Python——常见内置模块
Python
- 模块(Modules)
- 1、概念
- 模块=函数+类+变量
- 2、分类
- 3、模块导入的方法:五种
- 4、使用import 导入模块
- 5、使用from……import部分导入
- 6、使用as关键字为导入模块或功能命名别名
- 7、模块的搜索目录
- 8、自定义模块
- 常见内置模块
- 一、math模块
- 二、random模块
- 三、OS模块
- 四、os.path模块
- 五、sys模块
- 六、UUID模块
- 七、时间日期模块
- 1、time模块
- 2、datetime模块
- 3、calendar模块
- 八、加密模块
- 1、hashlib
- 2、hmac模块
模块(Modules)
1、概念
- 将实现某一特定功能的代码放置在文件中,以便与其它程序进行导入,可以避免函数名或变量名的冲突,该文件称为模块,扩展名.py
- 打开python的安装包,lib文件下全是模块
模块=函数+类+变量
2、分类
- 内置模块:目前python内置模块大概在200多个,如:

- 自定义模块:第三方模块
3、模块导入的方法:五种
- import 模块名
- from 模块名 import 功能名
- from 模块名 import
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
4、使用import 导入模块
- 格式1:import 模块名
- 格式2:import 模块名1 , 模块名2 ,…… 模块名n
- 使用方法:模块名.功能名()
import math
print(math.sqrt(9))
5、使用from……import部分导入
- 意义:使用import导入后会把所有内部功能全部导入到当前的文件中,比较臃肿一些,若需要导入部分功能可以使用from语句
- 例:
from math import sqrt, floor
print(sqrt(9), floor(10.88))
- 注意:使用时不需要书写模块名
6、使用as关键字为导入模块或功能命名别名
- 原因:某些情况下导入的模块或功能名称过长,可以使用较短的别名对齐命名,使用时较为方便
- 例:
import time as ttprint('hello')
tt.sleep(3)
print('world')
- 注意:别名命名后不能在使用原有的模块名
7、模块的搜索目录
-
当使用import语句导入模块时,默认情况下会按照如下顺序进行模块查找:
- 执行python文件的当前项目目录
- 环境变量:PYTHONPATH
- python解释器安装目录中
-
可以通过sys.path查找目录的路径:
import sys
print(sys.path)
8、自定义模块
- 作用:将相关的代码编写在一个单独的文件中,并命名为模块名.py,可以导入到程序中使用,注意自行创建的模块名不能与python自带的标准库中模块名重名
- 例:新建一个模块文件prime.py,实现素数判断:
def fun_prime(num):if num<2:print('请输入大于2的正整数')else:for i in range(2,num):if num%i==0:return 0else:return 1
新建一个python文件加载导入上述模块,实现100以内的素数判断输出
import primefor i in range(2, 100):if prime.fun_prime(i) == 1:print(i, end=' ')
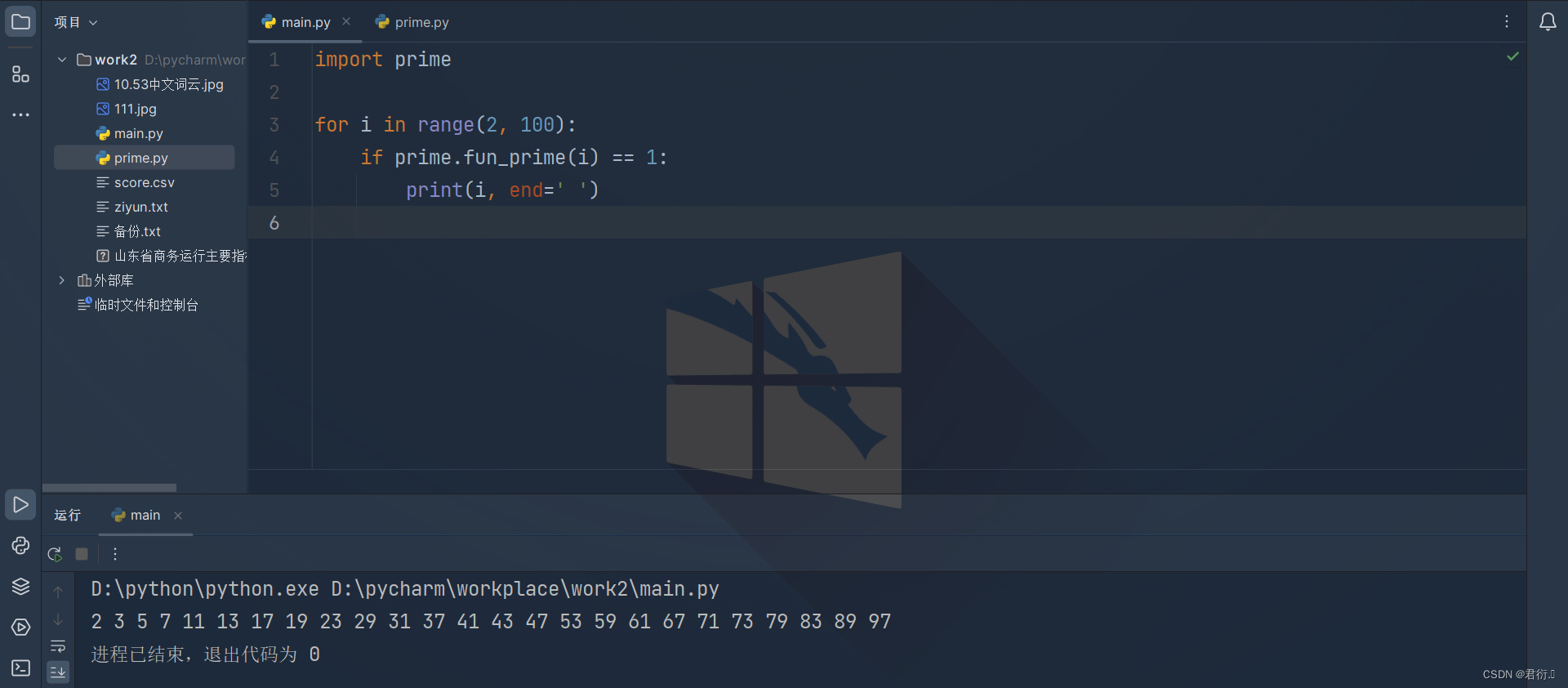
- 自定义模块中的功能测试
- 作用:编写完自定义模块后,最好在模块内部对代码进行测试,以防止出现问题
- 魔方方法:_ _ name _ _ ,每个模块中都会有一个字符串变量,记录模块名称,随着运行页面的不同,返回值结果也不相同
- 当前页面执行:返回值为_ _ main_ _
def fun_prime(num):if num < 2:print('请输入大于2的正整数')else:for i in range(2, num):if num % i == 0:return 0else:return 1print(__name__) #结果:_ _ main_ _
在第三方页面导入执行时,返回值:模块名称
import primefor i in range(2, 100):if prime.fun_prime(i) == 1:print(i, end=' ')
# 输出 prime 模块名
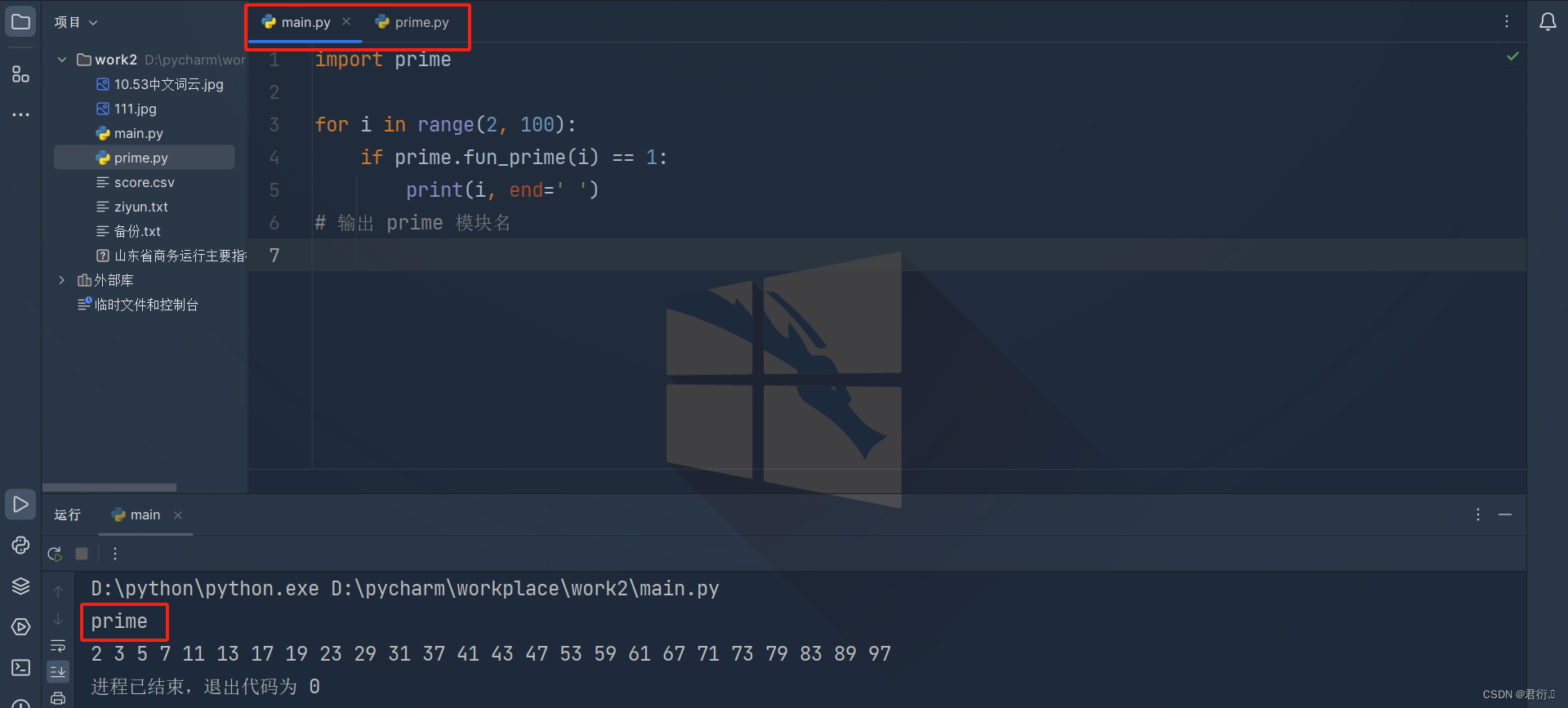
基于以上特性,可以把_ _name _ _编写在自定义模块汇总,格式如下:
if _ name _ _ ==’ _ _ name_ _ _’
处理
def fun_prime(num):if num < 2:print('请输入大于2的正整数')else:for i in range(2, num):if num % i == 0:return 0else:return 1if __name__ == '__main__':if fun_prime(5) == 1:print('素数')else:print('平数')
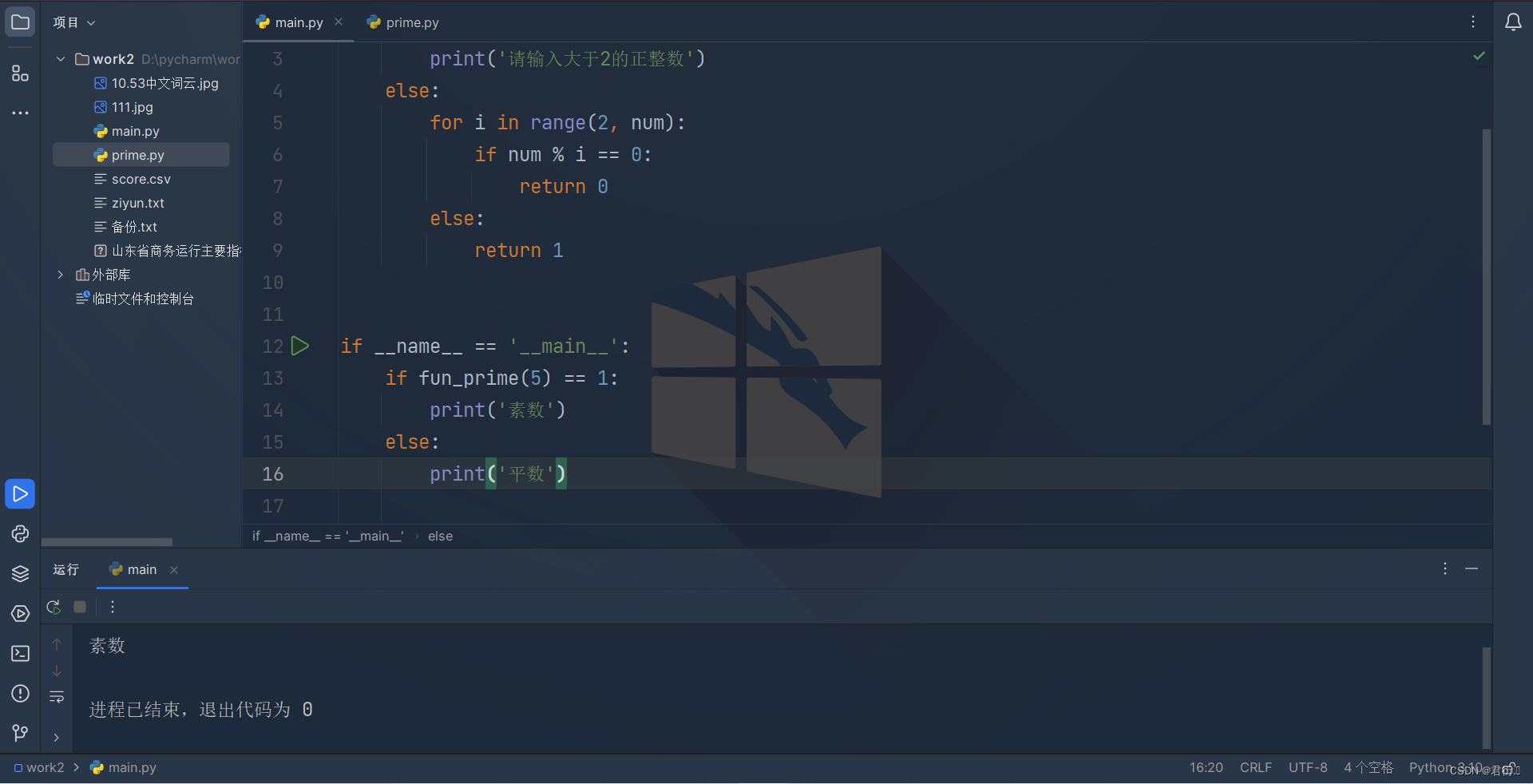
常见内置模块
- 什么是模块?
import XXX ------其中 XXX就是模块 ,自己定义的XX.py文件本质就是模块
打开python的安装包,lib文件下全是模块 - 模块的分类
- 通过模块的创建者
-
- 系统内置模块
uuid、os、math、random均是python官方提供的cpython解释器提供的模块
- 系统内置模块
-
- 第三方模块
程序员、组织、公司 创建的第三方模块,第三方模块需要使用,首先需要安装模块
在线安装(简单方便,这种情况必须有网)
(cmd-----pip install modle_name(如果有问题python -m pip install modle-name))
pip install requests(requests是使用爬虫的,不用安装,只是给大家演示一下)
------安装requests模块,一般会出现进度条,因为我以及安装了,所以会出现“already”,如下图:
离线安装(1,先下载离线安装包xxx.zip 2.解压安装包 3.安装中setup.py4.cmd:python install setup.py)
- 第三方模块
-
- 自定义模块
xxx.py
- 自定义模块
- 模块的导入问题
- import 关键字导入 --------- import math
- import 模块名称 as alias(别名)
- import hashlib as h (给hashlib起别名)
- from 包 import 模块名称 python3强烈推荐这种方法
一、math模块
math主要的作用是数学运算
| 方法 | 说明 |
|---|---|
| ceil | (天花板的意思) 向上取整 |
| floor | 向下取整 注意:四舍五入(全局函数中的round) |
| e | 属性 自然常数 |
| fabs | 求绝对值 等价于全局函数abs() |
| fmod | 求模 |
| isnan | 判断是不是一个数字(是数字返回flase nan—not a number) |
| isfinite | 判断是不是无限 |
| pi | 圆周率 |
| pow() | 幂次方 |
| sqrt | 根号 开平方根 |
- math 模块常量
| 常量 | 描述 |
|---|---|
| math.e | 返回欧拉数 (2.7182…) |
| math.inf | 返回正无穷大浮点数 |
| math.nan | 返回一个浮点值 NaN (not a number) |
| math.pi | π 一般指圆周率。 圆周率 PI (3.1415…) |
| math.tau | 数学常数 τ = 6.283185…,精确到可用精度。Tau 是一个圆周常数,等于 2π,圆的周长与半径之比。 |
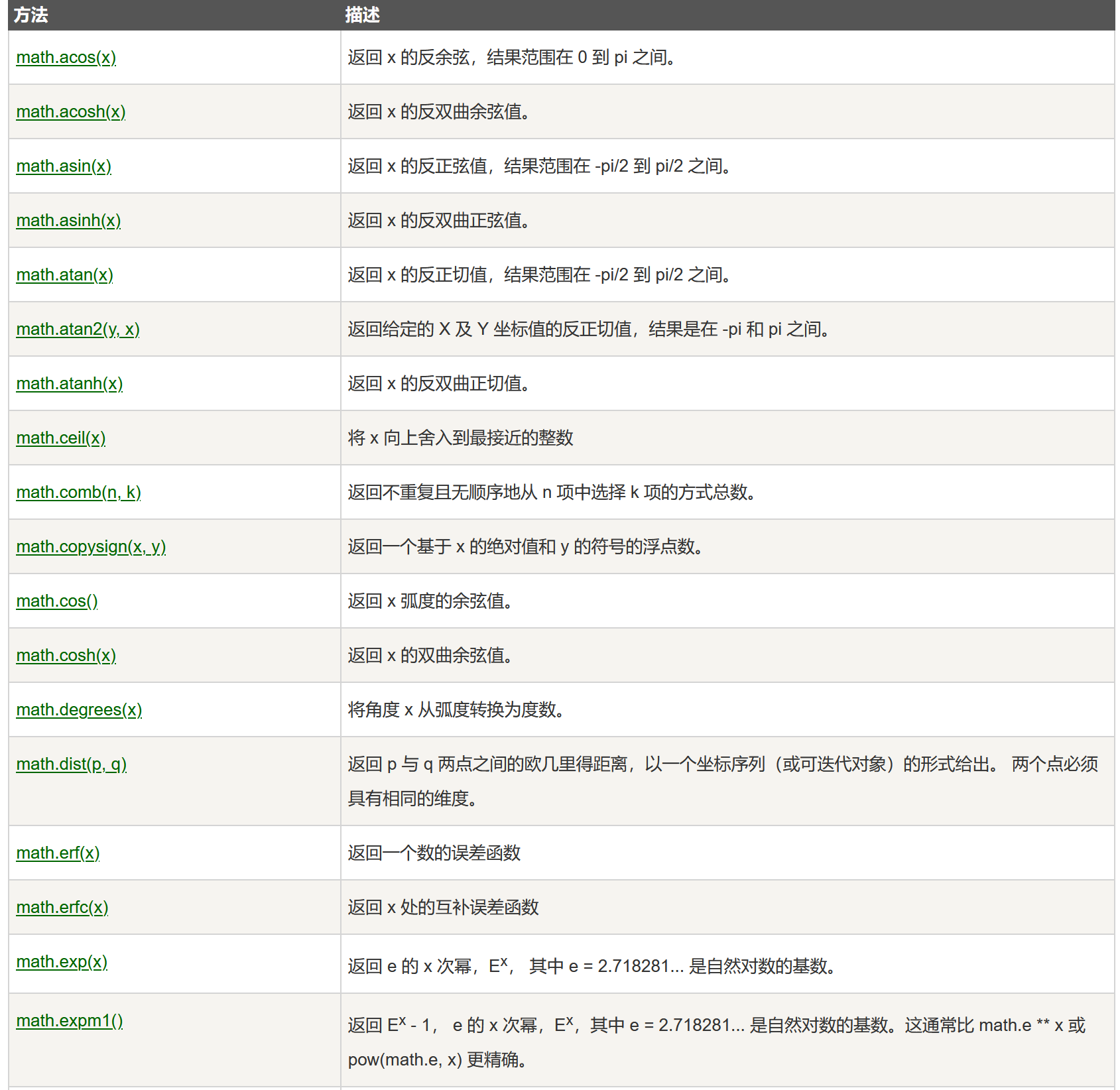
- 常见方法:
二、random模块
该模块主要用来产生随机数(伪随机数,计算机产生不了真正的随机数,是依靠算法来计算的)
| 方法 | 说明 |
|---|---|
| randint() | 产生随机整数[m,n] |
| random() | 产生一个0~1内的随机数[0,1) random.random() 可以乘10取整得到0·9的整数 |
| uniform() | 产生基于正态分布的随机数(一般用不到) |
| range() | 产生一个范围的随机数 |
| choice() | 在序列(有序的,set是无序的)中随机筛选一个元素 ls=[1,2,3,4,5,6,7,8,9] random.choice(ls) s = {1,2,3,4,5,6,7} random.choice(s)-----报错 |
其他的方法,自己调取帮助文档help()自己学习,并且总结
- 查看:
import randomprint(dir(random))
- 例:random() 方法返回一个随机数,它在[半开放区间 [0,1) 范围内,包含 0 但不包含 1
import randomprint(random.random())
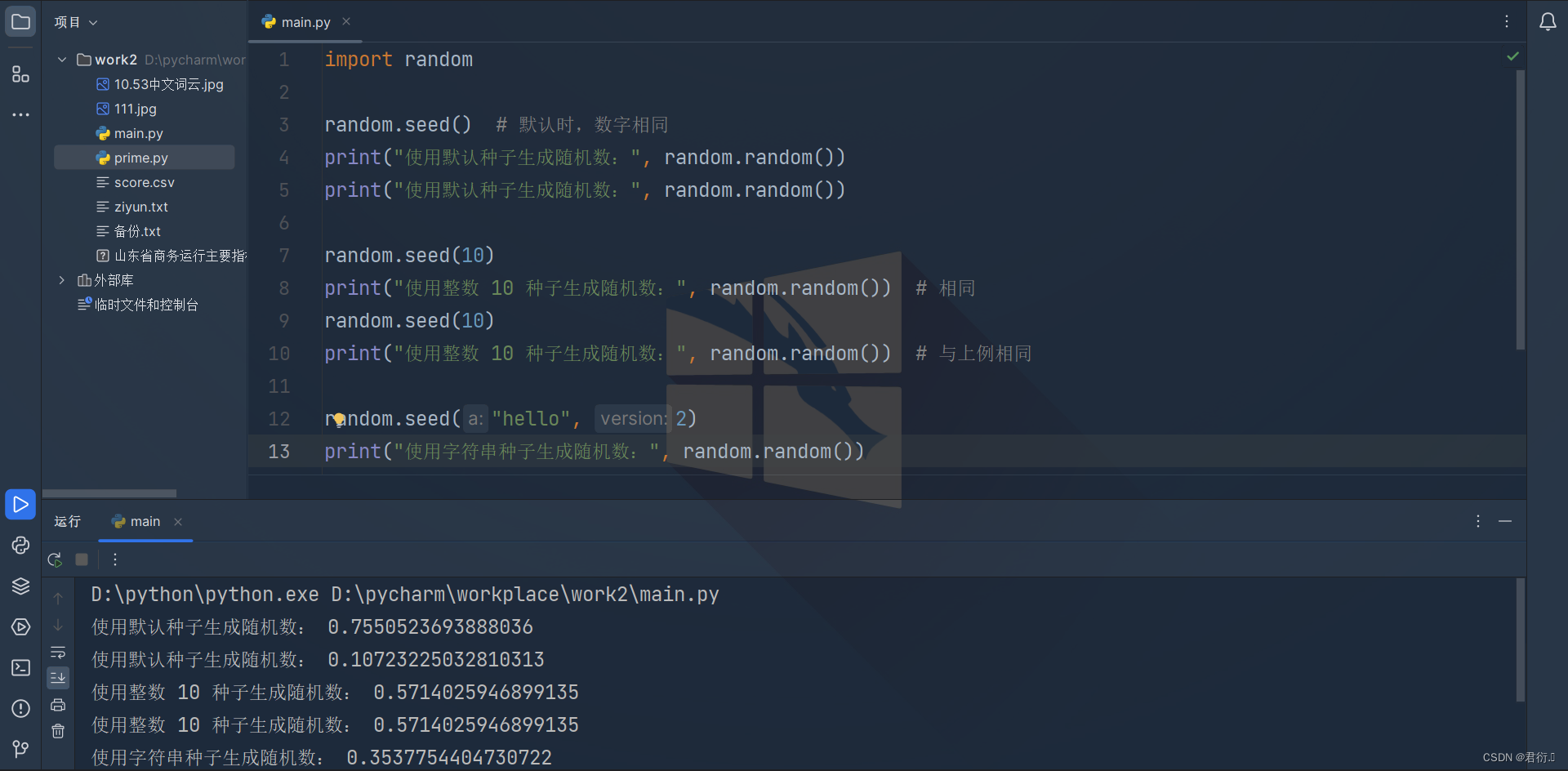
- 例:seed() 方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数
import randomrandom.seed() # 默认时,数字相同
print ("使用默认种子生成随机数:", random.random())
print ("使用默认种子生成随机数:", random.random())random.seed(10)
print ("使用整数 10 种子生成随机数:", random.random()) # 相同
random.seed(10)
print ("使用整数 10 种子生成随机数:", random.random()) # 与上例相同random.seed("hello",2)
print ("使用字符串种子生成随机数:", random.random())
- 常用
- randint(a, b) #返回随机一个整数 N 满足 a <= N <= b
- random.sample(range(0, 20), 20) 返回随机序列
三、OS模块
操作的是系统的文件系统
os.system(“cls”)-----清屏
| 方法 | 说明 |
|---|---|
| chdir(path) | 修改当前工作目录 os.chdir(“c:\”)------os.chdir(“…”) ,一般不会更改 |
| curdir | 获取当前目录 属性 注意返回的是相对路径 (绝对路径os.path.abspath(os.curdir)) |
| chmod() | 修改权限 主要用在linux,help(os.chmod)(不做演示) |
| close | 关闭文件路径(不做演示) |
| cpu_count() | 返回cpu的核对应线程数(2核4线程) |
| getcwd() | 获取当前路径,返回的是绝对路径 ,相当于linux的pwd |
| getpid() | 获取当前进程的进程编号(任务管理器—详细信息) |
| getppid() | 获取当前进程的父进程的进程编号 |
| kill() | 通过进程编号杀死进程(明白就行) |
| linesep | 对应系统下的换行符 |
| listdir() | 返回对应目录下的所有文件及文件夹(隐藏文件也可以调取出来),返回的是列表 |
| makedirs() | 创建目录,支持创建多层目录(文件夹)os.makedirs(“a/b/c/d”) |
| mkdir | 创建目录,只支持一层创建,不能创建多层 |
| open | 创建文件,等价于全局函数open (IO流详细讲) |
| pathsep | 获取环境变量的分隔符 windows ; linux : |
| sep | 路径的分割符 windows \ linux / |
| remove(文件名或者路径) | 删除文件 os.remove(b.text) |
| removedirs() | 移除目录,支持多级删除,递归删除 |
| system | 执行终端命令 |
windows 换行: \r\n
类unix中 换行:\n
-
目录也称为文件夹,用于分层保存文件
-
os模块与操作系统相关,不同的操作系统运行os模块,返回结果不同
import os
print(os.name)
# nt 为windows操作系统,若为posix表示Linux或Mac OSos.system("cls") #清屏
- 路径:定位一个文件或目录的字符串称为路径
- 相对路径:当前目录开始访问
- 绝对路径:文件的实际路径,从盘符号或根(\)开始访问
import os
print(os.getcwd()) # 显示当前工作目录
import os
print(os.path.abspath('test1.py')) # 获取绝对路径
四、os.path模块
先引入Import os 模块,在os模块里面有个很重要的模块path,要注意path是一个子模块,可以通过help(os.path)查看帮助文档
那么此模块的导入方式:先导入os模块,使用dir(os.path);其次可以直接import os.path导入模块;import os.path as p ----------dir§;from os import path
| 方法 | 说明 |
|---|---|
| abspath(相对路径) | 返回路径对应的绝对路径(完整的路径) path.abspath(“.”) |
| altsep | 查看python中的各种符号 |
| basename | 文件名称,shell编程里面也有 path.basename(“路径”) |
| dirname | 文件所在的目录,shell编程里面也有 |
| exists | 判断文件或者目录是否存在(特别有用,使用爬虫爬取数据的时候需要判断是否有这个文件或者文件夹) |
| getctime | 创建时间(不做演示) |
| getmtime | 修改时间(不做演示) |
| getsize | 获取文件的大小,单位是字节 |
| isdir | 判断path是不是目录(文件夹) |
| isfile | 判断path是不是文件 |
| isabs | 判断是不是绝对路径(不演示) |
| islink | 判断是不是连接(不演示) |
| ismount | 判断是不是挂载文件(Linux下要用的)(不演示) |
| join (p1,p2) | 拼接路径 name=“123.txt” url=“C:/a/b/c” url +“/”+name path.jion(url,name) |
| sep | 路径分隔符 url + path.sep +name |
| split | 分割路径 path.split(“C://desktop”) |
| realpath | 返回真实路径 和abspath一样 |
- 判断目录是否存在
- 格式:os.path.exists(path)
- path:要判断的路径,推荐绝对路径
- 存在返回True,否则返回False
import os
print(os.path.exists('c:\demo')) # 判断目录
print(os.path.exists('test1.py')) # 判断文件
- 创建目录
- 创建一级目录:os.mkdir(path)
- 一般用于创建指定路径中最后一级目录,若上级目录不存在则会抛出异常,若已存在目录会抛出异常
- 例:在创建一个c:\demo目录
import os
os.mkdir('c:\\demo') # 注意转义,可在win系统查看
注意:上例再次执行,由于目录已存在会抛出异常,所以一般会和判断目录是否存在的函数一同使用
import ospath = 'c:\\demo'
if not os.path.exists(path):os.mkdir(path)print('目录创建成功')
else:print('目录已存在')
- 创建多级目录:os.makedirs(path)
# 递归方式创建目录
import os
os.makedirs(r'c:\t1\t2\t3') # 可以使用r起到转义符失效的作用
- 例:批量创建20个目录
import os
# 创建20个文件夹
os.mkdir('c:\\python')
for i in range(1, 21):# 如果不存在对应的文件夹,就创建if not os.path.exists('c:\\python\\第{}次课'.format(i)):os.mkdir('c:\\python\\第{}次课'.format(i))
- 删除目录
-
格式:os.rmdir(path)
-
注意:只有当要删除的目录为空时才能删除
-
若删除的目录不存在则会抛出异常,所以一般会和判断目录是否存在的函数一同使用
-
可以使用shutil.rmtree()函数删除不为空的目录
-
删除文件:os.remove(path)
-
import os
os.rmdir(r'c:\demo')
- 文件或目录重命名
- 格式:os.rename(src , dst)
- src:指定需要重命名的文件或目录
- dst:新名称的文件或目录
- 若重命名的目录或文件不存在则会抛出异常,所以一般会和判断目录是否存在的函数一同使用
import os
os.mkdir('c:\\demo')
os.rename('c:\\demo',r'c:\test')
-
获取文件信息
- 获取文件的访问事件、修改时间、大小等信息
- os.stat(path)
-
常见方法汇总:
import osprint(os.name) # nt 表示Windows 系统;'posix’表示Linux系统
print(os.getcwd()) # 显示当前工作路径
print(os.listdir('C:\Windows')) # 显示指定目录下所有的文件和目录
print(os.mkdir('a')) # 生成 单层目录
print(os.path.basename('D:\python\\test1')) # 返回文件名
作业:使用os和os.path以及函数的递归完成:
给出一个路径,遍历当前路径所有的文件及文件夹
打印输出所有的文件(遇到文件输出路径,遇到文件夹继续进文件夹)
import osfrom os import path#定义一个函数(方法)def scanner_file(url):#os.listdir 输入当前路径下所有的文件和文件夹files = os.listdir(url)# print(files) 验证#进行路径拼接 三种方式for f in files:#real_path = url +”\\” +f#real_path = url +os.sep +freal_path = path.jion(url,f)#print(real_path) 得到路径#判断该路径是不是文件或者目录if path.isfile(real_path):print(path.abspath(real_path))#是一个目录elif path.isdir(real_path):#此时是一个文件夹Scanner_file(real_path)else:print(“其他情况”)passScanner _file(“D:\\”) #不建议遍历C盘,会涉及权限的问题
五、sys模块
| 方法 | 说明 |
|---|---|
| api_version | 获取当前python的内部版本号 |
| argv() | 接收脚本参数的,注意第一个参数是脚本名称(javaz中mian函数中有个args) import sys print(sys.argv) ----- python xxx.py 返回的是[“xxx.py”] python xxx.py 1 2 3 hahaha |
| copyright | 输出cpython的版权信息 |
| sys.exit() | 退出系统 |
| getdefaultencoding() | 获取默认编码, 默认是utf-8(python3),python2的编码是根据系统一致 |
| getfilesystemencoding | 获取文件系统的默认编码,默认是utf-8 |
| getrecursionlimit | 获取python对于递归的限制层数 |
| setrecursionlimit(num) | 重新设置递归的限制层数,注意能不用不要用,以免造成其他的问题 |
| getrefcouont(对象) | 获取对象的引用计数,是垃圾回收机制中的引用计数 例如:ls=[1,2,3,4] sys.getrefcouont(ls) ----结果是2 (默认有一个引用计数 加上ls) a = ls sys.getrefcouont(ls) ----结果是3 b=ls 结果是4 |
| getwindowsversion() | 返回窗口的版本信息 |
| verson | 获取版本信息 |
- 例:
import sys
a=2
if a<=2:sys.exit(8)
print(a) # 未执行
#注释:退出python执行程序,下面的代码将不会执行,如同shell中的exit一样。import sys
print(sys.version) # 获取版本信息
import sys# sys.stdin.readline() 相当于input,区别在于input不会读入'\n'
aa = sys.stdin.readline() # 输入数据多一个'\n'
bb = input('请输入:')print(len(aa))
print(len(bb))
import osfrom os import pathimport sys#定义一个函数(方法)def scanner_file(url):#os.listdir 输入当前路径下所有的文件和文件夹files = os.listdir(url)# print(files) 验证#进行路径拼接 三种方式for f in files:#real_path = url +”\\” +f#real_path = url +os.sep +freal_path = path.jion(url,f)#print(real_path) 得到路径#判断该路径是不是文件或者目录if path.isfile(real_path):print(path.abspath(real_path))#是一个目录elif path.isdir(real_path):#此时是一个文件夹Scanner_file(real_path)else:print(“其他情况”)passls = sys.argvif len(ls)<2:print("对不起,这个脚本需要输入参数,参数是需要遍历的磁盘路径")else:Scanner _file(sys.argv[1])运行:python xxx.py D://
python的垃圾回收原理:
引用计数为主,以标记清除和分代收集为辅
java:以标记清除为主,以引用计数和分代收集为辅
六、UUID模块
Uuid模块 -----是一种特殊的技术,在文件上传、文件备份会经常使用
------------- 获取的是永不重负的字符串uuid4().hex
-
概念:UUID: 通用唯一标识符 ( Universally Unique Identifier ),对于所有的UUID它可以保证在空间和时间上的唯一性,它是通过MAC地址、 时间戳、 命名空间、 随机数、 伪随机数来保证生成ID的唯一性,有着固定的大小( 128 bit位 ),通常由 32 字节的字符串(十六进制)表示。
-
python的uuid模块提供的UUID类和函数uuid1(),uuid3(),uuid4(),uuid5() 来生成1, 3, 4, 5各个版本的UUID ( 需要注意的是:python中没有uuid2()这个函数)。
import uuidname = 'test_name'
namespace = uuid.NAMESPACE_DNSa = uuid.uuid1() # 基于时间戳
print(a, type(a))b = uuid.uuid3(namespace, name) # 基于名字的MD5散列值
print(b, type(b))c = uuid.uuid4() # 基于随机数
print(c, type(c))d = uuid.uuid5(namespace, name) # 基于名字的SHA-1散列值
print(d, type(d))
七、时间日期模块
1、time模块
Python提供的一个 time模块来格式化时间,在python爬虫等应用中相当有用
Dir(time)
- Python 提供了一个 time模块来格式化时间,在python爬虫等应用中相当有用
import timet = time.time()
print("当前时间戳为:", t)
localtime = time.localtime()
print("本地时间为 :", localtime) # 时间元组,附表查看
localtime = time.asctime(time.localtime())
print("本地时间为 :", localtime)
# 格式化时间
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))print(time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))

| 方法 | 说明 |
|---|---|
| asctime() | 获取当前时间 |
| ctime() | 获取当前时间 |
| localtime() | 获取本地时间 返回的是对象,方便自己完成格式化 ltiem = time.localtime() ltime.tm_year print(“%s-%s-%s &s:%s:%s”%(ltime.tm_year,ltime.tm_mon,ltime.tm_mday,ltime.tm_hour,ltime.tm_min,ltime.tm_sec)) |
| sleep(1) | 表示休眠时间,单位是秒 |
| time() | 获取当前系统的时间戳,单位是秒(计算机从1970年0时0分0秒到现在秒数) |
| strftime() | 将时间对象格式化为字符串 f—format help(time.strftime) time.strftime(“%Y-%m-%d”) |
| strptime() | 将一个特定格式的时间字符串转换成时间对象 help(time.strptime) s=“2019-08-03 07:35:35” type(s) time.strptime(s,“%Y-%m-%d %H:%M:%S”) |
import timet = time.time()
print("当前时间戳为:", t)
localtime = time.localtime()
print("本地时间为 :", localtime) # 时间元组,附表查看
localtime = time.asctime(time.localtime())
print("本地时间为 :", localtime)
# 格式化时间
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))print(time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
2、datetime模块
对Time模块的补充,用于时间的处理
dir(time)
Datetime子模块:
- 常用类:date 类、time 类、datetime 类、timedelta 类
import datetime as dtx = dt.date(2021, 10, 1) # 年、月、日
y = dt.time(7, 15, 30, 10) # 时、分、秒、微秒
z = dt.datetime(2021, 10, 1, 7, 15, 30) # date类和time类的结合,参数:年、月、日、时、分、秒
d = dt.timedelta(3, 2, 1, 6) # 日、秒、微秒、毫秒,分钟,小时,周星期
print(x, y, z, d)
From datetime import datetime
Dir(datetime)
now()--------------获取当前时间
3、calendar模块
- 常用方法:

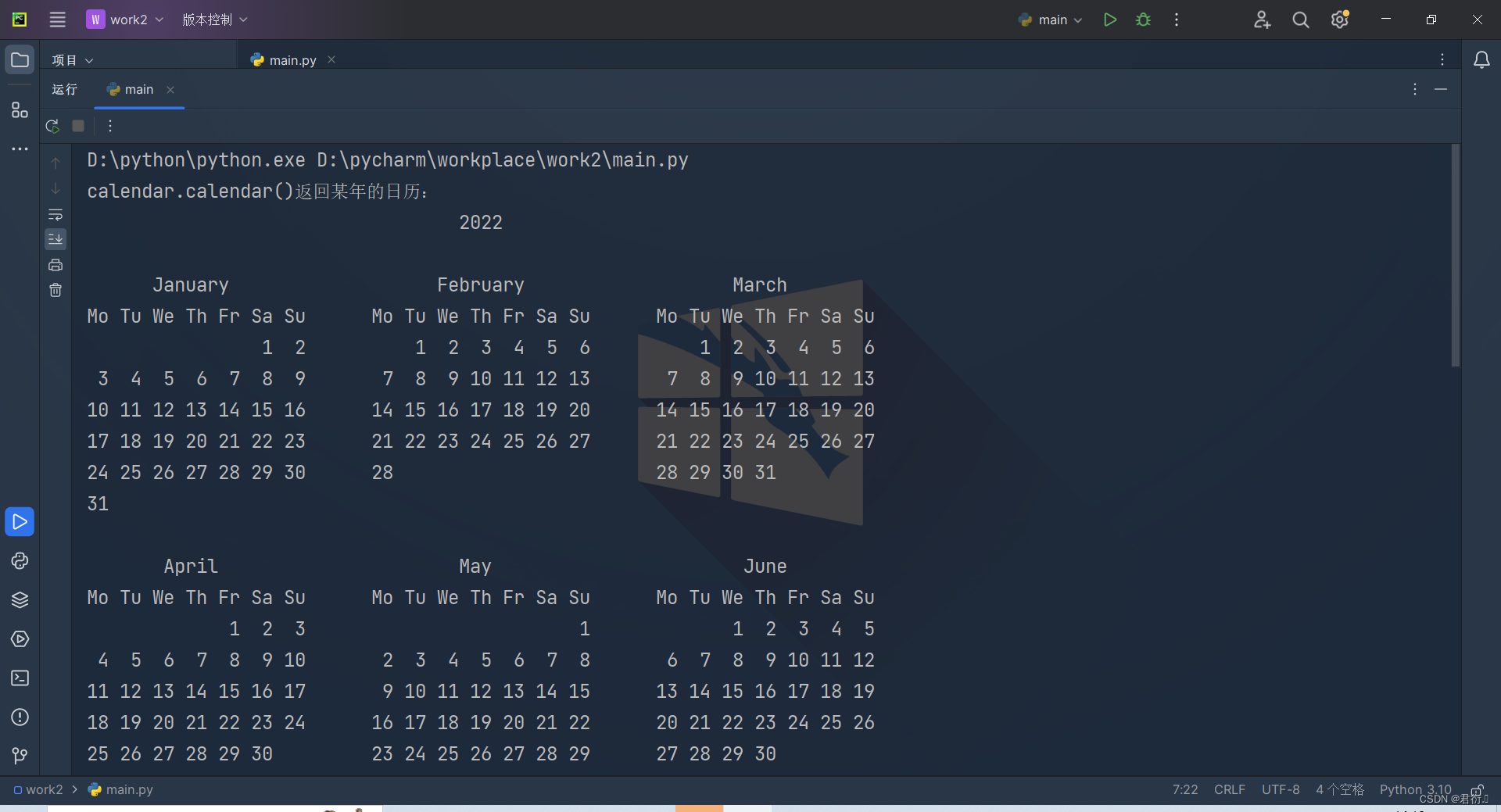
import calendarprint("calendar.calendar()返回某年的日历:")
print(calendar.calendar(2022))print("calendar.month()返回某年某月的日历:")
print(calendar.month(2022, 11))print("calendar.isleap()返回是否是闰年:")
print(calendar.isleap(2020), calendar.isleap(2021))
print("calendar.leapdays()返回两年之间的闰年总数:")
print(calendar.leapdays(2000, 2021))print("calendar.weekday()返回某年某月某日是周几:")
print(calendar.weekday(2022, 11, 23))
八、加密模块
有了解过加密吗?什么地方用到过加密?加密是计算机最重要的计数之一,无论是学习哪一方面,都需要学习加密。
加密算法的分类(须牢记):
- 以算法是否可逆:
-
- 可逆算法
是不是使用用一个密钥:
- 可逆算法
-
-
- 对称加密
解密和加密用的是同一密钥(压缩文件—输入密码(可以暴力破解,百度) 并不是说是右击文件夹对文件夹进行隐藏)
例如:DES算法
- 对称加密
-
-
-
- 不对称加密
加密和解密使用的是一对密钥(公钥、私钥),网络中大部分使用的就是不对称加密,https协议(使用的证书认证,也就是CA认证)(HTTP协议不安全,各种钓鱼网站等信息不安全)
例如: RSA
- 不对称加密
-
-
- 不可逆算法 (hash算法)
特点:不可逆、结果是唯一的
Md5
- 不可逆算法 (hash算法)
1、hashlib
import hashlib
dir(hashlib)
哈希算法
- 1、 注意:hashlib所有的hash操作起来是一样的,就是你学会一个其它的用法都市一样的,只改变名称就可以,但是在Java里就不一样了,每个算法不一样
cmd窗口:md5 = hashlib.md5()
md5 - 2、 使用步骤:
创建算法对象(md5 sha256),返回一个算法对象
注意: 调用MD5的时候一定要给参数,例如:md5 = hashlib.md5("12345"),这个错误不是其他错误,需要接收字节数据不能是字符串md5 = hashlib.md5("12345".encode("utf-8"))
如果不做盐值混淆,直接调用hexdigest() md5.hexdigest()
哈希算法的特点:结果唯一、不可逆,哈希算法是无法反向解密的,安全性特别强,因为结果唯一,可以使用碰撞破解,先把MD5的值存下来,下一次遇到的话就可以破解了
https://cmd5.com/ 这个网站可以对MD5密码解密
在数据校验、安全检查的时候一定不要做盐值混淆(淘宝买东西,订单的10000元可以手动改成1元,所以淘宝会对订单的生成做一个数据校验,价格、数量、时间戳(类似一个随机数)等做一个md5)
在注册账号的时候,需要输入密码和账号存储到数据库中,密码可以铭文存储到数据库吗?不可以,运维人员一定可以看的得到所有人的密码和账号,这样就很不安全,使用密码校验的时候使用的密文校验。 - 3、 盐值混淆
Hash容易碰撞破解,一般建议使用盐值混淆
Md5.update(salt)
md5 = hashlib.md5("12345".encode("utf-8"))
md5.uptate("!@@@@&%hhh".encode("utf-8"))
md5.hexdigest()
2、hmac模块
hmac也是一个哈希加密库,而且用到了对称加密
参数: 第一个参数是要加密的字符串,第二个参数是盐值 ,第三个参数是加密算法
hmac.new("123456".encode("utf-8"),“hahhah”.encode("utf-8),md5)
首先会使用对称加密(密钥就是盐值),之后将加密后的数据再做一次hash加密,盐值混淆,所以整个结果十分安全。
练习:完成用户的登录注册
#完成登录注册案例
import sys
import hashlib
#用来存储所有的用户信息
users = []
slat = "hahha!@@@@%$^"# def password_md5(slat,password):def password_md5(password):md5 = hashlib.md5(password.encode("utf-8"))#盐值混淆md5.update(slat.encode("utf-8"))return md5.hexdigest()
def main():print("~*"*20)print("\t\t 1.用户注册")print("\t\t 2.用户登录")print("\t\t 3.退出系统")print("~*"*20)choice = input("请输入您要操作的选项:")return choice
def register():username = input("请输入你的用户名称:")password = input("请输入你的用户密码:")#保存前要校验数据if username == None or username.strip() == " ":
print("用户名不能为空")
return if password == None or password.strip() == " " or len(password)<3:
print("密码长度不能小于3位")
return #判断用户是否存在?怎么判断?用户名?密码?用户名+密码# for i in users:# if i.get("username") ==username:# print("对不起,该用户已经存在,请请重新输入")# return if exits_user(username):
print("对不起,该用户已经存在,请请重新输入")
return #组建成一个字典对象user = {}user["username"] = username#user["password"] = password#print(user)#密码加密留作业 user["password"] = password_md5(password)users.append(user)#验证print(users)
def exits_user(username):for i in users:
if i.get("username") ==username:#print("对不起,该用户已经存在,请请重新输入")return Truereturn False
def is_login(username,password):for i in users:
if i.get("username") == username and i.get("password")==password:print("登录成功")return Truereturn False
def login():username = input("输入用户名:")password = input("输入用户密码:")#加密密码password = password_md5(password)# for i in users:# if i.get("username") == username and i.get("password")==password:# print("登录成功")# returnif is_login(username,password):
print("恭喜你登录成功")else:
print("对不起,登录失败,请重新登录")
while True:#独立的界面# print("~*"*20)# print("\t\t 1.用户注册")# print("\t\t 2.用户登录")# print("\t\t 3.退出系统")# print("~*"*20)# choice = input("请输入您要操作的选项:")choice = main()if choice == "1":
print("用户注册")
#注册本质是什么?将数据存储下来,第一选择数据库(不学)通过IO技术将数据直接持久化磁盘 存储到内存中(容器 选择哪个容器最合适?list+字典)
register()elif choice == "2":
print("用户登录")
login()else:
print("程序正常退出")
sys.exit()