网络运维Day18
文章目录
- 环境准备
- 导入数据
- 确认表导入成功
- 练习用表解析
- 表格结构设计
- 查询语句进阶
- 什么是MySQL函数
- 常用功能函数
- 数学计算
- 流程控制函数
- 查询结果处理
- 连接查询(联表查询)
- 表关系
- 什么是连接查询
- 连接查询分类
- 笛卡尔积
- 内连接(INNER)
- 外连接
- 子查询
- 什么是子查询
- 子查询出现的位置
- 子查询练习
- 总结
环境准备
本节课实验需要一台CentOS7.9虚拟机(沿用上节课实验环境即可)
导入数据
- 将tarena.sql导入至mysql主机的/root
使用tarena.sql备份文件导入(还原)数据
[root@server51 ~]# mysql -uroot -p'tedu123...A' < /root/tarena.sql
确认表导入成功
#登录数据库
[root@mysql ~]# mysql -hlocalhost -uroot -p'tedu123...A'#确认数据已经导入
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| tarena |
+--------------------+
5 rows in set (0.00 sec)mysql> SHOW TABLES FROM tarena;
+------------------+
| Tables_in_tarena |
+------------------+
| departments |
| employees |
| salary |
| user |
+------------------+
4 rows in set (0.00 sec)mysql> USE tarena;
练习用表解析
#查看表结构
mysql> DESC tarena.departments;
+-----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+----------------+
| dept_id | int(4) | NO | PRI | NULL | auto_increment |
| dept_name | varchar(10) | YES | | NULL | |
+-----------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)mysql> DESC tarena.employees;
+--------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+----------------+
| employee_id | int(6) | NO | PRI | NULL | auto_increment |
| name | varchar(10) | YES | | NULL | |
| hire_date | date | YES | | NULL | |
| birth_date | date | YES | | NULL | |
| email | varchar(25) | YES | | NULL | |
| phone_number | char(11) | YES | | NULL | |
| dept_id | int(4) | YES | MUL | NULL | |
+--------------+-------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)mysql> DESC salary;
+-------------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| date | date | YES | | NULL | |
| employee_id | int(6) | YES | MUL | NULL | |
| basic | int(6) | YES | | NULL | |
| bonus | int(6) | YES | | NULL | |
+-------------+---------+------+-----+---------+----------------+
5 rows in set (0.00 sec)#确认表内有数据
mysql> SELECT * FROM tarena.departments; #查看部门表所有数据mysql> SELECT * FROM tarena.employees; #查看员工表所有数据mysql> SELECT * FROM tarena.salary; #查看工资表所有数据
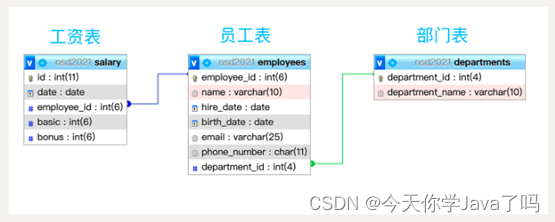
表格结构设计
- departments部门表:共8个部门
| 字段 | 类型 | 说明 |
|---|---|---|
| dept_id | INT(4) | 部门编号 |
| dept_name | VARCHAR(10) | 部门名称 |
- employees员工表:共133位员工隶属于不同部门
| 字段 | 类型 | 说明 |
|---|---|---|
| employee_id | INT(6) | 员工工号 |
| name | VARCHAR() | 姓名 |
| hire_data | DATE | 入职日期 |
| birth_date | DATE | 生日 |
| VARCHAR(25) | 邮箱 | |
| phone_number | CHAR(11) | 电话号码 |
| dept_id | INT(4) | 隶属部门编号 |
- salary工资表
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT(11) | 行号 |
| date | DATE | 发信日期 |
| employee_id | INT(6) | 员工工号 |
| basic | INT(6) | 基础工资 |
| bonus | INT(6) | 奖金 |
查询语句进阶
什么是MySQL函数
MySQL服务内部为实现某个功能而定义好的命令
MySQL函数格式:
- 函数()
MySQL函数用法:
- SELECT 函数();
- SELECT NOW();
- SELECT 函数(函数());
- SELECT YEAR(NOW());
- SELECT 函数(字段) FROM 库名.表名
- SELECT COUNT(*) FROM tarena.user;
常用功能函数
- 系统信息函数
#系统信息函数练习mysql> SELECT VERSION(); #显示当前数据库版本
+-----------+
| VERSION() |
+-----------+
| 5.7.17 |
+-----------+
1 row in set (0.00 sec)mysql> SELECT DATABASE(); #显示当前正在操作的库
+------------+
| DATABASE() |
+------------+
| tarena |
+------------+
1 row in set (0.00 sec)mysql> SELECT USER(); #显示当前登录数据库的用户
+----------------+
| USER() |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.00 sec)
- 聚集函数:用于统计,操作查询的结果
#聚集函数练习#avg(字段):计算平均值
mysql> SELECT AVG(uid) FROM tarena.user; #user表中uid的平均值#sum(字段):求和
mysql> SELECT SUM(uid) FROM tarena.user; #user表中uid的和#min(字段):获取最小值
mysql> SELECT MIN(uid) FROM tarena.user; #user表中uid最小的值#max(字段):获取最大值
mysql> SELECT MAX(uid) FROM tarena.user; #user表中uid最大的值#count(字段):统计表头值个数
mysql> SELECT COUNT(name) FROM tarena.user; #user表中用户数
mysql> SELECT COUNT(name) FROM tarena.user WHERE shell="/bin/bash"; #user表中使用/bin/bash解释器的用户数(带条件统计)
数学计算
#包括+、-、*、/、%操作
#SELECT可以直接运行计算表达式
#也可以对表内已有的数据进行运算#数学计算练习
mysql> SELECT * FROM tarena.salary WHERE employee_id=8; #查询8号员工的工资条mysql> SELECT * FROM tarena.salary -> WHERE-> employee_id=8 AND date='20201010'; #查询8号员工2020年10月的工资情况#计算8号员工2020年10月的总工资(总工资=基础工资+奖金)
mysql> SELECT -> date AS 发薪日期,-> employee_id AS 工号,-> basic AS 基础工资,-> bonus AS 奖金,-> basic+bonus AS 工资总额-> FROM-> tarena.salary-> WHERE -> employee_id=8 AND date='20201010'; #可以根据已有数据创建临时字段
+--------------+--------+--------------+--------+--------------+
| 发薪日期 | 工号 | 基础工资 | 奖金 | 工资总额 |
+--------------+--------+--------------+--------+--------------+
| 2020-10-10 | 8 | 24247 | 6000 | 30247 |
+--------------+--------+--------------+--------+--------------+mysql> SELECT * FROM tarena.employees-> WHERE-> employee_id%2=1; #查询工号是奇数的员工表记录
流程控制函数
- IF函数
#语法:IF(表达式,值1,值2)如果表达式为真,则返回值1,如果表达式为假,则返回值2#IF函数练习
mysql> SELECT IF(1>0,"true","false"); #表达式为真,返回true
+------------------------+
| IF(1>0,"true","false") |
+------------------------+
| true |
+------------------------+
1 row in set (0.00 sec)mysql> SELECT IF(1<0,"true","false"); #表达式为假,返回false
+------------------------+
| IF(1<0,"true","false") |
+------------------------+
| false |
+------------------------+
1 row in set (0.00 sec)#IF函数应用
mysql> SELECT name,uid,IF(uid<1000,"系统用户","普通用户") AS 用户类型-> FROM tarena.user; #根据uid大小来判断用户类型
- IFNULL函数
#语法:IFNULL(值1,值2)如果值1不为NULL(空)则返回值1,为NULL(空)则返回值2#IFNULL函数练习
mysql> SELECT IFNULL("hello","world"); #hello不为NULL,返回hello
+-------------------------+
| IFNULL("hello","world") |
+-------------------------+
| hello |
+-------------------------+
1 row in set (0.00 sec)mysql> SELECT IFNULL("","world"); #""不是NULL,是0个字符,返回0个字符
+--------------------+
| IFNULL("","world") |
+--------------------+
| |
+--------------------+
1 row in set (0.00 sec)mysql> SELECT IFNULL(NULL,"world"); #NULL是空,返回world
+----------------------+
| IFNULL(NULL,"world") |
+----------------------+
| world |
+----------------------+
1 row in set (0.00 sec)#IFNULL函数应用
mysql> SELECT -> name AS 用户名,-> IFNULL(homedir,"no homedir") AS 用户家目录-> FROM tarena.user; #查询user表中所有记录,如果homedir为空打印no homedir
- CASE语句
#语法:用于多分支判断如果字段名等于某个值,则返回对应位置then后面的值并结束判断如果与所有值都不相等,则返回else后面的结果并结束判断 语法1:CASE 字段名 WHEN 值1 THEN 结果 WHEN 值2 THEN 结果 WHEN 值3 THEN 结果 ELSE 结果 END语法2:CASE WHEN 判断条件 THEN 结果 WHEN 判断条件 THEN 结果 WHEN 判断条件 THEN 结果 ELSE 结果 END#CASE语句练习mysql> SELECT * FROM tarena.departments;
+---------+-----------+
| dept_id | dept_name |
+---------+-----------+
| 1 | 人事部 |
| 2 | 财务部 |
| 3 | 运维部 |
| 4 | 开发部 |
| 5 | 测试部 |
| 6 | 市场部 |
| 7 | 销售部 |
| 8 | 法务部 |
+---------+-----------+
8 rows in set (0.00 sec)#语法1练习
mysql> SELECT dept_id,dept_name, -> CASE dept_name -> WHEN "运维部" THEN "技术部门"-> WHEN "开发部" THEN "技术部门" -> WHEN "测试部" THEN "技术部门" -> ELSE "非技术部门" -> END AS "部门类型" -> FROM tarena.departments;
+---------+-----------+-----------------+
| dept_id | dept_name | 部门类型 |
+---------+-----------+-----------------+
| 1 | 人事部 | 非技术部门 |
| 2 | 财务部 | 非技术部门 |
| 3 | 运维部 | 技术部门 |
| 4 | 开发部 | 技术部门 |
| 5 | 测试部 | 技术部门 |
| 6 | 市场部 | 非技术部门 |
| 7 | 销售部 | 非技术部门 |
| 8 | 法务部 | 非技术部门 |
+---------+-----------+-----------------+
8 rows in set (0.00 sec)#语法2练习
mysql> SELECT dept_id,dept_name,-> CASE-> WHEN dept_name IN ("运维部","开发部","测试部") THEN "技术部门"-> WHEN dept_name IN ("市场部","销售部") THEN "营销部门"-> ELSE "职能部门"-> END AS "部门类型"-> FROM tarena.departments;
+---------+-----------+--------------+
| dept_id | dept_name | 部门类型 |
+---------+-----------+--------------+
| 1 | 人事部 | 职能部门 |
| 2 | 财务部 | 职能部门 |
| 3 | 运维部 | 技术部门 |
| 4 | 开发部 | 技术部门 |
| 5 | 测试部 | 技术部门 |
| 6 | 市场部 | 营销部门 |
| 7 | 销售部 | 营销部门 |
| 8 | 法务部 | 职能部门 |
+---------+-----------+--------------+
8 rows in set (0.00 sec)
查询结果处理
即对于SELECT语句从表中查询到的数据进行二次处理
语法:
SELECT 字段列表 FROM 库名.表名 WHERE 筛选条件 [分组|排序|过滤|分页];
- 分组(GROUP BY)
#分组语法SELECT 字段列表 FROM 库名.表名 [WHERE 筛选条件] GROUP BY 分组字段;除分组字段外其他字段需配合聚集函数使用#分组练习
mysql> SELECT COUNT(name),shell FROM tarena.user -> GROUP BY shell; #查询user表中使用各种解释器的用户数量
+-------------+----------------+
| COUNT(name) | shell |
+-------------+----------------+
| 3 | NULL |
| 2 | /bin/bash |
| 1 | /bin/false |
| 1 | /bin/sync |
| 1 | /sbin/halt |
| 20 | /sbin/nologin |
| 1 | /sbin/shutdown |
+-------------+----------------+
7 rows in set (0.00 sec)mysql> SELECT dept_id,COUNT(name) FROM tarena.employees -> GROUP BY dept_id; #查询employees表中不同部门的人数
+---------+-------------+
| dept_id | COUNT(name) |
+---------+-------------+
| 1 | 8 |
| 2 | 5 |
| 3 | 6 |
| 4 | 55 |
| 5 | 12 |
| 6 | 9 |
| 7 | 35 |
| 8 | 3 |
+---------+-------------+
8 rows in set (0.00 sec)
- 排序(ORDER BY)
#排序语法SELECT 字段列表 FROM 库名.表名 [WHERE 筛选条件] ORDER BY 排序字段 [ASC|DESC];ASC代表升序,为默认值DESC为为降序#排序练习
mysql> SELECT name,uid,shell FROM tarena.user-> WHERE uid IS NOT NULL; #默认情况uid无序mysql> SELECT name,uid,shell FROM tarena.user-> WHERE uid IS NOT NULL-> ORDER BY uid; #按照uid字段值大小升序排列mysql> SELECT name,uid,shell FROM tarena.user-> WHERE uid IS NOT NULL-> ORDER BY uid DESC; #按照uid字段值大小降序排列
- 过滤(HAVING)
#过滤语法SELECT 字段列表 FROM 库名.表名 [WHERE 筛选条件] [GROUP BY 分组字段] HAVING 过滤条件;#WHERE用于表内真实字段筛选#HAVING用于SELECT后出现的字段过滤(可过滤临时字段)#GROUP BY 后边只能用HAVING#过滤练习
mysql> SELECT dept_id,name FROM tarena.employees; #查询employees表所有数据mysql> SELECT dept_id,name FROM tarena.employees-> WHERE dept_id >= 5; #查询employees表中部门id大于5的记录mysql> SELECT dept_id,COUNT(name) FROM tarena.employees -> WHERE dept_id >= 5 -> GROUP BY dept_id; #查询employees表中部门id大于5的每个部门人数mysql> SELECT dept_id,COUNT(name) AS dept_count -> FROM tarena.employees -> WHERE dept_id >= 5 -> GROUP BY dept_id -> HAVING dept_count > 10; #查询employees表中部门id大于5且部门人数大于10人的部门与人数
- 分页(LIMIT)
#分页语法SELECT 字段列表 FROM 库名.表名 LIMIT 数字;SELECT 字段列表 FROM 库名.表名 LIMIT 数字1,数字2;用于显示部分查询结果LIMIT 后边只有1个数字则为前几行LIMIT 后边有两个数字则从第几行开始及之后的行数(注意:起始行从0开始算)#分页练习
mysql> SELECT * FROM tarena.user; #显示所有结果mysql> SELECT * FROM tarena.user LIMIT 2; #显示所有结果的前2行mysql> SELECT * FROM tarena.user LIMIT 2,3; #显示所有结果从第3行开始及之后的3行
- 综合练习
#综合语法:SELECT 查询字段列表FROM 库名.表名WHERE 筛选条件GROUP BY 分组字段HAVING 过滤字段ORDER BY 排序字段LIMIT 行数#1、查询salary表中所有员工2018年工资总和并按照总工资降序排列
mysql> SELECT * FROM tarena.salary; #获取salary表所有数据mysql> SELECT * FROM tarena.salary WHERE YEAR(date)=2018; #筛选2018年工资记录mysql> SELECT employee_id,basic+bonus AS total -> FROM tarena.salary -> WHERE YEAR(date)=2018; #通过计算汇总月工资mysql> SELECT employee_id,SUM(basic+bonus) AS year_total -> FROM tarena.salary -> WHERE YEAR(date)=2018 -> GROUP BY employee_id; #补充分组和SUM函数汇总年工资mysql> SELECT employee_id,SUM(basic+bonus) AS year_total -> FROM tarena.salary -> WHERE YEAR(date)=2018 -> GROUP BY employee_id -> HAVING year_total>300000; #补充过滤年工资高于30wmysql> SELECT employee_id,SUM(basic+bonus) AS year_total -> FROM tarena.salary -> WHERE YEAR(date)=2018 -> GROUP BY employee_id -> HAVING year_total>300000 -> ORDER BY year_total DESC; #补充按照年工资降序排列mysql> SELECT employee_id,SUM(basic+bonus) AS year_total -> FROM tarena.salary -> WHERE YEAR(date)=2018 -> GROUP BY employee_id -> HAVING year_total>300000 -> ORDER BY year_total DESC-> LIMIT 5; #补充显示前5条记录mysql> SELECT employee_id,SUM(basic+bonus) AS year_total -> FROM tarena.salary -> WHERE YEAR(date)=2018 -> GROUP BY employee_id -> HAVING year_total>300000 -> ORDER BY year_total DESC,employee_id DESC -> LIMIT 5; #补充多字段排序,当year_total相同按照employee_id降序
连接查询(联表查询)
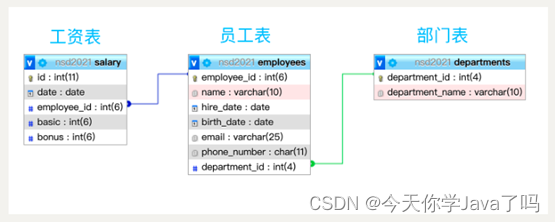
表关系
什么是连接查询
把多张表通过连接条件临时组成一张新表,在临时的新表里有连接表的所有字段和数据
连接查询分类
-
按功能分类
- 内连接
- 外连接
-
按年代分类
- SQL92标准:仅支持内连接
- SQL99标准:支持所有类型连接
-
语法
#连接查询语法 SELECT 字段列表 FROM 表1 AS 别名1连接类型 JOIN 表2 AS 别名2ON 连接条件连接类型 JOIN... 表n AS 别名nON 连接条件 [WHERE 分组前筛选条件] [GROUP BY 分组字段] [HAVING 分组后筛选条件] [ORDER BY 排序字段] [LIMIT 显示行数]
笛卡尔积
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员
例如:X=(1,2), Y=(a,b) 则X×Y=((1,a),(1,b),(2,a),(2,b))
#获取笛卡尔积结果
mysql> USE tarena;mysql> SELECT * FROM departments; #查询departments表所有数据mysql> SELECT * FROM employees; #查询employees表所有数据mysql> SELECT * FROM departments,employees; #查询dep表和emp表的笛卡尔积
内连接(INNER)
-
功能:将2张及以上的表格按照连接条件连接为1张新表(取符合连接条件的部分)
-
语法
#语法格式 SELECT 字段列表 FROM 表1 AS 别名1INNER JOIN 表2 AS 别名2 连接条件INNER JOIN... 表n AS 别名nON 连接条件 [WHERE 分组前筛选条件 | GROUP BY 分组字段 | HAVING 分组后筛选条件 | ORDER BY 排序字段 | LIMITE 显示行数]#连接条件- 等值连接:连接条件是等值判断- 不等值连接:连接条件是不等值判断- 自连接:自己连接自己,把1张表当做2张表(使用时需定义别名) -
等值连接
#内连接-等值连接练习#查询每个员工所属部门(多表中无重复字段可直接查询字段)
mysql> SELECT dept_name,name FROM-> departments-> INNER JOIN-> employees-> ON departments.dept_id=employees.dept_id;#查询工号为8的员工姓名和所属部门
mysql> SELECT name,dept_name FROM -> employees-> INNER JOIN-> departments-> ON employees.dept_id=departments.dept_id -> WHERE employees.employee_id=8;#查询工号为8的员工姓名和所属部门(对表定义别名后字段前表名可使用别名)
mysql> SELECT -> employees.name,departments.dept_name FROM-> employees-> INNER JOIN-> departments-> ON employees.dept_id=departments.dept_id-> WHERE employees.employee_id=8; #原始写法,不定义表的别名mysql> SELECT -> e.name,d.dept_name FROM -> employees AS e-> INNER JOIN-> departments AS d -> ON e.dept_id=d.dept_id -> WHERE e.employee_id=8; #优化写法,定义表别名mysql> SELECT -> e.name AS "员工姓名",-> d.dept_name AS "部门名称"-> FROM-> employees AS e-> INNER JOIN-> departments AS d-> ON e.dept_id=d.dept_id-> WHERE e.employee_id = 8; #对查询结果字段名定义别名
+--------------+--------------+
| 员工姓名 | 部门名称 |
+--------------+--------------+
| 汪云 | 人事部 |
+--------------+--------------+
1 row in set (0.00 sec)
- 非等值连接
#内连接-非等值连接#创建新表,用于划分工资级别
mysql> USE tarena; #切换到tarena库mysql> CREATE TABLE tarena.wage_grade(-> id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,-> grade CHAR(1),-> floor INT,-> ceiling INT-> ); #创建工资级别表wage_grademysql> INSERT INTO tarena.wage_grade(grade,floor,ceiling)-> VALUES-> ('A',5000,8000),('B',8001,10000),-> ('C',10001,15000),('D',15001,20000),-> ('E',20001,1000000); #向表内写入数据,划分工资为5个级别mysql> SELECT * FROM tarena.wage_grade; #确认数据写入成功
+----+-------+---------+---------+
| id | grade | floor | ceiling |
+----+-------+---------+---------+
| 1 | A | 5000 | 8000 |
| 2 | B | 8001 | 10000 |
| 3 | C | 10001 | 15000 |
| 4 | D | 15001 | 20000 |
| 5 | E | 20001 | 1000000 |
+----+-------+---------+---------+#查询2018年12月员工基本工资
mysql> SELECT date,basic FROM tarena.salary where YEAR(date)=2018 AND MONTH(date)=12;#查询2018年12月员工基本工资级别
mysql> SELECT s.employee_id,s.date,s.basic,g.grade FROM salary AS s INNER JOIN wage_grade AS g ON s.basic BETWEEN g.floor AND g.ceiling WHERE YEAR(s.date)=2018 AND MONTH(s.date)=12;
+-------------+------------+-------+-------+
| employee_id | date | basic | grade |
+-------------+------------+-------+-------+
| 1 | 2018-12-10 | 17016 | D |
| 2 | 2018-12-10 | 20662 | E |
| 3 | 2018-12-10 | 9724 | B |
| 4 | 2018-12-10 | 17016 | D |
....#查询2018年12月员工基本工资各级别的人数
mysql> SELECT COUNT(s.basic),g.grade FROM salary AS s INNER JOIN wage_grade AS g ON s.basic BETWEEN g.floor AND g.ceiling WHERE YEAR(s.date)=2018 AND MONTH(s.date)=12 GROUP BY g.grade;
+----------------+-------+
| COUNT(s.basic) | grade |
+----------------+-------+
| 13 | A |
| 12 | B |
| 30 | C |
| 32 | D |
| 33 | E |
+----------------+-------+
- 自连接
#内连接-自连接
#操作方法:自己连接自己,通过定义别名的方式区分筛选字段#自连接练习#查询入职月份与出生月份相同的人有哪些
mysql> SELECT e.employee_id,e.name,e.birth_date,emp.hire_date FROM employees AS e INNER JOIN employees AS emp ON e.employee_id = emp.employee_id WHERE MONTH(e.birth_date)=MONTH(emp.hire_date);
+-------------+-----------+------------+------------+
| employee_id | name | birth_date | hire_date |
+-------------+-----------+------------+------------+
| 3 | 李玉英 | 1974-01-25 | 2012-01-19 |
| 5 | 郑静 | 1997-02-14 | 2018-02-03 |
| 62 | 林刚 | 1990-09-23 | 2007-09-19 |
| 76 | 刘桂兰 | 1982-10-11 | 2003-10-14 |
...mysql> SELECT employee_id,name,birth_date,hire_date FROM employees WHERE MONTH(birth_date)=MONTH(hire_date); #可通过WHERE条件实现
外连接
| 连接类型 | 关键字 | 功能 |
|---|---|---|
| 左外连接 | LEFT JOIN | 左边的表为主表 左边表的记录全都显示出来 右边的表只显示与条件匹配记录 右边表比左边表少的记录使用NULL匹配 |
| 右外连接 | RIGHT JOIN | 右边的表为主表 右边表的记录全都显示出来 左边的表只显示与条件匹配记录 左边表比右边表少的记录使用NULL匹配 |
| 全外连接 | UNION [ALL] | 也称联合查询 用来一起输出多个select查询结果 要求查询时多个select语句查看的字段个数必须一致 UNION关键字默认去重,可以使用UNION ALL包含重复项 |
- 左外连接
#语法SELECT 字段列表 FROM表1 AS 别名1LEFT JOIN表2 AS 别名2ON 连接条件[WHERE 筛选条件] | [GROUP BY 分组] | [HAVING 分组后筛选]|[ORDER BY 排序]|[LIMIT 行数]#左外连接练习#departments表中创建新部门
mysql> INSERT INTO tarena.departments(dept_name) VALUES ('行政部'),('公关部');mysql> SELECT * FROM tarena.departments; #确认新部门添加成功#使用内连接的等值连接查询每个员工属于哪个部门,稍后和左外连接做个对比
mysql> SELECT d.dept_id,d.dept_name,e.name FROM departments AS d INNER JOIN employees AS e ON d.dept_id=e.dept_id;#测试左外连接
mysql> SELECT d.dept_id,d.dept_name,e.name FROM departments AS d LEFT JOIN employees AS e ON d.dept_id=e.dept_id;
+---------+-----------+-----------+
| dept_id | dept_name | name |
+---------+-----------+-----------+
| 1 | 人事部 | 梁伟 |
...
| 8 | 法务部 | 杨金凤 |
| 9 | 行政部 | NULL |
| 10 | 公关部 | NULL |
+---------+-----------+-----------+
135 rows in set (0.00 sec)
#name为employees表字段,目前部门内没人,用NULL补#查询目前还没有人的部门
mysql> SELECT -> d.dept_name AS 部门名称,COUNT(e.name) AS 部门人数-> FROM departments AS d LEFT JOIN employees AS e-> ON d.dept_id=e.dept_id -> GROUP BY d.dept_name -> HAVING 部门人数=0;
+--------------+--------------+
| 部门名称 | 部门人数 |
+--------------+--------------+
| 公关部 | 0 |
| 行政部 | 0 |
+--------------+--------------+
2 rows in set (0.00 sec)
- 右外连接
#语法SELECT 字段列表 FROM表1 AS 别名1RIGHT JOIN表2 AS 别名2ON 连接条件[WHERE 筛选条件] | [GROUP BY 分组] | [HAVING 分组后筛选]|[ORDER BY 排序]|[LIMIT 行数]#右外连接练习#employees表中入职新员工
mysql> INSERT INTO employees(name) VALUES ('tom'),('bob');
mysql> SELECT * FROM employees; #确认新员工添加成功#测试右外连接
mysql> SELECT d.dept_name,e.name FROM departments AS d RIGHT JOIN employees AS e ON d.dept_id=e.dept_id;
+-----------+-----------+
| dept_name | name |
+-----------+-----------+
| 人事部 | 梁伟 |
...
| 法务部 | 杨金凤 |
| NULL | tom |
| NULL | bob |
+-----------+-----------+
135 rows in set (0.00 sec)
#dept_name为departments表字段,目前tom和jim无部门归属,用NULL补齐
- 全外连接
#语法:(SELECT语句 ) UNION (SELECT语句); #去除重复结果(SELECT语句 ) UNION ALL (SELECT语句); #保留重复结果#全外连接练习#测试全外连接
mysql> SELECT name,uid,shell FROM user LIMIT 1; #1条结果mysql> SELECT name,uid,shell FROM user LIMIT 2; #2条结果mysql> (SELECT name,uid,shell FROM user LIMIT 1) -> UNION -> (SELECT name,uid,shell FROM user LIMIT 2); #去重显示
+------+------+---------------+
| name | uid | shell |
+------+------+---------------+
| root | 0 | /bin/bash |
| bin | 1 | /sbin/nologin |
+------+------+---------------+
2 rows in set (0.00 sec)mysql> (SELECT name,uid,shell FROM user LIMIT 1) -> UNION ALL -> (SELECT name,uid,shell FROM user LIMIT 2); #不去重显示
+------+------+---------------+
| name | uid | shell |
+------+------+---------------+
| root | 0 | /bin/bash |
| root | 0 | /bin/bash |
| bin | 1 | /sbin/nologin |
+------+------+---------------+
3 rows in set (0.00 sec)#左外连接 UNION 右外连接 实现全外连接
mysql> (SELECT d.dept_name,e.name FROM departments d LEFT JOIN employees e ON d.dept_id=e.dept_id) -> UNION-> (SELECT d.dept_name,e.name FROM departments d RIGHT JOIN employees e ON d.dept_id=e.dept_id);
+-----------+-----------+
| dept_name | name |
+-----------+-----------+
| 人事部 | 梁伟 |
...
| 法务部 | 杨金凤 |
| 行政部 | NULL |
| 公关部 | NULL |
| NULL | tom |
| NULL | bob |
+-----------+-----------+
137 rows in set (0.00 sec)
子查询
什么是子查询
SELECT语句中嵌套若干个SELECT子句从而完成某个复杂功能的SQL编写方法
子查询出现的位置
- SELECT之后
- FROM之后
- WHERE之后
- HAVING之后
子查询练习
#登录MySQL服务
[root@mysql ~]# mysql -hlocalhost -uroot -p'123qqq...A'mysql> USE tarena; #切换至tarena库#使用子查询统计每个部门的人数(SELECT之后)
mysql> SELECT d.dept_id,d.dept_name FROM departments AS d;mysql> SELECT COUNT(e.name) FROM employees AS e WHERE e.dept_id=1;mysql> SELECT d.dept_id,d.dept_name,(SELECT COUNT(e.name) FROM employees AS e WHERE e.dept_id=d.dept_id) AS 人数 FROM departments AS d;
+---------+-----------+--------+
| dept_id | dept_name | 人数 |
+---------+-----------+--------+
| 1 | 人事部 | 8 |
| 2 | 财务部 | 5 |
| 3 | 运维部 | 6 |
...
总结
- 掌握mysql常用函数
- 时间函数
- 聚集函数
- 掌握查询结果处理
- 分组查询
- 排序
- 分页查询
- 过滤
- 连接查询
- 内连接
- 外连接
- 子查询