论文阅读:One Embedder, Any Task: Instruction-Finetuned Text Embeddings
1. 优势
现存的emmbedding应用在新的task或者domain上时表现会有明显下降,甚至在相同task的不同domian上的效果也不行。这篇文章的重点就是提升embedding在不同任务和领域上的效果,特点是不需要用特定领域的数据进行finetune而是使用instuction finetuning就可以在不同的任务和领域上表现得很好。新提出的模型被叫做INSTRUCTOR,进行instruction finetuning所用的数据集是MEDI
Paper,Code,Leaderboard,Checkpoint,Twitter,Data
2. INSTRUCTOR结构
- 基于single encoder architecture,参考:Leveraging Passage Retrieval with Generative Models
for Open Domain Question Answering - 使用GTR模型(Generalizable T5-based dense Retrievers)作为encoder骨架。GTR模型是用T5模型初始化的,在web corpus上做预训练,在information search datasets上做finetune。
- GTR模型用的是Large Dual Encoders Are Generalizable Retrievers这篇文章里面的,T5模型是这篇文章里面的Exploring the Limits of Transfer Learning with a Unified
Text-to-Text Transformer,由于T5模型的文章过长,可以参考T5 模型:NLP Text-to-Text 预训练模型超大规模探索,找到自己的目标实验之后再看对应的论文片段。
3. 训练数据
- 这个方法的核心是instruction-base finetuning,如下图所示,一个输入经过INSTRUCTOR会根据不同的目标改写成不同的输入形式:
- instructioninstruction-based finetun
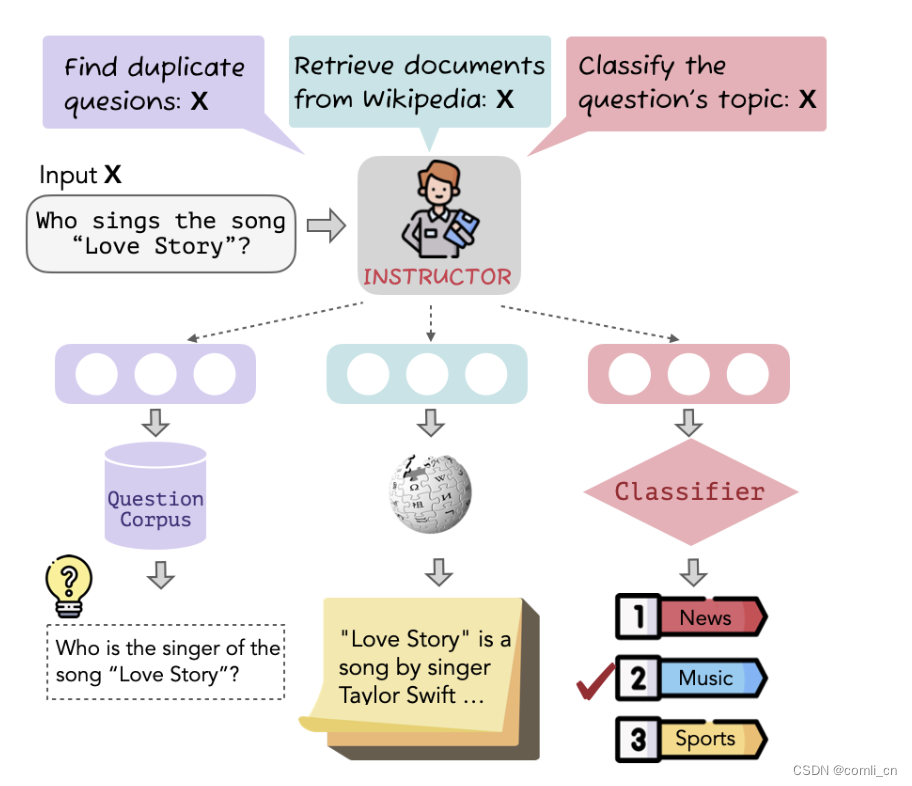
input:Who sings the song "Love Story"?INSTRUCOR:input1:Find duplicate quesions:Who sings the song "Love Story"?input2:Retrieve documents from wikipedia:Who sings the song "Love Story"?input3:Classify question's topic:Who sings the song "Love Story"?
-
构建了MEDI,一个多样化的数据集,用于微调INSTRUCTOR。这个数据集包含了330种不同的文本embedding任务,并就这种具有对比损失的多任务组合对INSTRUCTOR进行训练
-
其中300个数据集来自super-NI,还有30个来自现有集合
-
super-NI带有Instructions但是没有提供正负样本对,这里用Sentence-T5 embedding来帮助构成pairs。数据下载:natural-instructions
-
对于分类任务,如果 x i x_i xi和 x j x_j xj的label均为正且 x i x_i xi和 x j x_j xj的embedding相似度高,则 x i x_i xi和 x j x_j xj就会被归为positive-pair,如果 x i x_i xi和 x j x_j xj的label不同,则归为negative-pair。
下图是super-NI数据集的标准格式
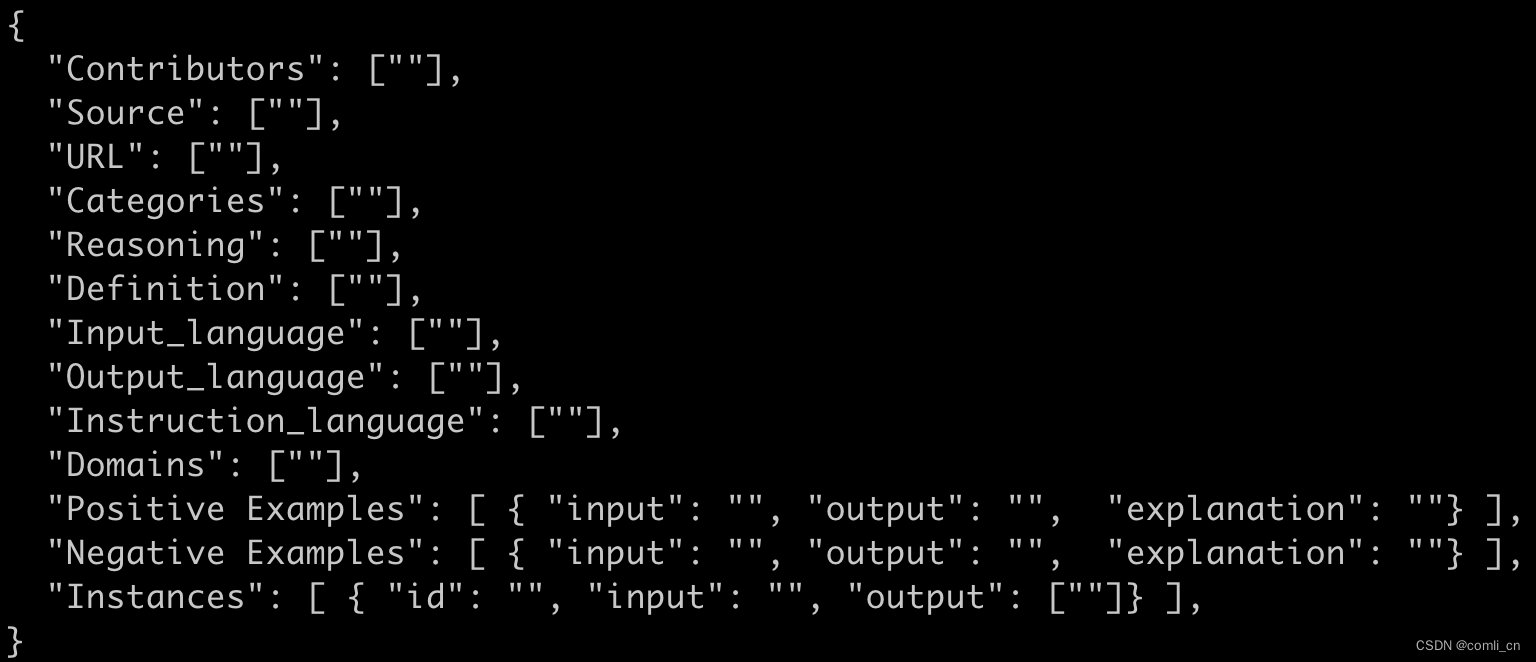
如下图是super-NI里面一个分类任务的数据集,如果都属于Positive Examples且embedding相似度高则为positive-pair,如果一个属于Positive Examples,一个属于Negative Examples则为negative-pair
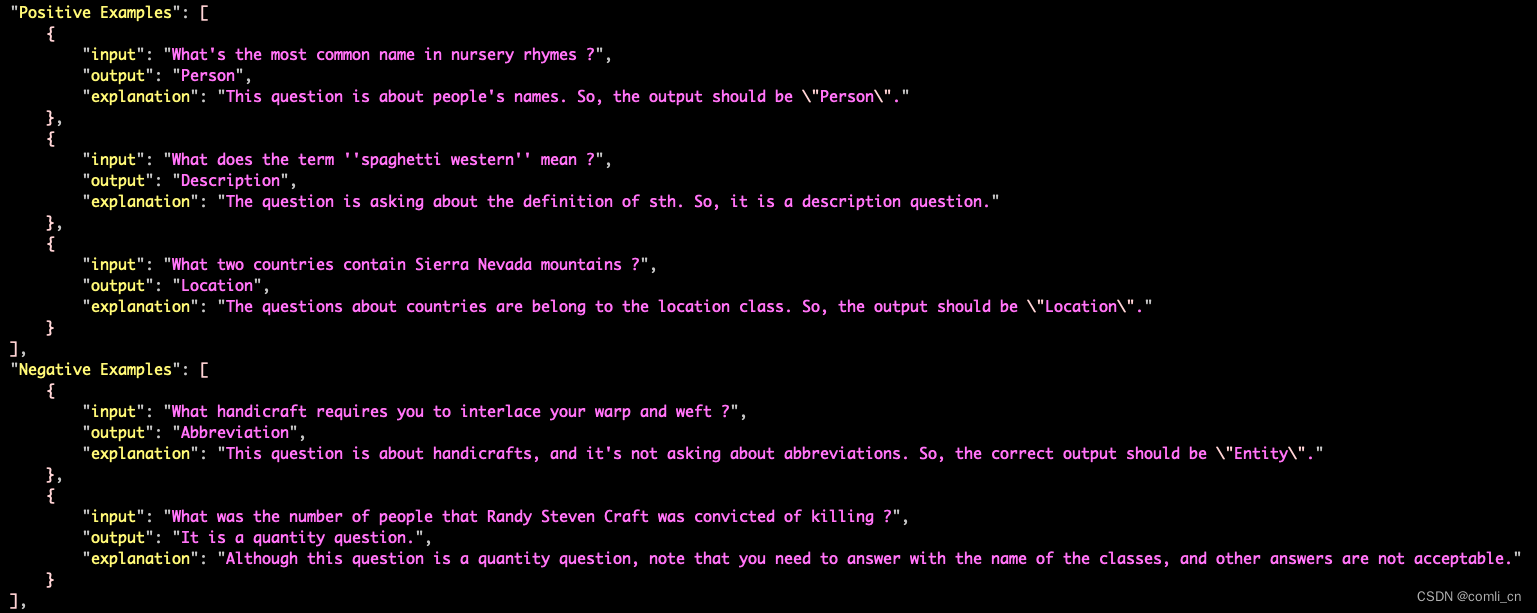
-
对于其他任务,要先按照下面的式子计算score,然后选择s_pos最高的作为positive-pair,选择s_neg最高的作为hard negative-pair(一个反例对有一个更大的余弦相似对意味着从不同的类别中区分两对样例是更困难的,这样的对被视为硬反例对hard negative pairs,他们有更多的信息并且更有意义去学习一个可区分的特征)
-
在训练的时候将每个batch里面放入一个hard negative,一个batch里面除了一个positive之外其余的都作为negtive(inbatch sampled negatives)
-
-
另外30个数据集来自Sentence Transformers embedding data
- 这30个数据集已经有了positive pairs,其中的一小部分比如说MSMARCO和Natural Questions包含有hard negative pairs
- 在模型finetune时使用4个negative pairs(参考一下这篇文章:Large Dual Encoders Are Generalizable Retrievers)Large Dual Enco
- 因为这些数据集缺乏instructions,做了一个instruction模版,并且人工为每个数据集写prompt
- 数据集的几种格式:

4. 训练目标
最大化输入与正样本的相似度,最小化输入与负样本的相似度;用instruction和query拼接后的embedding与instruction和doc拼接后的embedding计算相似度
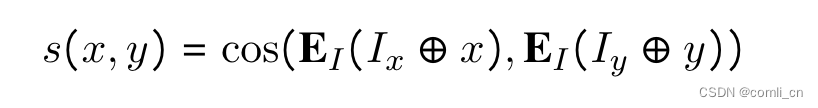
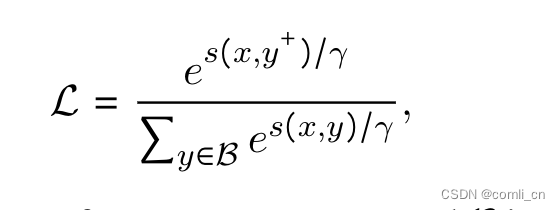
5. 训练细节
- 因为MEDI里面datasets的大小差别很大,所以要对比较大的dataset做降采样
- 在每一步,首先随机选择一个dataset,然后从这个dataset里构建一个minibatch。这样我们可以确定in-batch negatives是从同一个dataset里面采样的,从而防止模型使用任务差异来预测负标签
- 用GTR-Large模型初始化INSTRUCTOR,并使用AdamW优化器在学习率为2*10(-5),warmup ratio为0.1的条件下在MEDI上进行finetune
6. 评估
- 在70项embedding评估任务(其中66项在训练期间看不到)上进行评估,涵盖了从分类,信息检索到语义文本相似性,文本生成评估和上下文学习中的prompt检索
7. 效果
- 在70项评估任务中获得了平均3.4%的提升
- INSTRUCTOR的表现优于使用同样结构但是没有task instructions的变体,通过这个实验证明了instructions对task-aware embedding的重要性
- 分析表明,INSTRUCTOR对指令的变化很鲁棒,指令微调减轻了在不同数据集上训练单个模型的挑战
8. 分析
-
使用instructions对INSTRUCTOR进行finetune可以让模型在多个任务上表现出色。对比实验,将MEDI分为对称group和非对称group,在inetune时没有instructions的情况下INSTRUCTOR单独在对称group或非对称group里的表现与原始的GTR模型相似,但是如果将两个group混合的话inetune时没有instructions表现就会变差。如下图所示,w/o表示without,左右相比可以看到蓝色的网格条有很明显的提升,绿色和黄色的也有提升,证明了instructions的重要性。
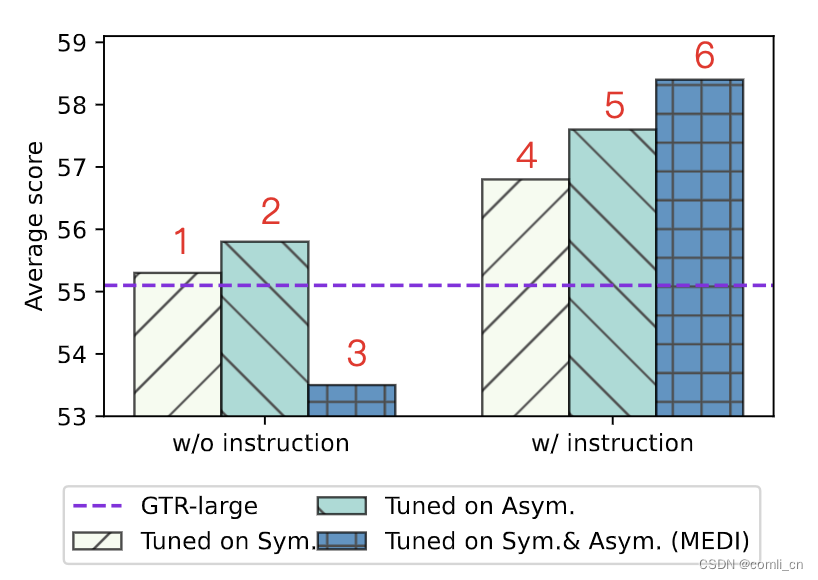
-
使用instructions对INSTRUCTOR进行finetune可以让模型的鲁棒性增加,如下图所示,加入instructions之后在super-NI上最好的表现与最差表现之间的差距明显变小了,模型比较稳定了。
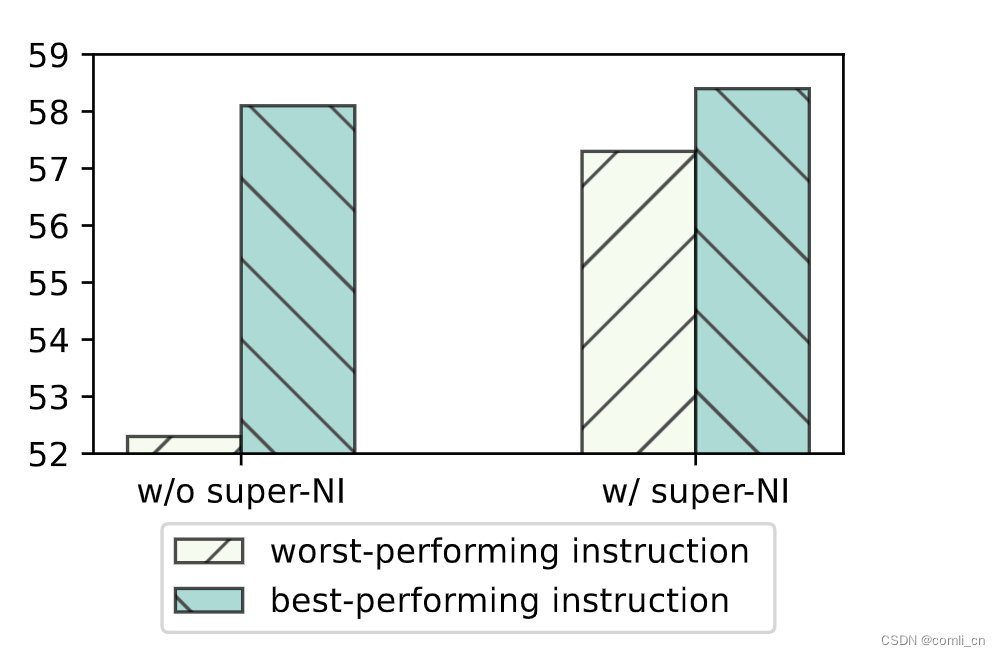
-
instructions越复杂模型表现越好,如下图所示,N/A表示没有instructions,tag表示提供了数据集的名字,simple表示给任务领域提供了一两个词的描述,detail表示instructions提供全了
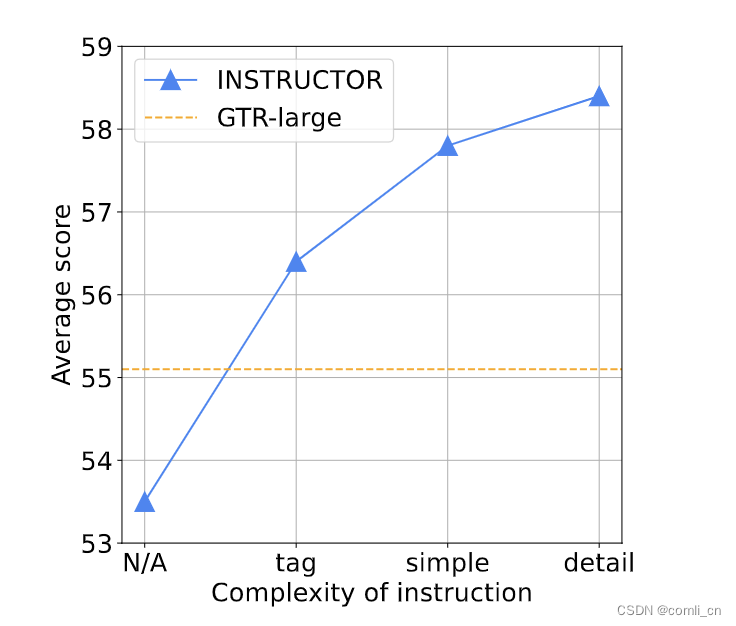
-
model size越大表现越好
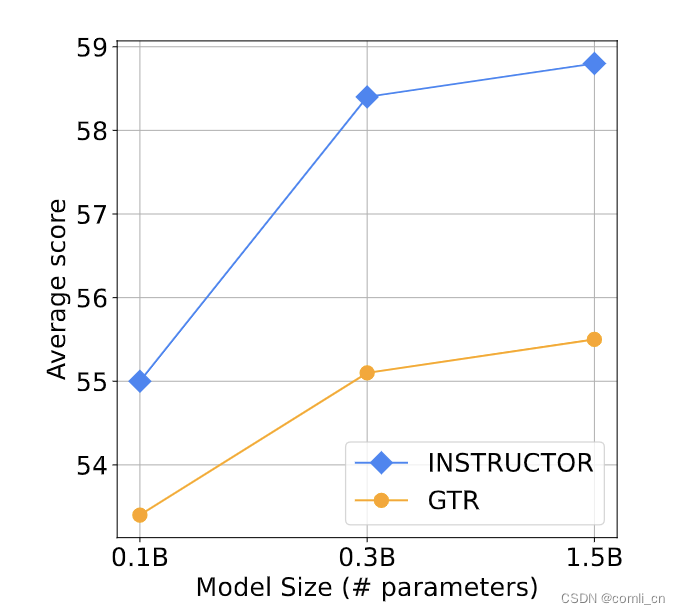
-
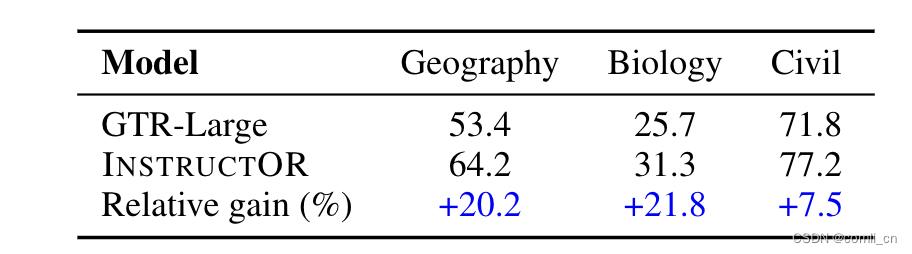
在没有见过的领域表现更好,如下表所示,在没有学习过的三个领域INSTRUCTOR相较于GTR-Large都有明显的优势
-
语义相似的vector距离更近,语义不同的vector距离更远,如下图所示,红色圈圈是语义相似的,绿色圆圈是语义不同的,圆圈带实框的是有instructions的,圆圈没有带实框的是没有instructions的

9. T5模型
- 所谓的 T5 模型其实就是个 Transformer 的 Encoder-Decoder 模型,BERT只用了Encoder,GPT只用了Decoder
- T5训练数据的清洗工作
- 只保留结尾是正常符号的行;
- 删除任何包含不好的词的页面,具体词表参考List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words库,里面中文列表有319个词
- 包含 Javascript 词的行全去掉
- 包含编程语言中常用大括号的页面
- 任何包含”lorem ipsum(用于排版测试)“的页面
- 连续三句话重复出现情况,保留一个
- T5模型的训练方法
- Transformer Encoder-Decoder 模型
- BERT-style 式的破坏方法
- Replace Span 的破坏策略
- 15 %的破坏比
- 3 的破坏时小段长度
- T5的不同尺寸模型
- Small,Encoder 和 Decoder 都只有 6 层,隐维度 512,8 头
- Base,相当于 Encoder 和 Decoder 都用 BERT-base
- Large,Encoder 和 Decoder 都用 BERT-large 设置,除了层数只用 12 层
- 3B(Billion)和11B,层数都用 24 层,不同的是其中头数量和前向层的维度
10. GTR模型
-
提出的思路:在bottleneck embedding固定不变的情况下(768)增加双塔编码器的尺寸(用T5模型进行编码)可以获取表现更好的embeddingbottleneck embedding
-
模型结构:
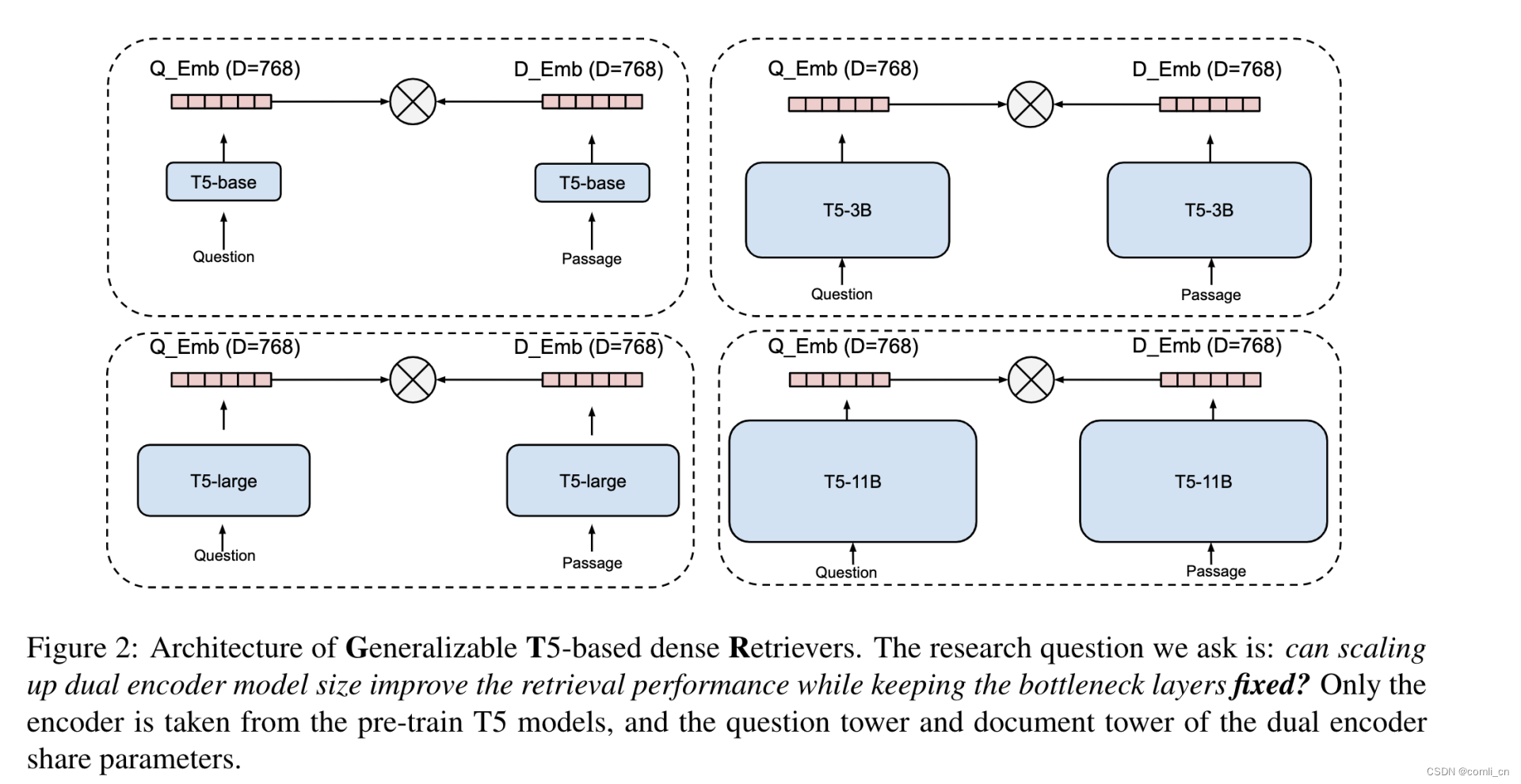
-
训练数据:pretrain使用的是2B的query-answer对,finetune用的是MS Marco
-
结论:
- 尽管bottleneck embedding的尺寸是固定的,但是增加编码器的尺寸会使的模型拥有更好的泛化性
- 是用问答数据进行预训练和用人类标注的数据进行finetune对用充分利用大模型优秀的能力是很重要的
- GTR在利用人类标注数据上表现出了很高的效率,只需要用10%的MS Marco就可以提神模型在领域外的泛化能力
参考:
- 代码:instructor-embedding