Re50:读论文 Large Language Models Struggle to Learn Long-Tail Knowledge
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Large Language Models Struggle to Learn Long-Tail Knowledge
ArXiv网址:https://arxiv.org/abs/2211.08411
官方GitHub项目(代码和实体):https://github.com/nkandpa2/long_tail_knowledge
本文是2023年ICML论文,主要关注LLM无法记忆长尾知识的问题。
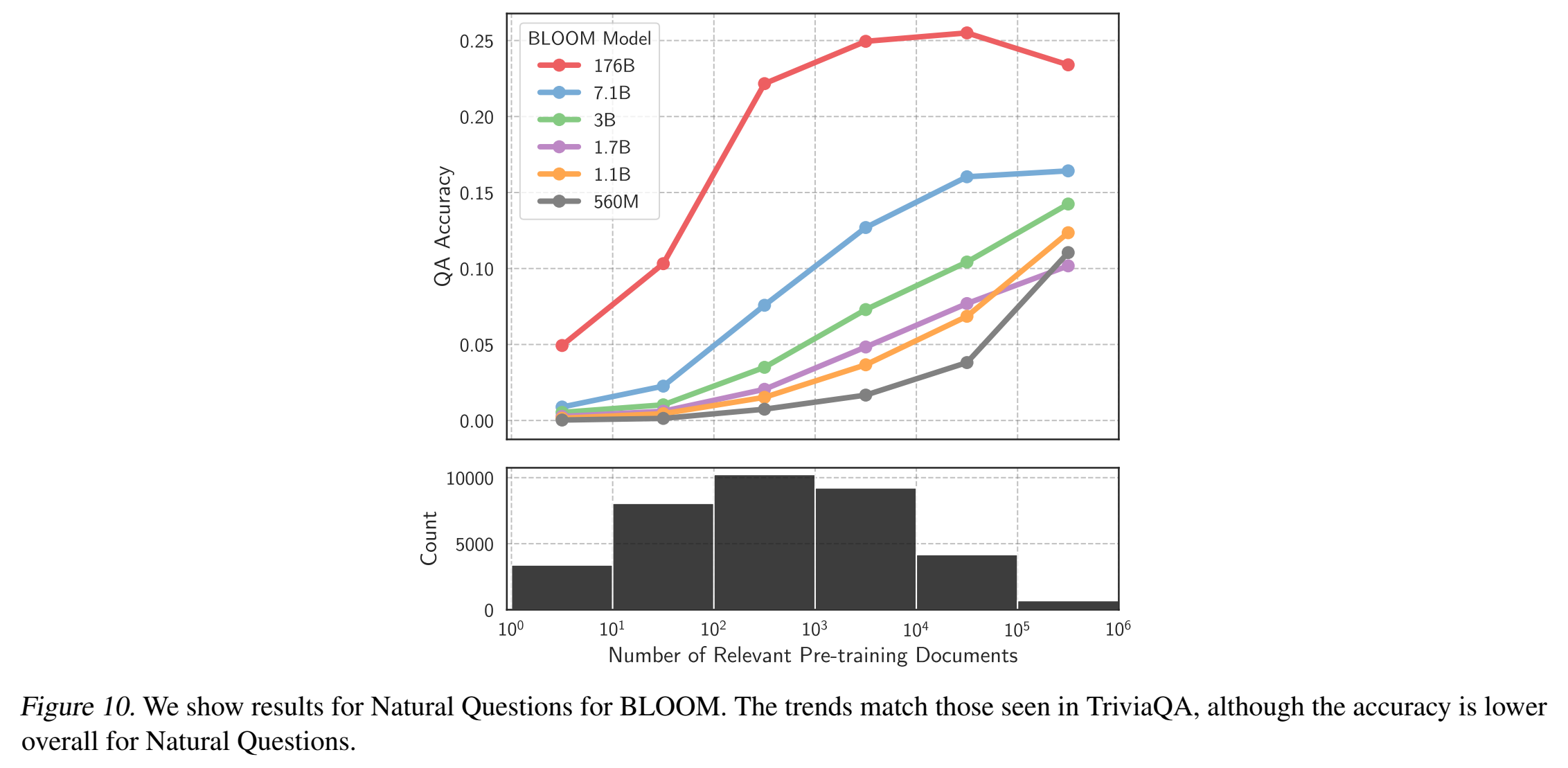
检测方式是让LLM基于事实回答问题(4-shot closed-book QA evaluations),看准确率与预训练语料中问题相关文档数的关系。文档中包含问题里的实体对,就算相关文档。
增大模型确实能缓解长尾问题,但是要求规模指数级提升才能匹配数据集出现频率的一点点提升。还是用检索增强的方式比较好。但是检索系统的方法本身也需要有相关文档才行。
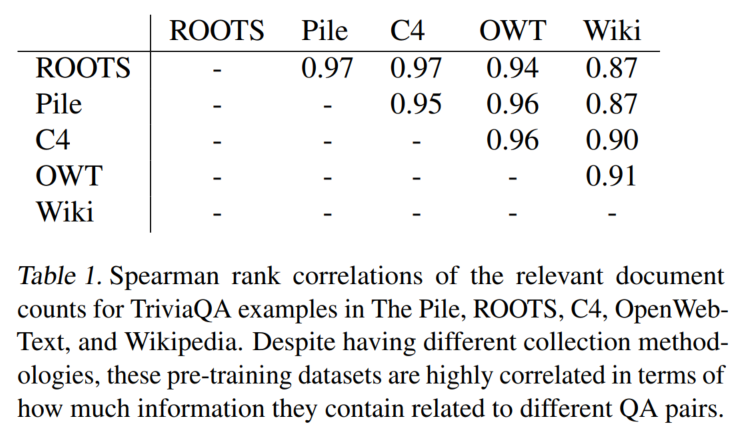
预训练语料(用于链接实体和找相关文档):ROOTS, The Pile, C4, OpenWebText, and Wikipedia
(话说本文提到没有研究跨语言知识。我感觉这一点也挺值得研究的)
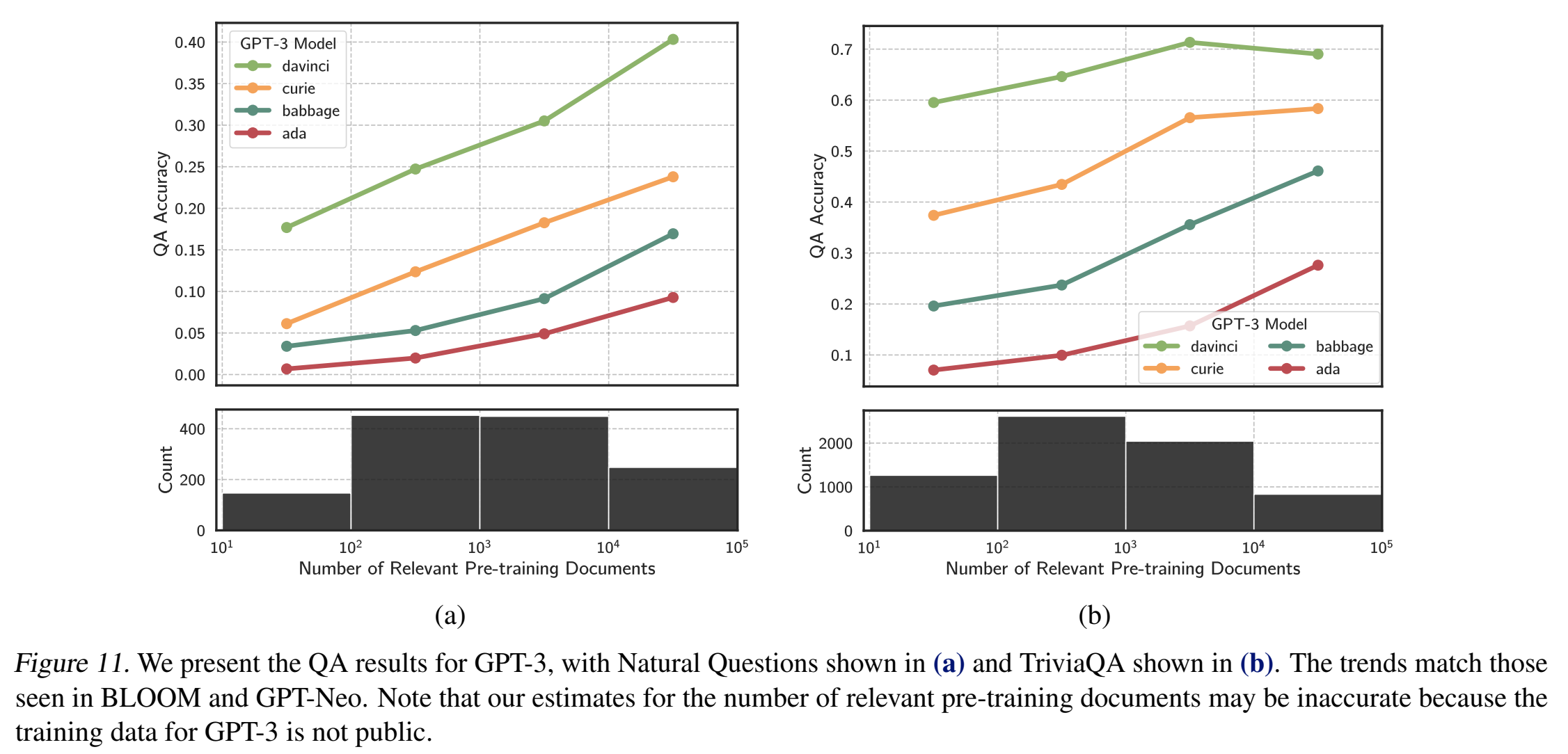
QA数据集:Natural Questions & TriviaQA
模型:
Transformer decoder-only LMs:
GPT-Neo
BLOOM-176B BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
GPT-3
文章目录
- 1. 研究背景&核心观察结果
- 2. 实验
- 1. 实验设置
- 2. 观察实验结果
- 3. 解决方案
1. 研究背景&核心观察结果
LLM难以记忆长尾知识:
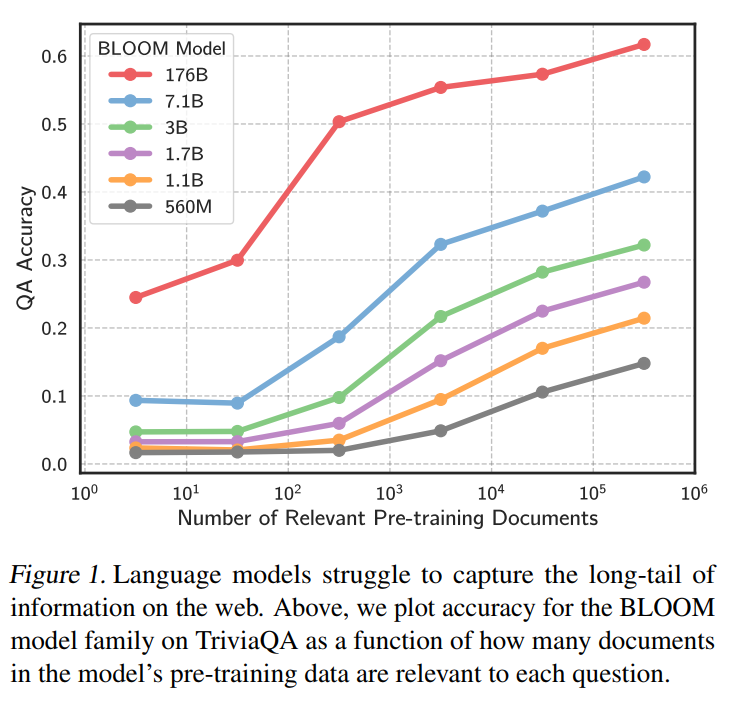
(相关文档数量指数分箱,取QA准确率平均值)
2. 实验
1. 实验设置
1. 找相关文档:
事实QA数据集→从预训练文档里找出相关文档(如果问答对中的两个实体都出现,就算相关文档)
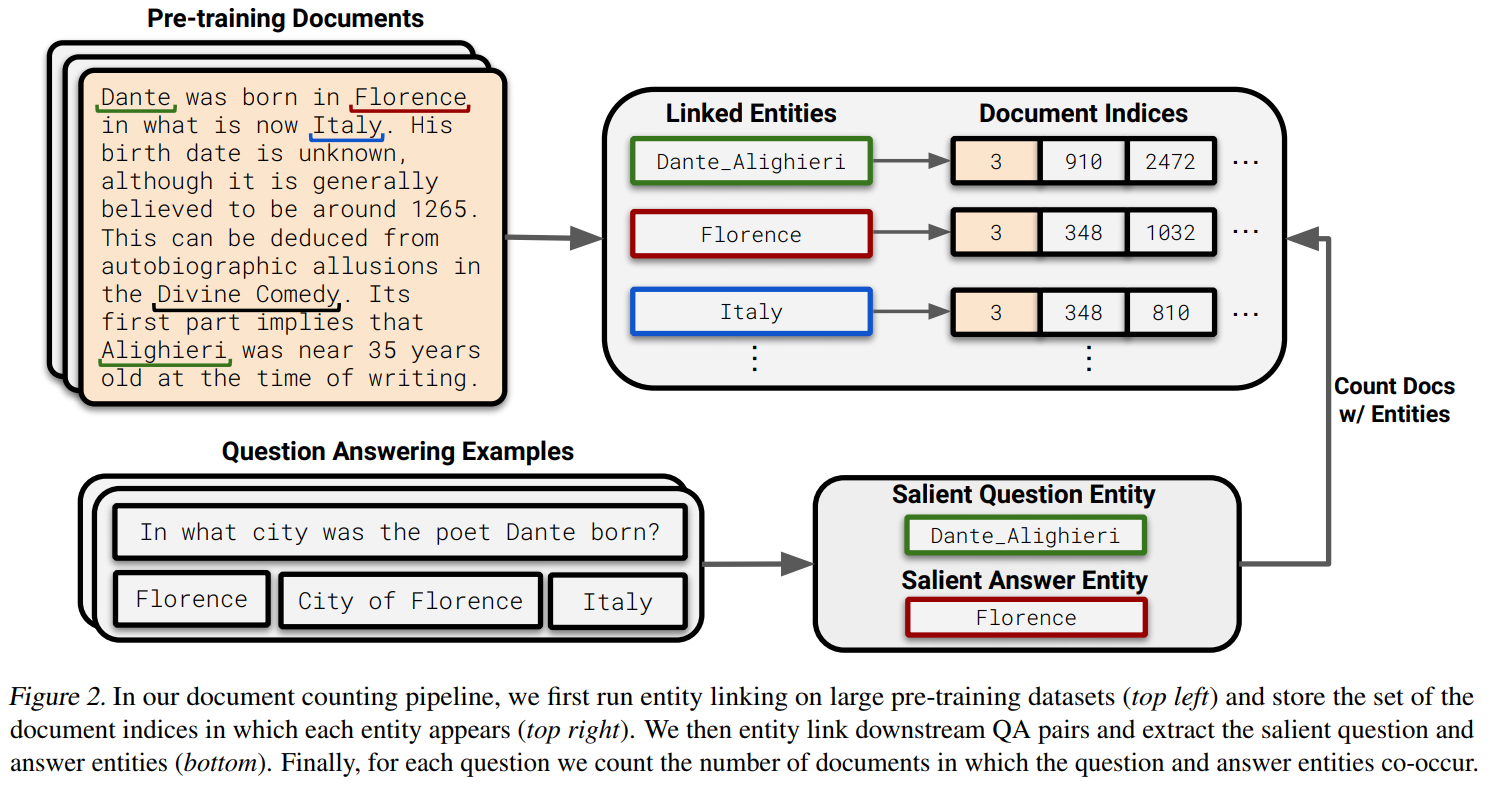
实体链接工具:DBpedia Spotlight Entity Linker1
2. QA:

其他示例样本数得到的结果差别不大
解码方案:贪心解码
2. 观察实验结果
(TriviaQA在BLOOM上的结果图Figure 1我放在第一节了)
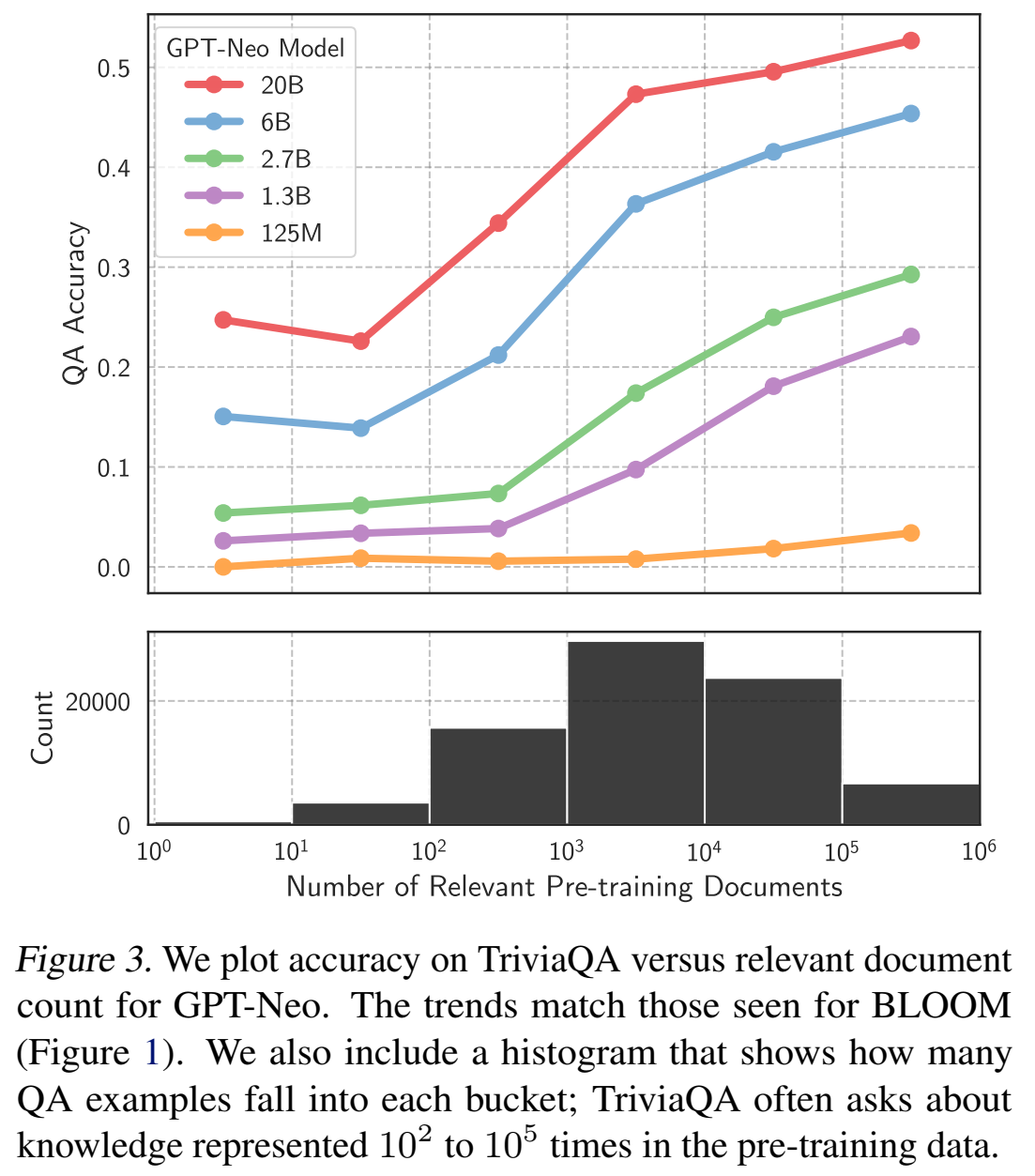
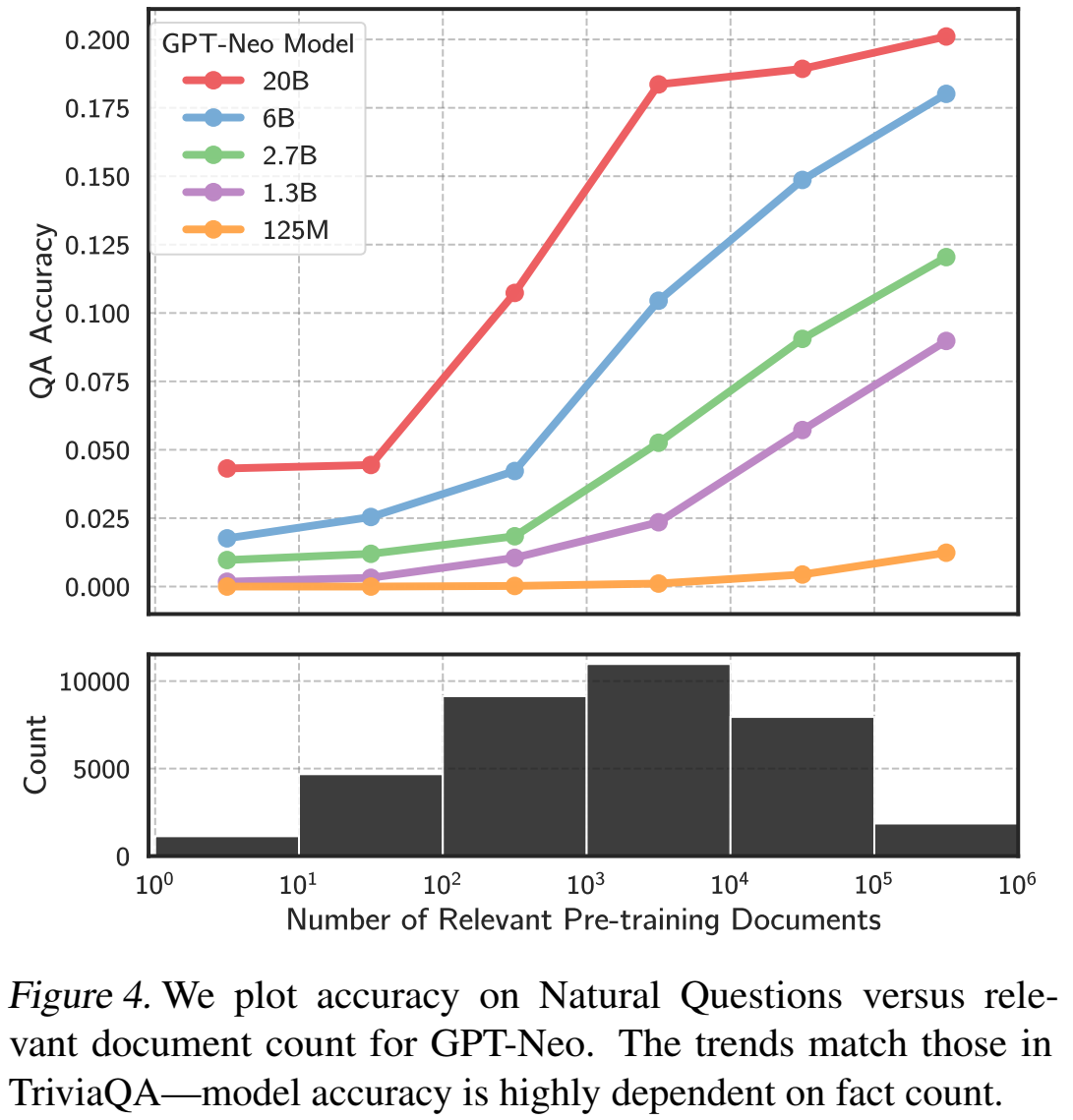
证明相关文档必须要同时含有问答中的实体的必要性:
用问题实体或回答实体,可以得到与同时使用中相似的结果;但是如果去掉问答都有的情况,就没有这样的表现了。说明其实模型学习靠的是问答都有的情况
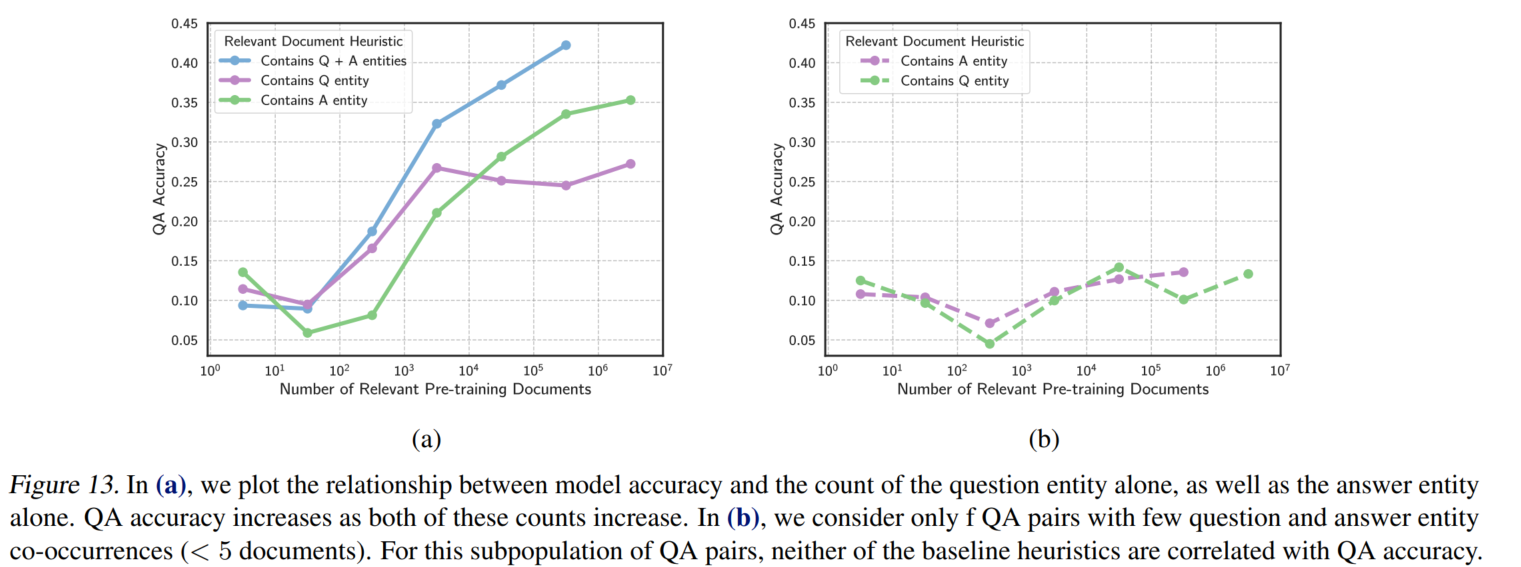
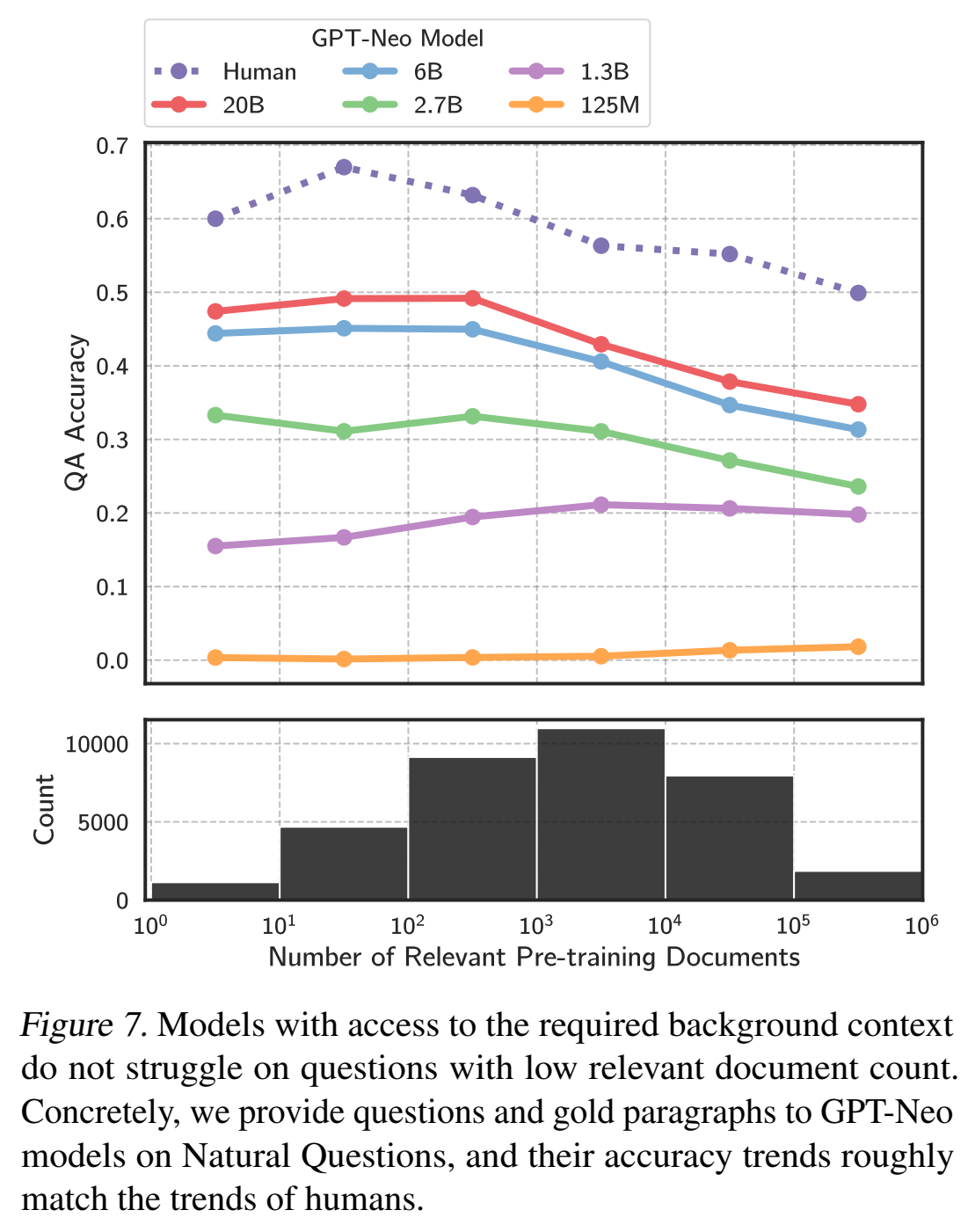
人工结果和LM结果趋势相反
对LM预测结果出现原因的分析:
对比实验,证明去掉相关文档重新训练LM后准确率会下降:
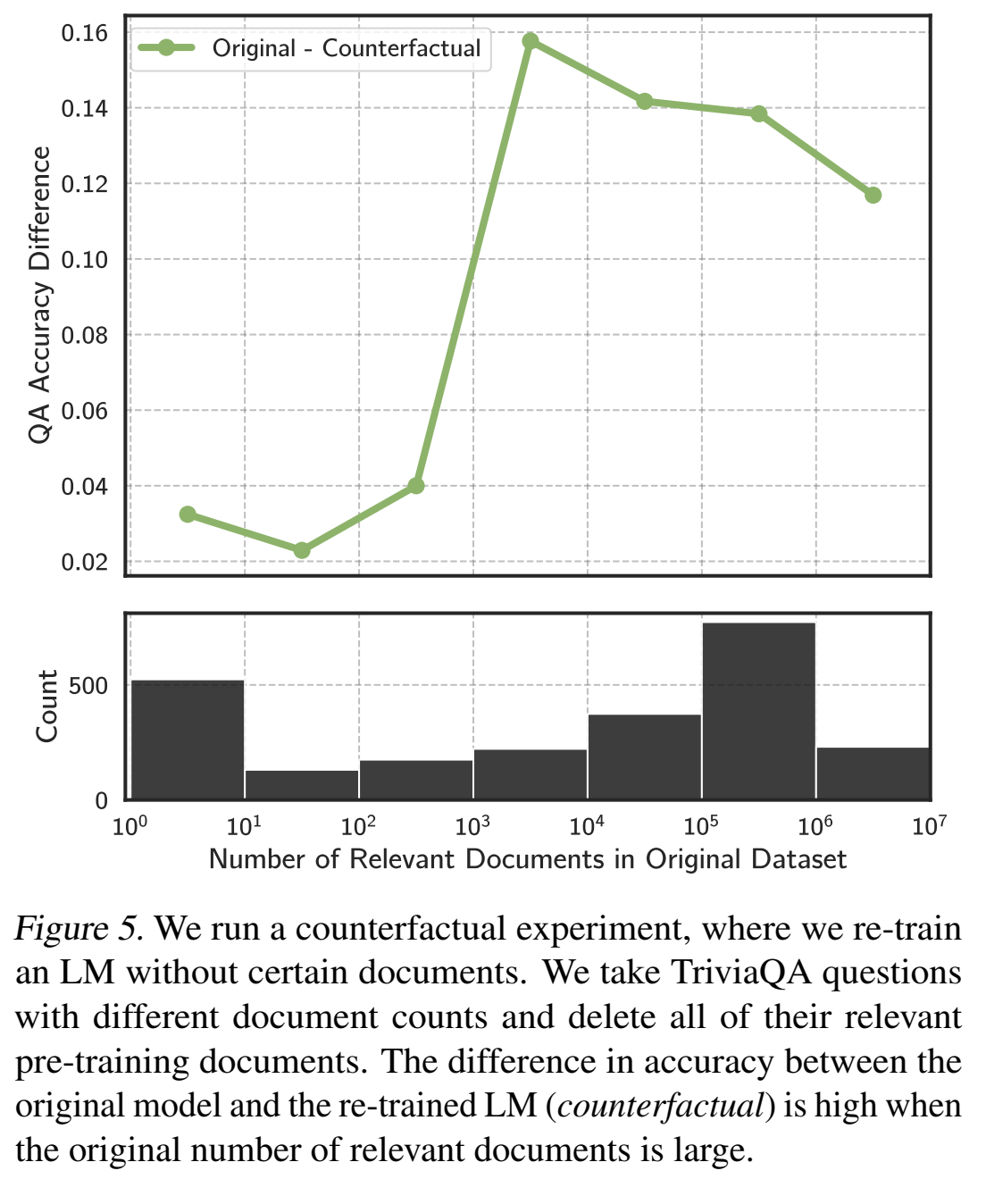
3. 解决方案
scale数据集
没啥用,各个数据集的支持信息都差不多:
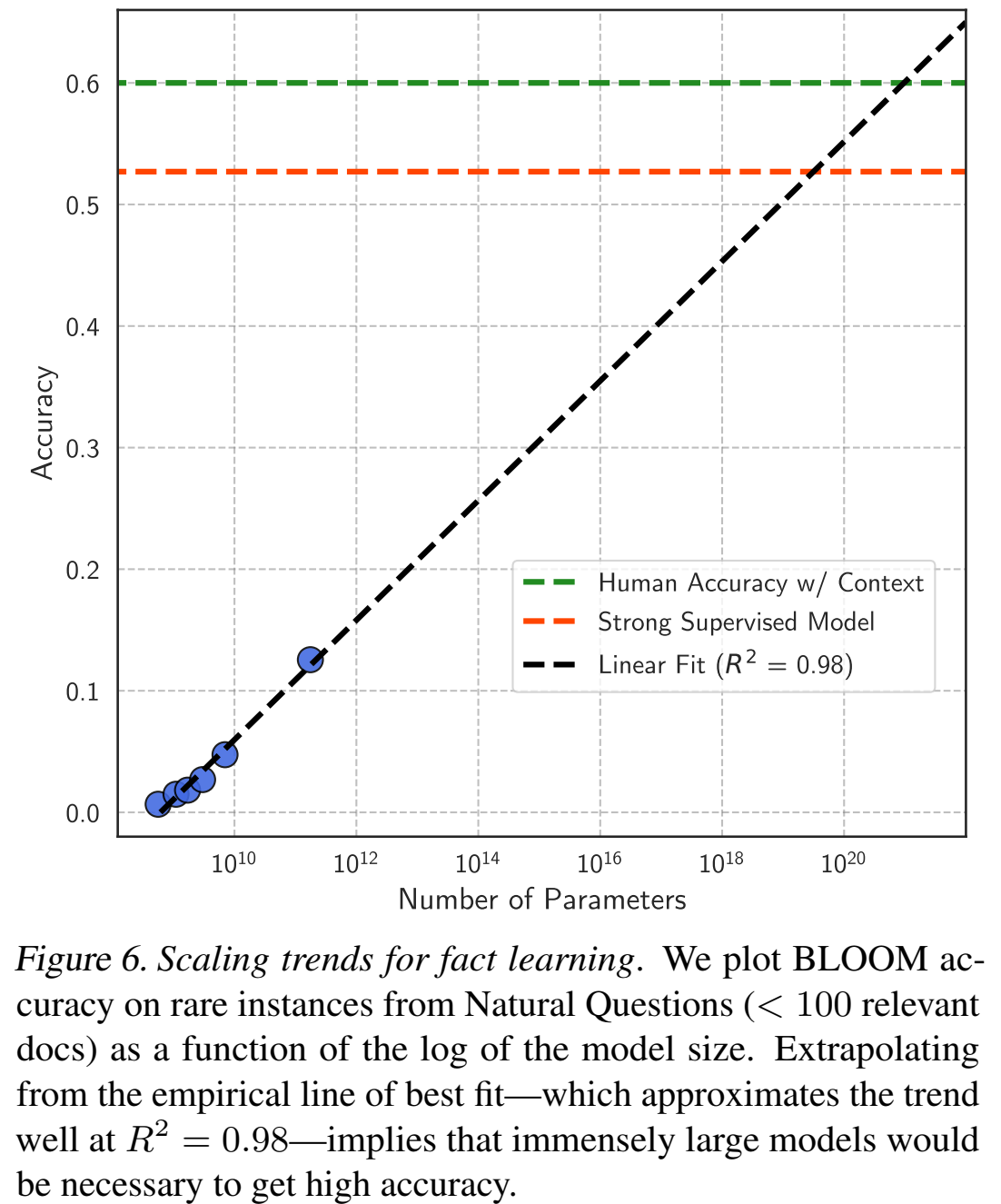
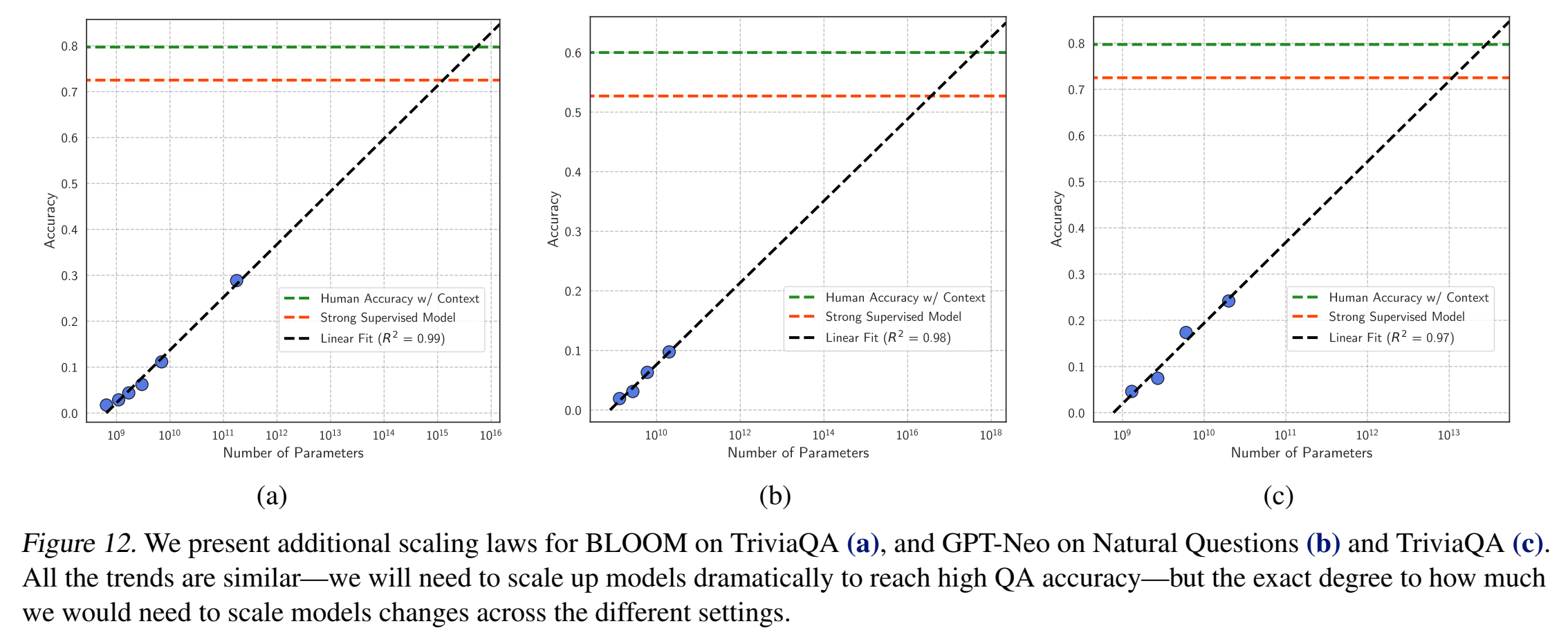
scale模型
想法是好的,但是需要的增量太大了
调整训练目标
改为encourage memorization
增大训练epoch数……等等
检索增强
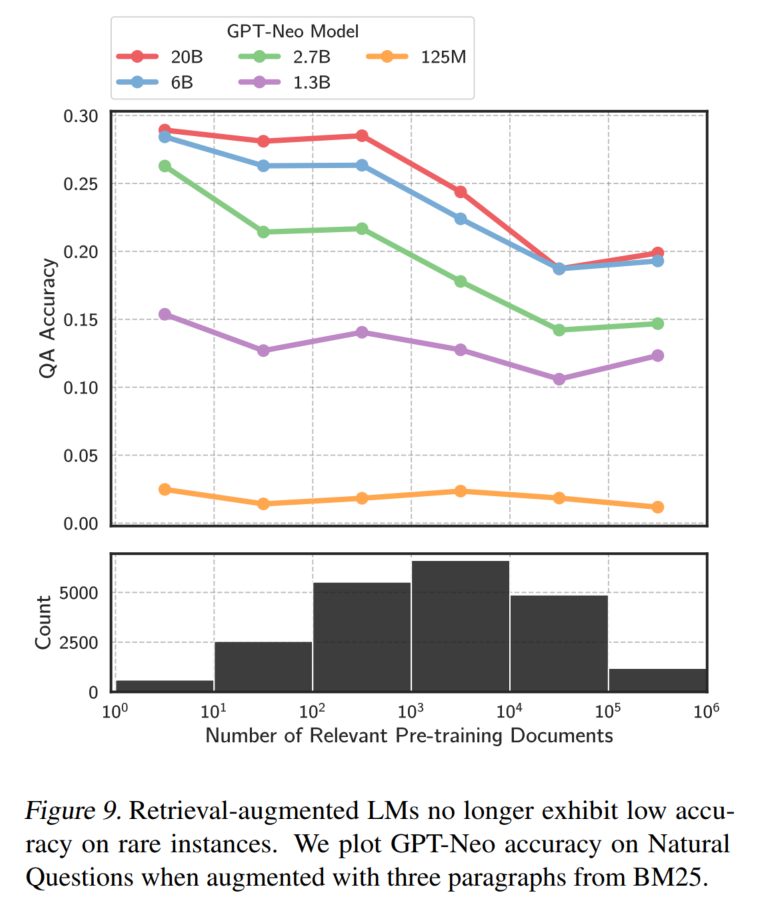
直接用相关文档,效果能得到大幅度提升:
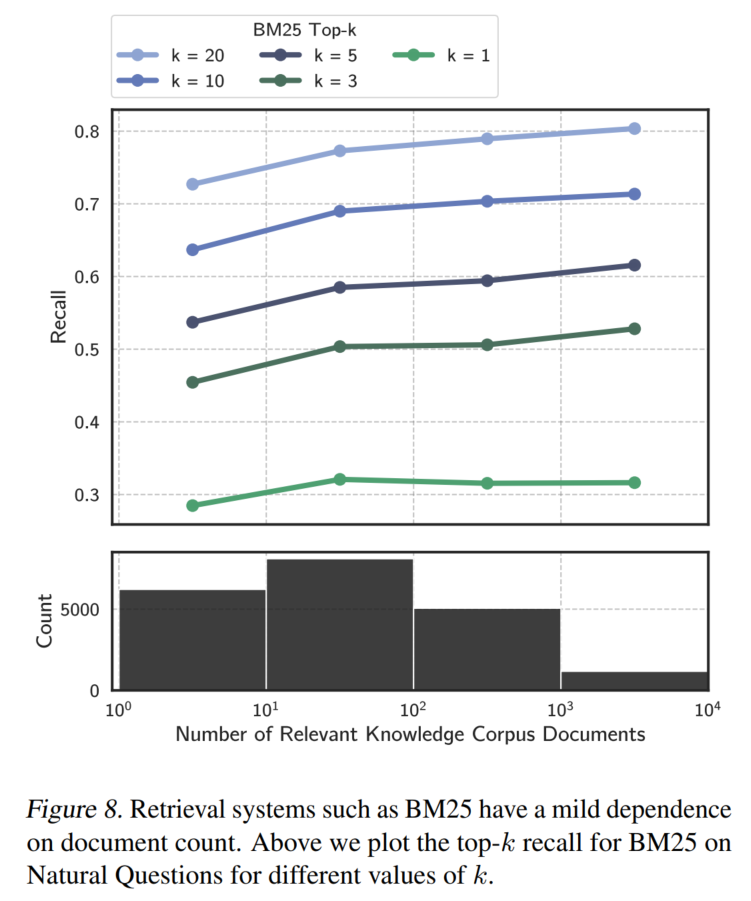
用BM25算法实现检索:
果然表现好起来了
(2011 I-Semantics) DBpedia spotlight: shedding light on the web of documents ↩︎