多优质内容🌈
目录
1.二叉树的存储结构
1.1链式存储
二叉链式存储:
三叉链式存储:
1.2顺序存储结构
2.堆
2.1堆的性质
2.2堆的数据结构
2.3堆的初始化
2.4堆的向上调整
2.4堆的向下调整
2.5堆的插入
2.6堆的删除
2.7堆的销毁,大小,Empty
3.堆排序
4.TopK问题
 书接上回,本章节也是关于树的内容:二叉树的存储简介,堆的初始化以及应用
书接上回,本章节也是关于树的内容:二叉树的存储简介,堆的初始化以及应用
1.二叉树的存储结构
相信经过上一阶段的学习(二叉树概念)大家都对二叉树有了一个初步的印象,接下里我们将介绍一下二叉树在内存中一般如何存储.
1.1链式存储
不同于上章所讲的用一个节点存储子结点,另一个节点用来存储兄弟节点,
因为二叉树中的子节点个数是确定的:一个到两个,最多两个.所以我们可以直接创建两个指针记录下其子结点的信息.
二叉链式存储:
就是用两个指针信息来记录其左右子节点的地址.再用一个变量来存储数据.一般是这样写的
typedef int TDatatype;
typedef struct tree
{
TDatatype val;
tree *left;
tree *right;
}tree;其形象的结构如图所示:
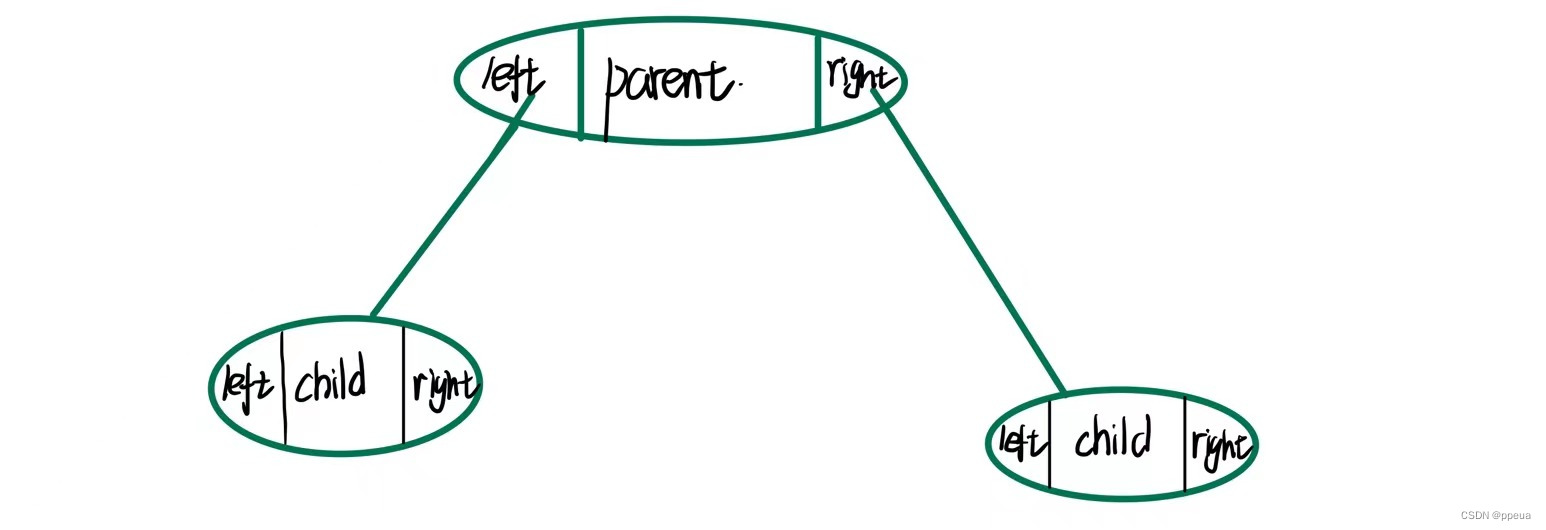
二叉链式 存储一般是比较常见的用在二叉树上.但还有一种结构,在后期学习到红黑树会用到的结构
三叉链式存储:
与上方不同,其是用两个指针存储左右儿子,再用一个指针来存储父节点,所以叫做三叉链式存储
typedef int TDatatype;
typedef struct tree
{
TDatatype val;
tree *left;
tree *right;
tree *parent;
}tree;其形象的结构如图所示:

1.2顺序存储结构
与链表的相同,二叉树也可以通过数组来存储信息,也就是顺序存储.
如果是二叉树可以用此结构存储,因为其他类型的树使用这种结构会造成大量的空间浪费.
就会出现这种情况

所以不推荐使用
2.堆
2.1堆的性质
先来了解下堆的性质
其本质就是一颗具有特殊属性的完全二叉树
若其父节点都大于等于子节点 则称为大顶堆
若其父节点都小于等于子节点 则称为小顶堆
下面这些就是大/小顶堆:

2.2堆的数据结构
刚刚提到堆是一颗完全二叉树,那么其结构具有二叉树的顺序存储结构的特点.
typedef int TDataType;
struct tree{
int size;
int capacity;
TDataType *a;
};其中 size用来存储当前堆中有多少个元素. capacity来判定当前数组是否需要扩容
而a自然是用来存储数据的.这与栈的顺序结构十分相似.
2.3堆的初始化
与链表等结构相同,使用堆前也需要对其初始化.这里没什么好说的,与其他数据结构都相同
void HeapInit(Heap* hp)
{
hp->size = 0;
hp->a = (HDataType*)malloc(sizeof(HDataType) * 4);
if (hp->a == NULL)
{
perror("malloc failed");
return;
}
hp->capacity = 4;
}2.4堆的向上调整
刚刚说过,堆有两种(大顶堆与小顶堆)
想要让一个无序的数组变成这样的,肯定需要对每一个插入的数进行调整.
其中就有向上调整,向下调整两种方式,这里先来讲讲向上调整

将1插入到一个小顶堆,其做的变化如图所示。
先是与父节点比较,父节点(i-1/2)比其大(大顶堆则相反)则交换(不满足小顶堆的规则).
直到child=0时停下
void UpAdjust(HDataType* hp, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (hp[parent] > hp[child])
{
Swap(&hp[parent], &hp[child]);
child = parent;
parent = (parent - 1) / 2;
}
else
break;
}
}2.4堆的向下调整
这里介绍下向下调整,向下调整是建一个堆的必要步骤
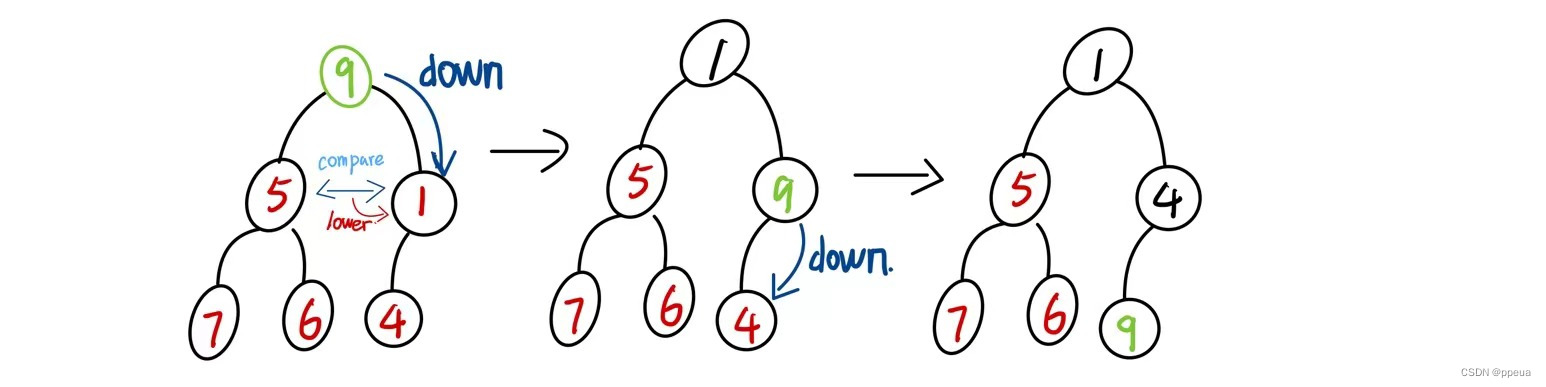
例如将9插入到一个小顶堆中,需要经历的是这几步
将9的两个子节点进行比较,因为是小顶堆,所以需要挑出其最小的部分,与9进行交换
之后一步步向下调整即可.当child>=n时停止
void DownAdjust(HDataType* hp, int n,int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child+1<n&&hp[child] > hp[child + 1])
{
child++;
}
if (hp[child] < hp[parent])
{
Swap(&hp[child], &hp[parent]);
parent = child;
child = parent * 2 + 1;
}
else break;
}
}向下调整的效率比向上调整的效率高.这个道理非常的简单,倒数第二层是除叶子节点外最多节点的一层,其向下调整最多只需要调整一层.往上节点越少,调整越多.
而向上调整则刚好相反,第一层节点最少,最多需要调整一次,但最后一层节点最多,需要调整的次数也是最多的.所以一般用向下调整来建堆
2.5堆的插入
有了之前的两个利器,接下来就十分的简单了.
void HeapPush(Heap* hp, HDataType x)
{
if (hp->size == hp->capacity)
{
HDataType* tmp = (HDataType*)realloc(hp->a,sizeof(HDataType) * hp->capacity * 2);
if (tmp == NULL)
{
perror("malloc failed");
return;
}
hp->a = tmp;
hp->capacity *= 2;
}
hp->a[hp->size++] = x;
UpAdjust(hp->a,hp->size-1);
}这与栈的插入十分相同,这里就不过多赘述了.值得注意的是最后一步,
UpAdjust的参数为:堆的数组与需要调整的子节点
2.6堆的删除
void HeapDelete(Heap* hp)
{
if (hp->size <= 0)return;
Swap(&hp->a[hp->size - 1], &hp->a[0]);
hp->size--;
DownAdjust(hp->a, hp->size - 1, 0);
}首先检查是否为空.
之后交换最后一个数据与第一个数据.将size--,释放最后一段空间,再将刚刚交换的数字进行向下调整

2.7堆的销毁,大小,Empty
这与之前所学相同 不过多赘述
需要注意Malloc了多少空间.就要释放多少空间
void HeapDestory(Heap* hp)
{
free(hp->a);
hp->capacity = hp->size = 0;
free(hp);
}
HDataType HeapTop(Heap* hp)
{
return hp->a[0];
}
int HeapSize(Heap* hp)
{
return hp->size;
}
int HeapEmpty(Heap* hp)
{
return hp->size == 0;
}
3.堆排序
其核心仍然是DownAdjust,先通过DownAdjust建一个堆,之后再删除堆顶元素,向下调整,直到size为0
虽然size为0,但是刚刚的数据依照大/小放到最后一位(大小堆决定),所以此时读取数组就变成了有序的.
注意:要排升序需要建大堆(因为大的被放到了最后一个),排降序建小堆
void heapSort(HDataType *a,int n)
{
/*for (int i = 1; i < n; i++)
{
UpAdjust(a, i);
}*/
for (int i = (n - 1 - 1 / 2); i >= 0; i--)
{
DownAdjust(a, n,i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[end], &a[0]);
end--;
DownAdjust(a, end,0);
}
} 因为向下建堆效率更高,所以采用这种方法.
4.TopK问题
给你一个无穷大的数组,想要让你找到前k个最大(最小的数组)如何去找?
十分的简单,先去将这个数组的前十个数据建堆.若找最大的,则建小堆,
将之后的每一个元素都与堆顶元素进行比较(因为堆顶是这十个数中最小的) ,若比他大,则说明堆中至少有一个数(堆顶)需要被换掉,将堆顶等于刚刚这个数,之后执行向下调整即可.
void TopK(const char* f, int top)
{
int* topk = (int*)malloc(sizeof(int) * top);
FILE* fl = fopen(f, "r");
for(int i=0;i<top;++i)
{
fscanf(fl, "%d", &topk[i]);
}
for (int i = (top-2)/2; i>=0; --i)
{
DownAdjust(topk, top, i);
}
int val = 0;
int ret = fscanf(fl, "%d", &val);
while (ret != EOF)
{
if (val > topk[0])
{
topk[0] = val;
DownAdjust(topk, top, 0);
}
ret = fscanf(fl, "%d", &val);
}
for (int i = 0; i < top; i++)
printf("%d \n", topk[i]);
printf("\n");
free(topk);
fclose(fl);
}
int main()
{
const char* f = "data.txt";
srand(time(NULL));
FILE* fl = fopen(f, "w");
for (int i = 0; i < N; i++)
{
fprintf(fl, "%d\n", rand() % 10000);
}
TopK(f, 10);
return 0;
}这里采用了文件的方式生成一万个随机数
fprintf(文件指针,数据格式,数据) 可以这样理解 printf将内容打印到了屏幕上,而fprintf打印到了文件里
fscanf(文件指针,数据格式,存入地址) 可以这样理解 scanf将键盘键入的内容存到了变量,而fscanf将文件中的内容存入到了变量,若读到的为空则返回EOF
🌈本篇博客的内容【TopK,堆排序, --堆的初始化与应用】已经结束。
🌈若对你有些许帮助,可以点赞、关注、评论支持下博主,你的支持将是我前进路上最大的动力。
🌈若以上内容有任何问题,欢迎在评论区指出。若对以上内容有任何不解,都可私信评论询问。
🌈诸君,山顶见!