Python绘制几种常见的时序分析图
时间序列数据是一种按照时间顺序排列的观测值集合,每个观测值对应于一个特定的时间点。这种数据在许多领域中都具有重要的应用价值,如金融、经济、气候科学等。通过分析时间序列数据,可以帮助我们掌握潜在的模式、发现趋势和季节性波动等重要信息。
时间序列分析是一种技术,用于评估时间序列数据,旨在确定相关的统计数据和其他数据属性。其主要目标是研究市场趋势和经济周期的关键思想,任何受到影响的具有重复模式的时间序列都可能受到影响。
可视化对于从时间序列数据中获取有洞察力的信息至关重要,它可以帮助我们理解复杂的关系并做出明智的决策。本文将介绍如何使用Python绘制几种常见的时序分析图。
数据集
数据集地址:https://github.com/jbrownlee/Datasets/blob/master/monthly-sunspots.csv
数据集变量:数据集由 2 列组成 - 从 1749 年到 1983 年的“月份”和“太阳黑子”。它基本上描述了该数据集中记录的每个月在太阳上看到的太阳黑子的数量。
1、Statsmodels库
本次用到了Statsmodels,Statsmodels库是Python中一个强大的统计分析库,包含假设检验、回归分析、时间序列分析等功能,能够很好的和Numpy和Pandas等库结合起来,提高工作效率。支持Python3.8、3.9和3.10。
安装方法
Anaconda
conda install -c conda-forge statsmodelsPyPI (pip)
pip install statsmodels
如果不能下载,则加上国内源,命令如下:
pip install statsmodels -i https://pypi.tuna.tsinghua.edu.cn/simple
从源代码安装
您需要安装C编译器来构建统计模型。如果您是从github源代码而不是源代码版本构建的,那么您还需要Cython。您可以按照下面的说明获得Windows的C编译器设置。
如果你的系统已经安装了pip、编译器和git,你可以试试:
pip install git+https://github.com/statsmodels/statsmodels
依赖库
Python >= 3.8NumPy >= 1.18SciPy >= 1.4Pandas >= 1.0Patsy >= 0.5.2
例子
import statsmodels.formula.api as smf
import pandas as pd
import numpy as np
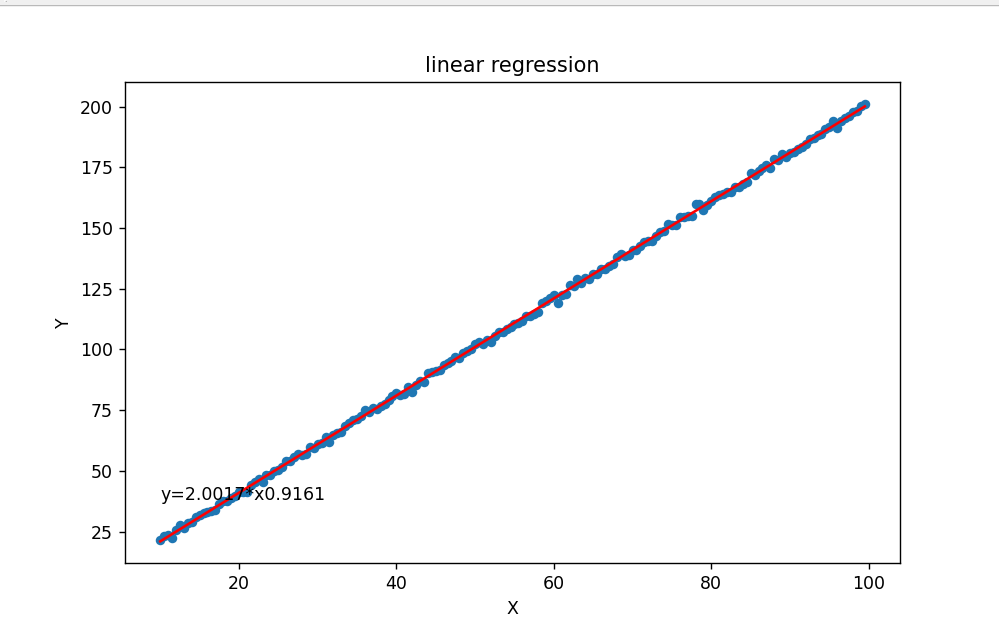
import matplotlib.pyplot as pltdata = pd.DataFrame({"X":np.arange(10,100,0.5)})
data["Y"] = 2 * data["X"] + 1 + np.random.randn(180)
mod = smf.ols("Y ~ X", data).fit()
print(mod.summary())data.plot(x="X", y="Y",kind="scatter",figsize=(8,5))
plt.plot(data["X"], mod.params[0] + mod.params[1]*data["X"],"r")
plt.text(10, 38, "y="+str(round(mod.params[1],4)) + "*x" + str(round(mod.params[0],4)))
plt.title("linear regression")
plt.show()
print(mod.summary())的输出结果:
OLS Regression Results
==============================================================================
Dep. Variable: Y R-squared: 1.000
Model: OLS Adj. R-squared: 1.000
Method: Least Squares F-statistic: 4.744e+05
Date: Mon, 13 Nov 2023 Prob (F-statistic): 7.49e-307
Time: 11:25:51 Log-Likelihood: -256.52
No. Observations: 180 AIC: 517.0
Df Residuals: 178 BIC: 523.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.0831 0.176 6.157 0.000 0.736 1.430
X 1.9993 0.003 688.746 0.000 1.994 2.005
==============================================================================
Omnibus: 0.781 Durbin-Watson: 2.104
Prob(Omnibus): 0.677 Jarque-Bera (JB): 0.462
Skew: 0.075 Prob(JB): 0.794
Kurtosis: 3.198 Cond. No. 141.
==============================================================================
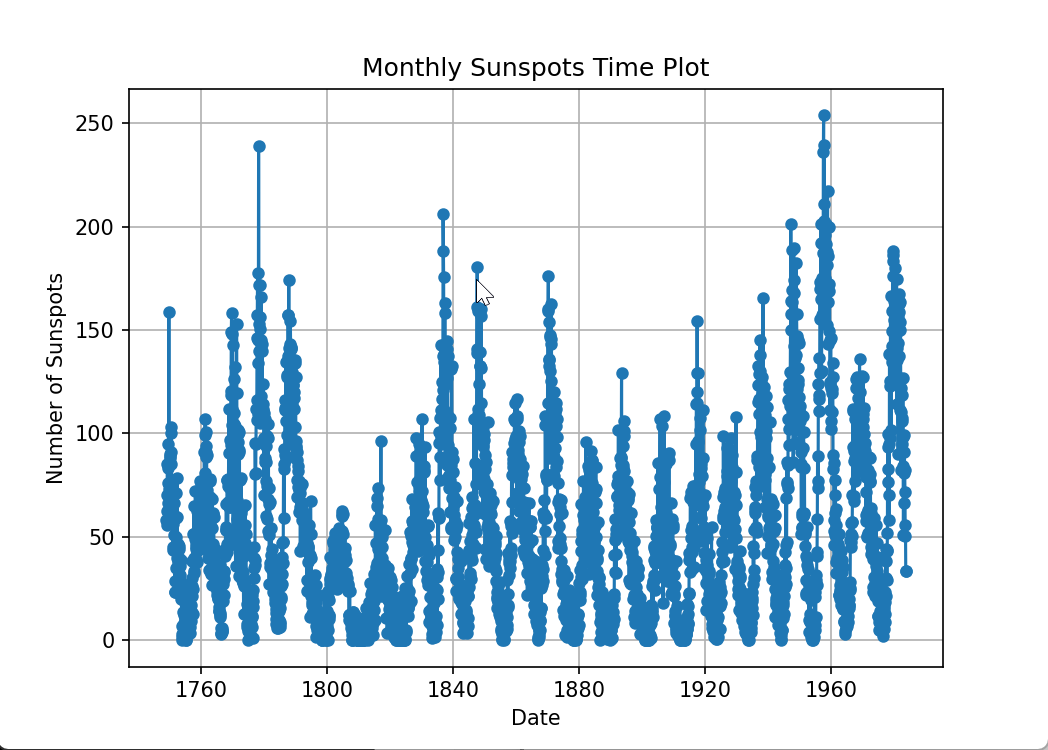
时间图
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-sunspots.csv"
data = pd.read_csv(url, parse_dates=['Month'], index_col='Month')
print(data)
# 时间图
plt.figure(figsize=(7, 5))
plt.plot(data.index, data['Sunspots'], marker='o', linestyle='-', markersize=5)
plt.xlabel('Date')
plt.ylabel('Number of Sunspots')
plt.title('Monthly Sunspots Time Plot')
plt.grid(True)
plt.show()
折线图
折线图是一种常见的数据可视化方式,它通过连接一系列数据点形成一条或多条线段来展示数据随时间或其他变量的变化趋势。折线图通常用于展示时间序列数据或其他有序数据的变化情况,例如股票价格、气温变化、销售数据等。
在折线图中,每个数据点通常表示为一个标记(如圆点、方块等),并通过直线段连接相邻的数据点。折线图的x轴通常表示时间或其他有序变量,而y轴则表示要展示的数据值。通过观察折线图的形状、趋势和波动情况,我们可以得出一些有用的信息和结论。
例如,在股票市场分析中,折线图可以用来展示股票价格的走势,帮助投资者判断股票的趋势和买卖时机;在气象学中,折线图可以用来展示气温、降雨量等气象数据的变化趋势,帮助人们更好地了解气候变化和预测天气情况。此外,折线图还可以通过添加多条折线来展示不同变量之间的关系和对比情况,例如展示不同地区的销售数据或不同产品的受欢迎程度等。
折线图是一种直观、简单的数据可视化方式,可以帮助我们更好地了解数据的变化趋势和规律,从而做出更明智的决策。
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
data = pd.read_csv("monthly-sunspots.csv", parse_dates=['Month'], index_col='Month')
print(data)
# 折线图
import matplotlib.pyplot as plt
plt.figure(figsize=(7, 5))
plt.plot(data)
plt.xlabel('Date')
plt.ylabel('Number of Sunspots')
plt.title('Monthly Sunspots Line Plot')
plt.grid(True)
plt.show()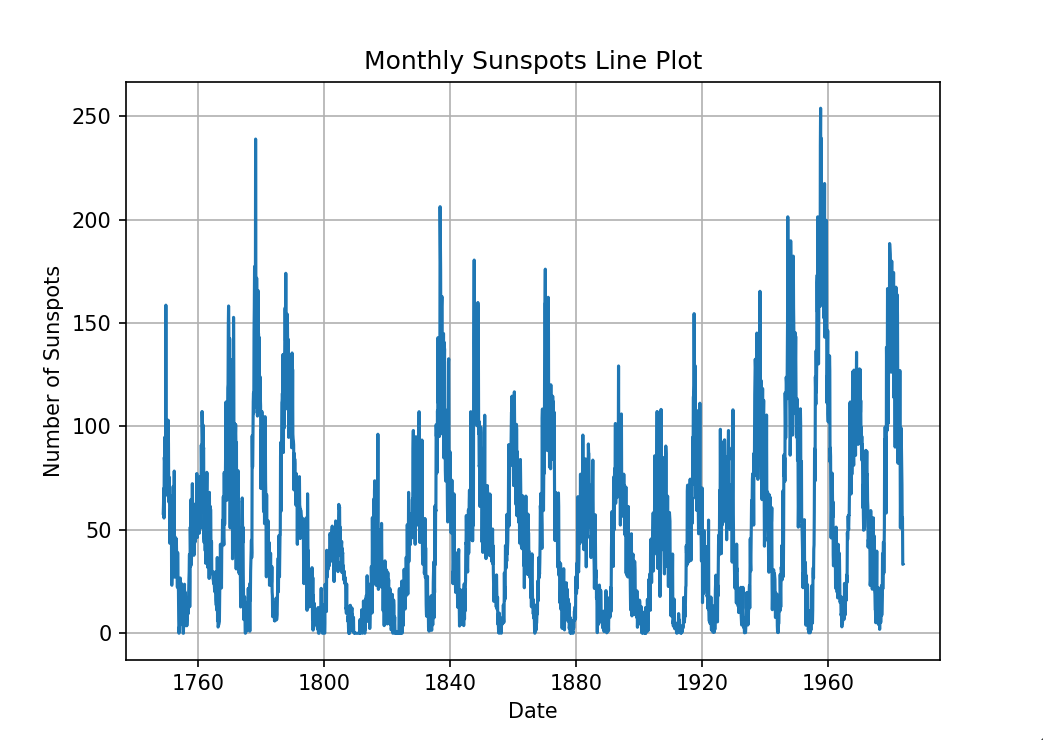
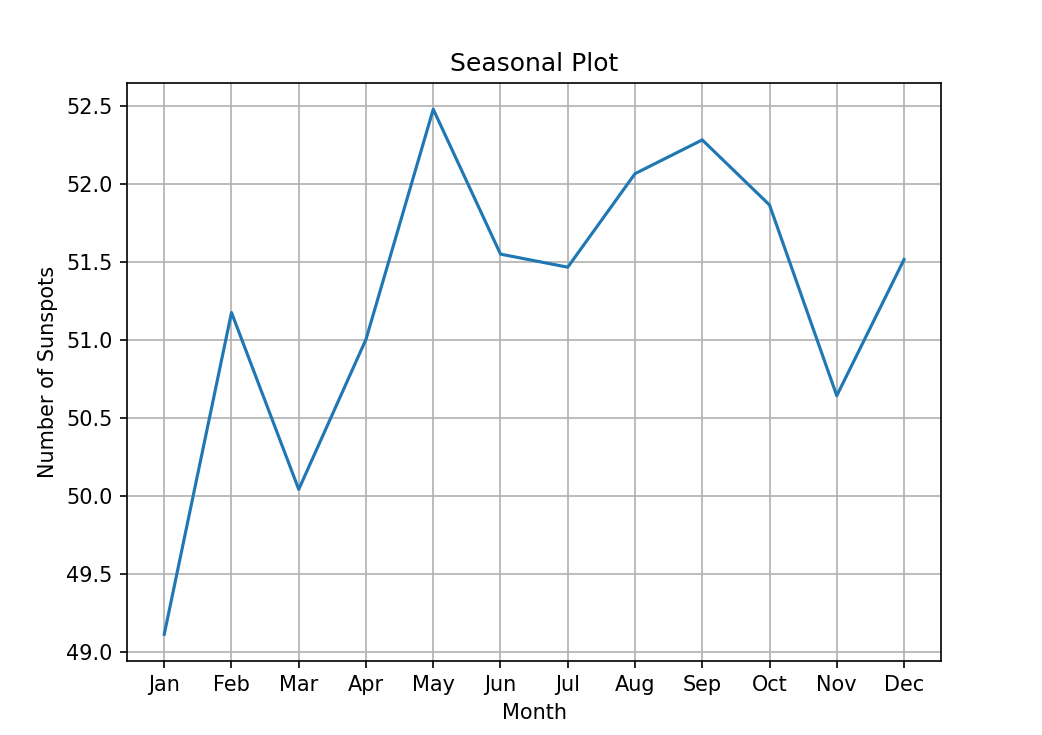
季节性图
季节性图是一种可视化时间序列数据的方式,它能够展示在特定时间间隔(如年、月、日等)内数据的重复模式。这种图通常用于观察和分析时间序列数据中的季节性变化,例如气候、销售、人口动态等。
季节性图通常以时间序列数据为x轴,以表现数值为y轴,将数据点在图上表示出来。为了更清晰地展示季节性变化,可以使用不同颜色或标记来表示每个季节的数据点。此外,可以使用趋势线或平滑曲线来拟合数据点,以帮助识别季节性模式的长期趋势。
季节性图可以用于各种领域,例如气候学、销售分析、人口统计学等。例如,在气候学中,季节性图可以用来展示气温、降雨量等气象数据的季节性变化;在销售分析中,季节性图可以用来观察商品销售在不同季节内的变化情况;在人口统计学中,季节性图可以用来展示人口数量在不同时间点的变化情况。
季节性图是一种强大的可视化工具,可以帮助我们更好地理解和分析时间序列数据中的季节性变化。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
data = pd.read_csv("monthly-sunspots.csv", parse_dates=['Month'], index_col='Month')
print(data)# 季节性图
plt.figure(figsize=(7, 5))
sns.lineplot(x=data.index.month, y=data['Sunspots'], ci=None)
plt.xlabel('Month')
plt.ylabel('Number of Sunspots')
plt.title('Seasonal Plot')
plt.xticks(range(1, 13), labels=['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])
plt.grid(True)
plt.show()
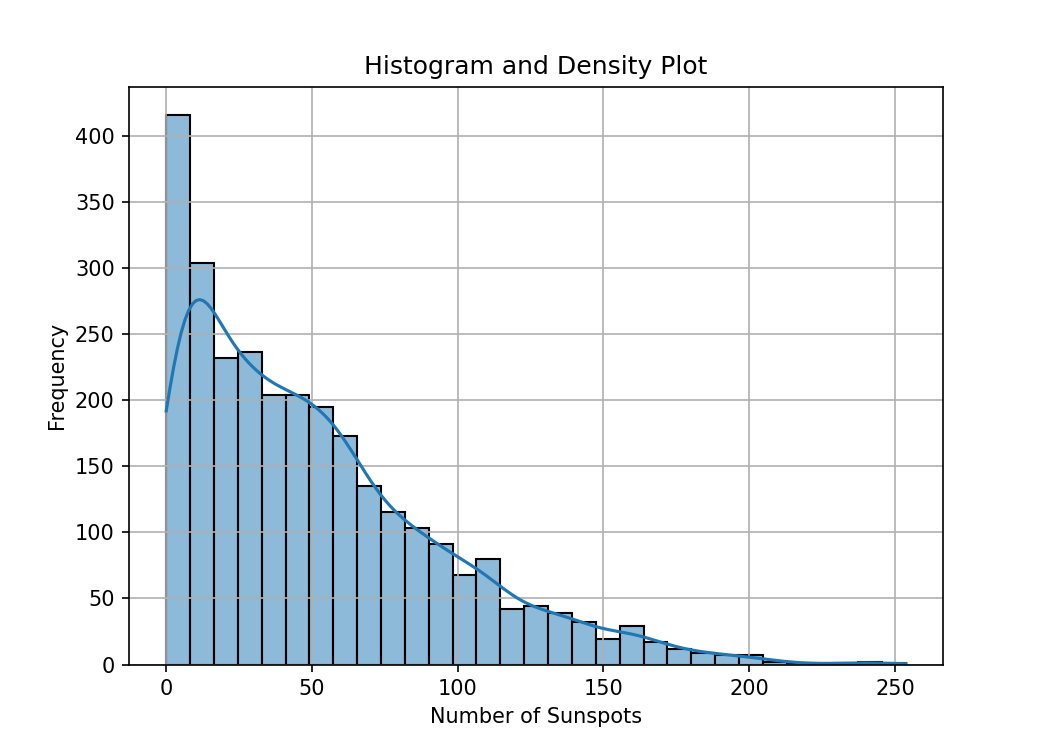
直方图和密度图
直方图和密度图是两种用于可视化数据分布的图形。
直方图是一种条形图,它显示了数据分布的频率。每个条形的高度表示数据值出现的次数,条形的宽度表示数据值的范围。通过观察直方图,我们可以了解数据的集中趋势、离散程度以及可能存在的异常值。在绘制直方图时,可以选择不同的颜色和柱状宽度以增强视觉效果。
密度图则是一种用于显示数据分布密度的图形。与直方图不同,密度图显示的是数据点在某个范围内的密集程度,而不是具体的数值。密度图通常用于展示数据的概率密度,特别是在大数据集或连续变量的情况下。通过观察密度图,我们可以了解数据的分布情况以及是否存在集中或离散的趋势。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
data = pd.read_csv("monthly-sunspots.csv", parse_dates=['Month'], index_col='Month')
print(data)# 直方图和密度图
plt.figure(figsize=(7, 5))
sns.histplot(data['Sunspots'], kde=True)
plt.xlabel('Number of Sunspots')
plt.ylabel('Frequency')
plt.title('Histogram and Density Plot')
plt.grid(True)
plt.show()
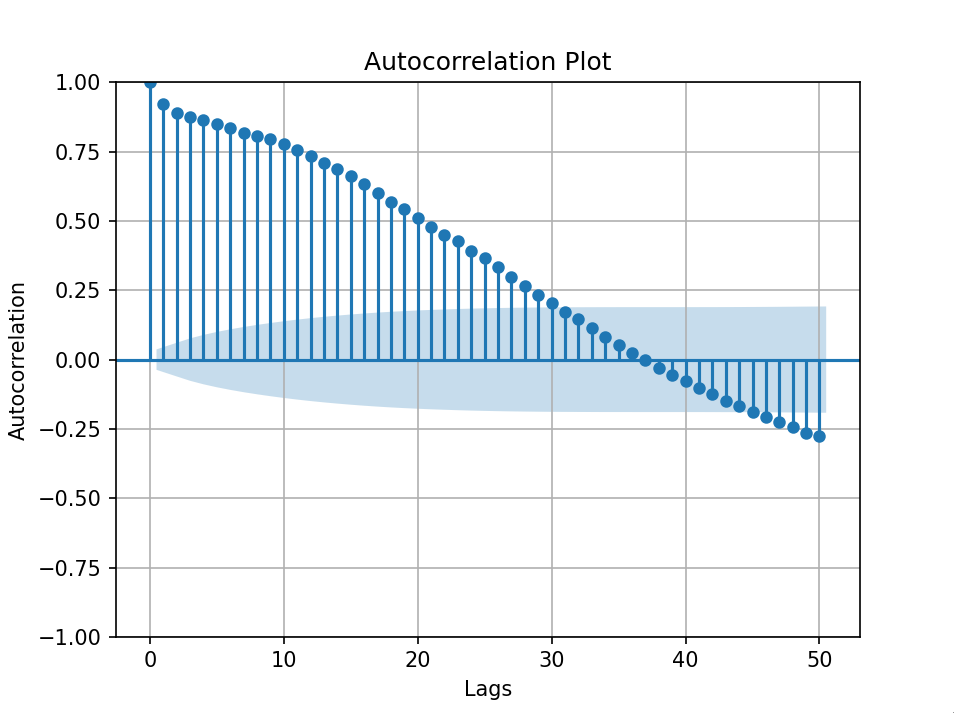
自相关图
自相关图是一个平面二维坐标悬垂线图。横坐标表示延迟阶数,纵坐标表示自相关系数。它是一个重要的统计工具,用于分析时间序列数据的重复模式和周期性趋势。通过观察自相关图,我们可以确定数据之间的相似性如何随时间变化,并以此为基础进行预测或解释。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
data = pd.read_csv("monthly-sunspots.csv", parse_dates=['Month'], index_col='Month')
print(data)# 自相关图
# plt.figure(figsize=(7,5))
plot_acf(data['Sunspots'], lags=50)
plt.xlabel('Lags')
plt.ylabel('Autocorrelation')
plt.title('Autocorrelation Plot')
plt.grid(True)
plt.show()
PACF图
PACF图是指偏自相关函数图,它衡量的是任意时间点与该时间点前的一段时间内的观测值的相关程度,并消除了其他滞后值的影响。偏自相关函数(PACF)衡量的是在控制了所有更短滞后的影响后,一个时间序列和它自身滞后版本之间的相关性。
在PACF图中,x轴代表滞后数,y轴代表偏自相关系数。与ACF图类似,PACF图中的每一个滞后数都有一个代表偏自相关系数的垂直线,同时还有两条水平蓝线表示置信区间。
通过对ACF图和PACF图的分析,可以得出数据可能适合的模型。例如,如果ACF图在某个点上截尾,而PACF图在该点后呈现出拖尾的形式,那么数据可能适合AR模型。如果ACF图在某个点后呈现出拖尾的形式,而PACF图在该点上截尾,那么数据可能适合MA模型。如果ACF图和PACF图都呈现出拖尾的形式,那么数据可能适合ARMA模型。
PACF图是一种分析时间序列数据的重要工具,可以帮助我们更好地理解数据的内在结构和关系。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
data = pd.read_csv("monthly-sunspots.csv", parse_dates=['Month'], index_col='Month')
print(data)# PACF图
# plt.figure(figsize=(7, 5))
plot_pacf(data['Sunspots'], lags=50)
plt.xlabel('Lags')
plt.ylabel('Partial Autocorrelation')
plt.title('Partial Autocorrelation Function (PACF) Plot')
plt.grid(True)
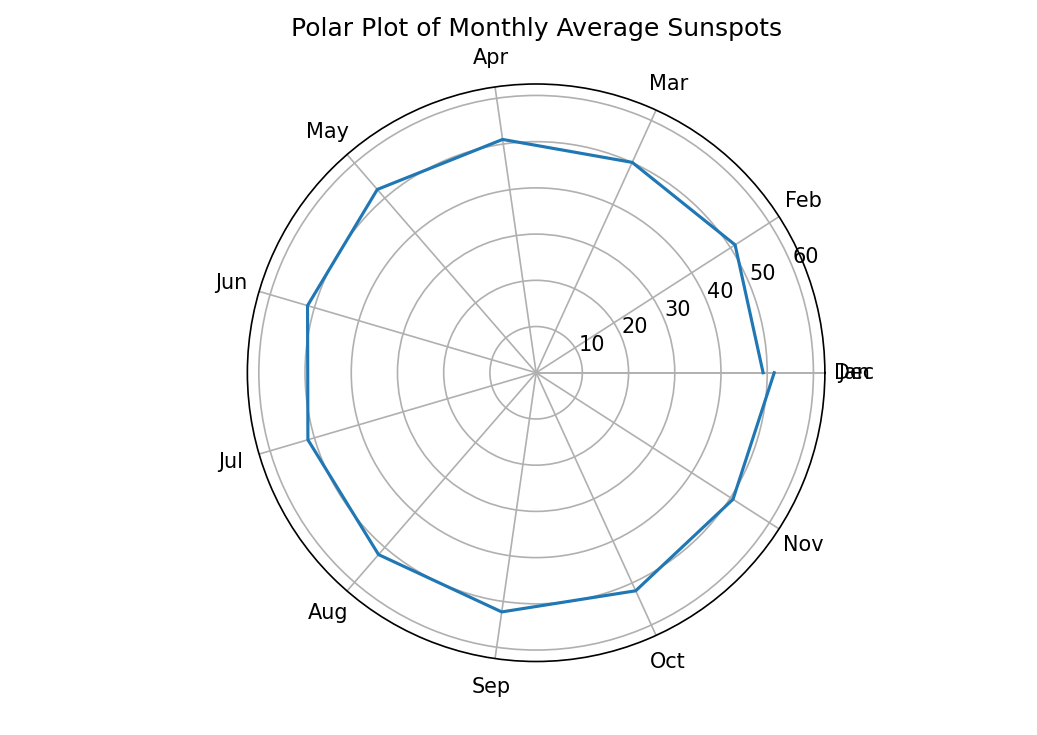
plt.show()极坐标图
极坐标图是一种用于表示方向性和距离信息的图形,常用于表示地理信息系统中的数据。在极坐标图中,每个点都有一个相对于极点的距离和角度信息,可以用来表示地理信息中的经纬度、方向和高度等数据。
在极坐标图中,角度通常以正北方向为0度,顺时针方向增加角度值。距离则通常以极点为原点,向各个方向延伸,单位可以根据需要进行设定。
极坐标图可以用于各种领域,例如物理学、工程学、地球物理学等。在地球物理学中,极坐标图可以用于表示地震数据、地磁数据等,以便更好地分析和研究地球的物理性质。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
data = pd.read_csv("monthly-sunspots.csv", parse_dates=['Month'], index_col='Month')
print(data)# 从上述数据集“Monthly Sunspots”的索引中提取月份和年份
data['Month_Num'] = data.index.month# 按月份对数据进行分组,计算每个月的平均太阳黑子数
monthly_average = data.groupby('Month_Num')['Sunspots'].mean()# 极坐标图θ(角度)和半径(长度)设置
theta = np.linspace(0, 2 * np.pi, len(monthly_average))
radii = monthly_average.values# 极坐标图
plt.figure(figsize=(7, 5))
plt.polar(theta, radii)
plt.title('Polar Plot of Monthly Average Sunspots')
plt.xticks(theta, ['Jan', 'Feb', 'Mar', 'Apr', 'May','Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])# 设置y轴限制以适应数据
plt.ylim(0, radii.max() + 10)
plt.show()
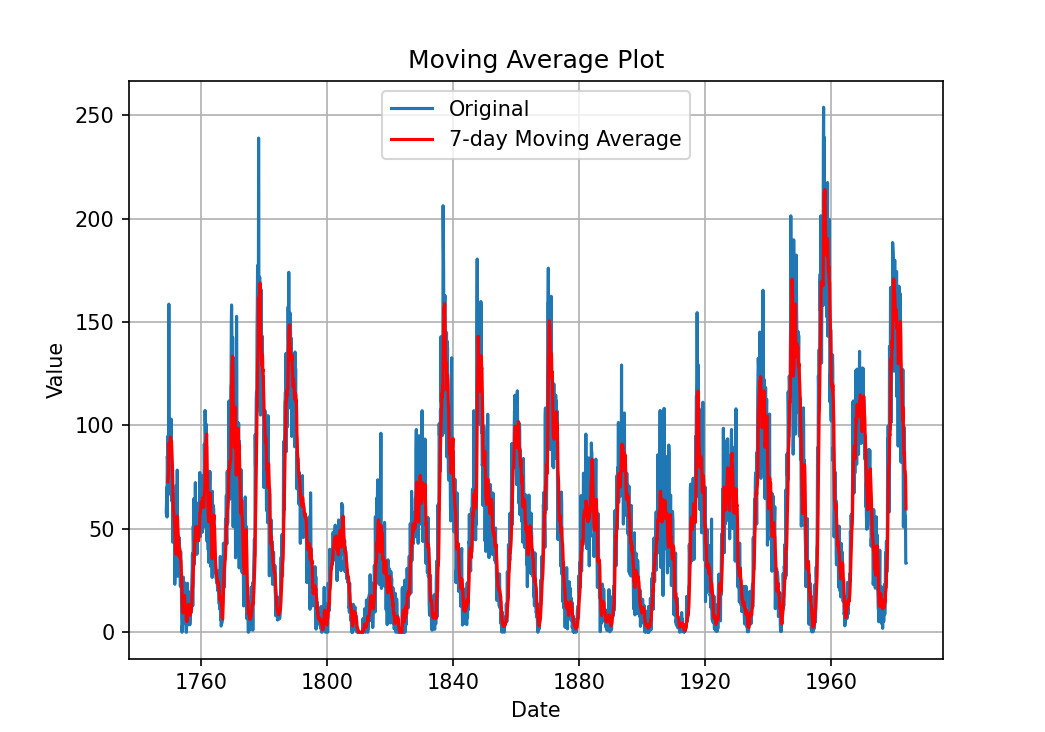
移动平均线图
移动平均线图是一种常用的技术分析工具,它通过计算一系列连续价格数据的平均值,以反映市场趋势和价格波动情况。在移动平均线图中,通常会绘制一组不同周期的移动平均线,以反映市场在不同时间段内的平均成本和趋势。
移动平均线图可以用于股票、期货、外汇等交易市场,以帮助交易者更好地把握市场趋势和价格波动情况。在移动平均线图中,不同周期的移动平均线会以不同颜色的线条表示,以方便交易者进行比较和分析。
通过观察移动平均线图,交易者可以发现市场中的趋势和转折点,以及价格波动的情况。例如,当短期移动平均线向上穿过长期移动平均线时,可能预示着市场即将上涨;而当短期移动平均线向下穿过长期移动平均线时,可能预示着市场即将下跌。此外,交易者还可以通过观察不同周期的移动平均线来分析市场的支撑和压力位,以及趋势的持续时间和强度。
移动平均线图是一种重要的技术分析工具,可以帮助交易者更好地理解市场趋势和价格波动情况,从而做出更明智的交易决策。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf# 加载每月太阳黑子数据集
data = pd.read_csv("monthly-sunspots.csv", parse_dates=['Month'], index_col='Month')
print(data)# 移动平均线图
plt.figure(figsize=(7, 5))
values = data['Sunspots']# 7天移动平均线
rolling_mean = values.rolling(window=7).mean()
plt.plot(values, label='Original')
plt.plot(rolling_mean, label='7-day Moving Average', color='red')
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Moving Average Plot')
plt.legend()
plt.grid(True)
plt.show()
参考文章:https://mp.weixin.qq.com/s/4tZan5-1X94oITmCCLshOw