Android开发中“真正”的仓库模式
- 原文地址:https://proandroiddev.com/the-real-repository-pattern-in-android-efba8662b754
- 原文发表日期:2019.9.5
- 作者:Denis Brandi
- 翻译:tommwq
- 翻译日期:2024.1.3
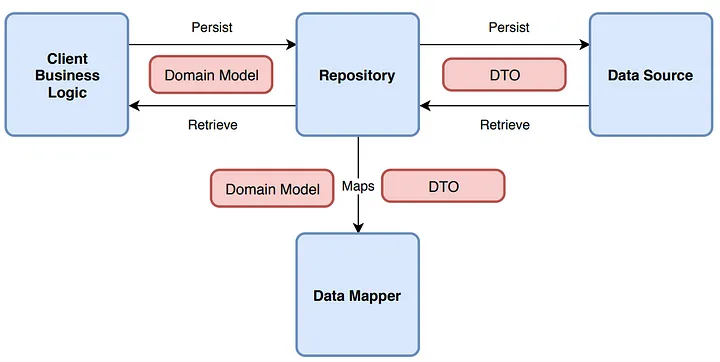
Figure 1: 仓库模式
多年来我见过很多仓库模式的实现,我想其中大部分是错误而无益的。
下面是我所见最多的5个错误(一些甚至出现在Android官方文档中):
- 仓库返回DTO而非领域模型。
- 数据源(如ApiService、Dao等)使用同一个DTO。
- 每个端点集合使用一个仓库,而非每个实体(或DDD聚合根)使用一个仓库。
- 仓库缓存所有的域,即使是频繁更新的域。
- 数据源被多个仓库共享使用。
那么要如何把仓库模式做对呢?
1. 你需要领域模型
这是仓库模式的关键,我想开发者难以正确实现仓库模式的原因在于他们不理解领域是什么。
引用Martin Fowler的话,领域模型是:
领域中同时包含行为和数据的对象模型。
领域模型基本上表示企业范围内的业务规则。
对于不熟悉领域驱动设计构建块或分层架构(六边形架构,洋葱架构,干净架构等)的人来说,有三种领域模型:
- 实体:实体是具有标识(ID)的简单对象,通常是可变的。
- 值对象:没有标识的不可变对象。
- 聚合根(仅限DDD):与其他实体绑定在一起的实体(通常是一组关联对象的聚合)。
对于简单领域,这些模型看起来与数据库和网络模型(DTO)很像,不过它们也有很多差异:
- 领域模型包含数据和过程,其结构最适于应用程序。
- DTO是表示JSON/XML格式请求/应答或数据库表的对象模型,其结构最适于远程通信。
Listing 1: 领域模型示例
// Entity
data class Product( val id: String,val name: String,val price: Price,val isFavourite: Boolean
) {// Value objectdata class Price( val nowPrice: Double,val wasPrice: Double) {companion object {val EMPTY = Price(0.0, 0.0)}}
}
Listing 2: 网络DTO示例
// Network DTO
data class NetworkProduct(@SerializedName("id")val id: String?,@SerializedName("name")val name: String?,@SerializedName("nowPrice")val nowPrice: Double?,@SerializedName("wasPrice")val wasPrice: Double?
)
Listing 3: 数据库DTO示例
// Database DTO @Entity(tableName = "Product") data class DBProduct(@PrimaryKey @ColumnInfo(name = "id") val id: String, @ColumnInfo(name = "name") val name: String,@ColumnInfo(name = "nowPrice")val nowPrice: Double,@ColumnInfo(name = "wasPrice")val wasPrice: Double )
如你所见,领域模型不依赖框架,对象字段提倡使用多值属性(正如你看到的Price逻辑分组),并使用空对象模式(域不可为空)。而DTO则与框架(Gson、Room)耦合。
幸好有这样的隔离:
- 应用程序的开发变得更容易,因为不需要检查空值,多值属性也减少了字段数量。
- 数据源变更不会影响高层策略。
- 避免了“上帝模型”,带来更多的关注点分离。
- 糟糕的后端接口不会影响高层策略(想象一下,如果你需要执行两个网络请求,因为后端无法在一个接口中提供所有信息。你会让这个问题影响你的整个代码库吗?)
2. 你需要数据转换器
这是将DTO转换成领域模型,以及进行反向转换的地方。
多数开发者认为这种转换是无趣又无效的,他们喜欢将整个代码库,从数据源到界面,与DTO耦合。
这也许能让第一个版本更快交付,但不在表示层中隐藏业务规则和用例,而是省略领域层并将界面与数据源耦合会产生一些只会在生产环境遇到的故障(比如后端没有发送空字符串,而是发送null,并因此引发NPE)。
以我所见,转换器写起来快,测起来也简单。即使实现过程缺乏趣味,它能保护我们不会因数据源行为的改变而受到意外影响。
如果你没有时间(或者干脆懒得)进行数据转换,你可以使用对象转换框架,比如ModelMapper - Simple, Intelligent, Object Mapping. 来加快进度。
我不喜欢在代码中使用框架,为减少样板代码,我建立了一个泛型转换接口,以免为每个转换器建立独立接口:
interface Mapper<I, O> {fun map(input: I): O
}
以及一组泛型列表转换器,以免实现特定的“列表到列表”转换:
// Non-nullable to Non-nullable
interface ListMapper<I, O>: Mapper<List<I>, List<O>>class ListMapperImpl<I, O>(private val mapper: Mapper<I, O>
) : ListMapper<I, O> {override fun map(input: List<I>): List<O> {return input.map { mapper.map(it) }}
}
// Nullable to Non-nullable
interface NullableInputListMapper<I, O>: Mapper<List<I>?, List<O>>class NullableInputListMapperImpl<I, O>(private val mapper: Mapper<I, O>
) : NullableInputListMapper<I, O> {override fun map(input: List<I>?): List<O> {return input?.map { mapper.map(it) }.orEmpty()}
}
// Non-nullable to Nullable
interface NullableOutputListMapper<I, O>: Mapper<List<I>, List<O>?>class NullableOutputListMapperImpl<I, O>(private val mapper: Mapper<I, O>
) : NullableOutputListMapper<I, O> {override fun map(input: List<I>): List<O>? {return if (input.isEmpty()) null else input.map { mapper.map(it) }}
}
注:在这篇文章中我展示了如何使用简单的函数式编程,以更少的样板代码实现相同的功能。
3. 你需要为每个数据源建立独立模型
假设在网络和数据库中使用同一个模型:
@Entity(tableName = "Product")
data class ProductDTO(@PrimaryKey @ColumnInfo(name = "id") @SerializedName("id")val id: String?,@ColumnInfo(name = "name")@SerializedName("name")val name: String?,@ColumnInfo(name = "nowPrice")@SerializedName("nowPrice")val nowPrice: Double?,@ColumnInfo(name = "wasPrice")@SerializedName("wasPrice")val wasPrice: Double?
)
刚开始你可能会认为这比使用两个模型开发起来要快得多,但是你注意到它的风险了吗?
如果没有,我可以为你列出一些:
- 你可能会缓存不必要的内容。
- 在响应中添加新字段将需要变更数据库(除非添加@Ignore注解)。
- 所有不应当在请求中发送的字段都需要添加@Transient注解。
- 除非使用新字段,否则必须要求网络和数据库中的同名字段使用相同的数据类型(例如你无法解析网络响应中的字符串nowPrice并缓存双精度浮点数nowPrice)。
如你所见,这种方法最终将比独立模型需要更多的维护工作。
4. 你应该只缓存所需内容
如果要显示存储在远程目录中的产品列表,并且对本地保存的愿望清单中的每个产品显示经典的心形图标。
对于这个需求,需要:
- 获取产品列表。
- 检查本地存储,确认产品是否在愿望清单中。
这个领域模型很像前面的例子,添加了一个新字段表示产品是否在愿望清单中:
// Entity
data class Product( val id: String,val name: String,val price: Price,val isFavourite: Boolean
) {// Value objectdata class Price( val nowPrice: Double,val wasPrice: Double) {companion object {val EMPTY = Price(0.0, 0.0)}}
}
网络模型也和前面的示例类似,数据库模型则不再需要。
对于本地的愿望清单,可以将产品id保存在SharedPreferences中。不要使用数据库把简单的事情复杂化。
最后是仓库代码:
class ProductRepositoryImpl(private val productApiService: ProductApiService,private val productDataMapper: Mapper<DataProduct, Product>,private val productPreferences: ProductPreferences
) : ProductRepository {override fun getProducts(): Single<Result<List<Product>>> {return productApiService.getProducts().map {when(it) {is Result.Success -> Result.Success(mapProducts(it.value))is Result.Failure -> Result.Failure<List<Product>>(it.throwable)}}}private fun mapProducts(networkProductList: List<NetworkProduct>): List<Product> {return networkProductList.map { productDataMapper.map(DataProduct(it, productPreferences.isFavourite(it.id)))}}
}
其中依赖的类定义如下:
// A wrapper for handling failing requests
sealed class Result<T> {data class Success<T>(val value: T) : Result<T>()data class Failure<T>(val throwable: Throwable) : Result<T>()
}// A DataSource for the SharedPreferences
interface ProductPreferences {fun isFavourite(id: String?): Boolean
}// A DataSource for the Remote DB
interface ProductApiService {fun getProducts(): Single<Result<List<NetworkProduct>>>fun getWishlist(productIds: List<String>): Single<Result<List<NetworkProduct>>>
}// A cluster of DTOs to be mapped into a Product
data class DataProduct(val networkProduct: NetworkProduct,val isFavourite: Boolean
)
现在,如果只想获取愿望清单中的产品要怎么做呢?实现方式是类似的:
class ProductRepositoryImpl(private val productApiService: ProductApiService,private val productDataMapper: Mapper<DataProduct, Product>,private val productPreferences: ProductPreferences
) : ProductRepository {override fun getWishlist(): Single<Result<List<Product>>> {return productApiService.getWishlist(productPreferences.getFavourites()).map {when (it) {is Result.Success -> Result.Success(mapWishlist(it.value))is Result.Failure -> Result.Failure<List<Product>>(it.throwable)}}}private fun mapWishlist(wishlist: List<NetworkProduct>): List<Product> {return wishlist.map {productDataMapper.map(DataProduct(it, true))}}
}
5. 后记
我多次熟练使用这种模式,我想它是一个时间节约神器,尤其在大型项目中。
然而我多次看到开发者使用这种模式仅仅是因为“不得不”,而非他们了解这种模式的真正优势。
希望你觉得这篇文章有趣也有用。