解析html生成Word文档
内容:读取html文件中的文本内容,然后生成Word文档导出。
事例场景:需求开发完成之后需要写文档(代码修改清单),文档内容就是这次需求修改/新增的所有代码,需要列出修改的文件路径以及代码片段,并且用不同的颜色标注区分。
例图:
如果手动复制粘贴并且标注,会相当麻烦。所以这里记录一下,使用代码来简单处理,生成所需文档。
第一步:功能测试完成后,把代码合并到新的分支,然后进入页面就能查看到这次的合并记录。
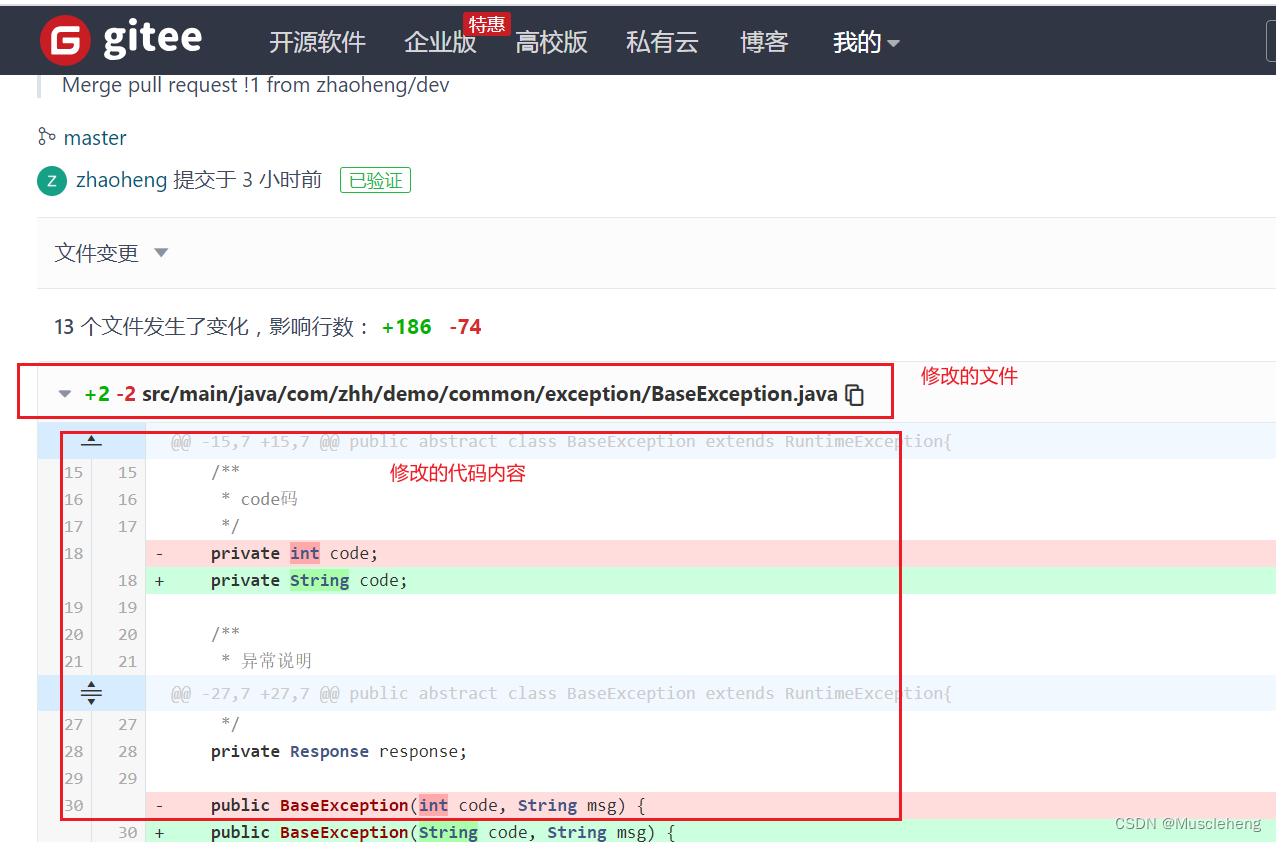
第二步:保存这个页面到本地,然后执行程序,生成Word文档。
功能实现说明
项目:SpringBoot
html文件来源:gitee。如果是gitLab的页面,可能页面标签元素就不太一样,需要修改一下代码中解析html读取标签的方式。
代码实现逻辑:使用jsoup读取并解析html文件,然后使用poi生成Word文档。
解析html需要先搞清楚html中的标签元素,然后再用代码读取。
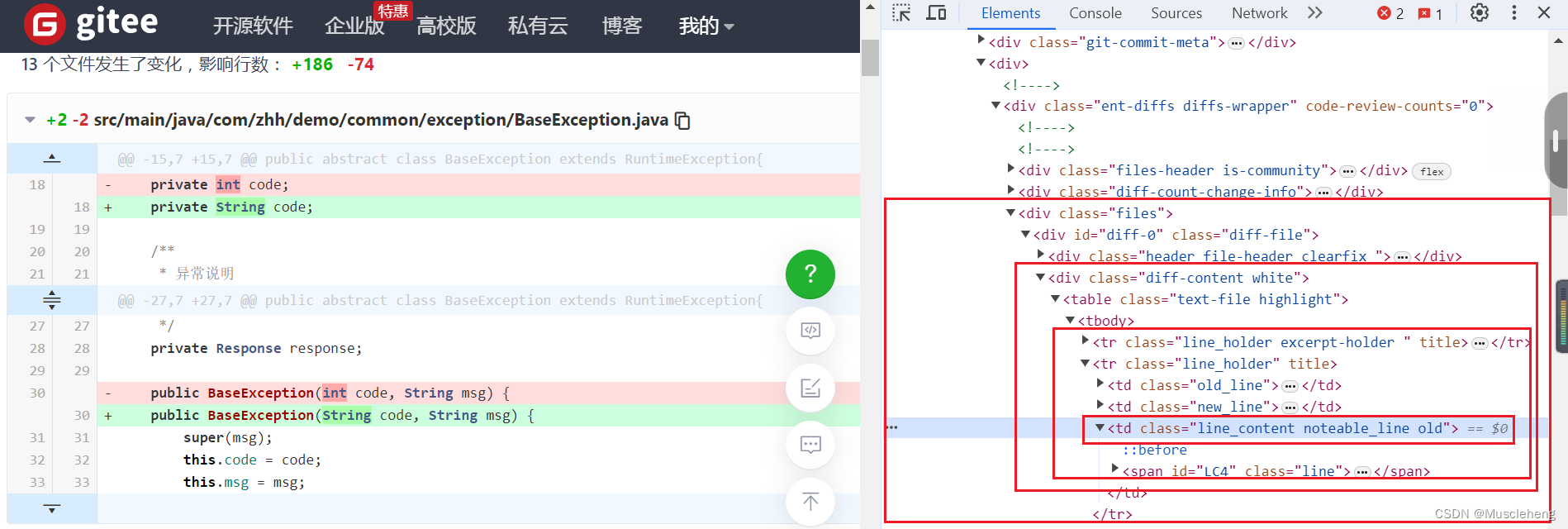
开始编码
Maven依赖:
<!-- poi 读取,生成Word文档、Excel文档--><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>3.15</version></dependency><!-- 解析html --><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.8.3</version></dependency>Java代码:
package com.example.demo16.util;import lombok.extern.slf4j.Slf4j;
import org.apache.poi.xwpf.usermodel.ParagraphAlignment;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTShd;import java.io.File;
import java.io.FileOutputStream;@Slf4j
public class CodeChangeDetailUtil {public static void main(String[] args) throws Exception {String htmlPath="E:/Downloads/code_01.html";String saveWordPath="E:/Downloads/code_0112.docx";codeChangeDetailOutPutWorld(htmlPath, saveWordPath);}/*** 旧代码标识:old* 新代码标识:new*/private static final String CODE_TYPE_OLD = "old";private static final String CODE_TYPE_NEW = "new";/*** 解析HTML文件内容生成Word* @param htmlPath HTML文件路径* @param saveWordPath Word文档保存路径* @throws Exception*/public static void codeChangeDetailOutPutWorld(String htmlPath, String saveWordPath) throws Exception {XWPFDocument doc = new XWPFDocument();Document document = Jsoup.parse(new File(htmlPath), "utf8");Elements elements = document.getElementsByClass("files");// 文件元素集合Elements diffFileElements = elements.get(0).getElementsByClass("diff-file");createHeader(doc, "修改清单(数量:" + diffFileElements.size() + ")");for (Element element : diffFileElements) {String headerText = element.getElementsByClass("header").get(0).getElementsByTag("a").get(0).text();createNullLine(doc, 1);createText(doc, headerText, "");}createNullLine(doc, 2);createHeader(doc, "程序修改记录");for (Element element : diffFileElements) {// 文件头,文件路径String headerText = element.getElementsByClass("header").get(0).getElementsByTag("a").get(0).text();//log.info("headerText:{}",headerText);// 得到文件路径/名称createNullLine(doc, 2);createTextHeader(doc, headerText);// 文件内容元素,代码存放在表格的行中,一行代码一行,这里获取表格的所有行if (null == findTableElements(element)) {log.error("该文件内容可能被折叠,请在原页面搜索【差异被折叠,点击展开】点击展开后再保存html文件,文件:{}", headerText);throw new Exception("该文件内容可能被折叠,请在原页面搜索【差异被折叠,点击展开】点击展开后再保存html文件");}Elements trElements = findTableElements(element).get(0).getElementsByTag("tbody").get(0).getElementsByTag("tr");// 遍历所有的行,得到文件内容for (Element tr : trElements) {String lineContent = tr.getElementsByClass("line_content").get(0).text();// 旧代码if(tr.getElementsByClass("old").size()>0){createText(doc, lineContent, CODE_TYPE_OLD);continue;}// 新代码if(tr.getElementsByClass("new").size()>0){createText(doc, lineContent, CODE_TYPE_NEW);continue;}createText(doc, lineContent, "");}}FileOutputStream fileOutputStream = new FileOutputStream(saveWordPath);doc.write(fileOutputStream);fileOutputStream.close();log.info("文档生成成功,存储路径:{}", saveWordPath);}/*** 创建标题* @param doc* @param headerText 标题文本*/private static void createHeader(XWPFDocument doc, String headerText) {// 创建标题XWPFParagraph paragraph = doc.createParagraph();//标题等级,1,2,3...paragraph.setStyle("1");//设置对齐paragraph.setAlignment(ParagraphAlignment.LEFT);XWPFRun run = paragraph.createRun();run.setColor("000000");run.setText(headerText);run.setFontFamily("黑体");run.setFontSize(22);// 加粗run.setBold(true);}/*** 生成文件路径* @param doc* @param contentText 文本内容*/private static void createTextHeader(XWPFDocument doc, String contentText) {XWPFParagraph paragraph = doc.createParagraph();// 左对齐paragraph.setAlignment(ParagraphAlignment.LEFT);XWPFRun contentRun = paragraph.createRun();contentRun.setFontSize(11);// 前面创建空行createNullLine(doc, 2);contentRun.setText(contentText);// 加粗contentRun.setBold(true);}/*** 文件内容* @param doc* @param contentText 文本内容* @param textType 代码内容标识*/private static void createText(XWPFDocument doc, String contentText, String textType) {XWPFParagraph paragraph = doc.createParagraph();// 左对齐paragraph.setAlignment(ParagraphAlignment.LEFT);XWPFRun contentRun = paragraph.createRun();contentRun.setFontFamily("Consolas");contentRun.setFontSize(9);contentRun.setText(contentText);// 突出显示CTShd ctShd = contentRun.getCTR().addNewRPr().addNewShd();// old:旧代码,new:新代码if (CODE_TYPE_OLD.equals(textType)) {ctShd.setFill("FFEFD5");} else if (CODE_TYPE_NEW.equals(textType)) {ctShd.setFill("CCFF99");}}/*** 创建空行* @param doc* @param lineNum 行数*/private static void createNullLine(XWPFDocument doc, int lineNum) {XWPFParagraph paragraph = doc.createParagraph();XWPFRun contentRun = paragraph.createRun();for (int i = 0; i <lineNum; i++) {contentRun.setText("\n");}}/*** 查找表格元素* @param element 元素对象* @return*/private static Elements findTableElements(Element element) {Elements trElements_temp = element.getElementsByClass("diff-content");for (Element element_t : trElements_temp) {int tableSize = element_t.getElementsByTag("table").size();if (tableSize > 0) {return element_t.getElementsByTag("table");}}return null;}
}
具体页面具体分析。主要就是利用jsoup读取html内容并处理,jsoup的使用细节可以参考官方文档。