自然语言处理:电脑如何理解我们的语言?

☁️主页 Nowl
🔥专栏《机器学习实战》 《机器学习》
📑君子坐而论道,少年起而行之

文章目录
编辑
常见方法
1.基于词典的方法
2.基于计数的方法
基于推理的方法
Bert
input_ids
attention_mask
token_type_ids
结语
在广阔的人工智能领域中,有着这样一个神奇的分支——自然语言处理,它研究人工智能在各种语言场景中的应用,我们不禁会思考这样一个问题,电脑是怎么理解我们的自然语言的呢。

常见方法
1.基于词典的方法
介绍
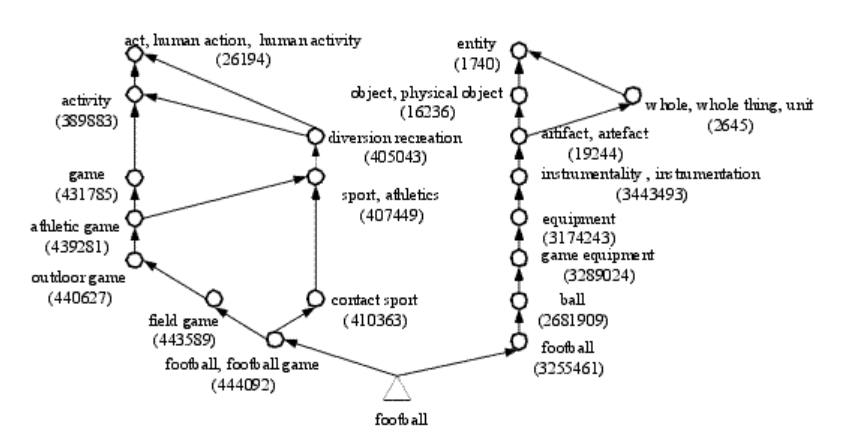
在自然语言处理学科发展的早期,人们将一些词语的关系串成一个网络,这个网络也叫作同义词词典,类似下图,从一个单词出发可以得到与它相关的近义词,反义词等,通过这个网络,可以让计算机了解单词之间的相关性(要找到一个词的近义词,就可能用某种图搜索方法去寻找)
最著名的同义词词典是WordNet,由普林斯顿大学开发
同义词词典的弊端
- 不灵活,我们的语言习惯会随着时间产生变化,而词典不会,如果要修改的话牵扯到的劳力又太大,而且总是要更改,浪费时间与精力
- 无法完全表达单词之间的联系,我们知道语言是很精妙的,有时候我们也无法解释一些词语,因为词语的意思可能与语境,单词顺序有关,而同义词词典难以实现这一功能
2.基于计数的方法
语料库
自然语言处理领域有非常多的语料库,这些语料库收录了许多人类写的文字,包括一些作家的文章,这些语料库可以看作是一个自然语言处理领域通用的数据集
然后呢我们要对其中的文字进行编码(因为计算机只能理解数字),考虑下面这一句话
sentence = "I like these stars because they are bright"我们将他们编码,做成一个编码字典
words = {'I': 0, 'like': 1, 'these': 2, 'stars': 3, 'because': 4, 'they': 5, 'are': 6, 'bright': 7}真实的编码字典复杂得多,这里仅做示例
这时如果我们要表达这一句话
"these stars are bright"我们就可以用这样的编码表示
[2, 3, 6, 7]分布式假设
分布式假设的思想是这样的,一个单词本身没有意义,它的意义与它上下文的单词有关,这点我们也能理解,就像我们常常在英语考试中通过上下文来理解某个不认识的单词一样
想想看,我们统计了两个不同单词的上下文,发现他们的上下文差不多,那么我们是不是就可以猜测这两个单词相关呢,这便是基于统计的方法,统计单词的上下文,以理解词与词之间的关系
假设要统计一个单词前后的词,以上面的例子举例就是这样
{'0': [1], '1': [0, 2], '2': [1, 3], '3': [2, 4], '4': [3, 5], '5': [4, 6], '6': [5, 7], '7': [6]}得到了一个记录单词和它上下文的字典
基于推理的方法
上文中的基于词典,基于计数等方法都太片面,要理解一个单词的意思我们应该从多个维度考虑
我们在上文中了解到了给单词编码的原理,我们不妨拓展一下,除了单词本身可以编码,我们还能编码什么信息呢
我们经常听过这样一句话,"要抓重点",基于这个思想,我们可以告诉机器是否要省略某些词
还有,当语料库有许多个句子时,我们是不是要区分哪些词是哪句话的呢
基于这些思想,我们接着往下看吧
Bert
bert模型是一个自然语言处理任务的模型,在本章中我们将用它来进行讲解
from transformers import BertTokenizer这句代码导入了bert模型的分词器,它用来处理句子的基础信息
input_ids
input_ids是词编码,代表了一个单词在词表中的位置,这是一个单词的基本信息
from transformers import BertTokenizer# 指定分词模型为中文模型
token = BertTokenizer.from_pretrained('bert-base-chinese')
# 进行分词,固定长度为17,返回类型为pytorch张量
sentence = token.batch_encode_plus(["你好,这是一个编码工具", "它是一个预训练模型"], return_tensors='pt', padding='max_length', max_length=17)print(sentence["input_ids"])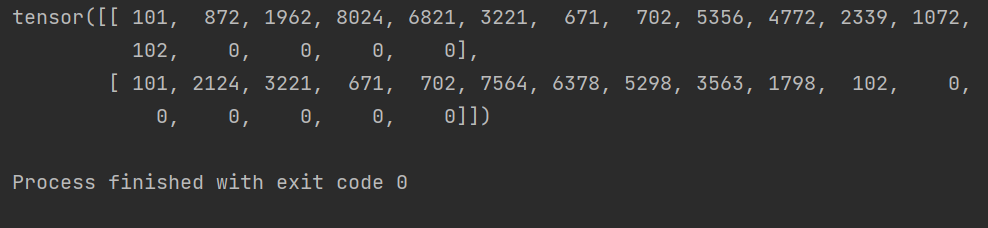
attention_mask
attention_mask表示是否要忽略某个词,它一般用在这些场景中
- 我们编码句子时肯定需要确定一个固定长度,不统一长度的话之后进行运算会很麻烦,这时attention_mask就可以告诉模型要忽略那些多出句子长度的地方了
- 在一些具体任务中,如单词填空,我们可以使用mask来遮住要预测的词,实现训练模型的效果
from transformers import BertTokenizertoken = BertTokenizer.from_pretrained('bert-base-chinese')
sentence = token.batch_encode_plus(["你好,这是一个编码工具", "它是一个预训练模型"], return_tensors='pt', padding='max_length', max_length=17)print(sentence["attention_mask"])
返回了两个句子的attention_mask,0代表忽略,这个例子中忽略了自动补齐长度的单词
token_type_ids
token_type_ids表示了这个词的种类,通常用于区分不同句子的词
from transformers import BertTokenizertoken = BertTokenizer.from_pretrained('bert-base-chinese')
sentence = token.batch_encode_plus(["你好,这是一个编码工具", "它是一个预训练模型"], return_tensors='pt', padding='max_length', max_length=17)print(sentence["token_type_ids"])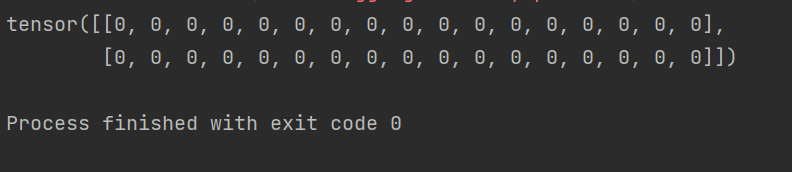
由于这个例子中的编码器只是进行批处理,并未在意句子的不同,所以返回的token_type_ids是一样的
结语
- 我们在这一篇文章中了解到了计算机理解自然语言的基本思想——将单词编码成数字
- 同时我们还介绍了一些其他因素,是否要忽略某些词,考虑词属于哪些句子等
- 要理解一个句子的过程是复杂的,跟着本专栏继续探索吧
感谢阅读,觉得有用的话就订阅下本专栏吧,有错误也欢迎指出