Azure 设计模式之资源整合
资源整合模式
将多个任务或操作合并到一个计算单元中以提高计算资源利用率,并降低在云托管应用程序中的计算成本和管理开销。
问题背景
云应用程序通常用于实现各种操作。在某些解决方案中,遵循关注点分离的设计原则是有意义的,并将这些操作划分为独立的计算单元,可独立运行和部署(例如,分离出独立的web应用,虚拟机或webRole)。但是,即使这样可以帮助简化解决方案的逻辑设计,部署大量计算单元会导致运行时托管成本的增加,使系统管理变得更加复杂。
例如,该图显示了使用多个计算单元实现的云托管解决方案的简化结构。每个计算单元都在其自己的虚拟环境中运行。每个函数都作为独立的任务(通过任务E标记任务a)实现,并在其自己的计算单元中运行。
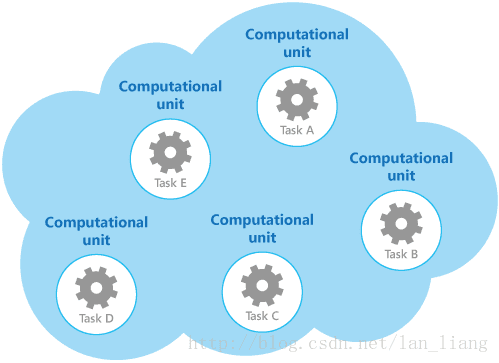
每个计算单元都使用可计费的资源, 即使它是闲置的或轻的。因此, 这并不总是最 cost-effective 的解决方案。
在 Azure 中, 此问题适用于云服务、应用程序服务和虚拟机中的角色。这些项目在它们自己的虚拟环境中运行。运行单独的角色、网站或虚拟机的集合, 这些功能旨在执行一组定义良好的操作, 但作为单个解决方案的一部分需要进行通信和合作, 这可能是资源的低效使用。
解决方案
为了帮助降低成本、提高利用率、提高通信速度并减少管理开销,可以将多任务或操作合并到一个计算单元中。
根据当前环境所提供的功能以及其相关成本,对任务进行分组。一种常见的方法是将伸缩性、生存期和处理要求有关的任务分为一组。将其组合在一起作为同一个单元进行伸缩。许多云环境提供的弹性机制使得计算单元实例能够根据工作负载自动启动和停止。例如,Azure提供了可应用于云服务、应用程序服务和虚拟机的自动伸缩机制。有关详细信息,请参阅自动伸缩。(https://docs.microsoft.com/en-us/azure/architecture/best-practices/auto-scaling)
下面以计数器程序为例, 演示如何使用可伸缩性来确定哪些操作不应该组合在一起, 请考虑以下任务:
任务1:对发送到队列的消息进行轮询,频率不高,不需要实时。
任务2:处理网络通信的高并发。
第二个任务需要是使用azure弹性机制,自动启动或停止计算单元的大量实例。如果对第一个任务应用相同的缩放, 只会导致更多的任务侦听同一队列中的不常见消息, 并且是资源的浪费。
在许多云环境中,可以设定CPU,内核、内存、磁盘空间等资源类型的数量来配置计算单元可用的资源。指定的资源越多,成本就越高。为了节省成本,就是要在昂贵计算单位的执行以后,将其工作内容最大化,而不是长时间让其处于闲置状态。
例如,有些任务在短时间内都需要大量的CPU,考虑将它们合并到一个计算单元中。并且要确保计算资源在保持被充分利用的同时,过度负载时有相应的负载均衡机制。而对于长运行的任务与计算任务较大的任务就不应该分在同一个计算单元中。
问题和注意事项
实现这个模式时, 请考虑以下几点:
伸缩性和弹性。许多云解决方案通过启动和停止单元实例来实现计算单元的可伸缩性和弹性。应避免在同一计算单元中出现对具有可伸缩性要求有冲突的任务。
生命周期。云基础结构周期性地回收计算单元的虚拟环境。当计算单元中有许多长时间的运行任务时,可能需要对其进行配置以防止被自动回收。或者通过使用检查点方法来设计任务,使它们能够干净的停止,并在重新启动时,从计算单元时中断的位置继续执行。
修改频率。如果任务或配置频繁更改,则可能需要停止计算单元,重新配置和并重部署该单元,然后重启。还需要停止、重新部署并重启同一计算单元中的所有任务。
安全性。同一计算单元中的任务可能共享相同的安全上下文,并且能够访问相同的资源。在任务之间必须有高度的信任度,并且一个任务不会对另一个产生负面影响。此外,增加计算单元中运行的任务数也会增加单元被攻击的概率。总体安全性等同于最“弱”的那个任务。
容错性。如果计算单元中的一个任务出现故障或行为异常,则会影响在同一单元中运行的其他任务。例如,如果一个任务无法正确启动, 则会导致计算单元的整个启动失败, 并导致同一单元中的其他任务无法运行。
资源竞争。避免在同一个计算单元中的任务之间出现资源争用。理想情况下,共享同一计算单元的任务应具有不同的资源利用率。例如,两个计算密集型任务不应驻留在同一计算单元中,两个任务都占用大量内存不应在同一计算单元。但是将计算密集型任务与占用大量内存的任务混合使用是一个可行的。
注意事项
考虑将计算资源合并为一个在生产中运行的系统,以便操作员和开发人员可以监控并创建一个热映射,以标识每个任务的资源使用情况。进而确定哪些任务是共享计算资源的候选项。
复杂性。将多个任务合并到单个计算单元中会增加该单元中代码的复杂性,可能使测试、调试和维护变得更加困难。因此需要使得每个任务中的代码设计与环境解耦,即使任务的物理环境发生了变化代码逻辑也不受影响。
其他策略。合并计算资源只是帮助降低同时运行多任务成本的一种方法。需要仔细的规划和监测,以确保它是一种有效的办法。其他策略可能更合适,具体取决于工作的性质以及这些任务运行的用户所在位置。例如,根据功能分配来进行负载分解(如计算分区指南所述https://msdn.microsoft.com/library/dn589773.aspx)可能是更好的选择。
何时使用此模式
如果任务在其自己的计算单元中运行,可以使用这个模式来改善开销大的任务花费。如果任务的闲置时间很长,则在特殊计算单元中运行此任务可能会很昂贵。此模式不适用于比较关键的,容错高的任务,或处理高度敏感以及私有数据的任务,这些需要知道它们的安全上下文。这些任务应该在各自独立的环境中运行,即在单独的计算单元中。
例子
在Azure上构建云服务时,可以将由多任务执行的处理合并为单一角色。通常,这是一个执行后台或异步处理任务的workerRole。在某些情况下,可以在webRole中包含后台或异步处理任务。有助于降低成本并简化部署,尽管它会影响webRole提供的面向公共接口的可伸缩性和响应性。将多个workerRole合并到azureWebRole中的文章(http://www.31a2ba2a-b718-11dc-8314-0800200c9a66.com/2012/02/combining-multiple-azure-worker-roles.html)中包含了实现背景的详细说明和webRole中的异步处理任务。
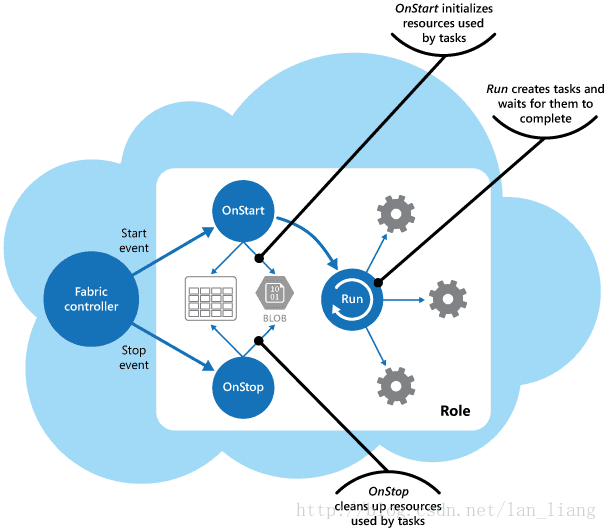
Role负责启动和停止任务。当AzureFabric控制器加载Role时,它将触发Role的Start事件。你可以重写WebRole或WorkerRole类的OnStart方法,要在这个方法中初始化任务所依赖的数据和其他资源。
当 OnStart方法执行完毕, Role开始响应请求。您可以在应用程序启动过程中的Role部分中找到具体细节(https://msdn.microsoft.com/library/ff803371.aspx#sec16)还有模式和实践中讲述如何将应用程序移到云的部分(https://msdn.microsoft.com/library/ff728592.aspx)
保持OnStart方法中的代码尽可能简洁。Azure对此方法完成所花费的时间没有任何限制,但在此方法完成之前,Role无法响应发送给它的任何请求。
当OnStart方法完成时,Run方法被执行。此时,结构控制器可以开始向Role发送请求。
将实际创建任务的代码放在Run方法中。注意,Run方法定义了Role实例的生命周期。当此方法完成时,结构控制器将安排Role关闭。
当Role关闭或被回收时,结构控制器会阻止从负载均衡器接收请求,并引发Stop事件。可以通过重写Role的OnStop方法来捕获此事件,并在Role终止之前执行所需的任何清理操作。
在OnStop方法中执行的任何操作都必须在五分钟内完成(如果在本地计算机上使用Azure模拟器,则为30秒)。否则,Azure结构控制器将假定Role已停止并将其强制停止。
任务由等待任务完成的Run方法启动。这些任务实现了云服务的业务逻辑,并可通过Azure负载均衡器响应路由到Role的消息。该图显示了Azure云服务中Role中任务和资源的生命周期。
ComputeResourceConsolidation.Worker项目中的WorkerRole.cs文件中说明了如何在Azure云服务中实现此模式。
ComputeResourceConsolidation.Worker项目可从GitHub下载,是ComputeResourceConsolidation解决方案的一部分(https://github.com/mspnp/cloud-design-patterns/tree/master/compute-resource-consolidation)。
MyWorkerTask1和MyWorkerTask2方法说明了如何在同一个Role中执行不同的任务。以下代码显示了MyWorkerTask1是一个简单的任务,休眠30秒,然后输出一个消息。它重复这个过程直到任务被取消。MyWorkerTask2中的代码逻辑也类似。
示例代码是后台进程常见的实现方式。在应用程序中,可以遵循相同的结构,只是应该将自己的逻辑放在等待取消请求的循环体中。
在workerRole初始化它所使用的资源之后,Run方法将同时启动两个任务,如下所示。
在这个例子中,Run方法等待任务完成。如果任务被取消,则Run方法假定Role正在关闭,并在完成之前等待剩余的任务被取消(终止之前最多等待5分钟)。如果某个任务由于异常而失败,则Run方法将取消该任务。
你可以在Run方法中写更全面的监视和异常处理逻辑,例如重启失败的任务,或包含使Role停止并启动单个任务的代码。
当结构控制器关闭Role实例(它是从OnStop方法调用的)时,将调用以下代码中的Stop方法。通过取消来停止每个任务。如果任何任务超过五分钟,则Stop方法中的取消将停止等待并且Role被终止。
相关的模式和指导
实施这种模式时,以下模式和指导可能也是相关的:
自动伸缩(https://docs.microsoft.com/zh-cn/azure/architecture/best-practices/auto-scaling)。自动伸缩可用于启动和停止托管资源的实例,具体取决于处理需求。
计算分区指南(https://msdn.microsoft.com/library/dn589773.aspx)。介绍如何在云服务中分配服务和组件,以便在维持服务的可伸缩性,性能,可用性和安全性的同时最大限度地降低运营成本。
示例程序可以在这里下载(https://github.com/mspnp/cloud-design-patterns/tree/master/compute-resource-consolidation)
将多个任务或操作合并到一个计算单元中以提高计算资源利用率,并降低在云托管应用程序中的计算成本和管理开销。
问题背景
云应用程序通常用于实现各种操作。在某些解决方案中,遵循关注点分离的设计原则是有意义的,并将这些操作划分为独立的计算单元,可独立运行和部署(例如,分离出独立的web应用,虚拟机或webRole)。但是,即使这样可以帮助简化解决方案的逻辑设计,部署大量计算单元会导致运行时托管成本的增加,使系统管理变得更加复杂。
例如,该图显示了使用多个计算单元实现的云托管解决方案的简化结构。每个计算单元都在其自己的虚拟环境中运行。每个函数都作为独立的任务(通过任务E标记任务a)实现,并在其自己的计算单元中运行。
每个计算单元都使用可计费的资源, 即使它是闲置的或轻的。因此, 这并不总是最 cost-effective 的解决方案。
在 Azure 中, 此问题适用于云服务、应用程序服务和虚拟机中的角色。这些项目在它们自己的虚拟环境中运行。运行单独的角色、网站或虚拟机的集合, 这些功能旨在执行一组定义良好的操作, 但作为单个解决方案的一部分需要进行通信和合作, 这可能是资源的低效使用。
解决方案
为了帮助降低成本、提高利用率、提高通信速度并减少管理开销,可以将多任务或操作合并到一个计算单元中。
根据当前环境所提供的功能以及其相关成本,对任务进行分组。一种常见的方法是将伸缩性、生存期和处理要求有关的任务分为一组。将其组合在一起作为同一个单元进行伸缩。许多云环境提供的弹性机制使得计算单元实例能够根据工作负载自动启动和停止。例如,Azure提供了可应用于云服务、应用程序服务和虚拟机的自动伸缩机制。有关详细信息,请参阅自动伸缩。(https://docs.microsoft.com/en-us/azure/architecture/best-practices/auto-scaling)
下面以计数器程序为例, 演示如何使用可伸缩性来确定哪些操作不应该组合在一起, 请考虑以下任务:
任务1:对发送到队列的消息进行轮询,频率不高,不需要实时。
任务2:处理网络通信的高并发。
第二个任务需要是使用azure弹性机制,自动启动或停止计算单元的大量实例。如果对第一个任务应用相同的缩放, 只会导致更多的任务侦听同一队列中的不常见消息, 并且是资源的浪费。
在许多云环境中,可以设定CPU,内核、内存、磁盘空间等资源类型的数量来配置计算单元可用的资源。指定的资源越多,成本就越高。为了节省成本,就是要在昂贵计算单位的执行以后,将其工作内容最大化,而不是长时间让其处于闲置状态。
例如,有些任务在短时间内都需要大量的CPU,考虑将它们合并到一个计算单元中。并且要确保计算资源在保持被充分利用的同时,过度负载时有相应的负载均衡机制。而对于长运行的任务与计算任务较大的任务就不应该分在同一个计算单元中。
问题和注意事项
实现这个模式时, 请考虑以下几点:
伸缩性和弹性。许多云解决方案通过启动和停止单元实例来实现计算单元的可伸缩性和弹性。应避免在同一计算单元中出现对具有可伸缩性要求有冲突的任务。
生命周期。云基础结构周期性地回收计算单元的虚拟环境。当计算单元中有许多长时间的运行任务时,可能需要对其进行配置以防止被自动回收。或者通过使用检查点方法来设计任务,使它们能够干净的停止,并在重新启动时,从计算单元时中断的位置继续执行。
修改频率。如果任务或配置频繁更改,则可能需要停止计算单元,重新配置和并重部署该单元,然后重启。还需要停止、重新部署并重启同一计算单元中的所有任务。
安全性。同一计算单元中的任务可能共享相同的安全上下文,并且能够访问相同的资源。在任务之间必须有高度的信任度,并且一个任务不会对另一个产生负面影响。此外,增加计算单元中运行的任务数也会增加单元被攻击的概率。总体安全性等同于最“弱”的那个任务。
容错性。如果计算单元中的一个任务出现故障或行为异常,则会影响在同一单元中运行的其他任务。例如,如果一个任务无法正确启动, 则会导致计算单元的整个启动失败, 并导致同一单元中的其他任务无法运行。
资源竞争。避免在同一个计算单元中的任务之间出现资源争用。理想情况下,共享同一计算单元的任务应具有不同的资源利用率。例如,两个计算密集型任务不应驻留在同一计算单元中,两个任务都占用大量内存不应在同一计算单元。但是将计算密集型任务与占用大量内存的任务混合使用是一个可行的。
注意事项
考虑将计算资源合并为一个在生产中运行的系统,以便操作员和开发人员可以监控并创建一个热映射,以标识每个任务的资源使用情况。进而确定哪些任务是共享计算资源的候选项。
复杂性。将多个任务合并到单个计算单元中会增加该单元中代码的复杂性,可能使测试、调试和维护变得更加困难。因此需要使得每个任务中的代码设计与环境解耦,即使任务的物理环境发生了变化代码逻辑也不受影响。
其他策略。合并计算资源只是帮助降低同时运行多任务成本的一种方法。需要仔细的规划和监测,以确保它是一种有效的办法。其他策略可能更合适,具体取决于工作的性质以及这些任务运行的用户所在位置。例如,根据功能分配来进行负载分解(如计算分区指南所述https://msdn.microsoft.com/library/dn589773.aspx)可能是更好的选择。
何时使用此模式
如果任务在其自己的计算单元中运行,可以使用这个模式来改善开销大的任务花费。如果任务的闲置时间很长,则在特殊计算单元中运行此任务可能会很昂贵。此模式不适用于比较关键的,容错高的任务,或处理高度敏感以及私有数据的任务,这些需要知道它们的安全上下文。这些任务应该在各自独立的环境中运行,即在单独的计算单元中。
例子
在Azure上构建云服务时,可以将由多任务执行的处理合并为单一角色。通常,这是一个执行后台或异步处理任务的workerRole。在某些情况下,可以在webRole中包含后台或异步处理任务。有助于降低成本并简化部署,尽管它会影响webRole提供的面向公共接口的可伸缩性和响应性。将多个workerRole合并到azureWebRole中的文章(http://www.31a2ba2a-b718-11dc-8314-0800200c9a66.com/2012/02/combining-multiple-azure-worker-roles.html)中包含了实现背景的详细说明和webRole中的异步处理任务。
Role负责启动和停止任务。当AzureFabric控制器加载Role时,它将触发Role的Start事件。你可以重写WebRole或WorkerRole类的OnStart方法,要在这个方法中初始化任务所依赖的数据和其他资源。
当 OnStart方法执行完毕, Role开始响应请求。您可以在应用程序启动过程中的Role部分中找到具体细节(https://msdn.microsoft.com/library/ff803371.aspx#sec16)还有模式和实践中讲述如何将应用程序移到云的部分(https://msdn.microsoft.com/library/ff728592.aspx)
保持OnStart方法中的代码尽可能简洁。Azure对此方法完成所花费的时间没有任何限制,但在此方法完成之前,Role无法响应发送给它的任何请求。
当OnStart方法完成时,Run方法被执行。此时,结构控制器可以开始向Role发送请求。
将实际创建任务的代码放在Run方法中。注意,Run方法定义了Role实例的生命周期。当此方法完成时,结构控制器将安排Role关闭。
当Role关闭或被回收时,结构控制器会阻止从负载均衡器接收请求,并引发Stop事件。可以通过重写Role的OnStop方法来捕获此事件,并在Role终止之前执行所需的任何清理操作。
在OnStop方法中执行的任何操作都必须在五分钟内完成(如果在本地计算机上使用Azure模拟器,则为30秒)。否则,Azure结构控制器将假定Role已停止并将其强制停止。
任务由等待任务完成的Run方法启动。这些任务实现了云服务的业务逻辑,并可通过Azure负载均衡器响应路由到Role的消息。该图显示了Azure云服务中Role中任务和资源的生命周期。
ComputeResourceConsolidation.Worker项目中的WorkerRole.cs文件中说明了如何在Azure云服务中实现此模式。
ComputeResourceConsolidation.Worker项目可从GitHub下载,是ComputeResourceConsolidation解决方案的一部分(https://github.com/mspnp/cloud-design-patterns/tree/master/compute-resource-consolidation)。
MyWorkerTask1和MyWorkerTask2方法说明了如何在同一个Role中执行不同的任务。以下代码显示了MyWorkerTask1是一个简单的任务,休眠30秒,然后输出一个消息。它重复这个过程直到任务被取消。MyWorkerTask2中的代码逻辑也类似。
```
// A sample worker role task.
private static async Task MyWorkerTask1(CancellationToken ct)
{
// Fixed interval to wake up and check for work and/or do work.
var interval = TimeSpan.FromSeconds(30);
try
{
while (!ct.IsCancellationRequested)
{
// Wake up and do some background processing if not canceled.
// TASK PROCESSING CODE HERE
Trace.TraceInformation("Doing Worker Task 1 Work");
// Go back to sleep for a period of time unless asked to cancel.
// Task.Delay will throw an OperationCanceledException when canceled.
await Task.Delay(interval, ct);
}
}
catch (OperationCanceledException)
{
// Expect this exception to be thrown in normal circumstances or check
// the cancellation token. If the role instances are shutting down, a
// cancellation request will be signaled.
Trace.TraceInformation("Stopping service, cancellation requested");
// Rethrow the exception.
throw;
}
}
```示例代码是后台进程常见的实现方式。在应用程序中,可以遵循相同的结构,只是应该将自己的逻辑放在等待取消请求的循环体中。
在workerRole初始化它所使用的资源之后,Run方法将同时启动两个任务,如下所示。
```
/// <summary>
/// The cancellation token source use to cooperatively cancel running tasks
/// </summary>
private readonly CancellationTokenSource cts = new CancellationTokenSource();
/// <summary>
/// List of running tasks on the role instance
/// </summary>
private readonly List<Task> tasks = new List<Task>();
// RoleEntry Run() is called after OnStart().
// Returning from Run() will cause a role instance to recycle.
public override void Run()
{
// Start worker tasks and add to the task list
tasks.Add(MyWorkerTask1(cts.Token));
tasks.Add(MyWorkerTask2(cts.Token));
foreach (var worker in this.workerTasks)
{
this.tasks.Add(worker);
}
Trace.TraceInformation("Worker host tasks started");
// The assumption is that all tasks should remain running and not return,
// similar to role entry Run() behavior.
try
{
Task.WaitAll(tasks.ToArray());
}
catch (AggregateException ex)
{
Trace.TraceError(ex.Message);
// If any of the inner exceptions in the aggregate exception
// are not cancellation exceptions then re-throw the exception.
ex.Handle(innerEx => (innerEx is OperationCanceledException));
}
// If there wasn't a cancellation request, stop all tasks and return from Run()
// An alternative to canceling and returning when a task exits would be to
// restart the task.
if (!cts.IsCancellationRequested)
{
Trace.TraceInformation("Task returned without cancellation request");
Stop(TimeSpan.FromMinutes(5));
}
}
...
```在这个例子中,Run方法等待任务完成。如果任务被取消,则Run方法假定Role正在关闭,并在完成之前等待剩余的任务被取消(终止之前最多等待5分钟)。如果某个任务由于异常而失败,则Run方法将取消该任务。
你可以在Run方法中写更全面的监视和异常处理逻辑,例如重启失败的任务,或包含使Role停止并启动单个任务的代码。
当结构控制器关闭Role实例(它是从OnStop方法调用的)时,将调用以下代码中的Stop方法。通过取消来停止每个任务。如果任何任务超过五分钟,则Stop方法中的取消将停止等待并且Role被终止。
```
// Stop running tasks and wait for tasks to complete before returning
// unless the timeout expires.
private void Stop(TimeSpan timeout)
{
Trace.TraceInformation("Stop called. Canceling tasks.");
// Cancel running tasks.
cts.Cancel();
Trace.TraceInformation("Waiting for canceled tasks to finish and return");
// Wait for all the tasks to complete before returning. Note that the
// emulator currently allows 30 seconds and Azure allows five
// minutes for processing to complete.
try
{
Task.WaitAll(tasks.ToArray(), timeout);
}
catch (AggregateException ex)
{
Trace.TraceError(ex.Message);
// If any of the inner exceptions in the aggregate exception
// are not cancellation exceptions then rethrow the exception.
ex.Handle(innerEx => (innerEx is OperationCanceledException));
}
}
```相关的模式和指导
实施这种模式时,以下模式和指导可能也是相关的:
自动伸缩(https://docs.microsoft.com/zh-cn/azure/architecture/best-practices/auto-scaling)。自动伸缩可用于启动和停止托管资源的实例,具体取决于处理需求。
计算分区指南(https://msdn.microsoft.com/library/dn589773.aspx)。介绍如何在云服务中分配服务和组件,以便在维持服务的可伸缩性,性能,可用性和安全性的同时最大限度地降低运营成本。
示例程序可以在这里下载(https://github.com/mspnp/cloud-design-patterns/tree/master/compute-resource-consolidation)