【三维目标检测】【自动驾驶】IA-BEV:基于结构先验和自增强学习的实例感知三维目标检测(AAAI 2024)
系列文章目录
论文:Instance-aware Multi-Camera 3D Object Detection with Structural Priors Mining and Self-Boosting Learning
地址:https://arxiv.org/pdf/2312.08004.pdf
来源:复旦大学 英特尔Shanghai Key Lab /美团
文章目录
- 系列文章目录
- 摘要
- 一、前言
- 二、提出解决方案
- 三、主要方法
- 3.1 特征编码器
- 3.2 结构先验挖掘
- 01.基于类别的深度解码器
- 02.基于实例的监督
- 3.3 Self-Boosting 学习
- 01.稀疏的Cost Volume构建
- 02.迭代立体匹配
- 3.4 BEV特征处理器
- 四、实验效果
- 总结
摘要
多相机三维目标检测是自动驾驶领域的一个重要研究方向,常用方法是将多视图图像特征转换到统一的鸟瞰图(BEV)空间进行感知。我们提出了一种实例感知的鸟瞰图检测器(IA-BEV),它在深度估计过程中引入了图像平面上的实例感知信息。在nuScenes数据集上,方法在使用两个关键帧的情况下达到了最先进的结果
一、前言
近年来,多相机三维目标检测在自动驾驶领域受到了广泛的关注。与激光雷达相比,其摄像头能够更好地捕获物体的语义信息,并且具有更低的成本优势。这个领域的最新趋势是将多视图图像特征转换到统一的BEV空间进行后续的感知任务。这种表示方式有利于在BEV空间中对来自多个传感器和时间戳的信号进行对齐,从而为下游的任务(如检测、地图分割和运动规划)提供了一种通用的表示形式。
在基于BEV的感知流程中,深度估计是从图像视图到BEV的透视投影的关键环节。早期的方法从单目图像中隐式或显式地估计深度。受到多视立体匹配技术的启发,后续的方法利用连续的摄像机帧构建cost volumn进行立体匹配。由于深度估计的提升,这些方法获得了高质量的BEV特征,从而明显提高了检测性能。
尽管已经取得了明显的进展,但由于现有的方法将每个像素都看得同等重要,因此忽略了前景物体中的固有属性。事实上,前景物体可以表现出类内一致性和实例间的差异性,我们认为这可以用来改善深度估计。 一方面,相同语义类别的物体具有相似的结构先验 ,这体现为两点:
1)图像中物体的尺度与其真实深度有一定的相关性,这种相关性通常对相同语义类别的物体是一致的,而对不同类别的物体是不同的。例如,图像中汽车的尺度与其真实深度成反比,但即使在相同的深度下,汽车和行人的尺度也有明显的差异。
2)相同语义类别的物体具有一致的内部几何结构。如图1(b)所示,当从图像平面上分离观察时,相同类别(汽车)的物体具有相似的相对深度分布。
另一方面,对于不同的实例物体,即使在同一类别中,由于分辨率和遮挡状态的不同,它们的视觉外观也有很大的差异 。因此,对不同实例物体的深度估计难度也是不同的。如图1所示,左侧汽车图像包含更多的纹理和形状细节,从而降低了深度估计的不确定性。虽然一些方法探索了二维物体先验用于三维物体检测,但它们主要利用透视投影后的检测到的二维物体,从而忽略了它们改进深度估计以增强BEV特征构建的潜力。

二、提出解决方案
基于上述观察,提出了一种 利用二维实例感知增强基于BEV检测器的深度估计算法,即IA-BEV。如图1(d)所示,我们的IA-BEV首先将场景分解为各个物体,然后利用这些物体的固有属性,通过两个新颖的模块分别有效地辅助单目和立体深度估计:
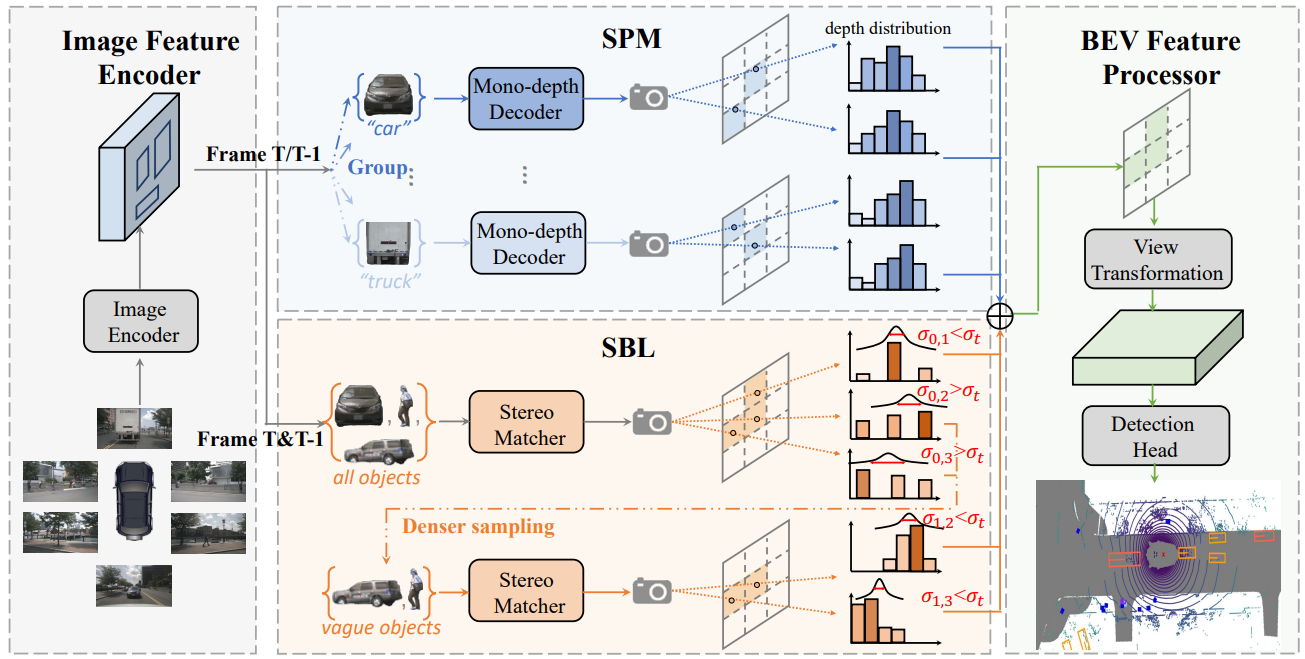
图2|我们提出方法的详细设计。给定从多视角摄像头收集的图像,我们首先使用现成的二维场景解析器解析前景物体。然后,这些物体及其图像特征被并行地输入到我们提出的SPM和SBL中,通过从类别和实例两个角度探索物体属性来进行有效的深度估计。最后,SPM和SBL的输出被合并,得到最终的图像深度,并用于常规的视图变换和基于BEV的检测。T帧和T-1帧被分别输入到SPM中,而它们被同时输入到SBL中,因为这里的立体匹配需要多帧时间信息
第一个模块是基于类别的结构先验挖掘(SPM),它将属于相同或 相似语义类别的物体分组,由各自的轻量级深度解码器进行处理,以更好地利用结构先验。然而,仅仅通过分组输入来期望这些并行解码器主动学习类别特定的模式是非常困难的,导致性能不佳。为了解决这个问题,我们 显式地将物体尺度属性编码为额外的输入,并应用两个基于实例的损失函数来监督粗略的实例绝对深度和细致的内部物体相对深度预测。
第二个模块是自增强学习(SBL),它以与类别无关的方式运行,侧重于迭代地区分和强化较难的物体。每次迭代,首先根据立体匹配的不确定性将物体划分为两个组。然后,不确定性较高的组(表示估计不准确)在后续的迭代中得到进一步的强化。由于后期迭代中需要处理的前景区域逐渐变得稀疏,我们可以在不确定性范围内为选定的有挑战性的样本设置更密集的深度假设,以便对它们进行更全面的立体匹配。最后,在SPM和SBL的结合深度估计的基础上,进行常规的视图变换过程,构建BEV特征用于最终检测。
三、主要方法
IA-BEV包含四个关键组成部分:特征编码器,负责提取图像特征和解析前景物体;结构先验挖掘方法(SPM),通过利用相同类别物体的结构一致性来增强单目深度估计;自增强学习策略(SBL),在立体深度估计中强化模糊的物体;BEV特征编码器,用于渲染特征和在BEV空间中检测物体。
3.1 特征编码器
多视角摄像头收集的图像,使用主干网络(如ResNet-50或ConvNeXt)提取图像特征。同时,我们使用成熟的实例分割器解析前景物体,这里我们保留了物体所有像素的特征,而不是汇总成一个向量,因为我们的目标是为整个物体区域密集地预测深度。随后使用 SPM 和 SBL ,发挥物体固有属性在深度估计中的潜力。
3.2 结构先验挖掘
01.基于类别的深度解码器
从单目图像估计深度具有挑战性,因为它需要理解不同语义物体尺度与深度值之间的关系。 现有基于BEV的方法采用流行的图像主干网络作为特征编码器,以赋予模型强大的语义捕获能力,但是它们依赖单个深度解码器同时学习多个语义类别的尺度到深度映射模式,增加了优化的负担 。
为了简化不同语义类别的学习过程,设计了 多个并行的轻量级深度解码器,其中每个解码器负责处理属于同一类别的物体,如图2所示。具体地,我们首先将所有前景物体划分成若干不重叠的语义组。然后,以从语义组中提取的物体特征,我们将物体特征和框参数(即标准化的框高和宽)同时输入轻量级深度解码器。在每个深度解码器中,框参数通过线性映射进行编码,然后使用SE模块与物体特征进行融合。最后,输出将通过卷积层预测当前物体区域的深度。最后,通过合并所有实例预测的深度,就可以获得单目估计的深度。
02.基于实例的监督
在典型的基于BEV的感知流程中,深度预测通过像素级交叉熵损失进行监督,这无法捕获细粒度的实例级提示,从而增加了上述类别特定深度解码器学习语义结构先验的难度。因此,我们设计了两个新的损失函数来鼓励学习 粗略的实例绝对深度 和 细致的实例内部的相对深度。首先,我们将物体离散的深度预测转换为连续的深度值。然后,我们将激光雷达点投影到图像平面上以获得GroundTruth深度,并保留那些与前景物体相交的部分来构建监督信号。
此时,我们同时拥有预测值和GroundTruth 深度值。为了明确监督实例级深度预测,对于每个物体,我们提取一个绝对深度值 Dgt 作为回归目标。值得注意的是,由于传感器存在误差,在GroundTruth 深度中存在一些离群值,这给我们的监督模型带来了巨大挑战。因此,我们首先将所有的深度值散点到预定义的深度bins中,然后仅对在投票数最大的深度仓中的值取平均数,作为计算绝对深度损失 dgt。另外,我们还计算相对深度损失以鼓励特定解码器学习细粒度的物体几何模式。
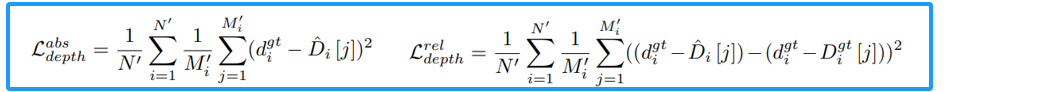
3.3 Self-Boosting 学习
基于时间的立体匹配技术依赖于时间维度上的几何一致性,进行深度估计。具体地,对于T帧中的每个像素,我们最初沿深度通道提出几个深度假设。然后,这些假设通过在T帧和(T-1)帧之间的单应变换投影到(T-1)帧中,以构建成本体积并学习它们之间的最佳匹配。在上述过程中,主要障碍在于为大量高分辨率图像特征中的像素和密集的假设构建三维成本体积带来的巨大内存开销。但是,在我们的场景中,图像区域不应该一视同仁。
首先,与背景区域相比,前景物体更重要。其次,视觉清晰度较低的物体的深度估计更具挑战性,应该给予更多关注。因此,我们设计了一种自增强策略,迭代地关注较难的物体区域,这进一步允许根据不同区域自适应地调整成本体积构建的粒度,从而在成本和效果之间实现更好的权衡。
01.稀疏的Cost Volume构建
为了提高效率,我们主要关注探索T帧中前景物体的立体匹配行为,这打破了传统的密集Cost Volume 构建范式。因此,我们将这样的过程改写为如下介绍的稀疏格式。我们使用T帧和(T-1)帧之间的单应变换对其进行变换以获取对应的投影位置,对于不同深度假设的每个像素,我们在(T-1)帧中建立其对应的像素,然后组合它们的特征生成稀疏Cost Volume。随后,使用三维稀疏卷积计算匹配分数。
以坐标(u, u) 以及对应的深度假设 dh为例,对第T帧和第T-1帧之间的 homography warping来获得相应投影:
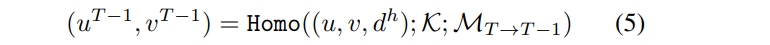
式中,K为摄像机的固有参数,MT→T-1 为从第T 到 T-1帧的变换矩阵。按照上述过程,对于每一个具有不同深度假设的目标像素,我们建立其与(T-1)帧像素的对应关系,然后与特征组合,生成稀疏代Cost Volume 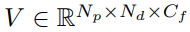
,其中Np和Nd 分别为前景像素个数和深度假设个数,Cf 为特征通道维数。随后,使用3D稀疏卷积计算匹配分数。
02.迭代立体匹配
在第一轮中,为了有效识别视觉细节丰富的物体,我们为前景物体中的所有像素均匀采样稀疏深度假设。然后构建稀疏Cost Volume,计算匹配分数。我们沿像素深度通道计算均值和标准差。当均值和标准差很小时,深度假设已经被成功验证来找到最佳匹配。相反,较大的均值和标准差,意味着多个深度假设被优先考虑,因此应该进一步得到增强。因此,我们将匹配分数标准差小于预定义阈值的像素视为满意的结果,并在下一迭代中对其进行过滤。对于剩余的像素,它们的均值和标准差可以提供更准确的搜索范围,这有助于为下一迭代更有效地提出深度假设。根据均值和标准差,我们更新下一迭代的深度采样范围。
我们进一步为剩余像素均匀采样多个深度假设。深度假设将在下一迭代中用于构建稀疏Cost Volume 和类似的计算均值和标准差。由于不同迭代的深度假设数量不同,我们采用插值操作填充所有预定义的深度bin进行对齐。如图4所示,所提出的自增强学习策略可以在早期迭代中区分主要清晰的物体区域,从而节省资源强化模糊的物体。
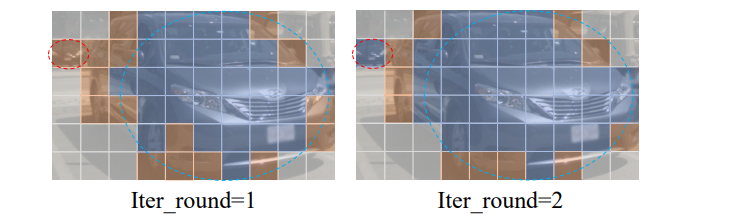
SBL中过滤和剩余patch的可视化。灰色斑块表示背景区域,蓝色和橙色斑块分别表示过滤后的斑块和剩余的斑块。我们使用红色和蓝色虚线圆圈分别突出显示模糊和清晰的对象
3.4 BEV特征处理器
通过求和从SPM和SBL预测的单目和立体深度,可以得到用于从多相机图像渲染BEV特征的最终深度预测。之后,BEV特征将被输入到常规的检测头进行最终的三维检测。
四、实验效果
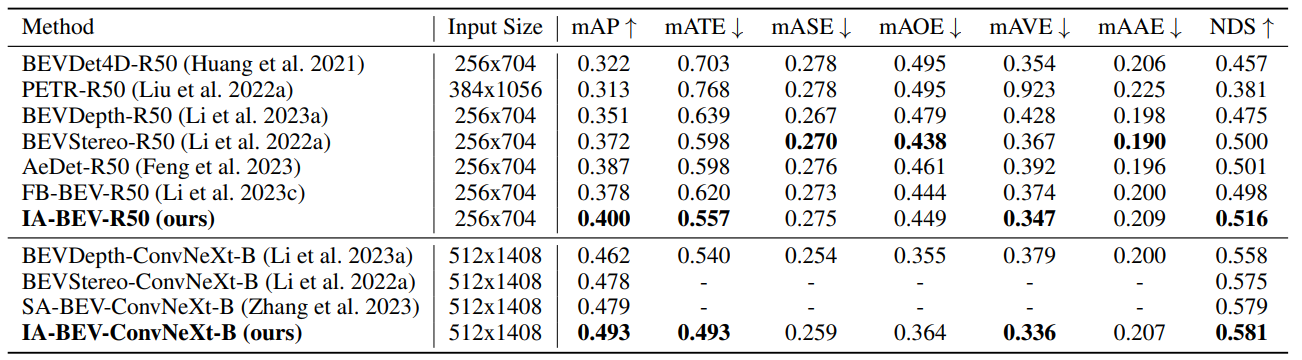
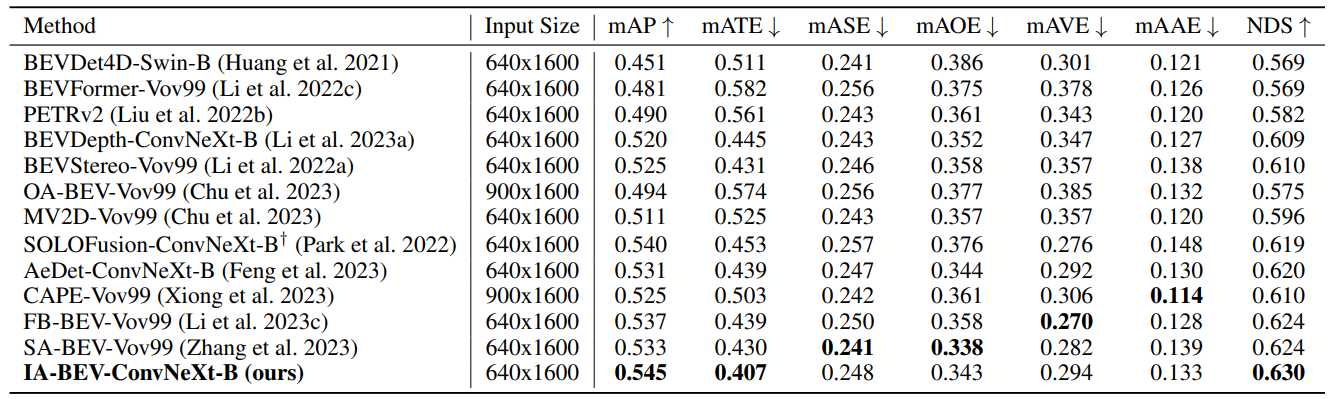
方法在nuScenes数据集上进行了大量的实验,与最先进方法的对比(验证集和测试集):
基线方法和IA-BEV之间的定性结果对比:

总结
提示:这里对文章进行总结:
d \sqrt{d} d 1 0.24 \frac {1}{0.24} 0.241 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ