Azure反模式——全部数据持久化
将应用程序的所有数据放入单一数据存储可能会降低整体性能,原因是这会导致资源争用发生的概率提高,或数据存储不适用于某些数据。
问题描述
一直以来,不管应用程序需要存储哪些不同类型的数据,往往只使用单一数据存储。这样做的原因通常是为了简化应用程序而设计,或者受限于开发团队的专业技能。
基于云环境的系统往往附带其他功能性和非功能性要求,需要存储许多异构类型的数据,例如文档、图像、缓存数据、排队消息、应用程序日志和遥测数据。遵循传统方法将所有这些信息放入同一个数据存储可能会损害性能,主要原因有两个:
在同一个数据存储中存储和检索大量不相关数据可能会导致资源争用,从而导致响应时间的增加和连接失败。
不管选择哪种数据存储,它都不一定适合所有类型的数据,或者未针对应用程序执行的操作进行优化。以下示例演示了一个向数据库添加新记录,并将结果记录到日志的ASP.NET WebAPI Controller。日志与业务数据保存在同一个数据库中。
可在此处找到完整示例。(https://github.com/mspnp/performance-optimization/tree/master/MonolithicPersistence)
日志记录的生成速率可能会影响业务操作的性能。如果另一个组件(例如应用程序进程监视器)定期读取和处理日志数据,则它们也可能会影响业务操作。
解决方案
根据数据的应用场景来隔离数据。对于每种数据集,选择最符合数据集用法的数据存储方式。在前面的示例中,应用程序应将日志记录与业务数据分开存:
注意事项
根据数据的使用方式及其访问方式隔离数据。例如,不要将日志信息和业务数据存在同一数据存储中。这些数据类型的要求和访问模式明显不同。日志记录天生是连续的,而业务数据更有可能需要随机访问,因此通常是关系型的。
考虑每种数据类型的数据访问形式。例如,将带有格式的报告和文档存储在CosmosDB(https://azure.microsoft.com/en-us/services/cosmos-db/)等文档数据库中,但使用AzureRedis(https://docs.microsoft.com/en-us/azure/redis-cache/)缓存来保存临时数据。
如果遵循了这些指导原则,依然达到了数据库瓶颈,可能需要纵向扩展数据库。此外,也可以横向扩展,并将负载分区到不同数据库服务器。但是,分区可能需要重新设计应用。有关详细信息,请参阅数据分区指南。(https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning)
如何检测问题
随着系统耗尽数据库连接等资源,系统的运行速度可能明显下降并最终发生故障。
可执行以下步骤来帮助确定问题的原因。
系统需要记录关键的性能统计信息。为每种操作的计时信息进行记录,以及应用程序读写数据的位置。
如果可能,在生产环境中监视运行了几天的系统,以获得有关系统使用方式的真实数据。如果无法进行这种监视,请配合实际数量的虚拟用户(这些用户执行一系列典型操作)通过运行脚本进行负载测试。
使用遥测数据来识别性能不佳的时段。
识别在这些时段内访问了哪些数据存储。
识别可能发生争用的数据存储资源。
诊断示例
以下部分演示如何将这些步骤应用到前面所述的示例应用程序。
检测和监视系统
下图显示了对上述示例应用程序执行负载测试的结果。该测试使用了1000个并发用户的阶跃负载。
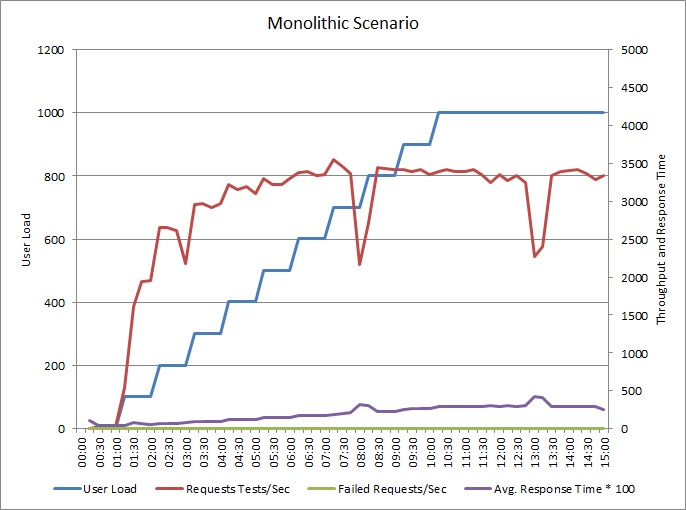
随着负载提高到700,吞吐量随之上升。但此时,吞吐量保持稳定,系统似乎以最大的容量运行着。平均响应时间随用户负载的提高而逐渐增加,表明系统已经无法跟上需求。
识别性能不佳的时段
监视生产环境的系统时,可能会看到一些模式。例如,响应时间在每天的相同时段明显下降。这可能是定期工作负荷或计划的批处理作业造成的,或只是因为系统在某些时候需要处理更多用户请求。应该重点关注这些事件的遥测数据。
找出响应时间增加与数据库活动增加或对共享资源发出的I/O请求增加之间的关系。如果存在关联,则意味着数据库可能就是瓶颈。
识别在这些时段内访问了哪些数据存储
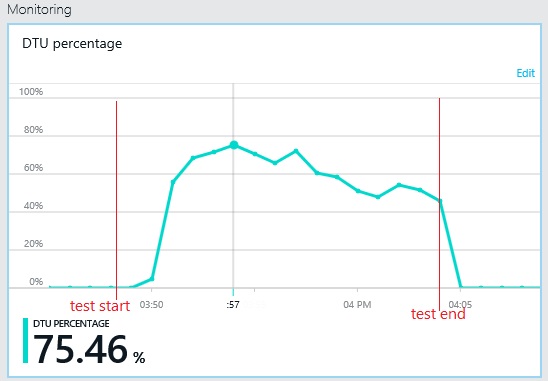
下图显示了负载测试期间数据库吞吐量单位(DTU)的利用率。(DTU用于度量可用容量,是CPU利用率、内存分配和I/O速率的组合。)DTU利用率很快达到100%。这大概就是上图中出现吞吐量峰值的位置。在测试完成之前,数据库利用率一直很高。在测试快要结束时略微下降,原因可能是实施了限流、数据库连接发生争用或其他因素。

检查数据存储的遥测数据
检测数据存储中的详细活动日志。在示例应用程序中,数据访问统计信息显示出对PurchaseOrderHeader表和MonoLog表执行了大量的插入操作。

识别资源争用情况
此时可以检查源代码,并重点检查应用程序在哪些位置访问了争用的资源。找到如下情况:
正在将逻辑隔离的数据写入相同的存储。日志、报告和排队消息等数据不应保存在业务数据库中。
所选数据存储与数据类型(例如关系型数据库中的大型Blob或XML文档)之间不匹配。
具有明显不同使用模式的数据共享同一个存储,例如将高写入/低读出数据与低写入/高读出数据存在一起。
实施解决方案并验证结果
应用程序已更改为将日志写入独立的数据存储。下面是负载测试结果:
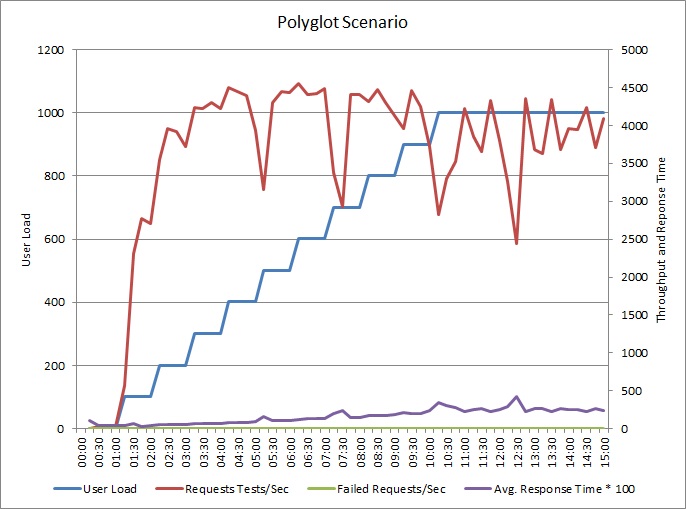
吞吐量类似于前面的图形,但性能峰值位置出现在每秒大约500个或更多请求时。平均响应时间也略微下降。但是,这些统计信息不能反映整体形式。业务数据库的遥测数据显示,DTU利用率峰值大约为75%而不是100%。
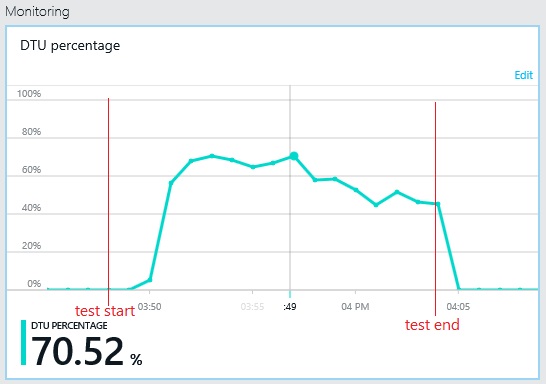
类似的,日志数据库的最大DTU利用率只达到了大约70%。数据库不再是系统性能的瓶颈。
相关资源
选择适当的数据存储(https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview)
有关选择数据存储的准则(https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-comparison)
构建高度可伸缩的数据访问解决方案:使用SQL、NoSQL和Polyglot数据持久化(https://msdn.microsoft.com/library/dn271399.aspx)
数据分区指南(https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning)
问题描述
一直以来,不管应用程序需要存储哪些不同类型的数据,往往只使用单一数据存储。这样做的原因通常是为了简化应用程序而设计,或者受限于开发团队的专业技能。
基于云环境的系统往往附带其他功能性和非功能性要求,需要存储许多异构类型的数据,例如文档、图像、缓存数据、排队消息、应用程序日志和遥测数据。遵循传统方法将所有这些信息放入同一个数据存储可能会损害性能,主要原因有两个:
在同一个数据存储中存储和检索大量不相关数据可能会导致资源争用,从而导致响应时间的增加和连接失败。
不管选择哪种数据存储,它都不一定适合所有类型的数据,或者未针对应用程序执行的操作进行优化。以下示例演示了一个向数据库添加新记录,并将结果记录到日志的ASP.NET WebAPI Controller。日志与业务数据保存在同一个数据库中。
可在此处找到完整示例。(https://github.com/mspnp/performance-optimization/tree/master/MonolithicPersistence)
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}日志记录的生成速率可能会影响业务操作的性能。如果另一个组件(例如应用程序进程监视器)定期读取和处理日志数据,则它们也可能会影响业务操作。
解决方案
根据数据的应用场景来隔离数据。对于每种数据集,选择最符合数据集用法的数据存储方式。在前面的示例中,应用程序应将日志记录与业务数据分开存:
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}注意事项
根据数据的使用方式及其访问方式隔离数据。例如,不要将日志信息和业务数据存在同一数据存储中。这些数据类型的要求和访问模式明显不同。日志记录天生是连续的,而业务数据更有可能需要随机访问,因此通常是关系型的。
考虑每种数据类型的数据访问形式。例如,将带有格式的报告和文档存储在CosmosDB(https://azure.microsoft.com/en-us/services/cosmos-db/)等文档数据库中,但使用AzureRedis(https://docs.microsoft.com/en-us/azure/redis-cache/)缓存来保存临时数据。
如果遵循了这些指导原则,依然达到了数据库瓶颈,可能需要纵向扩展数据库。此外,也可以横向扩展,并将负载分区到不同数据库服务器。但是,分区可能需要重新设计应用。有关详细信息,请参阅数据分区指南。(https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning)
如何检测问题
随着系统耗尽数据库连接等资源,系统的运行速度可能明显下降并最终发生故障。
可执行以下步骤来帮助确定问题的原因。
系统需要记录关键的性能统计信息。为每种操作的计时信息进行记录,以及应用程序读写数据的位置。
如果可能,在生产环境中监视运行了几天的系统,以获得有关系统使用方式的真实数据。如果无法进行这种监视,请配合实际数量的虚拟用户(这些用户执行一系列典型操作)通过运行脚本进行负载测试。
使用遥测数据来识别性能不佳的时段。
识别在这些时段内访问了哪些数据存储。
识别可能发生争用的数据存储资源。
诊断示例
以下部分演示如何将这些步骤应用到前面所述的示例应用程序。
检测和监视系统
下图显示了对上述示例应用程序执行负载测试的结果。该测试使用了1000个并发用户的阶跃负载。
随着负载提高到700,吞吐量随之上升。但此时,吞吐量保持稳定,系统似乎以最大的容量运行着。平均响应时间随用户负载的提高而逐渐增加,表明系统已经无法跟上需求。
识别性能不佳的时段
监视生产环境的系统时,可能会看到一些模式。例如,响应时间在每天的相同时段明显下降。这可能是定期工作负荷或计划的批处理作业造成的,或只是因为系统在某些时候需要处理更多用户请求。应该重点关注这些事件的遥测数据。
找出响应时间增加与数据库活动增加或对共享资源发出的I/O请求增加之间的关系。如果存在关联,则意味着数据库可能就是瓶颈。
识别在这些时段内访问了哪些数据存储
下图显示了负载测试期间数据库吞吐量单位(DTU)的利用率。(DTU用于度量可用容量,是CPU利用率、内存分配和I/O速率的组合。)DTU利用率很快达到100%。这大概就是上图中出现吞吐量峰值的位置。在测试完成之前,数据库利用率一直很高。在测试快要结束时略微下降,原因可能是实施了限流、数据库连接发生争用或其他因素。
检查数据存储的遥测数据
检测数据存储中的详细活动日志。在示例应用程序中,数据访问统计信息显示出对PurchaseOrderHeader表和MonoLog表执行了大量的插入操作。
识别资源争用情况
此时可以检查源代码,并重点检查应用程序在哪些位置访问了争用的资源。找到如下情况:
正在将逻辑隔离的数据写入相同的存储。日志、报告和排队消息等数据不应保存在业务数据库中。
所选数据存储与数据类型(例如关系型数据库中的大型Blob或XML文档)之间不匹配。
具有明显不同使用模式的数据共享同一个存储,例如将高写入/低读出数据与低写入/高读出数据存在一起。
实施解决方案并验证结果
应用程序已更改为将日志写入独立的数据存储。下面是负载测试结果:
吞吐量类似于前面的图形,但性能峰值位置出现在每秒大约500个或更多请求时。平均响应时间也略微下降。但是,这些统计信息不能反映整体形式。业务数据库的遥测数据显示,DTU利用率峰值大约为75%而不是100%。
类似的,日志数据库的最大DTU利用率只达到了大约70%。数据库不再是系统性能的瓶颈。
相关资源
选择适当的数据存储(https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview)
有关选择数据存储的准则(https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-comparison)
构建高度可伸缩的数据访问解决方案:使用SQL、NoSQL和Polyglot数据持久化(https://msdn.microsoft.com/library/dn271399.aspx)
数据分区指南(https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning)