Spark-06:Spark 共享变量
目录
1.广播变量(broadcast variables)
2.累加器(accumulators)
在分布式计算中,当在集群的多个节点上并行运行函数时,默认情况下,每个任务都会获得函数中使用到的变量的一个副本。如果变量很大,这会导致网络传输占用大量带宽,并且在每个节点上都占用大量内存空间。为了解决这个问题,Spark引入了共享变量的概念。
共享变量允许在多个任务之间共享数据,而不是为每个任务分别复制一份变量。这样可以显著降低网络传输的开销和内存占用。Spark提供了两种类型的共享变量:广播变量(broadcast variables)和累加器(accumulators)。
1.广播变量(broadcast variables)
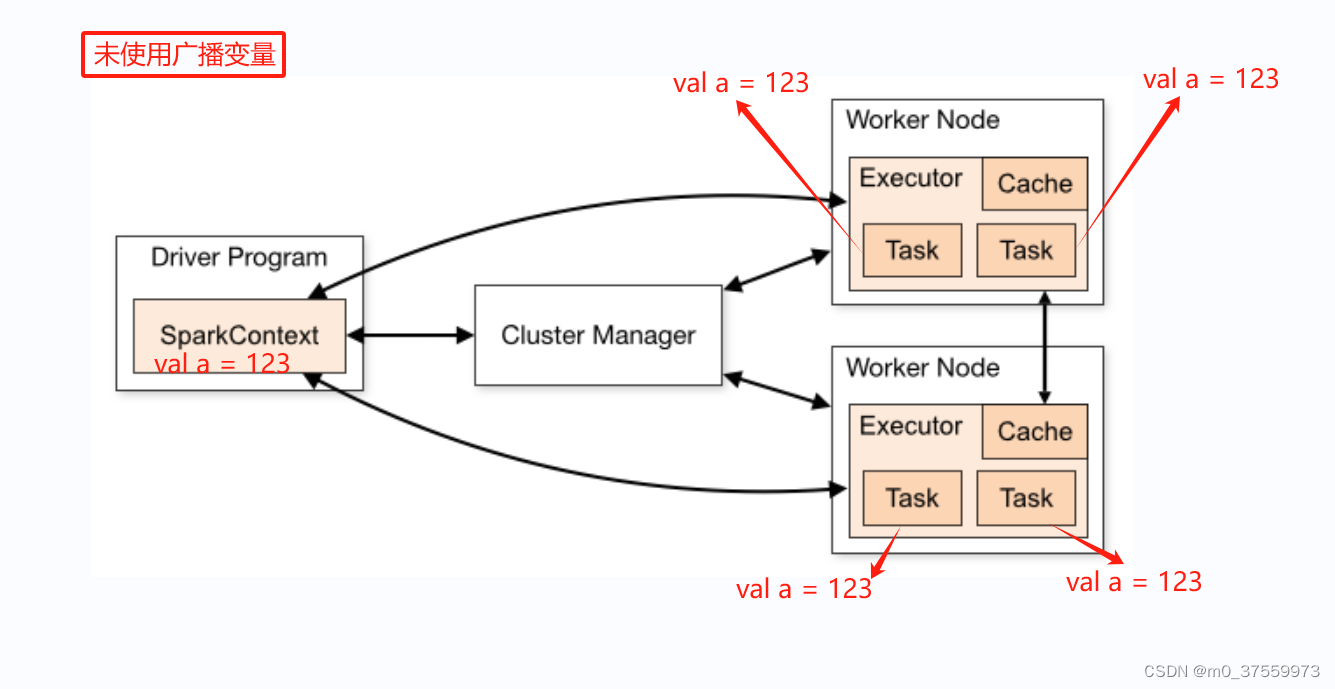
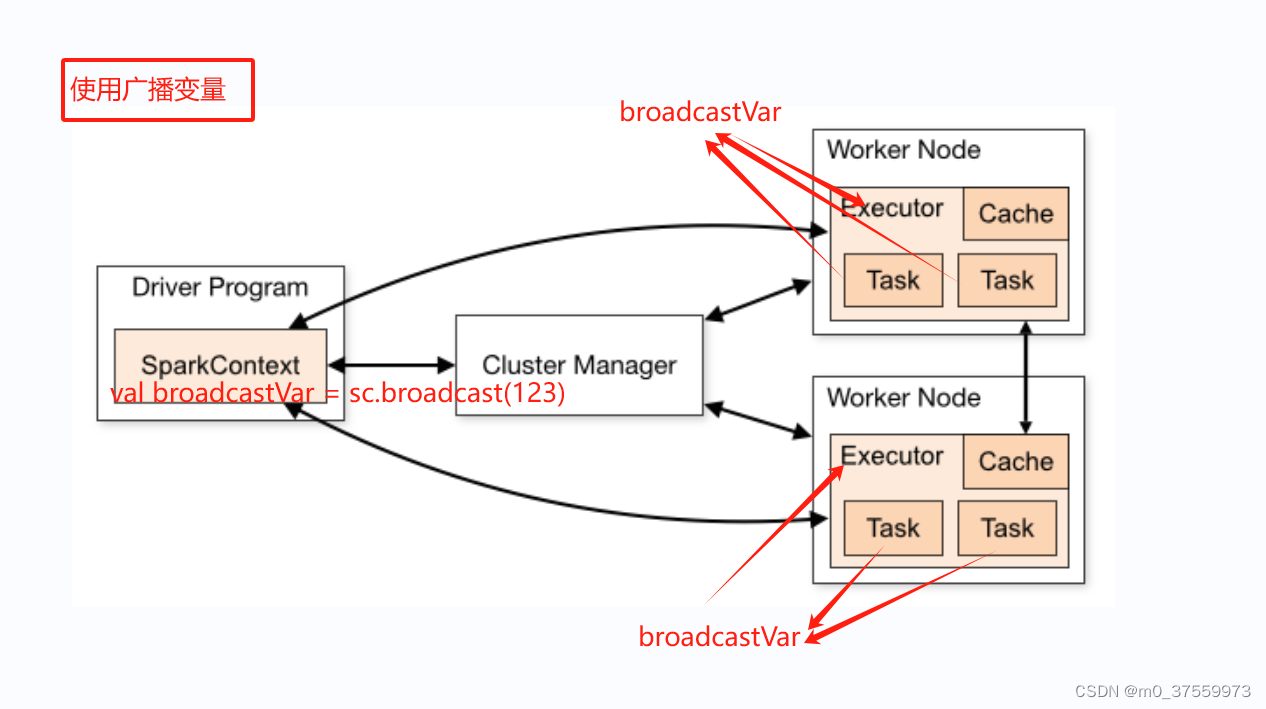
通常情况下,Spark程序运行时,通常会将数据以副本的形式分发到每个执行器(Executor)的任务(Task)中,但当变量较大时,这会导致大量的内存和网络开销。通过使用广播变量,Spark将变量只发送一次到每个节点,并在多个任务之间共享这个副本,从而显著降低了内存占用和网络传输的开销。
Scala 实现:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)Java 实现:
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3});broadcastVar.value();
// returns [1, 2, 3]2.累加器(accumulators)
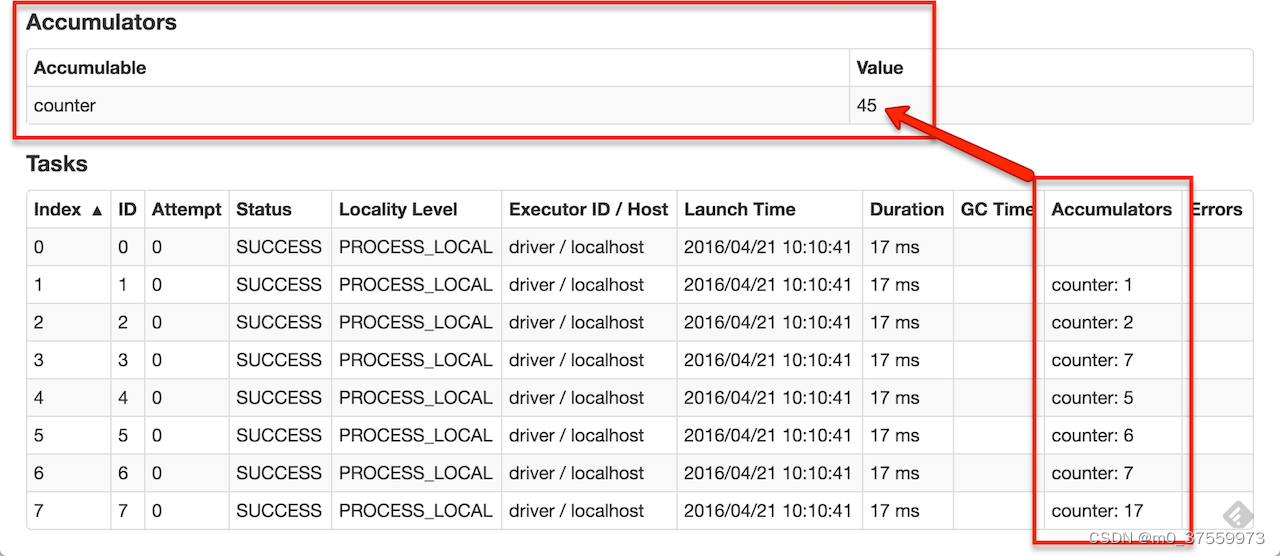
累加器是Spark中的一种特殊类型的共享变量,主要用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。累加器支持的数据类型仅限于数值类型,包括整数和浮点数等。
Scala 实现:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 sscala> accum.value
res2: Long = 10Java 实现:
LongAccumulator accum = jsc.sc().longAccumulator();sc.parallelize(Arrays.asList(1, 2, 3, 4)).foreach(x -> accum.add(x));
// ...
// 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 saccum.value();
// returns 10内置累加器功能有限,但可以通过继承AccumulatorV2来创建自己的类型。AccumulatorV2抽象类有几个方法必须重写:reset用于将累加器重置为零,add用于向累加器中添加另一个值,merge用于将另一个相同类型的累加器合并到此累加器。
自定义累加器Scala实现:
package com.yichenkeji.demo.sparkscalaimport org.apache.spark.util.AccumulatorV2class CustomAccumulator extends AccumulatorV2[Int, Int]{//初始化累加器的值private var sum = 0override def isZero: Boolean = sum == 0override def copy(): AccumulatorV2[Int, Int] = {val newAcc = new CustomAccumulator()newAcc.sum = sumnewAcc}override def reset(): Unit = sum = 0override def add(v: Int): Unit = sum += voverride def merge(other: AccumulatorV2[Int, Int]): Unit = sum += other.valueoverride def value: Int = sum
}
自定义累加器Java实现:
package com.yichenkeji.demo.sparkjava;import org.apache.spark.util.AccumulatorV2;public class CustomAccumulator extends AccumulatorV2<Integer, Integer> {// 初始化累加器的值private Integer sum = 0;@Overridepublic boolean isZero() {return sum == 0;}@Overridepublic AccumulatorV2<Integer, Integer> copy() {CustomAccumulator customAccumulator = new CustomAccumulator();customAccumulator.sum = this.sum;return customAccumulator;}@Overridepublic void reset() {this.sum = 0;}@Overridepublic void add(Integer v) {this.sum += v;}@Overridepublic void merge(AccumulatorV2<Integer, Integer> other) {this.sum += ((CustomAccumulator) other).sum;}@Overridepublic Integer value() {return sum;}
}
自定义累加器的使用:
package com.yichenkeji.demo.sparkjava;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;import java.util.Arrays;
import java.util.List;public class AccumulatorTest {public static void main(String[] args) {//1.初始化SparkContext对象SparkConf sparkConf = new SparkConf().setAppName("Spark Java").setMaster("local[*]");JavaSparkContext sc = new JavaSparkContext(sparkConf);CustomAccumulator customAccumulator = new CustomAccumulator();//注册自定义累加器才能使用sc.sc().register(customAccumulator);sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).foreach(x -> customAccumulator.add(x));System.out.println(customAccumulator.value());//5.停止SparkContextsc.stop();}
}