做一件荒谬的事:用AI推理下一次双色球结果 v0.1
做一件荒谬的事:用AI推理下一次双色球结果 v0.1
引言
事情的起因是父亲被亲戚安利,突然喜欢上了双色球,连规则和开奖结果怎么看都不懂的他,让我研究研究这个事,给他选个号。他还说老家有好几个人中了几百万,买个车买了房,我…,谁能拒绝一个2块钱就能买到的百万奖金梦呢?---------------------20231204
一、双色球规则

- 双色球由红色球和蓝色球组成。红色球共有33个号码(01-33),蓝色球共有16个号码(01-16)。
- 在每期双色球开奖中,从红色球中选择6个号码,从蓝色球中选择1个号码,共选出7个号码作为投注号码。
- 您可以选择手动选号或者使用机选功能。手动选号时,您可以自行选择6个红色球和1个蓝色球的号码。机选功能会随机生成一组号码。
- 每注双色球的投注金额为2元人民币。
- 您可以选择单式投注或复式投注。单式投注是指只选择一组号码进行投注,而复式投注是指选择多组号码进行投注,增加中奖机会。
- 双色球每周进行两次开奖,分别是每周二、四、日的晚上9点。
- 开奖时,会先从红色球中摇出6个号码作为中奖号码,然后再从蓝色球中摇出1个号码作为蓝色球号码。
- 中奖规则根据您选择的号码与中奖号码的匹配情况来确定。奖金分为一等奖、二等奖、三等奖、四等奖、五等奖、六等奖和七等奖,其中一等奖为中6红+1蓝,二等奖为中6红或5红+1蓝,依此类推。
下面是双色球各个奖项的中奖概率和奖金(总中奖概率为6.71%):
| 奖项 | 中奖概率 | 奖金(估计) |
|---|---|---|
| 一等奖(中6红+1蓝) | 1/17721088 | 数百万元 |
| 二等奖(中6红) | 0.0000846% | 约 50万元 |
| 三等奖(中5红+1蓝) | 0.000914% | 3000元 |
| 四等奖(中5红或4红+1蓝) | 0.0434% | 200元 |
| 五等奖(中4红或3红+1蓝) | 0.7758% | 10元 |
| 六等奖(中1/2红+1蓝或仅中蓝球) | 5.889% | 5元 |
投入2元的双色球,平均你可以拿到的收益为1元不到,为0.9377元
二、研究思路及目的
想研究一个中头奖的算法显然是不太可能,所以初步目标是希望将4等奖的中奖概率提升到1/100。这样便可以保证自己每买100注,便可以中一个4等奖,不赚不亏。理想非常丰满,hahahaha,让我们现在开始动起手来。
- 显然每次双色球都是一个独立随机事件,前后的结果是没有联系。但是我还是首先尝试把它建立成一个时间序列模型。下一次的中奖结果由前N次结果推导得到。
- 既然搞玄学,那必须得搞一手深度学习。炼丹与玄学简直不要太配。首选深度学习网络LSTM
- 模型有了,还需要用数据去调教。那就必须上一手爬虫,把近几十年的中奖结果搞出来。
说干就干!
三、获取历史中奖结果
分析网页源码
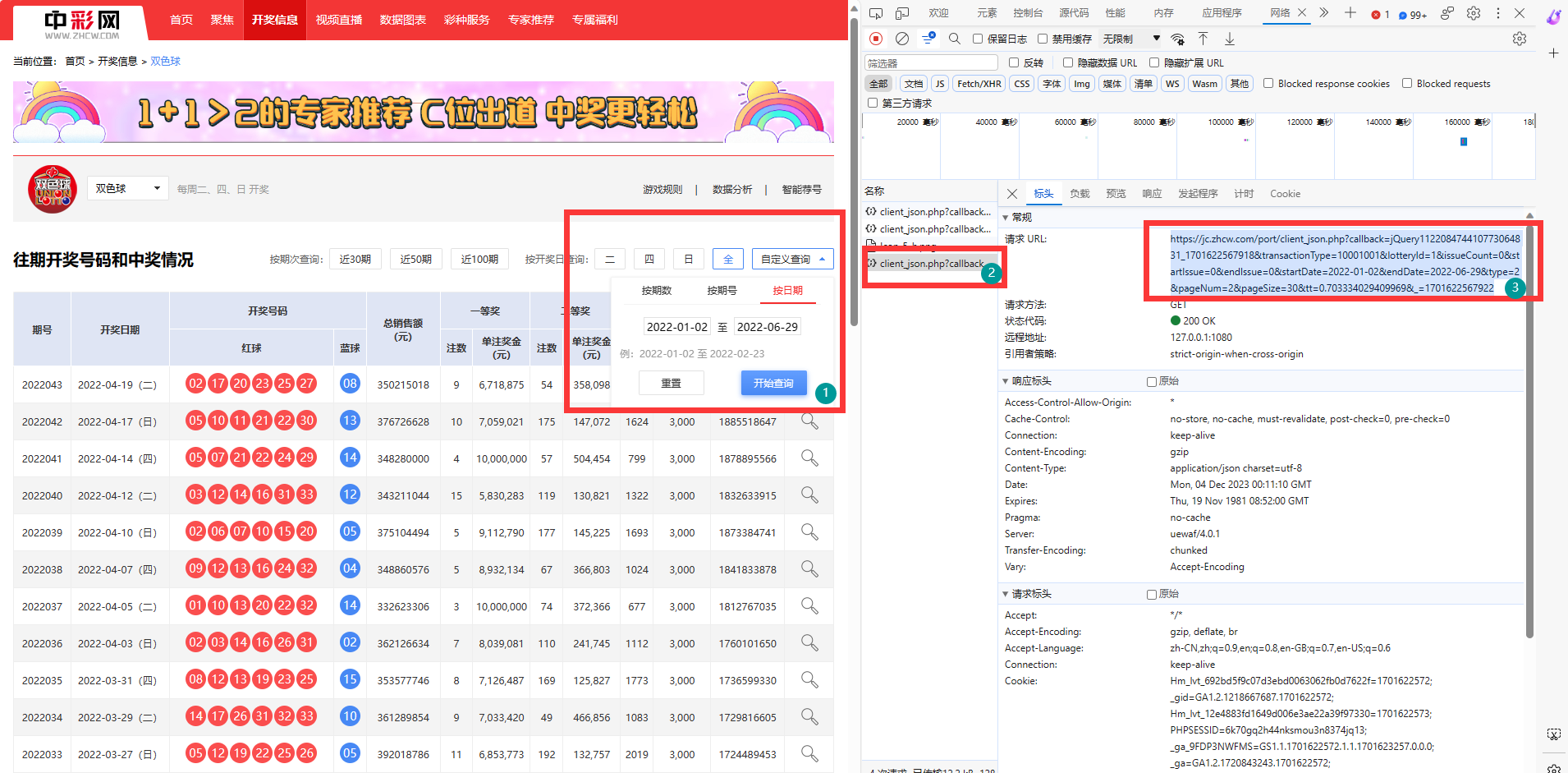
-
选择中彩网,打开浏览器源码使用F12查看源码,网页在每次查询的时候都会发送一个异步的jQuery请求,返回json格式的查询结果。(非计算机专业,对网页前后端的机制仅是简单了解)
-
使用python request库模仿请求,爬取历史数据
-
简单将这个url直接请求返回的数据为空;简单搜索一下,可以知道这个是jQuery在进行跨域请求的时候利用jsonp进行处理造成的现象。注意几点:1)需要设置
Referer头,因为这是跨域请求;2)_=1701651618276是时间戳; -
为了保险起见,又添加了cookie和User-Agent头
import requests import json import random url = 'https://jc.zhcw.com/port/client_json.php' headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0","Referer": "https://www.zhcw.com/" } cookies = {"Hm_lvt_692bd5f9c07d3ebd0063062fb0d7622f": "1701622572","_gid": "GA1.2.1218667687.1701622572","Hm_lvt_12e4883fd1649d006e3ae22a39f97330": "1701622573","PHPSESSID": "6k70gq2h44nksmou3n8374jq13","_ga_9FDP3NWFMS": "GS1.1.1701622572.1.1.1701623257.0.0.0","_ga": "GA1.2.1720843243.1701622572","Hm_lpvt_12e4883fd1649d006e3ae22a39f97330": "1701623257","Hm_lpvt_692bd5f9c07d3ebd0063062fb0d7622f": "1701623258" } params = {'callback':'jQuery112208474410773064831_1701622567918','transactionType':10001001,'lotteryId':1,'issueCount':0,'startIssue':'','endIssue':'','startDate':'2003-02-01','endDate':'2003-04-01','type':2,'pageNum':1,'pageSize':30,"tt": random.random(),"_": str(int(time.time() * 1000))} # 发送HTTP GET请求 response = requests.get(url,headers=headers,cookies=cookies,params=params)# 提取JSONP响应中的JSON数据 json_data = response.text.split('(')[1].split(')')[0] # 解析JSON数据 data = json.loads(json_data) # 提取双色球号码信息 for entry in data['data']:issue = entry['issue']openTime = entry["openTime"]front_winning_num = entry['frontWinningNum']back_winning_num = entry['backWinningNum']saleMoney = entry["saleMoney"]print(f"{issue} |{openTime}|{front_winning_num} |{back_winning_num} |{saleMoney}")结果输出: 2003011 |2003-03-30|04 05 11 12 30 32 |15 |12782494 2003010 |2003-03-27|01 02 08 13 17 24 |13 |12402130 2003009 |2003-03-23|05 09 18 20 22 30 |09 |12386072 ...
保存到文件
-
每一期的的信息有很多:日期、开奖日期、中奖号、销售额、奖池、中奖情况。但是一些早期数据一些数据是缺失的,所以我选择保留开奖日期、期号、中奖号码、销售额、奖金池。
-
保存最简单的方式就是以纯文本保存到CSV里。
-
因为每次只能爬取30条数据,所以我们按照月份来划分,每2个月爬取一次,2个月内不会超过30次开奖。双色球从2003年2月16日,我们便从20230201开始爬取 ,生成每次的时间节点字符串。
import datetime def add_two_months(date_str):date_format = "%Y-%m-%d"current_date = datetime.datetime.strptime(date_str, date_format)now = datetime.datetime.now()datestart = []dateend = []while current_date < now:datestart.append(current_date.strftime(date_format))current_date_end = current_date + datetime.timedelta(days=59)if current_date_end < now:dateend.append(current_date_end.strftime(date_format))else:dateend.append(now.strftime(date_format))current_date = current_date + datetime.timedelta(days=60)return datestart,dateend start_date = "2003-02-01" datestart,dateend = add_two_months(start_date) print(datestart) print(dateend)输出结果: ['2003-02-01', '2003-04-02', '2003-06-01', '2003-07-31',...,'2023-02-16', '2023-04-17', '2023-06-16', '2023-08-15', '2023-10-14'] ['2003-04-01', '2003-05-31', '2003-07-30', '2003-09-28',..., '2023-04-16', '2023-06-15', '2023-08-14', '2023-10-13', '2023-12-04'] -
循环爬取并保存
file = open('Bicolorballs.csv', 'w') # 打开Bicolorballs.csv文件,写模式 for s,e in zip(datestart,dateend):params = {'callback':'jQuery112208474410773064831_1701622567918','transactionType':10001001,'lotteryId':1,'issueCount':0,'startIssue':'','endIssue':'','startDate':s,'endDate':e,'type':2,'pageNum':1,'pageSize':30,"tt": random.random(),"_": str(int(time.time() * 1000))}# 发送HTTP GET请求response = requests.get(url,headers=headers,cookies=cookies,params=params)# 提取JSONP响应中的JSON数据json_data = response.text.split('(')[1].split(')')[0]# 解析JSON数据data = json.loads(json_data)# 提取双色球号码信息for entry in data['data']:issue = entry['issue']openTime = entry["openTime"]front_winning_num = entry['frontWinningNum']back_winning_num = entry['backWinningNum']saleMoney = entry["saleMoney"]prizePoolMoney = entry["prizePoolMoney"]data = f"{issue},{openTime},{front_winning_num},{back_winning_num},{saleMoney},{prizePoolMoney}\r\n"file.write(data) file.close() # 关闭文件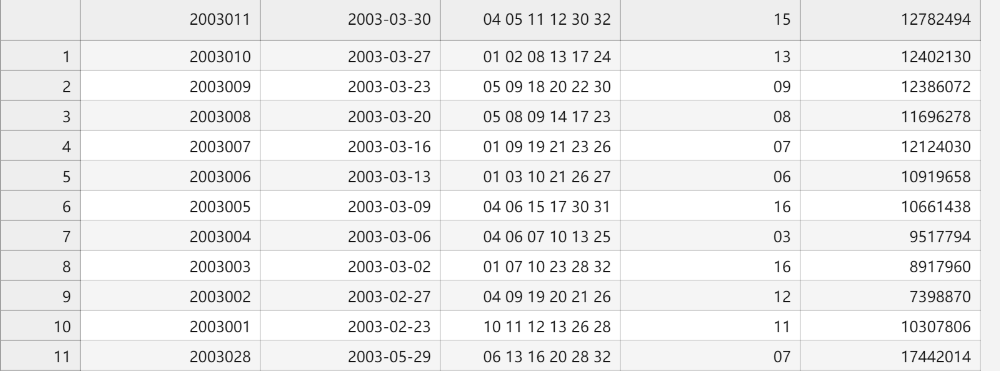
-
因为多次请求,响应返回的时间不同会导致数据的顺序是乱的,但这不重要,使用excel打开,排一下序就可以了。
-
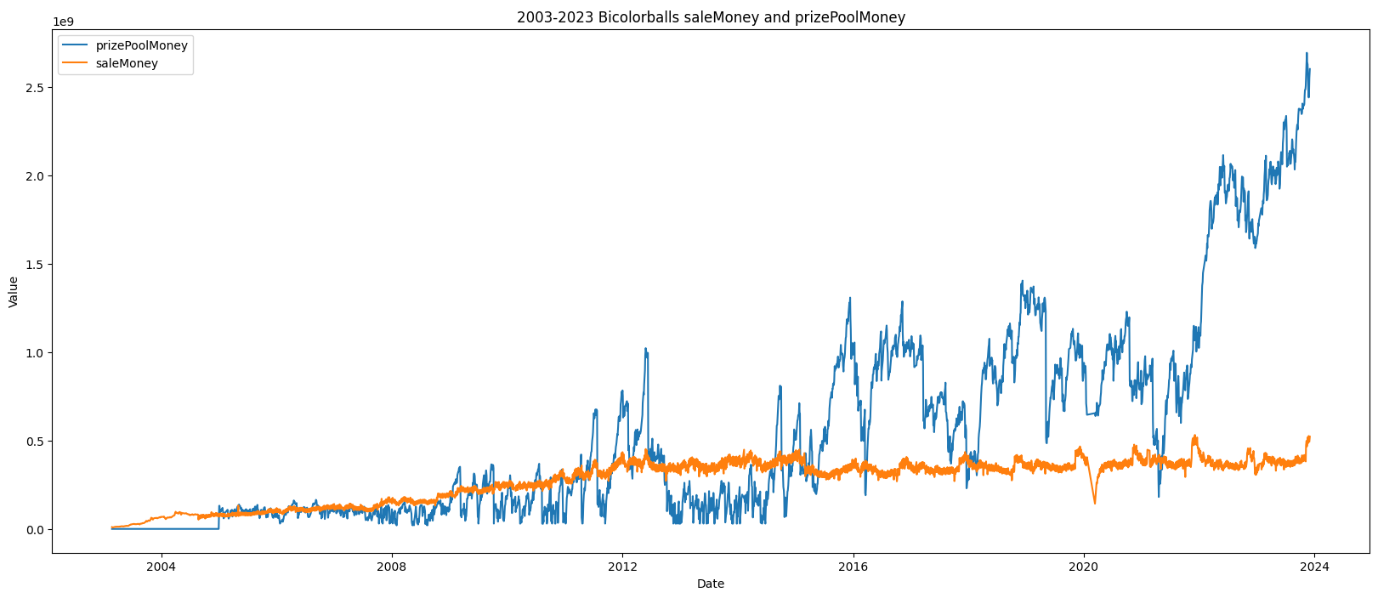
突然想到一个有趣的事,近20年的双彩球的销售额曲线会是怎样的呢?哈哈哈,会不会和国家经济发展曲线完全吻合呢?
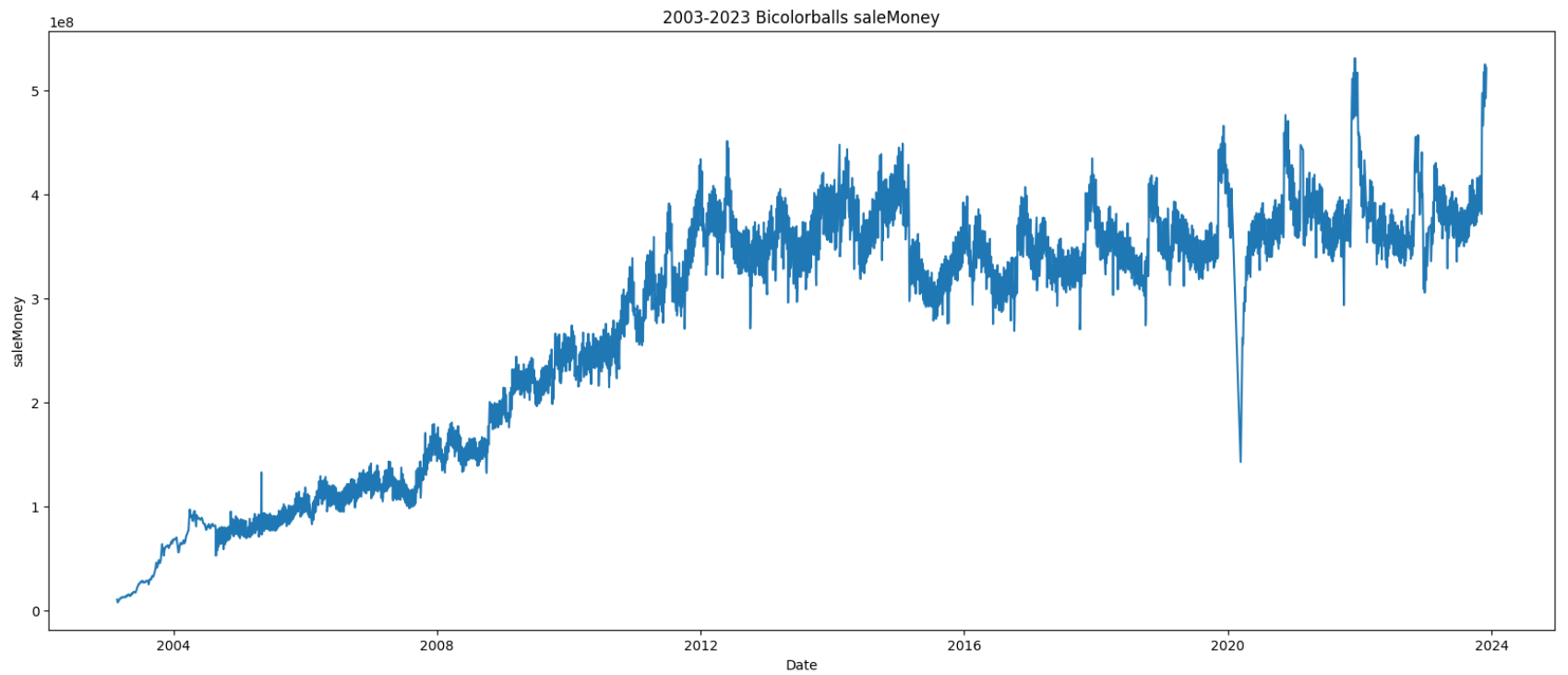
下图是2003年到2023年的国家GDP变化情况:
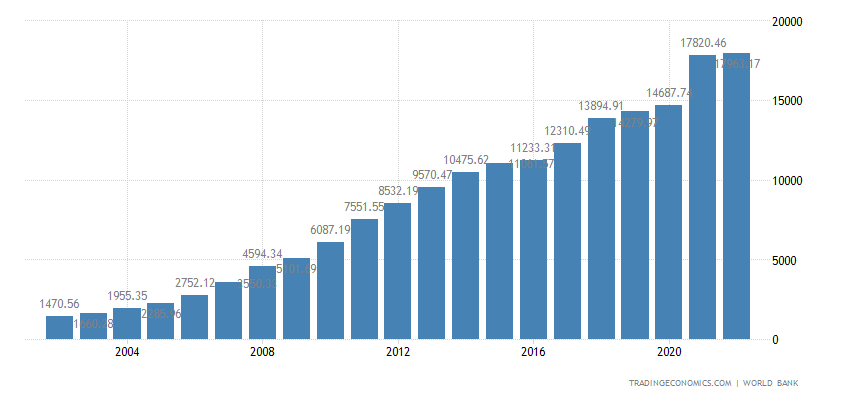
不能说毫无关系,只能说近乎一模一样,彩票销售额从长期来看大致和国家经济发展有关,其销售额在2016年以后基本保持稳定,猜测可能有两个原因:市场规模增长到上限或者和近几年中国经济增长放缓有关。除此之外销售额也会还会受到各种突发状况的冲击,比如2020年的疫情,使得销售了出现了一个明显的低谷;在2022年疫情恢复后,又反弹到一个小高峰。除此之外,销售额还表现出周期性,每年的年初和年末比较高,年中比较低,这是个有趣的现象,推测出现此现象的原因1)回家过年2)年终奖 3)年底发工资。
最后附上一张销售额和奖金池的历史变化曲线:
四、构建算法模型
1.原始数据分布
我们首先从原始数据的概率分布入手,看一下能不能找到一些规律。统计所有球中奖的概率分布:
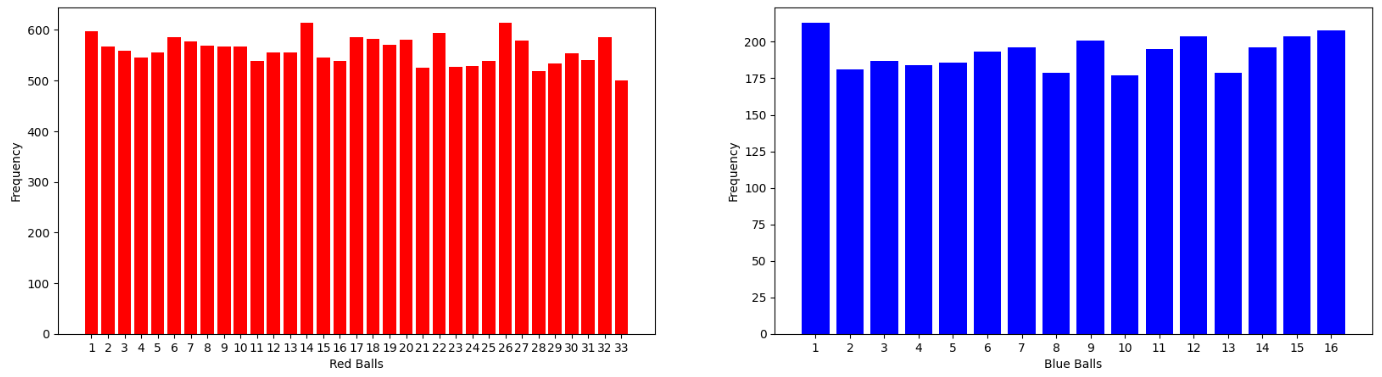
概率最大的5个红色球为:14,24,1,22,6,17;蓝色球为1。频次分别为614,614,597,594,586,585和213。
2.模型v0.1
数据集构造
我们首先简单假设下一次球的数字仅受之前中奖数字的影响。那么数据集只需要引入红色球编号和蓝色球编号2个变量。红球编号为1-33的5个不重复数字,蓝球为1-16的单个数字。我将其构造为
R = I 33 × 1 , B = I 16 × 1 , 其中 i 奖 = 1 , i 无 = 0 R = I_{33\times 1 }, B = I_{16\times 1},其中i_奖 = 1,i_无 = 0 R=I33×1,B=I16×1,其中i奖=1,i无=0
之前观察到彩票销售额的年内周期变化规律,我简单的假设下一次的中奖球编号收到之前一年的中奖(约150次)结果的影响,即:
R t , B t = f ( R t − 1 , B t − 1 , R t − 2 , B t − 2 , . . . R t − 150 , B t − 150 ) R_t,B_t = f(R_{t-1},B_{t-1},R_{t-2},B_{t-2},...R_{t-150},B_{t-150}) Rt,Bt=f(Rt−1,Bt−1,Rt−2,Bt−2,...Rt−150,Bt−150)
我们的目的即为构造时间序列推理模型f。
基于我目前所学的知识,我选择LSTM深度学习模型(长短期记忆递归神经网络)。
基于双色球的游戏规则,蓝色球中奖比红色球中要重要的多,我们显然应该在模型内部给与蓝色球更多的关注。但作为此模型的早期版本,我们假设红篮球中奖结果相互独立,将上述模型进一步简化为:
R t = f 1 ( R t − 1 , R t − 2 , . . . R t − 150 ) , B t = f 2 ( B t − 1 , B t − 2 , . . . B t − 150 ) R_t = f_1(R_{t-1},R_{t-2},...R_{t-150}) ,\\ B_t = f_2(B_{t-1},B_{t-2},...B_{t-150}) Rt=f1(Rt−1,Rt−2,...Rt−150),Bt=f2(Bt−1,Bt−2,...Bt−150)
即分别训练2个LSTM模型单独推理红球和蓝球。到此我们可以开始着手构造我们的数据集了:
读取数据
import numpy as np
import tensorflow as tfwith open('Bicolorballs.csv', 'r') as file:reader = csv.reader(file)red_balls = []blue_balls = []for row in reader:red = np.array([int(i)-1 for i in row[2].split(' ')])# 编码red = tf.one_hot(red, depth=33)red = tf.reduce_sum(red, axis=0)red_balls.append(red)blue = np.array([int(row[3])-1])blue = tf.one_hot(blue, depth=16)blue = tf.reduce_sum(blue, axis=0)blue_balls.append(blue)
print("数据集长度为:",len(red_balls))
print("红球编码后为:",red_balls[0].numpy())
print("蓝球编码后为:",blue_balls[0].numpy())
#输出结果:
#数据集长度为: 3083
#红球编码后为: [0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 0. 0. 0. 0. 0.]
#蓝球编码后为: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
构建红球的数据集,时间步为150,前面80%的数据为训练集,20%为测试集
data = tf.stack(red_balls)
# 定义超参数
n_steps = 150 # 时间步数,即每个样本包含的历史时间步数
T = len(data)
features = []
for i in range(T-n_steps):features.append(data[i: n_steps + i,:])
labels = data[n_steps:,:]
features = tf.stack(features) # 将数据集划分为训练集和测试集
train_size = int(len(data) * 0.8)
train_X, train_y = features[:train_size], labels[:train_size]
test_X, test_y = features[train_size:],labels[train_size:]# 创建tf.data.Dataset对象
train_dataset = tf.data.Dataset.from_tensor_slices((train_X, train_y))
test_dataset = tf.data.Dataset.from_tensor_slices((test_X, test_y))# 可选:对数据集进行一些预处理操作,例如乱序、批量化和缓存等
train_dataset = train_dataset.shuffle(100).batch(32).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(32).cache().prefetch(tf.data.AUTOTUNE)#测试数据集的的形状
#data,label = iter(train_dataset.take(1)).next()
#print(data.shape)
#(32, 150, 33) #(B,T,C)
构造模型
首先搭建一个简单的双层LSTM网络,LSTM单元数量为64/128/256,输出层使用全连接层(33),将输出变为33通道的输出,再接sigmoid层将输出向量映射到0-1之间的概率。损失函数使用多分类的交叉熵损失函数。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 定义输入和输出形状
input_shape = (150, 33)
output_shape = (1, 33)
# 创建双层LSTM网络
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=input_shape)) # 第一层LSTM
model.add(LSTM(64)) # 第二层LSTM
model.add(Dense(output_shape[-1], activation='sigmoid')) # 输出层
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 打印模型结构
model.summary()
################################################
#Model: "sequential"
#_________________________________________________________________
# Layer (type) Output Shape Param #
#=================================================================
# lstm (LSTM) (None, 150, 64) 25088
#
# lstm_1 (LSTM) (None, 64) 33024
#
# dense (Dense) (None, 33) 2145
#
#=================================================================
#Total params: 60,257
#Trainable params: 60,257
#Non-trainable params: 0
模型训练
开始训练,见证我一天的研究成果。将训练日志和最优参数保存下来,学习率默认为0.001
from datetime import datetime
from tensorflow import keras
EPOCHS = 200
NetNAME = 'LSTM2'
tf.debugging.set_log_device_placement(True)
timestamp = datetime.now().strftime("%Y%m%d-%H%M%S")
NAME = timestamp + NetNAME +"_batchsize";print(NAME)
logdir = "./logs/" + NAME
modeldir = "./model/"+NAME+".h5"
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
checkpoint = tf.keras.callbacks.ModelCheckpoint(filepath=modeldir, monitor='val_accuracy', verbose=1, save_best_only=True, mode = 'max')
with tf.device('/GPU:0'):model.fit(x=train_dataset, epochs=EPOCHS, validation_data=test_dataset, callbacks=[tensorboard_callback,checkpoint])
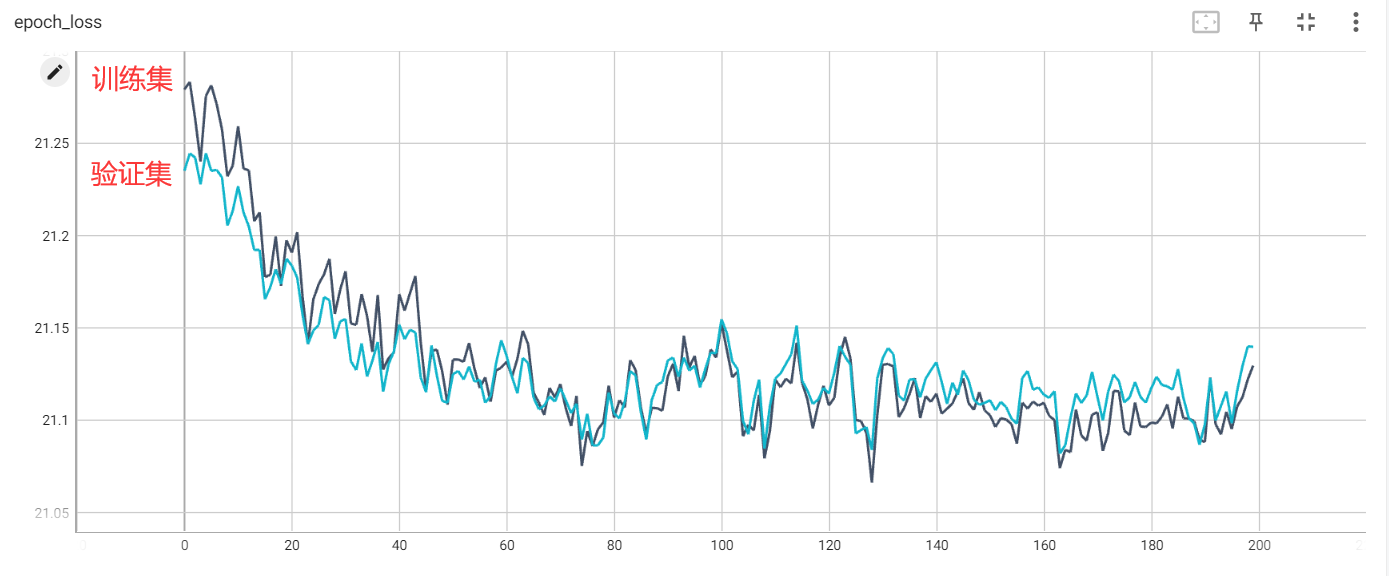
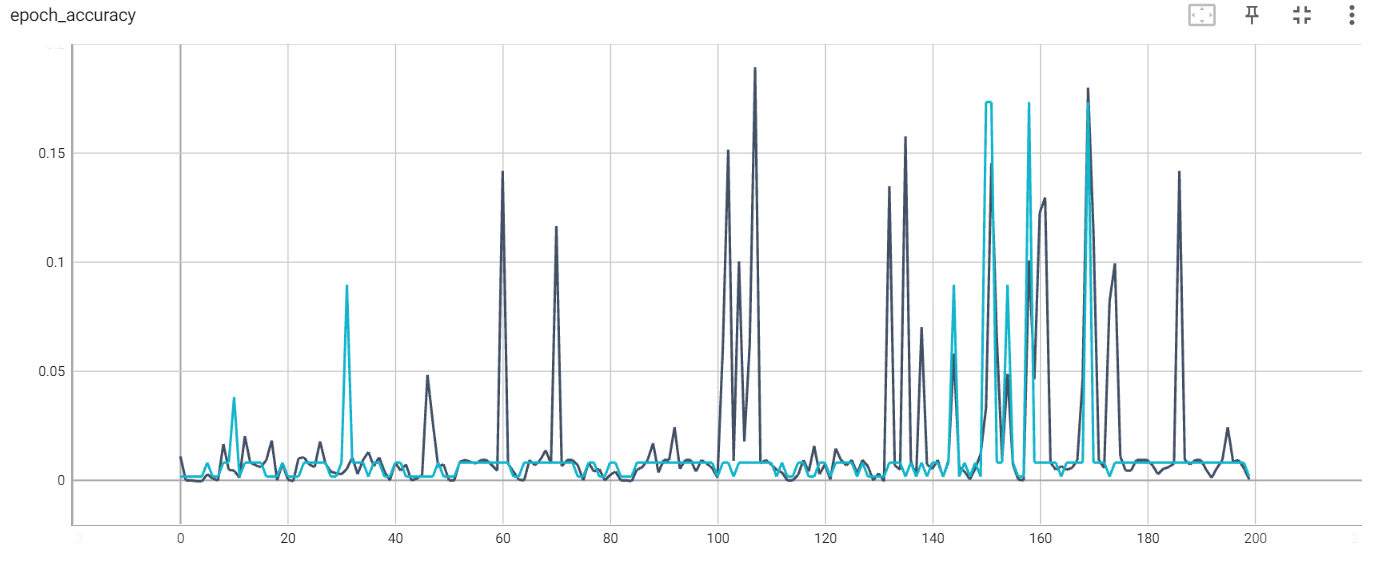
训练了几遍后,目前看起来还算说的过去的结果是这样的。测试集和训练集的损失函数会下降一点,但绝对值还是很大,模型是不收敛的。看精度变化曲线的话,在训练200轮的过程中,是有几次精度比较高的,说明模型偶然猜对了部分数据。
此外,我们采用同样的方法训练蓝球模型。因为蓝球最终只有一个结果,所以输出层的激活函数我们选择softmax层,损失函数选择二分类交叉熵损失函数。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.callbacks import LearningRateScheduler
from datetime import datetime
from tensorflow import keras
from tensorflow.keras.callbacks import LearningRateSchedulerdata = tf.stack(blue_balls)
# 定义超参数
n_steps = 150 # 时间步数,即每个样本包含的历史时间步数
T = len(data)
features = []
for i in range(T-n_steps):features.append(data[i: n_steps + i,:])
labels = data[n_steps:,:]
features = tf.stack(features) # 将数据集划分为训练集和测试集
train_size = int(len(data) * 0.8)
train_X, train_y = features[:train_size], labels[:train_size]
test_X, test_y = features[train_size:],labels[train_size:]# 创建tf.data.Dataset对象
train_dataset = tf.data.Dataset.from_tensor_slices((train_X, train_y))
test_dataset = tf.data.Dataset.from_tensor_slices((test_X, test_y))# 可选:对数据集进行一些预处理操作,例如乱序、批量化和缓存等
train_dataset = train_dataset.shuffle(100).batch(32).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(32).cache().prefetch(tf.data.AUTOTUNE)# 定义输入和输出形状
input_shape = (150, 16)
output_shape = (1, 16)
# 创建双层LSTM网络
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=input_shape)) # 第一层LSTM
model.add(LSTM(64)) # 第二层LSTM
model.add(Dense(output_shape[-1], activation='softmax')) # 输出层
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 打印模型结构EPOCHS = 400
NetNAME = 'B_LSTM2'
tf.debugging.set_log_device_placement(True)
timestamp = datetime.now().strftime("%Y%m%d-%H%M%S")
NAME = timestamp + NetNAME +"_batchsize";print(NAME)
logdir = "./logs/" + NAME
modeldir = "./model/"+NAME+".h5"def lr_scheduler(epoch, lr):if epoch % 100 == 0 and epoch != 0:lr = lr / 2return lr
lr_callback = LearningRateScheduler(lr_scheduler)
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
checkpoint = tf.keras.callbacks.ModelCheckpoint(filepath=modeldir, monitor='val_accuracy', verbose=1, save_best_only=True, mode = 'max')
with tf.device('/GPU:0'):model.fit(x=train_dataset, epochs=EPOCHS, validation_data=test_dataset, callbacks=[tensorboard_callback,checkpoint])
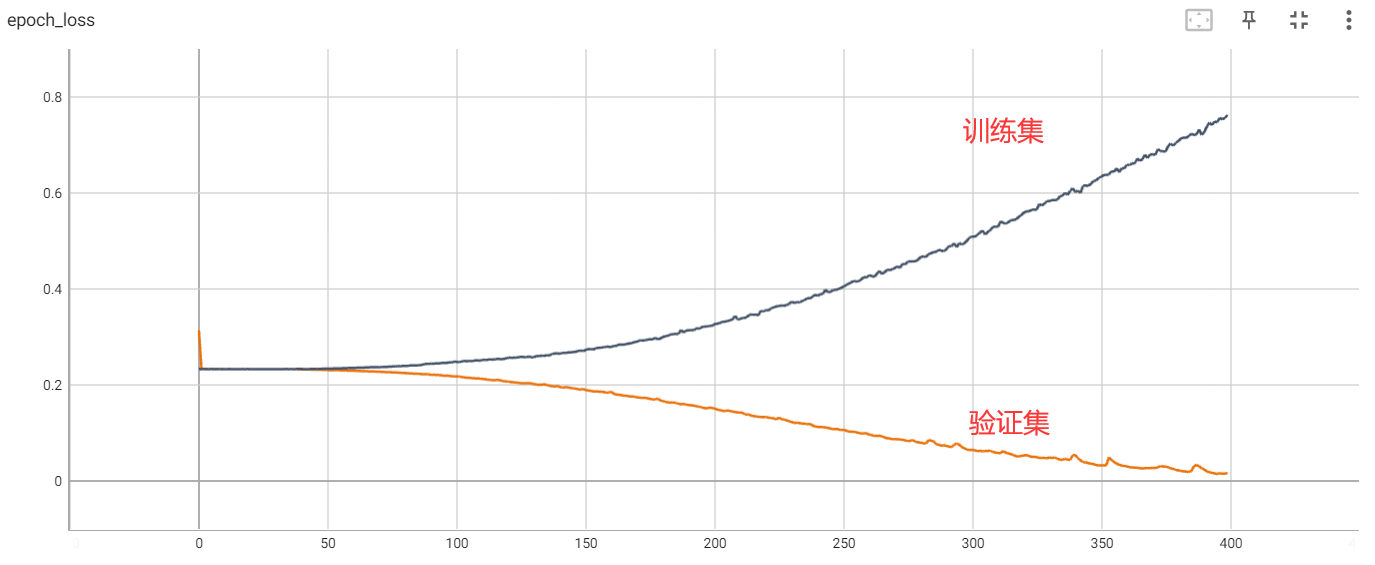
哎!蓝球你是一点也学不会啊,严重过拟合了。
模型推理
加载红球和蓝球模型进行推理,红色球取概率值最高的6个,蓝色球取最高的5个。猜测五次,每次红球不变蓝球变。根据真值判断自己得了几等奖,开玩!!!!!
import tensorflow as tf
from tensorflow.keras.models import load_modeldef CalculateTheAwards(R,B,Rlabel,Blabel):R = R.numpy()B = B.numpy()Rlabel = Rlabel.numpy()Blabel = Blabel.numpy()Rcount = 0Bcount = Blabel[B]for r in R:Rcount = Rcount + Rlabel[r]if Bcount+Rcount ==7:print('恭喜你,你中一等奖了!!')elif Rcount ==6 and Bcount ==0:print('恭喜你,你中二等奖了!!')elif Rcount ==5 and Bcount ==1:print('恭喜你,你中三等奖了!!')elif Bcount+Rcount ==5:print('恭喜你,你中四等奖了!!')elif Bcount+Rcount ==4:print('恭喜你,你中五等奖了!!')elif Bcount ==1 :print('恭喜你,你中六等奖了!!')else:print('很遗憾,你没有中奖')
# 加载模型
Rmodel = load_model('model/20231204-174742LSTM2_lr100_batchsize.h5') #20231204-173622LSTM2_batchsize.h5
Bmodel = load_model('model/20231204-192802B_LSTM2_batchsize.h5')i = 2 #测试数据编号
# 加载新的数据进行推理
R = tf.expand_dims(tf.stack(red_balls[-150-i:-i]), axis=0)
B = tf.expand_dims(tf.stack(blue_balls[-150-i:-i]), axis=0)
Rlabel = red_balls[-i+1]
Blabel = blue_balls[-i+1]
print(Rlabel.numpy())
print(Blabel.numpy())
# 对新数据进行预测
Rpredictions = Rmodel.predict(R,verbose=0)
Bpredictions = Bmodel.predict(B,verbose=0)
# # 打印预测结果
# print(Rpredictions)
# print(Bpredictions)# 选择出最大的5/6个元素的索引
_, Rindices = tf.math.top_k(tf.constant(Rpredictions[0]), k=6)
_, Bindices = tf.math.top_k(tf.constant(Bpredictions[0]), k=5)
print(f'预测结果是红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[0]+1).numpy()}')
CalculateTheAwards(Rindices,Bindices[0],Rlabel,Blabel)
print(f'预测结果是红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[1]+1).numpy()}')
CalculateTheAwards(Rindices,Bindices[1],Rlabel,Blabel)
print(f'预测结果是红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[2]+1).numpy()}')
CalculateTheAwards(Rindices,Bindices[2],Rlabel,Blabel)
print(f'预测结果是红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[3]+1).numpy()}')
CalculateTheAwards(Rindices,Bindices[3],Rlabel,Blabel)
print(f'预测结果是红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[4]+1).numpy()}')
CalculateTheAwards(Rindices,Bindices[4],Rlabel,Blabel)
模拟游戏
我们使用我们的模型,基于历史开奖数据进行模拟游戏。每次下注结果都是使用前150次的中奖数字通过模型推理得到的。每次买5注,10块钱。我们先玩10次看看
红球开奖结果: [0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0]
蓝球开奖结果: [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为10 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为14 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为11 ----> 恭喜你,你中六等奖了!!5块钱
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为15 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为4 ----> 很遗憾,你没有中奖
红球开奖结果: [0 0 1 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0]
蓝球开奖结果: [0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为8 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为14 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为10 ----> 恭喜你,你中六等奖了!!5块钱
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为5 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为15 ----> 很遗憾,你没有中奖
红球开奖结果: [0 0 0 0 1 1 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0]
蓝球开奖结果: [0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为8 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为5 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为4 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为12 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为15 ----> 很遗憾,你没有中奖
红球开奖结果: [0 0 0 0 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1]
蓝球开奖结果: [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为12 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为4 ----> 恭喜你,你中六等奖了!!5块钱
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为14 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为9 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为3 ----> 很遗憾,你没有中奖
红球开奖结果: [0 0 0 1 1 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0]
蓝球开奖结果: [0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为14 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为10 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为11 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为1 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为3 ----> 恭喜你,你中六等奖了!!5块钱
红球开奖结果: [0 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0]
蓝球开奖结果: [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为1 ----> 恭喜你,你中六等奖了!!5块钱
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为5 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为10 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为12 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为8 ----> 很遗憾,你没有中奖
红球开奖结果: [0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0]
蓝球开奖结果: [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为1 ----> 恭喜你,你中六等奖了!!5块钱
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为5 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为4 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为3 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为8 ----> 很遗憾,你没有中奖
红球开奖结果: [0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 0]
蓝球开奖结果: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为13 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为9 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为7 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为15 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为3 ----> 很遗憾,你没有中奖
红球开奖结果: [0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1]
蓝球开奖结果: [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为9 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为16 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为15 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为3 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为4 ----> 恭喜你,你中六等奖了!!5块钱
红球开奖结果: [0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1]
蓝球开奖结果: [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为9 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为16 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为4 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为13 ----> 很遗憾,你没有中奖
预测结果是红球编号[14 16 29 20 11 33],蓝球编号为1 ----> 恭喜你,你中五等奖了!!10块钱
hahahahahahahahahaha,红球模型的输出结果每次是不同的,但概率最高的永远是这6个数,有问题的,它似乎只喜欢买这几个号。但不管怎样,6等奖概率还可以。今天算是没白干(耗费11h),以后有空再搞v0.2。
问题总结
方便下次改进,1)红球输出是固定的,2)蓝球模型是严重过拟合的。两个模型都基本是无法收敛的,不过这也正常,但我觉得应该还有优化空间。
五、双色球应用程序
从网站上爬取最近150次的中奖结果,输入模型进行预测,得到红蓝球数字。
import requests
import json
import random
import tensorflow as tf
import numpy as np
from datetime import datetime,date
from tensorflow.keras.models import load_model
# 加载模型
Rmodel = load_model('model/20231204-174742LSTM2_lr100_batchsize.h5') #20231204-173622LSTM2_batchsize.h5
Bmodel = load_model('model/20231204-192802B_LSTM2_batchsize.h5')url = 'https://jc.zhcw.com/port/client_json.php'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0","Referer": "https://www.zhcw.com/"
}
cookies = {"Hm_lvt_692bd5f9c07d3ebd0063062fb0d7622f": "1701622572","_gid": "GA1.2.1218667687.1701622572","Hm_lvt_12e4883fd1649d006e3ae22a39f97330": "1701622573","PHPSESSID": "6k70gq2h44nksmou3n8374jq13","_ga_9FDP3NWFMS": "GS1.1.1701622572.1.1.1701623257.0.0.0","_ga": "GA1.2.1720843243.1701622572","Hm_lpvt_12e4883fd1649d006e3ae22a39f97330": "1701623257","Hm_lpvt_692bd5f9c07d3ebd0063062fb0d7622f": "1701623258"
}history = []
for i in range(1,6):params = {'callback':'jQuery112208474410773064831_1701622567918','transactionType':10001001,'lotteryId':1,'issueCount':150,'startIssue':'','endIssue':'','startDate':'','endDate':'','type':0,'pageNum':i,'pageSize':30,"tt": random.random(),"_": str(int(time.time() * 1000))}# 发送HTTP GET请求response = requests.get(url,headers=headers,cookies=cookies,params=params)# 提取JSONP响应中的JSON数据json_data = response.text.split('(')[1].split(')')[0]# 解析JSON数据data = json.loads(json_data)# 提取双色球号码信息for entry in data['data']:issue = int(entry['issue'])front_winning_num = entry['frontWinningNum']back_winning_num = entry['backWinningNum']history.append([issue,front_winning_num,back_winning_num])
# 按照期号进行排序
history = sorted(history, key=lambda x: x[0])
#print(history) red_history = []
blue_history = []
# 构造模型的输入数据
for h in history:red = np.array([int(i)-1 for i in h[1].split(' ')])# 编码red = tf.one_hot(red, depth=33)red = tf.reduce_sum(red, axis=0)red_history.append(red)blue = np.array([int(h[2])-1])blue = tf.one_hot(blue, depth=16)blue = tf.reduce_sum(blue, axis=0)blue_history.append(blue)
#print(blue_balls) # # 加载新的数据进行推理
R = tf.expand_dims(tf.stack(red_history), axis=0)
B = tf.expand_dims(tf.stack(blue_history), axis=0)# 对新数据进行预测
Rpredictions = Rmodel.predict(R,verbose=0)
Bpredictions = Bmodel.predict(B,verbose=0)
# # 打印预测结果
#print(Rpredictions)
# print(Bpredictions)# # 选择出最大的5个元素及其索引
_, Rindices = tf.math.top_k(tf.constant(Rpredictions[0]), k=6)
_, Bindices = tf.math.top_k(tf.constant(Bpredictions[0]), k=5)
print('今天是:', date.today(),' 推理下一次双色球的号码是:')
print(f'1:红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[0]+1).numpy()}')
print(f'2:红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[1]+1).numpy()}')
print(f'3:红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[2]+1).numpy()}')
print(f'4:红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[3]+1).numpy()}')
print(f'5:红球编号{(Rindices+1).numpy()},蓝球编号为{(Bindices[4]+1).numpy()}')
结果如下:
今天是: 2023-12-04 推理下一次双色球的号码是:
1:红球编号[14 16 29 20 11 33],蓝球编号为1
2:红球编号[14 16 29 20 11 33],蓝球编号为10
3:红球编号[14 16 29 20 11 33],蓝球编号为12
4:红球编号[14 16 29 20 11 33],蓝球编号为7
5:红球编号[14 16 29 20 11 33],蓝球编号为13