Large Language Models areVisual Reasoning Coordinators
目录
一、论文速读
1.1 摘要
1.2 论文概要总结
二、论文精度
2.1 论文试图解决什么问题?
2.2 论文中提到的解决方案之关键是什么?
2.3 用于定量评估的数据集是什么?代码有没有开源?
2.4 这篇论文到底有什么贡献?
2.5 下一步呢?有什么工作可以继续深入?
一、论文速读
paper: https://arxiv.org/pdf/2310.15166.pdf
1.1 摘要
视觉推理需要多模态感知和对世界的常识性认知。最近,提出了多种视觉-语言模型(VLMs),在各个领域展现了出色的常识性推理能力。然而,如何利用这些互补的 VLMs 的集体力量很少被探索。现有的方法如集成,仍然难以实现这些模型之间所需的高阶通信聚合。在这项工作中,我们提出了 Cola,一种协调多个 VLMs 进行视觉推理的新范式。我们的关键洞察是,一个大型语言模型(LLM)可以通过促进利用它们不同且互补能力的自然语言通信,有效地协调多个 VLMs。广泛的实验表明,我们的指令调整变体 Cola-FT,在视觉问答(VQA)、外部知识 VQA、视觉蕴含和视觉空间推理任务上达到了最先进的性能。此外,我们展示了我们的上下文学习变体 Cola-Zero,在零次和少次射击设置中表现出竞争力的性能,无需微调。通过系统的消融研究和可视化,我们验证了协调器 LLM 确实理解了指令提示以及 VLMs 的各自功能;然后它协调它们,使得具有令人印象深刻的视觉推理能力。
1.2 论文概要总结
这篇论文提出了一种名为Cola的新范式,专注于视觉推理领域。以下是对论文的概要:
相关工作:
- 视觉推理任务通常包括视觉问答(VQA)、视觉蕴涵(visual entailment)等,要求模型理解图像内容并运用高级认知能力得出合理结论。
- 传统视觉推理方法依赖于复杂的架构或在特定数据集上训练,而大型预训练模型如VLM和LLM已显示出在零样本设置下的强大性能。
- 已有研究尝试结合VLM和LLM进行视觉推理,但如何有效协调这些模型的集体力量尚未充分探索。
主要贡献:
- 提出了Cola模型,使用大型语言模型作为协调器来整合多个视觉-语言模型的力量,以实现视觉推理。
- Cola模型在多个视觉推理任务上实现了最佳性能,包括VQA、外部知识VQA、视觉蕴涵和视觉空间推理。
- 进行了系统的实验和可视化分析,验证了Cola模型如何理解指令提示并协调VLMs以展示出色的视觉推理能力。
论文主要方法:
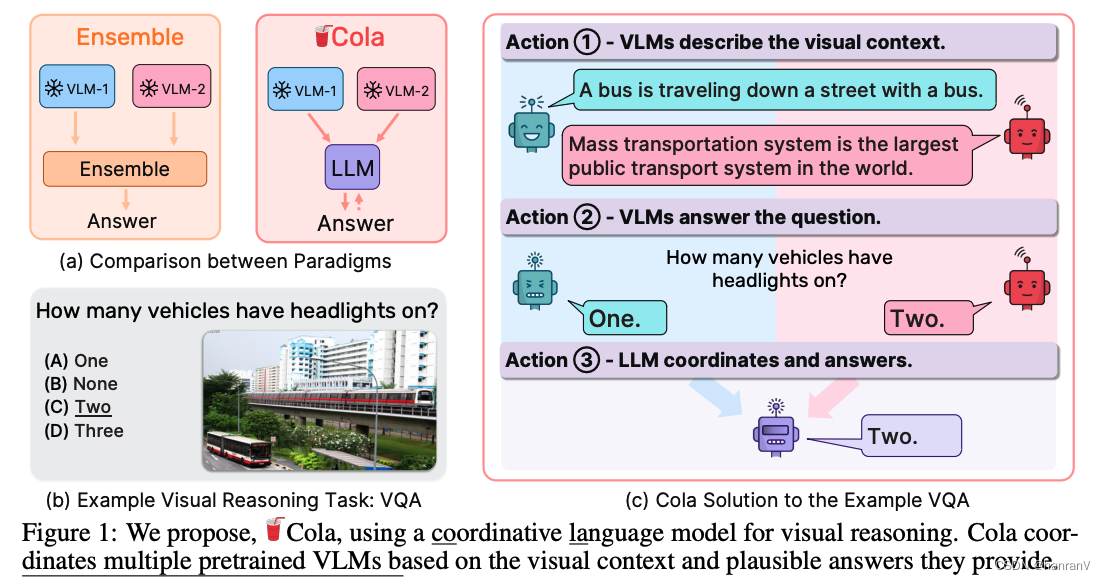
- Cola包含两种变体:Cola-FT(指令微调方法)和Cola-Zero(在上下文中学习方法)。
- Cola-FT通过预训练检查点初始化并仅微调语言模型部分,而Cola-Zero不需要指令微调。
- 通过协调器LLM,Cola利用自然语言交流来整合多个VLM的独特和互补能力。
实验数据:
- 在多个视觉推理任务上进行了广泛实验,包括A-OKVQA、OK-VQA、e-SNLI-VE和VSR等数据集。
- Cola-FT在一些数据集上达到了最佳性能,而Cola-Zero即使在零样本和少样本设置下也表现出竞争力。
未来研究方向:
- 探索非参数化工具在视觉推理中的应用,以增强Cola的性能。
- 将Cola应用于其他推理和规划任务,如图像生成和行动规划。
- 通过改进模型间的通信,使Cola在高风险应用中更具可解释性和安全性。
总之,这篇论文在视觉推理领域提出了一种创新的方法,通过结合LLM和VLM的优势,推动了该领域的发展。
二、论文精度
2.1 论文试图解决什么问题?
这篇论文试图解决的主要问题是如何有效地整合多个视觉-语言模型(VLMs)的集体力量来进行视觉推理。具体来说,论文关注的问题包括:
-
视觉推理的效率和有效性:虽然各种视觉-语言模型(如OFA、BLIP等)已经在处理视觉信息和进行一定的逻辑推理方面取得了显著成果,但这些模型往往是独立工作的,缺乏一个有效的机制来集成它们各自的优势。
-
模型协调的挑战:现有的方法(如模型集成和Socratic Models)在聚合多个模型进行视觉推理任务时面临着挑战,特别是在处理不同模型间的高阶通信和理解上。
-
零样本和少样本学习的能力:如何使模型能够在没有或很少有针对特定任务的训练数据的情况下仍然有效地进行视觉推理。
为解决这些问题,论文提出了一个名为Cola的新模型,它利用大型语言模型(LLM)作为协调器来整合多个VLM的能力,以提高视觉推理的整体性能和效率。这种方法旨在通过自然语言的沟通来利用各个VLM的独特和互补能力,从而实现更高效和有效的视觉推理。论文通过Cola模型的两个变体——Cola-FT(指令微调)和Cola-Zero(在上下文中学习)——展示了这一方法在多个视觉推理任务上的有效性。
2.2 论文中提到的解决方案之关键是什么?
论文中提出的解决方案——Cola模型的关键点主要包括:
-
使用大型语言模型作为协调器:Cola模型的核心是利用大型语言模型(LLM)作为协调器,来整合多个视觉-语言模型(VLMs)的能力。这一创新的方法允许不同的VLMs通过自然语言沟通进行交互,从而发挥它们各自的优势。
-
自然语言作为交流桥梁:Cola模型通过自然语言的形式来整合不同VLMs的输出,使得这些模型可以更好地“理解”彼此的贡献和限制。这种方法允许LLM有效地解释和协调VLMs提供的视觉描述和可能的答案。
-
Cola的两种变体:Cola模型有两种实现方式,即Cola-FT(指令微调)和Cola-Zero(在上下文中学习)。
- Cola-FT:通过预训练的模型进行指令微调,优化LLM以更好地理解和执行视觉推理任务。
- Cola-Zero:利用在上下文中学习的能力,使LLM能够在没有额外训练的情况下执行视觉推理任务,特别适合于零样本和少样本学习场景。
-
模板引导的推理:论文中使用特定的模板来引导LLM如何处理VLMs提供的信息,这包括对图像的描述、对问题的可能答案等,从而使LLM能够更有效地协调和整合这些信息。
-
系统化的实验和分析:Cola模型通过一系列系统化的实验和可视化分析,展示了其在各种视觉推理任务中的有效性和优越性能,如视觉问答(VQA)、外部知识VQA、视觉蕴涵和视觉空间推理等。
总的来说,Cola模型通过将大型语言模型作为协调器,以自然语言为桥梁,有效地整合了多个视觉-语言模型的力量,为视觉推理任务提供了一种新颖而高效的方法。
2.3 用于定量评估的数据集是什么?代码有没有开源?
论文中用于定量评估Cola模型的数据集包括:
-
Visual Question Answering v2 (VQA v2):这是一个大规模基准测试,包含超过100万张来自COCO数据集的图像和250,000多个人类生成的问题-答案对。它用于测试机器学习模型理解图像内容和自然语言问题的能力。
-
Augmented Outside Knowledge VQA (A-OKVQA):包含约25,000个问题,每个问题都配有多项选择答案。这个数据集的问题通常需要一些常识推理和对图像描绘情景的外部知识。
-
Outside Knowledge VQA (OK-VQA):包括超过14,000个需要外部知识来回答的问题。答案以自由文本直接答案形式提供。
-
e-SNLI-VE:这是SNLI-VE数据集的扩展版本,包含约190,000个问题对和人类注释的自然语言解释。任务是根据图像内容判断文本前提的真实性。
-
Visual Spatial Reasoning (VSR):包含65种图像中实例的空间关系(例如“在...下面”、“在...前面”、“面向...”等),超过10,000个问题对,与MS COCO数据集的6,940张图像相关联。
代码开源情况请关注论文作者
2.4 这篇论文到底有什么贡献?
这篇论文的主要贡献在于提出了一种新的模型——Cola,用于提高视觉推理任务的效果。具体的贡献可以总结如下:
-
创新的模型架构:Cola模型使用大型语言模型(LLM)作为协调器,以整合多个视觉-语言模型(VLMs)的能力。这种架构创新使得可以有效地利用各个VLM的独特和互补能力,进而提高视觉推理的准确性和效率。
-
提升视觉推理性能:通过实验,Cola在多个视觉推理任务上展示了其优越性能,包括视觉问答、外部知识视觉问答、视觉蕴含和视觉空间推理等。尤其是其两个变体,Cola-FT(指令微调)和Cola-Zero(在上下文中学习),在不同设置下均表现出色。
-
有效的零样本和少样本学习:Cola-Zero特别适用于零样本和少样本学习场景,这对于那些缺乏大量标注数据的应用领域尤为重要。
-
深入的系统分析:论文通过系统实验和可视化分析,深入探讨了Cola模型如何理解指令提示,并协调不同VLMs以实现显著的视觉推理能力。
-
跨任务的适应性:Cola模型在多个不同的视觉推理任务上展示了良好的适应性和迁移能力。
总体而言,这篇论文在视觉推理的领域中做出了重要的贡献,提出了一种新的方法来有效地整合不同模型的力量,为后续相关研究和应用提供了新的视角和解决方案。
2.5 下一步呢?有什么工作可以继续深入?
论文提出的Cola模型为未来的研究和发展指出了多个可能的方向:
-
拓展到更多视觉推理任务:虽然Cola在多个任务上表现出色,但还可以进一步探索其在更广泛的视觉推理任务中的应用,例如图像生成、行为预测或更复杂的视觉-语言交互任务。
-
改进模型协调能力:研究如何进一步优化LLM作为协调器的策略,以更有效地整合来自不同VLMs的信息,特别是在处理更复杂或细微差别的视觉场景时。
-
多模态学习与推理:将Cola应用于多模态学习领域,探索如何更好地结合视觉、语言、声音等不同模式的信息,以解决更为复杂的任务。
-
优化和简化模型结构:对Cola模型本身进行优化,例如减少参数量、提高计算效率,或者探索更为简化的模型结构,以适应资源受限的应用场景。
-
提升模型的解释性和安全性:研究如何使Cola模型的决策过程更加透明和可解释,这对于提高模型的可信度和在高风险领域的应用尤为重要。
-
跨领域迁移和泛化能力研究:探索Cola模型在不同领域和任务之间的迁移和泛化能力,例如从视觉问答迁移到医学图像分析或无人驾驶系统。
-
集成非参数化工具:探讨将非参数化工具,如数据库查询、知识图谱等与Cola模型结合,以提供更丰富的背景知识和上下文信息。