Python机器学习算法入门教程(第五部分)
接着Python机器学习算法入门教程(第四部分),继续展开描述。
二十五、Python Sklearn库SVM算法应用
SVM 是一种有监督学习分类算法,输入值为样本特征值向量和其对应的类别标签,输出具有预测分类功能的模型,当给该模型喂入特征值时,该模型可以它对应的类别标签,从而实现分类。
1、Sklearn库SVM算法
下面我看一下 Python 的 Scikit -Learn(简称 Sklearn) 库是如何实现 SVM 算法的。
支持向量机算法被包含在 sklearn.svm 模块中,该模块提供了 7 个常用类,这些不同的类分别应用了不同的核函数,因此它们可以解决不同的问题,比如分类问题、回归问题以及无监督学习中的异常点检测等。下表对它们做了简单的介绍:
| SVM算法类别 | 描述 |
|---|---|
| LinearSVC类 | 基于线性核函数的支持向量机分类算法 |
| LinearSVR类 | 基于线性核函数的支持向量机回归算法 |
| SVC类 | 可选择多种核函数的支持向量机分类算法,通过“kernel”参数可以传入 linear:选择线性函数; polynomial:选择多项式函数; rbf:选择径向基函数; sigmoid:选择 Logistics 函数作为核函数; precomputed:使用预设核值矩阵, SVC 类默认以径向基函数作为核函数。 |
| SVR类 | 可选择多种核函数的支持向量机回归算法 |
| NuSVC类 | 与 SVC 类非常相似,但可通过参数“nu”设置支持向量的数量。 |
| NuSVR类 | 与SVR类非常相似,但可通过参数“nu”设置支持向量的数量。 |
| OneClassSVM类 | 用支持向量机算法解决无监督学习的异常点检测问题 |
SVM 主要用于解决二分类的问题,上述表格中最常使用的是 SVC 类。下面对使用该算法的步骤进行总结:
- 读取数据,将原始数据转化为 SVM 算法所能识别的数据格式;
- 将数据标准化,防止样本中不同特征数值大小相差较大影响分类器性能;
- 选择核函数,在不清楚何种核函数最佳时,推荐使用“rbf”(径向基核函数)
- 利用交叉验证网格搜索寻找最优参数;(交叉验证的目的是防止过拟合,利用网格搜索可以在指定的范围内寻找最优参数)
- 使用最优参数来训练模型;
- 测试得到的分类模型。
2、SVM算法应用
下面使用 SVM 算法对鸢尾花数据集进行分类处理(若想下载鸢尾花数据集可从UCI官方下载)如图所示:

图1:鸢尾花数据集
数据集的中每一行都是一个鸢尾花的观察结果,前四个数据代表鸢尾花的生物属性,比如花萼长度、宽度以及花瓣的长度、宽度,最后一项表示鸢尾花的类别,共三类,分别是山鸢尾(0表示)、色鸢尾(1表示)、维吉尼亚鸢尾(2表示),我们的任务就是对它们进行正确分类,数据集的部分数据展示如下:

图2:鸢尾花数据集
下面使用支持向量机(SVM)算法对鸢尾花数据集进行分类,代码如下所示:
from sklearn.datasets import load_iris # 导入鸢尾花数据集
from sklearn.svm import SVC #使用支持向量机算法
import matplotlib.pyplot as plt# 加载鸢尾花数据集,返回特征值 X 以及标签 y
X,y = load_iris(return_X_y=True)
# 使用SVM.SVC分类算法搭建预测模型,并以径向基函数做为核函数的实现高维映射
clf = SVC(kernel='rbf')
# 训练模型,使用fit喂入数据X,y,即特征值和标签
clf.fit(X, y)
# 预测分类
result=clf.predict(X)
print(result)
# 对模型进行评分
score=clf.score(X,y)
print(score)plt.figure()
# 分割图1行1列第一个图
plt.subplot(111)
# 选择X特征值中的第一列特征值和第四列特征值进行绘图
plt.scatter(X[:,0],X[:,3],c =y.reshape((-1)),edgecolor='k',s=50)
plt.show()输出结果如下:
# 类别预测结果
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 2 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 1 2 2 2 2 2 2 2 2 2 2 2]
# 模型得分
0.9733333333333334
对分类结果进行可视化展示:
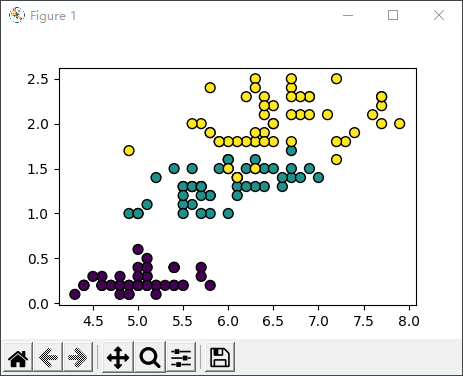
图3:数据可视化
支持向量机算法在分类问题中有着非常出色的表现,它的特点是够解决非线性问题,并且训练模型的时候不必依赖于全部数据,主要使用处于分类边缘的样本点,因此它也适用解决小样本群体的分类问题,并且泛化能力较强。
当然,SVM 也有一些不足之处,比如核函数的寻找难度较大,并且最原始的 SVM 算法只适用于二分类问题。后经过不断的拓展、延伸,目前的 SVM 算法可以解决多分类问题,同时能够解决文本分类问题。
二十六、什么是K-means聚类算法(无监督)
机器学习算法主要分为两大类:有监督学习和无监督学习,它们在算法思想上存在本质的区别。
有监督学习,主要对有标签的数据集(即有“参考答案”)去构建机器学习模型,但在实际的生产环境中,其实大量数据是处于没有被标注的状态,这时因为“贴标签”的工作需要耗费大量的人力,如果数据量巨大,或者调研难度大的话,生产出一份有标签的数据集是非常困难的。再者就算是使用人工来标注,标注的速度也会比数据生产的速度慢的多。因此要想对没有被标注的数据进行分类,就要使用无监督学习算法。
常见的无监督学习算法,包括 K-means 聚类算法、均值漂移聚类算法、主成分分析法(即 PCA 算法)、EM算法(期望最大化算法)等。本节介绍无监督学习中最为经典的 K-means 算法,它是聚类算法簇中的一个,也是最为经典的聚类算法,其原理简单、容易理解,因此得到广泛的应用。通过对该算法的学习,您将掌握什么是聚类问题,以及如何解决聚类问题。
1、聚类和分类的区别
聚类算法与分类算法的最终的目的都是将数据区分开来,但是两者的实现过程完全不同。分类问题,通过对已有标签的数据进行训练来确定最佳预测模型,然后对新样本的所属类别进行预测,在这个过程中算法模型只要尽可能的实现最佳拟合就 OK 了。与分类问题不同,聚类问题没有任何标签,可谓是一遍茫然,就像做练习题没有参考答案一样,不知道自己做的是否正确。在这种情况下,如果您想证明自己做的题目是否对,在没有参考答案的情况下,您会怎么做呢?没错,您可以多找同学几位同学,甚至找全班同学去对比。
举个简单的例子:一道选择题,你的选择答案是 A,通过询问后您发现全班 85% 以上同学都选择的 A,其余 15% 都选择的 C,那么您心里就会认为自己选择的是正确的,毕竟选择 A 选项占了多数,但是在老师没有公布正确答案之前,什么也说不准,也许会发生“真理只掌握在少数人手里”的事情,因此选择 C 的同学也并不一定就是是错误的,通过这种“找相似”的方法即使在没有“参考答案”的前提下,也能实现分类。因此“找相似”是解决聚类问题的核心方法。
2、找相似
俗话说“物以类聚,人以群分”,从这句成语中就能体会到“找相似”奥妙,兴趣相投人总会相互吸引,相似的物也总会放在一起。同样的道理,在一份数据集中拥有相似特征的数据也要聚集在一起,这样才便于将这些数据区分开来,但世界上并不存在完全相同的两片叶子,因此聚类算法在实现分类时,只能尽可能找相同点,相同点越多,说明他们就属于同一类,而不同点越多,就说明两者不是同一类。
我们知道,动物种类可以按照科属进行划分,比如豹子、老虎、猫咪都属于猫科动物,有时你可能无法相信,温顺的猫咪竟然和凶猛的老虎同属猫科动物,这就说明他们身上有相似的地方,比如都善于攀爬以及跳跃、皮毛柔软、爪子锋利并可伸缩等等。其实,科学家们最初也没有一个明确的答案知道什么是“猫科动物”,他们通过找相似特征的方法,最终将动物们分门别类,因此这个过程也可以看做是“无监督学习”。
通过上述知识的学习,我们知道解决聚类问题的关键就是“找相似”,下面我们来看一看,K-means 聚类算法是如何在数据集中寻找相同点的。
3、簇是什么
在聚类问题中,有一个非常重要的概念“簇”(Cluster),那到底什么是簇呢,样本数据集通过聚类算法最终会聚集成一个个“类”,这些类在机器学习中的术语称为“簇”(注意,这里的前提是使用“聚类算法”),因此“簇”是解决聚类问题的表现形式,数据集中的数据样本最终会以“簇”的形式分开。那么当要解决一个聚类问题时,到底要汇集成多少簇呢?
对于分类问题而言,由于有参考答案,因此要分成多少类是已知的,但是聚类则不同,由于没有参考答案,所以形成多少个簇,事先谁也不知道。
举个简单的例子:有同样大小的正方形和圆形各 3 个,每个方形和圆形的颜色两两相同,分别是黄色、红色、绿色,如果按照形状分类的话,可以分为圆形和正方形两个簇,如果按照颜色分类的话,可以分为黄色、红色、绿色三个簇。由此可见选择的分簇条件不同,形成的簇的数量也不同,从而聚类的结果也不同。
不同聚类算法采取了不同的思路,主要分为划分法、层次法、密度法和网格法,这些方法大致可总结为两类,一类是预先设定有多少个簇,另一类则是在聚类的过程中形成。
4、理解K的含义
K-means 就是一种采用了划分法的聚类算法,K-means 聚类算法与前面的 KNN 分类算法一样,都带有字母“K”,前面我们说过,机器学习喜欢用字母“K”来表示“多”,就像数学中常用字母“n”来表示是同样的道理,但 K-means 中的 K 究竟是什么意思呢?不妨先回顾一下 KNN 分类算法中的 K。
我们知道,KNN 分类算法采用了“多数表决的方法”,最终样本类能够完成分类,完全依赖于该方法,比如 KNN 中的 K 表示有多少个样本点参与表决,这里的 K 对于样本的分类起到了关键性的作用,因此可以换个说法,多数表决是需要限定在 K 规定范围内的。
再说 K-means 中的 K,由于该算法是没有参考标准的。如果不加以限定的话,它会形多任意数量的“簇”,这就要求我们要预先设定“簇”的数量,就像田忌赛马一样,根据马的自身的特点,将其分为上、中、下三个档次,因此 K-means 中 K 是聚集成几个“簇”,形成几个“类”的意思。
5、如何量化“相似”
前面我们提到过解决“聚类问题”的关键是找到“相似”之处,只有找到了相同点才可以实现类别的划分,说的直白一点,聚类的过程就是让相似的样本互相抱团的过程,这个过程看上去很简单,但实际上要怎样去操作呢?
注意,这里所说的“相似”有时也称之为“相似度”与之含义相反的是“相异度”,相异度越低,相似度就越高,这些词语主用于是衡量对象之间的相似程度。
不妨先回顾一下 KNN 最近邻分类算法,该算法以待分类样本点为中心,通过度量距离找出与其最近邻的 K 个样本点,哪个类别的样本点数量多,那么就认为待分类的样本点属于哪一类。在这个过程中有两点是解决分类问题的关键,一是以待分类样本为“中心点”;二是通过度量距离来确定 K 个最邻近中心的样本点,从而找到哪几个样本点拥有表决权。
在聚类算法中“相似”其实并不是一个具体的指标,就像“人以群分”这句成语,它没有提供具体的划分标准,即“以什么分”,可能是性格、爱好,也可能是志向,甚至是人的高低贵贱,因此量化相似也要根据具体的场景,也就是确定比较的标准(即度量相似的标准)。
K-means 聚类算法与 KNN 算法有许多相似之处(即使在本质它们并不相同),KNN 通过度量距离确定距离自己最近的“朋友圈”,其实换个角度来看的话,这个“朋友圈”就相当于 K-means 中的“簇”,因此我们可以采用与 KNN 相同的度量工具作为量化“相似”的标准。
(1) 随机选择质心
从 KNN 解决分类问题的过程不难看出,要想解决 K-means 聚类问题,同样需要一个“中心点”。
假设聚类问题的样本数据也能找出 K 个中心点,就能以该点为中心,以距离为度量画出范围来,将同一范围内的样本点作为一个簇,从而解决聚类问题,在 K-means 聚类算法中,这样的中心点称为“质心”。
聚类算法是无监督学习,因此数据中的样本点完全不知道自己属于哪一个簇, 就更别谈缺点“质心”了,为了解决这一问题,K-means 算法通过随机选择方式来确定质心,但由于是随机选择,因此无法保证随机选择的 K 个质心就恰好是完成聚类后的 K 个簇的中心点,这时就用到了“mean”,它是“均值”的意思,通过均值可以不断的调整质心,由此可知质心在 K-means 算法中是不断改变的。
(2)求出新质心点
假设现在随机了 K 个质心得到了 K 个簇,接下来要怎样让这 K 个簇形成新的质心呢?做法有很多,K-means 算法选择了最简单的一种,求平均。
每个簇都有若干数据点,求出这些数据点的坐标值均值,就得到了新质心的坐标点,比如一个簇中有三个数据点,分别 (3,2),(3,1),(2,3),那么新质心点位于:
x:(3+3+2)/3 约等于 2.666
y:(2+1+3)/3 = 2
质心坐标:(2.666,2)
这其实也是一种变相的多数表决。根据全体拥有表决权的数据点的坐标来共同决定新的质心在哪里,而表决权则由簇决定。
在 K-means 聚类的过程中会经历多次质心计算,数据点到底归属于哪个簇可能会频繁变动,比如同一个数据点可能在本轮与一群样本点进行簇 A 的质心计算,而在下一轮就与另一群样本点进行簇 B 的质心计算,这也是 K-means 算法与 KNN 算法最大的不同之处。
6、总结
K-means 聚类算法的聚类过程,可以看成是不断寻找簇的质心的过程,这个过程从随机设定 K 个质心开始,直到找到 K 个真正质心为止。
K-means 聚类算法的大致过程如下所示:
- 第一步,既然现在有了 K 个质心,对于其他数据点来说,根据其距离哪个质心近就归为哪个簇的办法,可以聚成 K 个簇。但请注意,这只是第一步,并不是最后完成聚类的结果;
- 第二步,对于聚成的 K 个簇,需要重新选取质心。这里运用了多数表决原则,根据一个簇内所有样本点各自的维度值来求均值,得到该簇的新的坐标值;
- 第三步是生成新的质心,其实就是重复上述过程。对于根据均值计算得到的 K 个新质心,重复第一步中离哪个质心近就归为哪个簇的过程,再次将全部样本点聚成 K 个簇,经过不断重复,当质心不再变化后,就完成了聚类。
最后总结一下:K-means 算法首先逐个计算数据集中的点到各自质心的距离,根据距离的远近,将数据样本点分别划归到距离最近的质心,从而形成 K 个类,然后继续选取新的质心,即对聚类内所有数据点求均值。最后重复上述两个过程:生成新质心后重新进行聚类,然后根据聚类结果再次生成新的质心,直至划分的“类”不再变化时结束。
二十七、K-means聚类算法原理解析
通过二十六一节的学习,我们了解了 K-means 聚类算法的聚类过程,其实就是不断寻找簇的质心的过程,该过程从随机设定 K 个质心开始,直到找到 K 个最合适的质心为止。本节我们透过算法流程直击算法的本质,帮助您彻底理解 K-means 算法。
1、度量最小距离
对于 K-means 聚类算法而言,找到质心是一项既核心又重要的任务,找到质心才可以划分出距离质心最近样本点。从数学角度来讲就是让簇内样本点到达各自质心的距离总和最小。
通过数学定义,我们将“质心”具象化,既然要使“距离的总和最小”,那么第一步就是确定如何度量距离,K-means 算法通过『欧几里得距离』来衡量质心与样本点之间的距离。前面在学习 KNN 算法时,我们介绍了『闵可夫斯基距离』,其公式如下:
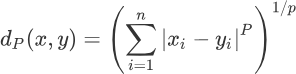
上述式子中 "∑" 符号称为求和符号,与 sum 函数功能一致,闵氏距离是一组代数形式的公式,通过给 P 设定不同的值,就能用闵氏距离得到不同的距离表达式。当 P =1 时,可以得到曼哈顿街区距离(简称“曼哈顿距离”);P = 2 时即可得到欧几里得距离,该公式常用于度量两点之间的直线距离,表达式和 L2 范式相同,如下所示:
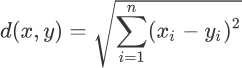
举个简单的例子:如果第 j 个簇内有若干个数据点(比如 m 个),根据上述欧几里得距离公式就可以计算出簇中各个点到质心z的距离总和,如下所示:
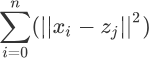
注意,上述公式中的 zj 是簇内所有样本点求均值的结果。
我们知道 K-measn 算法中会有 K 个簇,因此就要使每个簇内的数据点到质心的距离都可以达到最小,最终使得距离的总和最小。您可以这样理解,K 个簇共同组成了一个集合(这里定义为 A 集合),在 A 集合中每个簇的样本点到各自质心的距离都是最小的,因此可得如下表达式:
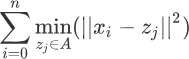
2、总结
上述内容,从数学的角度对 K-means 算法的原理进行了深入剖析,下面我们对 K-means 算法的流程进行回顾,可分以下四步:
- 随机选取 K 个对象,并以它们为质心;
- 计算数据集样本点到质心的距离;
- 根据样本点距离质心的距离将其分簇(类),距离哪个近,划分到哪个簇(类);
- 以簇内所有样本点的均值重新计算质心,,然后重复第二步,直到划分的簇(类)不在变化后停止。
K-means 算法是属于无监督学习算法,常用于解决聚类问题,通过给算法模型输入一个包含多种特征信息的样本点,会返回一个相应的类别编号(或称簇别),从而完成样本数据点的类别划分。
注意,判定聚类任务完成的终止条件并不是唯一的,常用方法有三个:
- 簇内数据点向质心靠拢、收敛,使得质心点不再发生明显的变化;
- 使用误差平方和(即 SSE)来衡量,当误差平和的值越小时,表示数据点越接近于他们的质心,聚类效果越好;
- 设定指定的定迭代次数,即最多选取几次质心点,不过这种方法,未必能达到最好的分类效果。
二十八、K-means聚类算法的应用以及实现
K-means 聚类算法属于无监督学习,它会将相似的对象归到同一个簇中,该算法原理简单,执行效率高,并且容易实现,是解决聚类问题的经典算法。
尽管如此,任何一款算法都不可能做到完美无瑕,K-measn 算法也有自身的不足之处,比如 K-means 需要通过算术平均数来度量距离,因此数据集的为维度属性必须转换为数值类型,同时 K-means 算法使用随机选择的方式来确定 K 的数量和初始化质心 ,因此不同的随机选择会对最终的分簇结果产生一定程度的影响。
1、算法应用场景
每一种算法都有各自适用的场景,对于 K-means 算法也不例外,它适合于解决而特征维度为数值型的聚类问题。
举个简单的例子,一个赛季结束后,篮球队要对队员的整体表现进行聚类分析,此时每位队员的特征维度都是可以量化的,比如某队员的上场时间、得分数、助攻数、失误数等。
K-means 算法也适用于文本聚类,比如新闻网站会将相同话题的新闻聚集在一起,并自动生成一个个不同话题的新闻专栏,其实这就是利用聚类算法实现的,但是文本的特征维度并非数值类型,因此需要对其进行数值转化操作,将文本数据转换为数学信息,此时可以使用 TF-IDF 加权技术计算单个词的权值。
TF-IDF 是一种用于信息检索与数据挖掘的常用加权技术。TF 是词频(Term Frequency),IDF 是逆文本频率指数(Inverse Document Frequency)。
下表对 K-means 聚类算法的特点做了简单说明:
| 项目 | 内容 |
|---|---|
| 优点 | 原理简单,实现容易,运算效率高。 |
| 不足 | 需要人为设置簇的个数与随机初始化质心点可能影响聚类的最终效果,同时 K-measn 算法对孤立点(离群点)特别敏感,会对最终的聚类结果产生明显扰动。 |
| 应用领域 | 适用于特征维度为数据类型的聚类问题,比如体育赛事等,而对特征维度不是数据类型的需要提前进行转换,比如文本分类等。 |
2、Sklearn使用K-means算法
在 Sklearn 机器学习库中,与聚类相关的算法模型都在 cluster 模块下,除 k-measn 外,还有十种聚类最近邻算法,下表对最常用的算法做了简单介绍:
| 类名 | 说明 |
|---|---|
| KMeans 类 | 本节介绍的算法,也是应用最多的聚类算法 |
| MiniBatchKMeans 类 | 该算法是 K-measn算法变形算法,使用 mini-batch(一种采样数据的思想) 来减少一次聚类所需的计算时间,mini-batch 也是深度学习常使用的方法。 |
| DBSCAN 类 | DBNSCAN 算法是一种比较有代表性的基于密度的聚类算法,它的主要思想是将聚类的类视为被低密度区域分割的高密度区域。与划分聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇。 |
| MeanShift 类 | MeanShift 算法流程,以任意点作为质心的起点,根据距离均值将质心不断往高密度的地方移动,也即所谓均值漂移,当不满足漂移条件后说明密度已经达到最高,就可以划分成簇。 |
| AffinityPropagation 类 | AffinityPropagation 算法(简称 AP 算法),该算法是层次聚类的典型应用,聚类实现过程是一个“不断合并同类项”的过程,用类似于归纳法思想来完成聚类。 |
通过表格不难看出,每一种算法所采用的思想均不相同,但最终都能解决聚类问题,这也是整个聚类算法族的特点之一。
下面我们对Kmeans.Kmeans()的常用参数做简单介绍:
| 参数 | 说明 |
|---|---|
| algorithm | 字符串参数值,有三种选择: 1) "auto" :默认值,自动根据数据值是否稀疏,来决定使用 "full"还是"elkan",采用默认值即可; 2) "full":表示使用传统的 K-measn 算法; 3) "elkan":表示使用 elkan-Means 算法,该算法可以减少不必要的距离计算,加快计算效率。 |
| n_cluster | 整型参数,表示分类簇的数量,默认值为 8 |
| max_iter | 整型参数,表示最大的迭代次数,默认值为 300 |
| n_init | 整型参数,表示用不同的质心初始化值运行算法的次数,默认值为 10 |
| init | 字符串参数,有三个可选参数: 1)" k-means++" ,默认值,用一种特殊的方法选定初始质心从而能加速迭代过程的收敛,效果最好; 2) "random" 表示从数据中随机选择 K 个样本作为初始质心点; 3) 提供一个 ndarray 数组,形如 (n_cluster,n_features),以该数组作为初始质心点。 |
| precompute_distance | 有三个可选值,分别是 "auto", True, False: 1) "auto" :如果样本数乘以聚类数大于 12 million 的话则不予计算距离; 2) True:总是预先计算距离; 3) False:永远不预先计算距离。 |
| tol | 浮点型参数(float),表示算法收敛的阈值,默认值为 1e-4 |
| n_jobs | 整型参数,指定计算所用的进程数量, 1) 若值为 -1,则用所有 CPU 进行运算; 2) 若值为 1 ,则不进行并行运算,方便调试; 3) 若值小于 -1,则用到的 CPU 数为(n_cpus+1+n_jobs),因此若为 -2 ,则用到的 CPU 数为总 CPU 数减去1 |
| random_state | 表示随机数生成器的种子,参数值为整形或 numpy.RandomState 类型 |
| verbose | 整型参数,默认值为 0,表示不输出日志信息;1 表示每隔一段时间打印一次日志信息;如果大于 1时,打印次数变得频繁。 |
最后通过鸢尾花数据集对 K-means 算法进行简单的演示,示例代码如下:
import matplotlib.pyplot as plt
import matplotlib
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris#设置 matplotlib rc配置文件
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题# 加载鸢尾花数据集
# 数据的特征分别是 sepal length(花萼长度)、sepal width(花萼宽度)、petal length(花瓣长度)、petal width(花瓣宽度)
iris = load_iris()
X = iris.data[:, :2] # 通过花萼的两个特征(长度和宽度)来聚类
k = 3 # 假设聚类为 3 类,默认分为 8 个 簇
# 构建算法模型
km = KMeans(n_clusters=k) # n_clusters参数表示分成几个簇(此处k=3)
km.fit(X)# 获取聚类后样本所属簇的对应编号(label_pred)
label_pred = km.labels_ # labels_属性表示每个点的分簇号,会得到一个关于簇编号的数组
centroids = km.cluster_centers_ #cluster_center 属性用来获取簇的质心点,得到一个关于质心的二维数组,形如[[x1,y1],[x2,y2],[x3,x3]]# 未聚类前的数据分布图
plt.subplot(121)
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.xlabel('花萼长度')
plt.ylabel('花萼宽度')
plt.title("未聚类之前")
# wspace 两个子图之间保留的空间宽度
plt.subplots_adjust(wspace=0.5) # subplots_adjust()用于调整边距和子图间距
# 聚类后的分布图
plt.subplot(122)
# c:表示颜色和色彩序列,此处与 cmap 颜色映射一起使用(cool是颜色映射值)s表示散点的的大小,marker表示标记样式(散点样式)
plt.scatter(X[:, 0], X[:, 1], c=label_pred, s=50, cmap='cool')
# 绘制质心点
plt.scatter(centroids[:,0],centroids[:,1],c='red',marker='o',s=100)
plt.xlabel('花萼长度')
plt.ylabel('花萼宽度')
plt.title("K-Means算法聚类结果")
plt.show()最终的显示结果如下图所示:
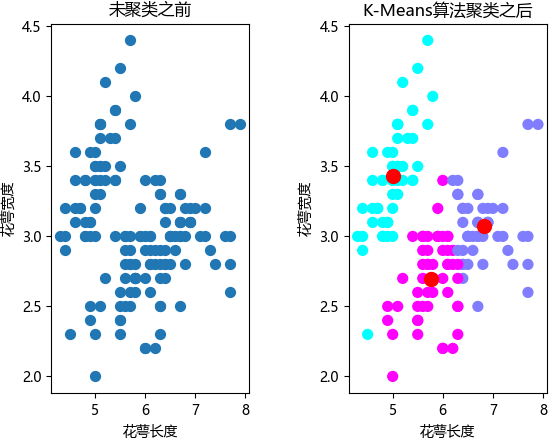
通过绘图结果可以看出,在没有“参考答案”的前提下,K-measn 算法完成了样本的分簇任务,其中红色圆点是质心点。
3、总结
聚类算法博大精深,每一种算法都有自己的实现原理,单拿 K-means 算法来说,就有多种基于它的衍生算法,比如二分 K-means 算法、K-means++ 算法、K-measn|| 算法、Canopy 算法,以及 Mini Batch K-means 算法等,这些算法的出现主要是为了弥补 K-means 算法的不足,比如随机选择初始簇质心点,以及 K 值敏感等问题。
不过世界上并没有十全十美的算法,因此这些算法也多少存在一些不足之处。如果您对上述提及的算法感兴趣,在掌握 K-means 算法的前提下,不妨自己钻研一下。
二十九、人工神经网络是什么
在本教程的开篇《一、什么人是工智能》一节中详细的阐述了深度学习发展历程,以及人工智能、机器学习、深度学习三者间的关系。就目前而言,这三者中红到发紫的当属“深度学习”。
深度学习(Deep Learning)这一概念是由 Geoffrey Hinton(深度学习之父)于 2006 年提出,但它的起源时间要早得多,可追溯至 20 世纪四五十年代,也就是人类刚刚发明出电子计算机时就已经提出来了,但当时并非叫做深度学习,而是人工神经网络(artificial neural network, ANN),简称神经网络(NN),它是一种算法模型,其算法的构思灵感来源于生物神经网络。
深度学习作为一个新兴概念,谈起时都会涉及如何搭建神经网络,由此可见深度学习的核心思想仍是人工神经网络模型。目前的神经网络算法与刚刚诞生时相比有了很大的变化,但总的来说,基本的算法思想并没有改变。本节内容将主要围绕人工神经网络展开介绍。
1、MP神经元模型
人工神经网络是一种有监督学习算法,它试图通过模拟人脑神经系统对复杂信息的处理机制来构建一种数学模型。我们知道,神经元是构成生物神经系统的基本单元,而人工神经网络也不例外,它也是从神经元模型的基础上发展而来的。
1943 年,美国心理学家麦克洛奇(Mcculloch)和数学家皮兹(Pitts)提出了 M-P 神经元模型(取自两个提出者姓名的首字母),这是最早、也是最简单的神经网络算法的模型,该模型意义重大,从此开创了神经网络模型的理论研究。在正式介绍 MP 神经元模型前,我们不妨先了解一下大脑神经元。
(1) 生物神经元
神经元是大脑神经系统重要组成单位,主要由细胞体、树突、轴突、突触组成。神经元是一种多输入单输出的信息处理单元,输入的电信号有两种,分别是兴奋性信号和抑制性信号。
树突,可以看作输入端,接受从从其他细胞传递过来的电信号;轴突可以看作输出端,传递电信号给其他细胞;突触,则可以看成 I/O 接口,用于连接不同神经元,单个神经元可以和上千个神经元进行连接;细胞体内存在膜电位,外界传递过来电流时会使膜电位发生变化,当电位升高到一个阈值时,神经元就会被激活,产生一个脉冲信号,传递到下一个神经元。
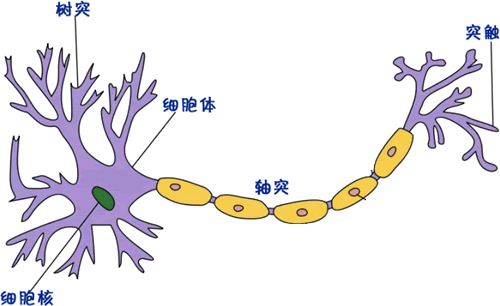
图1:生物神经元组成
为了便于大家理解神经元传递信号的过程,我们不妨把神经元看成一个水桶。水桶一侧的下方连接着多根水管(看做树突),水管即可以把桶里的水排出去,也可以将其他桶内的水输入进来,水管的粗细不同(理解为权重大小),对桶内水位的影响程度不同,当桶内的水位达到某一范围时(阈值),就能通过水桶另一侧的排水管将水(轴突)排出,从而降低水桶的水位。
(2) M-P神经元
M-P 模型就是基于生物神经构建的一种数学模型,只过不它将生物神经元信息传导过程进行了抽象化,并以网络拓扑相关知识来表示。
M-P 模型是神经网络的基本组成单位,在神经网络中也称为『节点(node)』或者『单元(unit)』。节点从其他节点接受输入,或从外部源接受输入(即 x1、x2、1),每个输入都带有一个权重值(weight,即 w),权重大小取决于输入值的相对重要性。函数 f 位于节点处,它是一个关于 ω、x 的线性函数,记做 f(x,ω) ,输入 b 表示函数的偏置项,最后经过 f(w,x) 的计算得输出 Y。模型如下所示:

图2:神经元模型示例图
上述模型对于神经网络说来说具有重要的意义,它是神经网络研究的开端。您可能会很诧异,几个带有箭头线段、一个圆形竟然就能表示 M-P 神经元模型? 正所谓大道至简,它的确就是神经元模型,上图所示模型由 3 部分组成,从左往右依次为:神经元的输入、输入信号处理单元,以及神经元的输出。
M-P 模型采用数学模型模拟了生物神经元所包含的细胞体、树突、轴突和突出等生理特征。通过 M-P 模型提出了神经元的形式化数学描述和网络结构方法,从而证明了单个神经元能执行逻辑功能,但由于模型中的权重和偏置是人为设置的,因此该模型并不具备学习的能力。
(3) M-P模型解析
我们知道,神经元是一种多端输入单端输出的信息处理单元,因此 M-P 神经元模型也遵循这个原理。神经元的输入端通常会被给予不同的权重,来权衡不同输入信号的重要程度,如图 2 所示是一个有 3 个输入,一个输出的神经元模型,该神经元模型接收 3 个输出信号,然后给予输入信号不同的权重,神经元的输入信号经过处理后得到神经元输出。注意,这里所说的信号可以理解为数据集中的数据样本。
(4) 信息处理单元
介于输入和输出之间的圆圈称为输入信息处理单元(即节点),之所以画成圆圈也是一种约定俗成的表示方式,而这个信息处理单元可以看成一个函数,当给这个模型“喂入”一个数据时,就会产生一个对应的输出。早期的 MP 神经元模型可以看成一种线性分类器,通过检验 f(x,ω) 的正负来识别两种不同类别的时输入。由此可知,该模型需要正确设置权重参数,才能使模型的输出对应所期望的类别。
注意:这里的 x 是表示输入值,ω 是输入的权重值,f(x,ω) 是一个线性函数,这也决定了该模型只能解决简单的线性问题,而对于复杂的数据分布,就无法达到理想的拟合效果。
2、感知机模型
新事物的诞生需要大众的一个认知过程,并非一问世就能一鸣惊人,虽然早在 1943 年基于 M-P 神经元人工神经网模型就被提出,但当时并没有引起人们的重视。直到 20 世纪 50年代(1957年),美国学者罗森勃拉特提出了感知器(或称感知机)模型,这才引发了一次 AI 领域的研究热潮,因此从某种意义上来说,感知器模型是第一个具有学习能力的神经网络,该模型能根据每个类别的输入样本来学习权重。
(1) 感知器模型
感知器模型,也可称为单层感知器,它是最简单的神经网络,它包含输入层和输出层,并且层与层之间直接相连。该模型从神经元模型的基础上发展而来,单层感知器能模拟逻辑与、逻辑或、逻辑非和逻辑与非等操作,单层感知器模型如下:
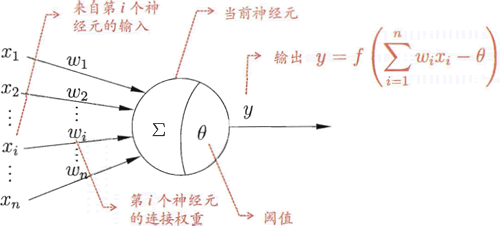
图3:感知器模型
虽然具备了学习的能力,但该模型只能解决简单的线性分类和线性回归问题,对于线性不可分问题(即异或问题,xor)仍无法解决(1969年,科学家明斯基和佩珀特证明)。如下图所示,无法找到一条直线可以把圆形和菱形分开:
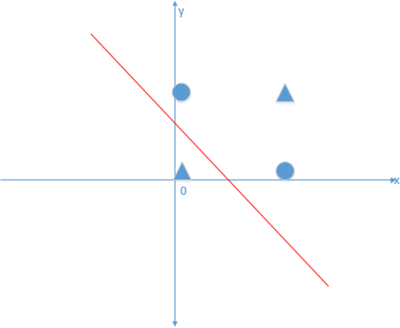
图4:线性不可分问题
感知器模型算法与神经元模型类似,是一个单层神经元结构,它首先对输入的数据进行加权求和,然后将得到的结果与阈值进行比较,假如与所期望的输出有较大误差,就对权值参数进行调整,反复多次,直到误差满足要求时为止。由上图可知单层感知器的输出为:
![]()
下面举个简单例子,看看单层感知器如何完成逻辑与运算(即 And,x1 ∧ x2):
令 w1 = w2 =1,θ = 1.5,则 y =f(1*x1+1*x2-1.5),显然,当 x1 和 x2 均为 1 时,y 的值为 1;而当 x1 和 x2 中有一个为 0 时,y 的值就为 0(通过 y 值的正负来取值,正值取值 1,负值取值 0,从而实现线性分类),当然逻辑或运算、与逻辑非运算也可通过此方法验证。
异或是一个数学运算符号,使用 ⊕ 来表示,计算机一般用 ^ 来表示。异或也叫半加运算,其运算法则相当于不带进位的二进制加法,用 1 表示真,用 0 表示假,运算法则为“同为 0,异为 1”。:
0⊕0=0
1⊕0=1
0⊕1=1
1⊕1=0
因此 w1、w2 和 θ 必须满足以下方程组:
0 + 0 - θ < 0 --> θ > 0
ω1 + 0 - θ ≥ 0 --> 0 ≥ θ - ω1
0 + ω2 - θ ≥ 0 --> 0 ≥ θ - ω2
ω1 + ω2 - θ < 0 --> θ > ω1 + ω2
将上述数值带入方程组后,只有第一个方程组是成立,其余方程均不成立。由此得出单层感知器模型是无法解决异或问题的(线性不可分问题)。
(2) 激活函数
由上述函数表示式可知,感知器是一个二分类的线性模型,输入与输出结果是一组线性组合,这极大的限制了感知器的应用范围。但这一问题很快便得到了解决,我们只需将非线性函数以“激活函数”的身份加入神经网络算法中,就可以扩展感知器模型的应用范围。通过它对线性函数的输入结果进行非线性映射,然后将结果作为最终值输出。
激活函数的加入对后期神经网络的发展提供了很大支持,目前这种算法思想仍在神经网络算法中广泛使用。下图展示了带有激活函数的感知器模型:
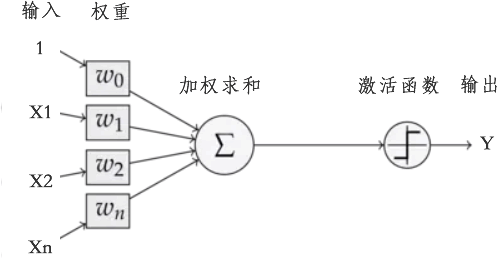
图5:感知器模型
上述感知器模型依然模拟了神经元结构,有输入(input)、权重(weight)、前馈运算(feed forward)、激活函数(activation function)、输出(output)等部分组成。注意,这里的前馈运算指的是图 3 中的『加权求和』,即在没有使用激活函数时输入值的加权求和结果,有时也记做『logit』。
通过上述模型很容易实现二分类。只需将对加权求和的结果值进行判断即可,比如 x>0 为 1 类,若 x <=0 则为 0 类,这样就将输出结果值映射到了不同类别中,从而完成了二分类任务。激活函数公式如下:
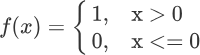
若想采用感知器模型解决线性回归问题就可以使用 sigmoid 函数,该函数在《九、Logistic回归问题(分类问题)》 一节进行了介绍,激活函数公式如下:
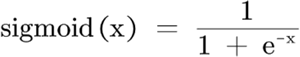
注意:常用非线性激活函数有多种,比如 sigmoid 函数、Tanh 函数、Relu 函数等
(3) 多层感知器模型
由于单层感知器模型无法解决非线性可分问题,即 xor 问题(1969年,马文·明斯基证明得出),这也导致了神经网络热潮的第一次大衰退。直至 20 世纪 80 年代,多层感知器模型(Multi -Layer Perceptrons,缩写为 MLP)的提出(1981年,韦伯斯提出),神经网络算法再次回归大众视野。
与单层感知器模型相比,该模型在输入层与输出层之间增加了隐藏层(Hidden),同时输出端,由原来一个增至两个以上(至少两个),从而增强了神经网络的表达能力。注意,对于只有一层隐藏层的神经网路,称为单隐层神经网络或者二层感知器,网络拓扑图如下所示:
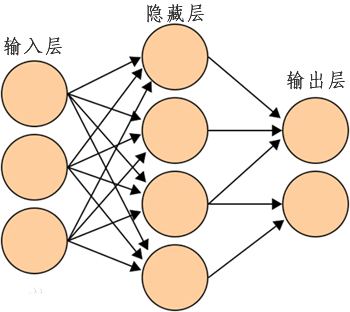
图6:多层感知器模型
从图 6 不难发现,多层感知器模型是由多个感知器构造而成的,模型中每一个隐藏层节点(或称单元)都可以看做成一个感知器模型,当我们将这些感知器模型组合在一起时就可以得到“多层感知器模型”。输入层、隐藏层与输出层相互连接形成了神经网络,其中隐藏网络层、输出层都是拥有激活函数的功能神经元(或称节点)。
在神经网络中的隐藏层可以有多层,当隐藏层有多层,且形成一定“深度”时,神经网络便称为深度学习(deep learning),这就是“深度学习”名字的由来。因此,深度学习就是包含了多个隐藏层的多层感知器模型。如下图所示,是具有两个隐藏层的神经网络:
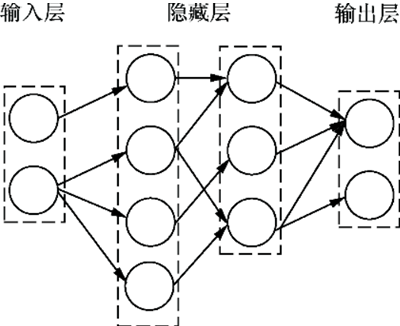
图7:多层感知器模型(两个隐藏层)
但『深度学习』这一概念直到 2006 年才被提出,在这之前多层感知器模型被称为“人工神经网络”。从神经元模型到单层感知器模型再到多层感知器模型,这就是人工神经网络的发展过程。在神经网络中每层的节点与下一层节点相互连接,节点之间不存在同层连接,也不存跨层连接,这样的网络结构也被称为“多层前馈神经网络”(multi-layer feedforward neural),如果层与层之间的节点全部相互连接,则称为“全连接神经网络”,如下所示:
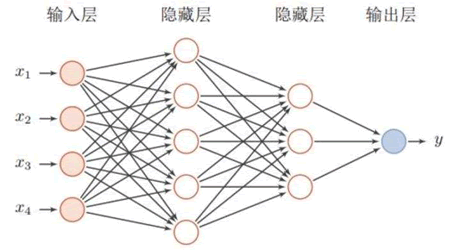
图8:全连接神经网络
多层感知器的诞生,解决了单层感知器模型无法解决的异或问题。下面简单分析一下解决过程。如图所示是包含了一个隐藏层的多层感知器模型:
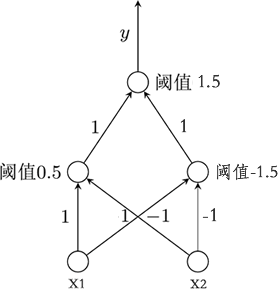
图8:多层感知器解决异或问题
在多层感知器模型中,隐藏层中的每一个节点都是想当于一个感知器模型。下面将输入值(x1 和 x2)带入隐藏层节点,可得以下函数式(这里的函数指的是激活函数):
左隐藏层节点:f1(x1+x2-0.5)
右隐藏层节点:f2(-x1-x2+1.5)
由此可知输出层的函数式如下:
f3(f1+f2-1.5)
根据异或法则“同为 0,异为 1”,分别将 (0,1),(1,0),(0,0),(1,1) 带入上述三个函数分别进行计算,可得以下结果(正数为 1,负数为 0):
(0,1):f1(0+1-0.5)=1 f2(0-1+1.5)=1 --> f3(1+1-1.5)=1
(1,0):f1(1+0-0.5)=1 f2(-1-0+1.5)=1 --> f3(1+1-1.5)=1
(0,0):f1(0+0-0.5)=0 f2(0-0+1.5)=1 --> f3(0+1-1.5)=0
(1,1):f1(1+1-0.5)=1 f2(-1-1+1.5)=0 --> f3(1+0-1.5)=0
可以看出输出层 f3 函数的结果完全符合异或运算法则,因此多层感知器可以解决“异或问题”。从函数图像上来看,多层感知器使用两条直线解决了线性不可分问题:
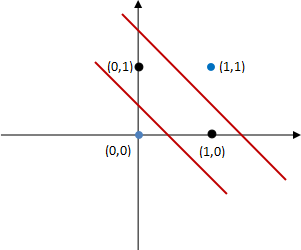
图9:分类区域
上图所示,位于红色直线之间的属于正类,而位于区域之外则属于负类。当然图像中只是包含了四个点而已,若是复杂的数据则可以选择不同的激活函数,比如 sigmoid 函数等。
3、反向传播算法
多层感知器的虽然解决了线性不可分问题,但随着隐藏层网络的加深,多层网络的训练和参数计算也越来越困难,因此多层感知器也显得“食之无味”。简单来说,就是当时的人们还不知道应该怎么训练多层神经网络,甚至不相信多层神经网络也是同样能被训练的。
直到 1986 年,深度学习教父 Hinton 等人对反向传播算法(Backpropagation algorithm,即误差逆向传播算法,简称 BP算法)进行了重新描述,证明了该算法可以解决网络层数过深导致的参数计算困难和误差传递等问题。
反向传播算法是一种用于训练神经网络的有监督学习算法,基于梯度下降(gradient descent)策略,以目标的负梯度方向对参数进行调整。但受限于当时(20世纪80年代)计算机算力不足等因素的影响,BP 算法只能以简单低效的方式来解决少数层神经网络训练问题,但即使如此,也已经弥足珍贵。
BP 算法的出现再次引发了 AI 研究的热潮,它是一款非常成功的神经网络算法,直到今天,该算法仍在深度学习领域发挥着重要的作用(用于训练多层神经网络)。
4、总结
经过几十年的发展,到目前为止,人工神经网络的发展进入了深度学习阶段,在这一阶段提出了许多新的神经网络模型,比如循环神经网络、卷积神经网络、生成对抗网络、深度信念网络等等。同时,深度学习又为人工神经网络引入了新的“部件”,比如卷积层、池化层等。
如今深度学习已非“人工神经网络”一词所能完全替代,可谓是“青出于蓝,而胜于蓝”,它已发展出一整套复杂的知识体系,哪怕只进行概要性地介绍也都会花费大量的篇幅,因此这里不做重点讨论。
纵观人工神经网络的发展历程,从生物神经元起源,再到多层感知器模型,历经三起两落,终于成为机器学习算法中的佼佼者。理解人工神经网络的发展历程,同时掌握各个模型的核心思想,对于后续知识的学习非常重要。
三十、神经网络分类算法原理详解
通过《二十九、人工神经网络是什么》一节,我们了解了神经网络的发展历程,同时掌握了人工神经网络的基本结构。在本节将主要围绕“反向传播算法”对人工神经网络的分类原理进行讲解。
在神经网络算法还没流行前,机器学习领域最受关注的算法是“支持向量机算法(即 SVM 算法)”,如今神经网络方兴未艾,您也许会好奇,神经网络各层的原理和结构都高度相似,为什么要堆叠这么多的神经网络层呢?就好比为什么单层感知器模型不能解决异或问题,但只要加上隐藏层就能解决呢?到底是谁赋予了神经网络如此奇妙的魔力。
一般来说,神经网络的层数越多,网络模型的学习能力就越强,就越能拟合复杂的数据分布。但这只是一种理想状态,因为随着网络的加深,也会带来其他问题,比如计算的难度也会增加,同时模型理解起来也比较晦涩。因此选择恰当的网络层数去解决适合的场景,这是神经网络算法中的难点。
1、神经网络工作流程
下面通过一个简单的示例来理解神经网络究竟是如何工作的:

图1:人工神经网络模型
如图 1 所示, A、B、C、D 是四位盲人,他们要玩“盲人摸象”的游戏。在数据集中有以下四个动物:大象、野猪、犀牛、麋鹿。四个人中 A、B、C 负责去摸动物(即动物特征),D 负责汇总分析 A、B、C 传递给他的信息,同时还会有人告诉 D,这一轮他们摸到是什么动物。此外,规定只有当 A、B、C 三个人摸到一下三个特征的时候向 D 汇报:
特征一:像一根柱子(腿部)
特征二:像一把蒲扇(耳朵)
特征三:像一条鞭子(尾巴)
注意,游戏在理想状态下进行的,不考虑其他外界因素。下面按照有监督学习的流程,先训练再预测。摸动物的过程,其实就是获取动物部位特征的过程,因为有 4 只动物,因此此处需要轮询 4 次,下面是四轮完成后 D 汇总的信息,如下所示:
第一次,大象:
A:像一根柱子(腿部)
B:像一把蒲扇(耳朵)
C:像一条鞭子(尾巴)
第二次,野猪:
B:像一把蒲扇
C:像一条鞭子
第三次,犀牛:
A:像一把蒲扇
C:像一条鞭子
第四次,麋鹿:
C:像一条鞭子
通过对上述汇总信息的分析,D 认为,C 汇报的最没有价值(即权重小),因为无论是不是大象,他所汇报的内容都是一样的。D 认为,相比之下,A 和 B 的报告更有价值(权重大),但各自汇报也会有错误的时候。经过 D 研究发现,只要将 A 和 B信息进行汇总,当两人同时说摸到【柱子和蒲扇】时,那么被摸的动物就是大象,这样即便是盲人也能通过精诚团结摸出大象来。
对于上述示例来说,A/B/C/D 其实构成了一个简单的神经网络模型,它们就想当于四个神经元,A/B/C 负责去“摸”,也就是汇总不同维度的输入数据,构成了神经网络的输入层。当它们三个人获取数据后都会告诉 D,通过 D 汇总分析,给出最终预测结果,即判断是不是大象,这相当于神经网络的输出层。神经网络能够把分散的信息进行汇总,从而提取出最有价值、权威的信息。若只是将网络中的一个独立节点拎出来都是以偏概全,比如 C 认为尾巴像鞭子的都是大象,这显然不合理的。
神经网络通过赋予输入信息不同的权重值来区别不同信息的重要程度。在模型训练过程中通过调节线性函数的相应权值,增加有价值信息的输入权值,降低其他价值信息较低的输入权值,这是【调优权值】的核心思想,通过上述方法能够提高网络模型预测的预测准确率。
神经元节点的个数和层数越多,神经网络的表达能力就越强,或者说拟合数据的能力就越强,这也是神经网络算法与其他机器学习学习算法相比,为什么适合处理图像识别、语音识别等复杂任务的根本原因。
2、反向传播算法
在神经网络模型中有两个重要部件,分别是:激活函数和反向传播 BP 算法,关于激活函数的相关概念,在《二十九、人工神经网络是什么》一节已经做了相关介绍,那到底什么是反向传播算法呢?在讲解反向传播之前,有必要先了解一下正向传播的概念。
我们知道,人工神经网络是由一个个的神经元节点构成的,这些节点的作用就是负责接受和传导信息,如同大脑神经元一样,接受外接刺激,传递兴奋信号。
在一个人工神经网络模型中,从输入层开始,传递到输出层,最后返回结果,这种信号传播方式被称为“正向传播”(或称前向运算、前向传播)。在神经网络模型中,若输入一层层的传递下去的,直到输出层产生输出,正向传播就结束了。
反向传播的与前向传播类似,但由于传播方向相反,因此被称为反向传播算法(简称 BP 算法),该算法最早出现在 20 世纪 60 年代,但当时并没有引起重视,直到 1986 年经 Hinton 等人进行了重新描述,才再次进入大众的视野。该算法成功解决了少数层神经网络【权值参数】计算的问题。
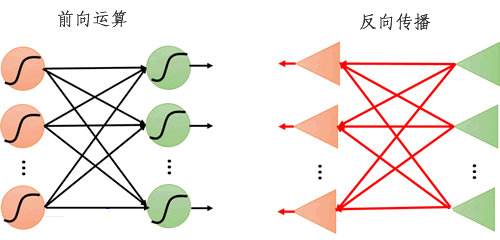
图2:前向运算和反向传播示意图
(1) 反向传播原理
反向传播算法(BP)是一种有监督学习算法,即通过有标记的训练数据来学习,它是训练人工神经网络模型的常用方法之一。简单的来说,BP 算法就是从错误中学习,直至将错误程度降到最低时结束,从而提高模型的可靠性。
BP 算法的学习过程由正向传播过程和反向传播过程两部分组成。在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层,如果输出值与标记值存在误差,则将误差由输出层经隐藏层向输入层传播(即反向传播),并在这个过程中利用梯度下降算法对神经元的各个权值参数进行调优,当误差达到最小时,网络模型训练结束,也即反向传播结束。流程图如下所示:
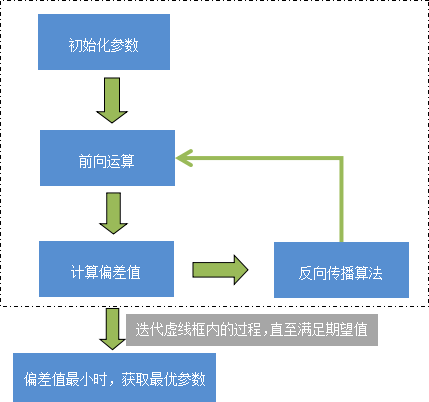
图3:神经网络模型训练
对上述过程进行总结:输入层接受一个输入数据 x,同时初始化一个权重参数 ω,通过隐藏层计算之后,由输出层输出结果,前向运算完成。之后,将输出层结果与标记值进行比较,获取偏差值,将此偏差值由输出层向输入层传播(反向传播阶段),这个阶段利用梯度下降算法对权值参数进行反复调优,当偏差值最小时,获得一组最优的权值参数(ω)。
(2) 应用示例
现有如下神经网络模型,由三层组成,分别是输入层,隐藏层,输出层,并以 Sigmoid 函数为神经网络的激活函数。下面看看反向传播算法是如何运算的,又是如何实现参数调优的。
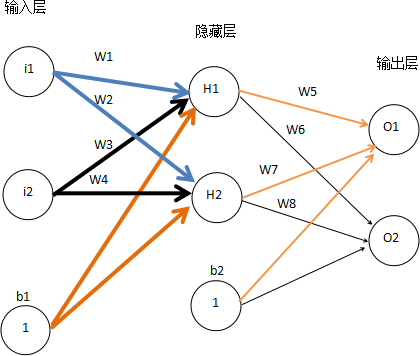
图4:神经网络模型
首先对网络模型的数据做一下简单说明:
输入层:i1=0.05,i2 = 0.1
初始化权值参数:w1=0.15,w2=0.2,w3=0.25,w4=0.3,w5=0.4,w6=0.45,w7=0.5,w8=0.55
输出层标记值(即期望值):o1=0.01,o2=0.99
偏置项权重值:b1=0.35,b2=0.6
下面使用反向传播算法使真实输出与标记值尽可能地接近,即真实值与标记值的偏差值最小。按照上述流程我们一步步进行计算。
前向运算阶段:输入层 --> 隐藏层 -->输出层,计算神经元 H1 的权值加和:
![]()
将初始化数据带入上述公式,可得以下结果:
![]()
隐藏层神经元的 H1 的输出结果,注意此结果需要经过激活函数映射:
![]()
同理依照上述方法可以计算出 H2 神经元输出,其结果如下:
![]()
下面计算输出层 O1 真实输出结果,如下所示:
![]()
将数据带入上述公式,经过激活函数映射,求得输出层 O1 的结果:

同理,按照上述方法可以计算出 O2 真实的输出结果:
![]()
通过上述运算可以得出:输出的实际结果与标记值相差甚远,计算结果是 [0.75136507,0.772928465],而实际上标记值是 [0.01,0.99]。 接下来使用反向传播算法,迭代更新权值,重新计算输出。
反向传播阶段,输出层 --> 隐藏层 --> 输入层,首先使用 MSE 均方误差公式计算总误差:

注意:MSE 是一种衡量“平均误差”较为方便的方法,MSE 可以评价数据的变化程度,MSE 的值越小,说明预测模型的泛化能力越好。
经上述计算求出了总误差(Etotal),这个值是由神经网络中所有节点“共同”组成的。因此就要计算每个神经元节点到底“贡献”了多少偏差值,这是反向传播算法要解决的核心问题,当然解决方法也很简单,即求偏导数,比如求 A 节点贡献了多少损失值,我们就对该节点求偏导数即可。
我们以 w5 为例对其进行调整,要知道 w5 对于整体误差到底产生多少影响,这里采用链式法则求偏导数,如下所示:
![]()
要想求得 w5 的偏导数,需要对另外三部分别求偏导数,如下所示:
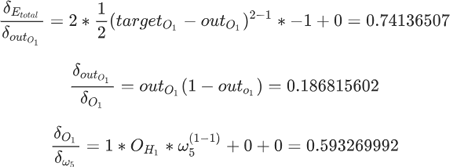
将上述三部分的结果相乘就可以得到 w5 的偏导数,其结果值为 0.082167041。最后使用梯度下降算法更新 w5 参数值,如下所示:
![]()
注意: η 是梯度下降算法中的学习率,此处取值 0.5,在前面讲解梯度下降算法时已经做了相关介绍,参考《七、梯度下降求极值》一节。
这样就完成了 w5 权值更新,同理,依照上述方法可以完成 w6、w7、w8 更新。
上述过程只是输出层向隐藏层传播,当计算出更新的权值后,开始由隐藏层向输入层传播,并依次更新 w1、w2、w3、w4,这样就完成了第一轮的权值更新。可以看出,通过第一轮权值更新后,总误差由 0.298371109 下降至 0.291027924,在迭代 10000 次后,总误差为 0.000035085,输出值为 [0.015912196, 0.984065734],已经非常逼近期望值 [0.01, 0.99]。
3、总结
神经网络分类算法是一种有监督学习算法,使用神经网络分类算法,大致需要以下五步:
- 初始化神经网络中所有神经元节点的权值;
- 输入层接收输入,通过正向传播产生输出;
- 根据输出的预测值,结合实际值计算偏差;
- 输出层接收偏差,通过反向传播机制(逆向反推)让所有神经元更新权值;
- 从第 2 步到第 4 步是一次完整的训练模型的过程,重复该过程,直到偏差值最小。
神经网络算法通过反向传播机制让所有神经元实现了权值更新,当我们不断迭代上述训练过程,直到偏差值最小,最终就会得到一个最优的网络模型,实现了对数据的最佳拟合。
三十一、神经网络分类算法的应用及其实现
在深度学习大热的当下,神经网络算法是最知名、应用最为广泛的机器学习算法。可以毫不夸张地说,你所能接触到的人工智能产品,绝大部分都使用了神经网络算法,比如手机经常用到的刷脸解锁、美颜修图、照片中的人物识别等,都是基于神经网络分类算法实现的。
1、神经网络算法特点
我们知道,深度学习的本质就是神经网络算法(深度学习是神经网络算法的一个分支)。理论上来说,在数据量和隐藏层足够多的情况下,神经网络算法能够拟合任何方程(函数)。神经网络算法是一种具有网络结构的算法模型,这决定了它具有非常好的延展性,通过调节神经网络中各个节点的权值参数使得分类效果明显提升。总的来说,神经网络算法具有以下特点:
(1) 黑盒算法
神经网络算法,也被称为“黑盒算法”,这是因为人们无法从外部得知神经网络模型究竟是如何完成训练的,比如使用一个预测准确率为 97% 的猫脸识别模型,有时会将小狗的脸部照片归纳到小猫中,而这种情况是无法解释的,因此神经网络算法又被人们形象地称之为“黑盒算法”。

图1:黑盒算法
由于神经网络算法的这一特性,导致一些场景并不适合使用神经网络算法,比如银行不会使用神经网络算法来评判用户的是否具备信用,因为一旦出现预测错误,银行根本无法溯源找到评判错误的原因,也就无法向客户做出合理的解释。
(2) 数据量
在互联网并不发达的七八十年代,数据量不足是阻碍神经网络发展的一大因素。与传统的机器学习算法相比,要想训练一个优秀的神经网络模型,往往需要更多的数据(至少需要数千甚至数百万个标记样本)。
比如人脸识别,需要各种姿态样式的人脸,发怒的、喜悦的、悲伤的、戴眼镜的、模糊的等等,总之越多越好。海量数据集对于训练一个优秀的神经网络模型非常重要,神经网络获得数据越多,表现能力就越好,这样训练出来的模型才具有更好的泛化能力。
注意:经过长达几十年的积累,直到目前,已经有大量的公开数据集可以使用,比如 Kaggle 数据集、Amazon 数据集、UCI 机器学习资源库、微软数据集等等。
(3) 算力和开发成本高
在计算方面,比传统算法下相比,神经网络算法要耗费更多的计算机资源,对于复杂的深度学习模型来说,若想训练出一个优秀的模型,甚至需要几周的时间。但以 20 世纪七八十年代的计算机硬件水平,想要实现如此大规模的计算,几乎是不可能的。因此计算机的硬件性能也是影响神经网络发展的因素之一。
进入 21 世纪以后,计算机的硬件性能获得了飞速发展,这为神经网络的发展创造了有利的外部环境。
2017 年 5 月,围棋高手 AlphaGo 机器人,从空白状态学起,自我训练 3 天,对弈 490 万次,便打败了人类第一围棋高手柯洁。AlphaGo Zero 作为 AlphaGo 的进阶版,它自我训练 40 天,对弈 2900 万次,最终以 100:0 的战绩,打败了它的前辈 AlphaGo 机器人。而这些数据的背后,是强大算力作为支撑。
同时神经网络模型搭建过程较为复杂,激活函数的选择,权值的调节,都是一个比较费时的过程,因此其开发周期相对较长。总之,神经网络算法是一种成本较高的算法,这也决定了它能够解决比传统机器学习算法更为复杂的问题。下表对神经网络的特点做了简单的总结:
| 项目 | 说明 |
|---|---|
| 优点 | 网络结构延展性好,能够拟合复杂的数据分布,比如非线性函数,通过调节权值参数来获取泛化能力较强的模型。 |
| 缺点 | 可解释性差,调参依赖于经验,可能会陷入局部最优解,或者梯度消失、梯度爆炸等问题。 |
| 应用领域 | 神经网络算法拟合能力强,应用领域广,比如文本分类等,而深度学习作为神经网络的分支,也是当前最为热门研究方向,在图像处理、语言识别和自然语言处理等多个领域都有着非常突出的表现。 |
2、神经网络算法应用
讲了这么多有关神将网络的相关知识,一切的都是为了解决实际的问题,那应该如何在编程中使用它呢?Python 机器学习 Sklearn 库提供了多层感知器算法(Multilayer Perceptron,即 MLP),也就是我们所说的神经网络算法,它被封装在 sklearn.neural_network 包中,该包提供了三个神经网络算法 API,分别是:
- neural_network.BernoulliRBM,伯努利受限玻尔兹曼机算法,无监督学习算法;
- neural_network.MLPClassifier,神经网络分类算法,用于解决分类问题;
- neural_network.MLPRgression,神经网络回归算法,用于解决回归问题。
下面使用神经网络分类算法解决鸢尾花的分类问题。在这之前有必要先了解 neural_network.MLPClassifier 分类器常用参数,如下所示:
| 名称 | 说明 |
|---|---|
| hidden_layer_sizes | 元组或列表参数,序列内元素的数量表示有多少个隐藏层,每个元素的数值表示该层有多少个神经元节点,比如(10,10),表示两个隐藏层,每层10个神经元节点。 |
| activation | 隐藏层激活函数,参数值有 identity、logistic、tanh、relu,默认为 'relu' 即线性整流函数(校正非线性) |
| solver | 权重优化算法,lbfgs、sgd、adam,其中 lbfg 鲁棒性较好,但在大型模型或者大型数据集上花费的调优时间会较长,adam 大多数效果都不错,但对数据的缩放相当敏感,sgd 则不常用 |
| alpha | L2 正则项参数,比如 alpha = 0.0001(弱正则化) |
| learning_rate | 学习率,参数值 constant、invscaling、adaptive |
| learning_rate_init | 初始学习率,只有当 solver 为 sgd 或 adam 时才使用。 |
| max_iter | 最大迭代次数 |
| shuffle | 是否在每次迭代时对样本进行清洗,当 solver 参数值为 sgd 或 adam 时才使用该参数值 |
| random_state | 随机数种子 |
| tol | 优化算法中止的条件,当迭代先后的函数差值小于等于 tol 时就中止 |
Iris 鸢尾花数据集内包含 3 个类别,分别是山鸢花(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)共150 条记录,每一个类别有 50 条数据,每条记录有 4 项特征(单位为厘米):
- sepallength:萼片长度
- sepalwidth:萼片宽度
- petallength:花瓣长度
- petalwidth:花瓣宽度
我们选取两个类别(0 和 1,即山鸢尾花和变色鸢尾花)的样本标记值和两个特征属性('sepal length (cm)', 'petal length (cm)'),之后使用神经网络分类算法对数据集中的 0 和 1 两类鸢尾花进行正确分类。代码如下所示:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifierdef main():iris = datasets.load_iris() # 加载鸢尾花数据集# 用pandas处理数据集data = pd.DataFrame(iris.data, columns=iris.feature_names)print(iris.feature_names)#数据集标记值 iris.targetdata['class'] = iris.target# 此处只取两类 0/1 两个类别的鸢尾花,设置类别不等于 2data = data[data['class'] != 2]# 对数据集进行归一化和标准化处理scaler = StandardScaler()# 选择两个特征值(属性)X = data[['sepal length (cm)', 'petal length (cm)']]#计算均值和标准差scaler.fit(X)# 标准化数据集(数据转化)X = scaler.transform(X)# 'class'为列标签,读取100个样本的的列表Y = data[['class']]# 划分数据集X_train, X_test, Y_train, Y_test = train_test_split(X, Y)# 创建神经网络分类器mpl = MLPClassifier(solver='lbfgs', activation='logistic')# 训练神经网络模型mpl.fit(X_train, Y_train)# 打印模型预测评分print('Score:\n', mpl.score(X_test, Y_test))# 划分网格区域h = 0.02x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))Z = mpl.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)#画三维等高线图,并对轮廓线进行填充plt.contourf(xx, yy, Z,cmap='summer')# 绘制散点图class1_x = X[Y['class'] == 0, 0]class1_y = X[Y['class'] == 0, 1]l1 = plt.scatter(class1_x, class1_y, color='b', label=iris.target_names[0])class2_x = X[Y['class'] == 1, 0]class2_y = X[Y['class'] == 1, 1]l2 = plt.scatter(class2_x, class2_y, color='r', label=iris.target_names[1])plt.legend(handles=[l1, l2], loc='best')plt.grid(True)plt.show()main()模型评分为 1.0,即模型预测正确率为 100%,输出效果图如下:
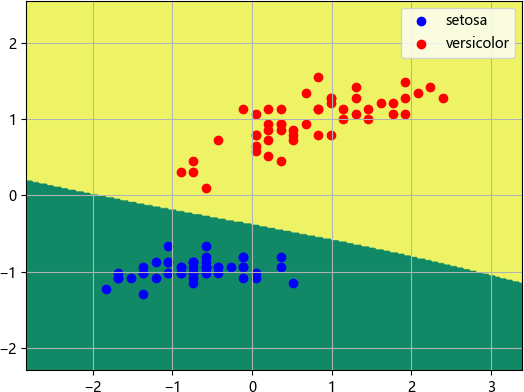
图2:分类效果图
以上就是神经网络算法的实际应用,可以看出神经网络虽然复杂,但训练出的模型预测正确率高,这是传统的机器学习算法所不能相比的。神经网络算法适合处理大规模的数据分析任务,不管是分类还是回归任务,都有着十分优秀的表现力。
三十二、什么是集成学习算法
经过前面的学习,我们认识了机器学习中的常用回归算法、分类算法和聚类算法,在众多的算法中,除神经网络算法之外,没有一款算法模型预测准确率达到 100%,因此如何提高预测模型的准确率成为业界研究的重点。通过前面内容的学习,你可能会迅速想到一些方法,比如选择一款适合的算法,然后反复调整各种参数,其实这并不是最佳的方法,有以下三点原因:
- 一是任何算法模型都有自身的局限性;
- 二是反复调参会浪费许多不必要的时间;
- 三是依靠调参来提升模型预测准确率具有很大的不确定性。
那到底有没有一种适合的方法呢?当然有,它就是本节要介绍的主角——集成学习方法(Ensemble Method),或称集成学习算法。
准确来讲,集成学习算法并非一种机器学习算法,它更像是一种模型优化方法,是一种能在各种机器学习任务上提高准确率的强有力技术,这种技术的关键体现在“集成”两个字上,所谓集成就是“捏在一起”,因此集成学习算法可以理解成是一套组合了多种机器学习算法模型的框架,它关注的是框架内各个模型之间的组织关系,而非某个模型的具体内部结构。
可以说集成学习算法是“集”百家之长,使预测模型获得较高准确率,当然这也导致了模型的训练过程会稍加复杂,效率降低了一些,但在硬件性能发达的今天,几乎可以忽略不计。
当下深度学习大行其道,将任何一款传统机器学习算法单拎出来与之一较高下,几乎都会败下阵来,而集成学习算法的出现打破了这个平衡,它几乎能与深度学习平分秋色。在 Kaggle、天池等著名机器学习竞赛中,选手使用最多当属集成学习算法,而非 SVM、KNN 或者 Logistic 逻辑回归等单个算法,由此可见集成学习算法具有更广泛的适应场景,比如分类问题、回归问题、特征选取和异常点检测等各类机器学习任务。
1、集成学习发展史
集成学习算法的理论、应用体系的构建与完善经历一个漫长的过程,下面进行简单地介绍。
集成学习最早出现于 1979 年,Dasarathy 提出了集成系统(Ensemble system) 的思想,他使用线性分类器和最近邻居分类器组成的复合模型进行训练,得到了比单个分类器训练更好的预测效果。
1988 年 Kearns 提出了“弱学习器”概念,引发了“能否用一组弱学习器创造一个强学习器”的广泛讨论。(学习器,指的是某种机器学习算法模型),注意,所谓弱学习器,指的是一个个单独的算法模型,比如 KNN 算法模型、线性回归模型、朴素贝叶斯等,而强学习器指的是由多个不同类别的“弱学习器”集成的学习器,也称“异质集成”,这类学习器的预测准确率在 90% 以上。除此之外,还有一种“基学习器”(也称同质集成),它是由同一款机器学习算法组成的。
1990 年 Schapire 对这问题给出了答案,并且研发了著名的 Boosting 算法,该算法是集成学习常用方法之一;1992 年 Wolpert 首次提出“堆叠泛化”这一概念,即“堆叠”弱学习器训练的模型比任何单个弱学习器训练的模型具有更好的性能。
1996年,Breiman 开发了另一个集成学习方法 —— Bagging 算法(也称装袋算法),并对其原理和训练过程进行了详细的描述,并明确指出 Bagging 算法能够提高预测的准确性。其后几年,Breiman 在 Bagging 算法的基础上对“随机决策森林”进行另外重新描述,提出了集成学习中最广为人知的算法 —— 随机森林算法(RandomForest),该算法通过集成学习的思想将多棵“决策树”集成为一片“森林”,使其兼顾了解决回归问题和分类问题的能力。
截止到目前,已经有越来越多的集成学习算法被提出,比如 2010 年 Kalal 等人提出的 P-N 学习,以及近几年提出的以堆叠方式构建的深度网络结构、XGBoost 等算法,它们都能显著提升模型的预测效果。
2、集成学习组织方式
集成学习不是一种独立的机器学习算法,而是把互相没有关联的机器学习算法“集成”在一起,从而取得更好的效果。我们知道,每个算法模型都有各自的局限性,集成学习方式的出现正好弥补了这一不足之处,其实就算是大神也有“折戟沉沙”的时候,但人多力量大,多找几个大神凑在一起,就算遇到难题,最终也能比较好的解决。
前面,我们介绍的机器算法都是“个人”的单打独斗,而集成学习是“团队协作”,大家可以集思广益。这种方式固然好,但是如果没有统一的协调,也很容易出现问题,比如一个开发团队遇到问题时,总能通过相互沟通很快地推举出一个擅长解决该问题的人。但机器学习算法是无法使用语言来沟通的,那怎样才能使集成学习发挥出团队威力呢?这就要通过集成学习的组织结构来解决这一问题。
总的来说,集成学习算法主要使用两种结构来管理模型与模型之间的关系,一种是并联,另一种是串联(这和物理上串联电路、并联电路似乎有些相似之处)。下面对这两种方式进行简单介绍(其实很好理解)。
(1) 并联组织关系
所谓并联,就是训练过程是并行的,几个学习器相对独立地完成预测工作,彼此互不干扰,当所有模型预测结束后,最终以某种方法把所有预测结果合在一起。这相当于学生拿到试卷后先分别作答,彼此不讨论、不参考,当考试完成后,再以某种方式把答案整合在一起。并行式集成学习的典型代表是 Bagging 算法。并行结构示意图如下所示:
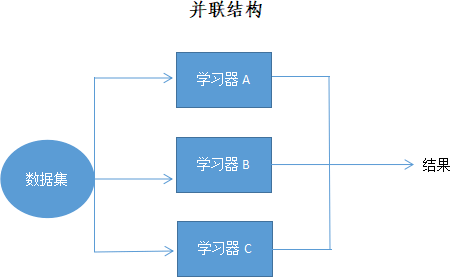
图1:集成学习并联结构
(2) 串联组织关系
串联结构也很好理解,指的是训练过程是串行的,几个学习器串在一起,通力合作一起来完成预测任务。第一个学习器拿到数据集完成预测,然后把预测结果以及相关数据传递给第二个学习器,第二个学习器也是在完成预测后把结果和相关数据继续传递下去,直至传递到最后一个学习器,这个过程很像是传声筒游戏,第一个人先听一段旋律,然后复述给第二个队员,依次进行下去,直到最后一个人给出歌曲的名字。串行式集成学习的典型代表是 Boosting 算法。串行结构示意图如下所示:

图2:集成学习串联结构
注意:串联与并联的最大区别在于,并联的学习器彼此独立,而串联则是把预测结果传递给后面的学习器。
串联和并联各有各的优势,那么我们到底该如何选择呢?其实,如果各个学习器势均力敌,分不出主次优劣,在这种情况下建议选择并联结构;如果学习器已经有了明确的分工,知道谁负责主攻,谁负责辅助,则可以使用串联结构。
3、预测结果的方式
不管是串联结构,亦或是并联结构,最终都要输出一个预测结果,而在一个组织结构会有多个学习器,因此就会产生多个预测结果,那么我们要怎么将这些结果整合成一个结果对外输出呢,也就是使用什么方式来整合每个学习器的输出结果呢。对于集成学习算法来说,把多个结果整合成一个结果的方法主要有两种,分别是平均法和投票法,下面分别对它们进行介绍。
(1) 平均法
平均法,又分为简单平均法和加权平均法,简单平均法就是先求和然后再求均值,而加权平均则多了一步,即每个学习器通过训练被分别赋予合适的权值,然后求各个预测结果的加权和,最后再求均值。
(2) 投票法
投票法,具体分为三种:简单多数投票法、绝对多数投票法和加权投票法。
简单多数投票法就是哪个预测结果占大多数,就把这个结果就作为最终的预测结果。
绝对多数投票法就多了一个限制,这个“多数”必须达到半数,比如有共有 6 个学习器,得出同一预测结果的必须达到 3 个及以上,否则就拒绝进行预测。下面重点理解一下加权投票法。
加权投票法,有点类似加权平均,首先给不同的学习器分配权值,其次是查看哪个结果占大多数,注意,此处有一点儿不同,这里的“大多数”是权值相加后再比较得到的大多数,最后以得票最多的作为预测结果。
关于加权投票法举一个简单的例子,比如预测结果为 A 的有 3 个学习器,权值分别为 0.1、0.2 和 0.3,那么结果 A 的票数就为三者之和,即 0.6,而预测结果为 B 的只有 2 个学习器,但权值分别为 0.4 和 0.5,那么结果 B 的票数就为 0.9,也就是结果 B 的票数高于结果 A,最终预测结果就是结果 B。
4、集成学习实现方法
根据个体学习器生成方式的不同,目前集成学习的实现方式主要分为两种,一种是 Bagging 算法为代表的并行式集成学习方法,其中最典型的应用当数“随机森林算法”;另一种是以 Boosting 算法为代表的串行式集成学习方法,其中应用频率较高的有两个 AdaBoost 算法和 XGBoost 算法。除上述两种主要的方法外,还有一种 Stacking 分层模型集成学习算法。
(1)Bagging算法 (并行式集成学习方法)
Bagging 算法又称为“装袋算法”最初由 Leo Breiman 于 1996 年提出,它是并行式学习的典型代表,该算法主要是从数据层面上进行设计。并联结构中的每个学习器所使用的数据集均采用放回重采样的方式生成,也就是说,每个学习器生成训练集时,每个数据样本都有相同的被采样概率。训练完成后,Bagging 采用投票的方式进行预测。
通过放回重采样的方式来构建样本量相等、且相互独立的数据集,从而在同一算法中训练出不同的模型。Bagging 算法的集成策略比较简单,对于分类问题,一般通过投票法,以多数模型预测结果为最终结果;而对于回归问题,一般采用算术平均法,对所有模型的预测结果做算术平均得到最终结果。
(2) Boosting算法 (串行式集成学习方法)
与 Bagging 算法相比,Boosting 是一种串行式集成学习算法,该算法基于错误来提升模型的性能,根据前面分类器分类错误的样本,调整训练集中各个样本的权重来重新构建分类器。
Boosting 可以组合多个弱学习器来形成一个强学习器,从而在整体上提高模型预测的准确率。在模型训练过程中,Boosting 算法总是更加关注被错误分类的样本,首先对于第一个弱学习器预测发生错误的数据,在后续训练中提高其权值,而正确预测的数据则降低其权值,然后基于调整权值后的训练集来训练第二个学习器,如此重复进行,直到训练完成所有学习器,最终将所有弱学习器通过集成策略进行整合(比如加权法),生成一个强学习器。
Boosting 算法的训练过程是呈阶梯状的,后一个学习器会在前一个学习器的基础上进行学习,最终以某种方式进行综合,比如加权法,对所有模型的预测结果进行加权来产生最终的结果。
(3) Stacking算法 (分层模型集成学习算法)
相比于前两种算法,Stacking 集成学习算法要更为复杂一些,该算法是一种分层模型框架,由 Wolpert 于1992 年提出。
Stacking 算法可以分为多层,但通常情况下分为两层,第一层还是由若干个弱学习器组成,当原始训练集经过第一层后,会输出各种弱学习器的预测值,然后将预测结果继续向下一层传递,第二层通常只有一个机器学习模型,该层对第一层的各种预测值和真实值进行训练,从而得到一个集成模型,该模型将根据第一层的预测结果,给出最终的预测结果。
集成学习思想在机器学习算法中应用广泛,它对于提升模型预测准确率,有着不可忽视的作用。如果大家对于集成学习感兴趣的话,可以自己花点时间研究一下,相信您一定会收获满满。
三十三、集成学习应用:随机森林算法(RF)
随机森林(Random Forest,简称RF)是通过集成学习的思想将多棵树集成的一种算法,它的基本单位是决策树模型,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。我们知道,集成学习的实现方法主要分为两大类,即 Bagging 和 boosting 算法,随机森林就是通过【Bagging 算法+决策树算法】实现的。前面已经学习过决策树算法,因此随机森林算法会很容易理解。
1、决策树和随机森林
下面对决策树算法做简单的回顾:决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
(1) 决策树
决策树选取了一个特征维度作为判别条件,在数据结构中通常称之为“根节点”,根节点通过 if-else 形成最初的分支,如果这时分类没有完成,刚刚形成的分支还需要继续形成分支,这就是决策树的第一个关键机制:节点分裂。在数据结构中,分支节点通常称为叶子节点,如果叶子节点再分裂形成节点,就称为子树。
叶子节点可能不断分类形成子树,正如 if-else 语句可以不断嵌套 if-else,利用这个机制,一次判别不能完全达到把数据集划分成正类和负类的效果,那就在判别结果中继续进行判别。决策树通过叶子节点不断分裂形成子树,或者说通过 if-else 不断嵌套 if-else,每一次分裂都相当于一次对分类结果的“提纯”,不断重复这个过程,最终就达到分类目标了。
决策树一般有 ID3、ID4.5、CART 这三种算法。其中最常用的是 CART 树(classification and regression tree,即分类回归树算法),它是一棵二分树,在每个节点做出决策时只能选择是或否。CART 树生成的主要思想就是分裂。每个准备分裂的节点,都会从数据集中选择一个最优特征的最优值作为分裂的条件,将数据分成两部分想要了解更多地了解决策树可点击前往《十七、决策树分类算法(if-else原理)》一节。
(2) 随机森林
随机森林,顾名思义,即使用随机的方式建立一个森林,这个森林由很多的决策树组成,并且每一棵决策树之间是相互独立的。
如果训练集有 M 个样本,对于每棵数而言,以随机且有放回的方式从训练集中抽取 N 个训练样本(N<M),作为该棵决策树的训练集。除了采用样本随机之外,随机森林还采用了特征随机。假设每个样本有 K 个特征,从所有特征中随机选取 k 个特征(k<=K),选择最佳分割属性作为节点建立 CART 决策树,重复该步骤,建立 m 棵 CART 树,这些树就组成了森林,这也是随机森林名字的由来。随机采样和随机特征选取在一定程度上避免了过拟合现象的发生。
当有一个新的输入样本进入森林时,就让森林中的每一棵决策树分别对其进行判断,看看这个样本应该属于哪一类(对于分类算法而言),然后使用少数服从多数的【投票法】,看看哪一类被选择最多,就预测该样本为哪一类。
举个形象化的例子:森林中召开动物大会,讨论某个动物是狼还是狗,每个树都要独立地发表对这个问题的看法,也就是每一棵树都要投票,并且只能投是或否。依据投票情况,最终得票数最多的类别就是对这只动物的认定结果。在这个过程中,森林中每棵数都是独立地对若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器。
随机森林既可以处理属性为离散值的样本(即分类问题),也可以处理属性为连续值的样本(即回归问题),另外随机森林还可以应用于无监督学习的聚类问题,以及异常点检测。
2、算法应用及其实现
作为一种新兴的、高度灵活的机器学习算法,随机森林(Random Forest,简称 RF)拥有广泛的应用前景,它在金融、医疗等行业大放异彩,比如银行预测借贷顾客的风险等级,医药行业可以采用随机森林算法来寻找正确的药品成分组合,同时该算法业也可以对病人的既往病史进行分析,这非常有助于确诊病人的疾病。
在 Scikit-Learn 机器学习库中提供了 Bagging 和 Boosting 两种集成学习方法,且都在 ensemble 类库下,包括随机森林算法。除此之外,该类库下还包含了其他几类算法,较为知名有如下几种:
| 说明 | |
|---|---|
| RandomForestClassifier类 | 使用随机森林(Random Forest)算法解决分类问题,随机森林可谓 Bagging 集成学习算法的典型代表,它选择以 CART 决策树算法作为弱学习器,是一种常用的机器学习算法。 |
| RandomForestRegressor类 | 使用随机森林算法解决回归问题 |
| ExtraTreesClassifier类 | 使用极端随机树(Extra Tree)算法解决分类问题,极端随机树算法可以看作随机森林算法的一种变种,主要原理非常类似,但在决策条件选择时采用了随机选择的策略。 |
| ExtraTreesRegressor类 | 使用极端随机树算法解决回归问题。 |
| AdaBoostRegressor类 | 使用AdaBoost算法解决分类问题,AdaBoost算法是最知名的Boosting算法之一。 |
| AdaBoostRegressor类 | 使用AdaBoost算法解决回归问题。 |
| GradientBoostingClassifier类 | 使用Gradient Boosting算法解决分类问题,Gradient Boosting算法常常搭配CART决策树算法使用,这就是有名的梯度提升树(Gradient Boosting Decision Tree,GBDT)算法。 |
| GradientBoostingRegressor类 | 使用Gradient Boosting算法解决回归问题。 |
Scikit-Learn 对于集成学习方法做了非常良好的封装,可以实现“开箱即用”,下面以随机森林算法为例进行演示:
from sklearn.datasets import load_iris
#从Scikit-Learn库导入集成学习模型的随机森林分类算法
from sklearn.ensemble import RandomForestClassifier
#载入鸢尾花数据集
X, y = load_iris(return_X_y=True)
#训练模型
#随机森林与决策树算法一样,其中有一个名为“criterion”的参数
#同样可以传入字符串“gini”或“entropy”,默认使用的是基尼指数
clf = RandomForestClassifier()
clf.fit(X, y)
print("模型预测准确率",clf.score(X, y))
#使用模型进行分类预测
print("预测结果:",clf.predict(X))输出结果如下所示:
模型预测准确率 1.0
预测结果: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
3、总结
随机森林算法是集成学习方法的典型代表,该算法具有以下特点:
- 模型准确率高:随机森林既可以处理分类问题,也可以处理回归问题,即使存在部分数据缺失的情况,随机森林也能保持很高的分类精度;
- 能够处理数量庞大的高维度的特征,且不需要进行降维(因为特征子集是随机选择的);
- 能够评估各个特征在分类问题上的重要性:可以生成树状结构,判断各个特征的重要性;
- 对异常值、缺失值不敏感。
当然随机森林算法也存在一些不足,比如:
- 随机森林解决回归问题的效果不如分类问题;
- 树之间的相关性越大,错误率就越大;
- 当训练数据噪声较大时,容易产生过拟合现象。
截止到目前,我们已经学习了机器学习中常用的回归算法、分类算法和聚类算法,相信通过这些知识点的学习,您对机器学习算法有了初步了解和掌握。每种算法各有千秋,在学习的时候,我们要更多的关注每种模型的原理、结构以及数学实现,只有在掌握了这些之后,我们才能提高自己认知能力,当遇到其他算法时,才能做到触类旁通、应对自如。