【总结】浅谈深度学习算法与硬件协同优化
写在前面
本文总结了笔者本科期间关于深度神经网络算法与硬件协同优化的思路和常用方法,希望能够给入门此方向的同学带来一定的启发。笔者学疏才浅,如有问题欢迎私信或评论区讨论交流!
一、背景与意义
深度神经网络(Deep Neural Network, 简称DNN)已经被成功应用在计算机视觉、自然语言处理等任务中,并在特定应用场景中取得了超越人类水平的成功。随着深度神经网络模型层数的加深、参数量的剧增,其计算复杂度也在不断增加,这不但会导致推理速度变慢,而且在运行时会带来巨大的功耗。
随着工业界对深度神经网络推理的实时性、隐私性、低成本的需求日益增大,在边缘计算设备部署高性能神经网络的需求日益增多。然而边缘计算设备如嵌入式或移动端设备受限于成本而具有算力不足、存储和功耗受限等缺点,因此DNN在此类平台上的推理仍不够高效。
解决上述问题的一个思路从算法和硬件两个方面对DNN进行协同优化。从算法层面,设计轻量化神经网络或使用神经网络压缩算法,在保证精度不严重损失的前提下从算法层面降低运算复杂度和存储需求;从硬件层面,设计轻量化神经网络特殊算子的专用加速器,避免指令调度产生的开销。深度神经网络算法与硬件协同优化背景示意图如图1所示。
基于上述思路,目前工业界有多家公司从事此方向的研究和应用,如Xilinx、百度、寒武纪、海云捷讯、大疆等,展现出广阔的应用前景和市场潜力。
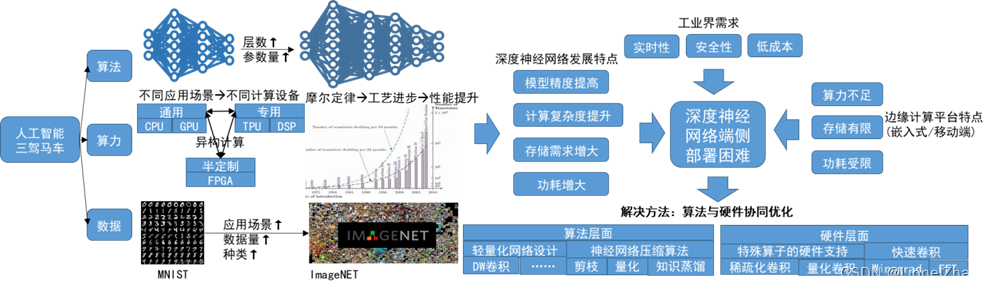 图 1深度神经网络算法与硬件协同优化背景示意图
图 1深度神经网络算法与硬件协同优化背景示意图
二、深度神经网络算法优化
目前,常用的神经网络轻量化的方法有直接设计轻量级网络和压缩现有的神经网络模型两种思路。
1、直接设计轻量化网络
直接设计轻量级网络分为人工设计轻量级网络模型和基于神经网络架构搜索(Neural Architecture Search , NAS)的自动化神经网络架构设计。
人工设计轻量级神经网络的思路是设计更加高效的卷积计算方式、构造更高效的神经网络结构,如Google的MobileNet v1[1]和MobileNet v2[2]神经网络使用深度可分离卷积替代传统卷积降低参数量。
通过NAS在给定候选神经网络架构组成的搜索空间内按照一定的搜索策略寻求最优解的方式能够创造出人工尚未设计的轻量级神经网络,如谷歌的Mobile Net v3[3]网络使用NetAdapt算法搜索得到卷积核和通道的最佳数量,并引入SE通道注意力机制和h-switch激活函数。
2、压缩现有的神经网络
现有的神经网络模型压缩的算法主要有剪枝(Pruning)、量化(Quantization)以及知识蒸馏(Knowledge Distillation ,KD)。
(1)剪枝
剪枝是指按照一定的准则判断参数重要性并裁剪模型中冗余的参数来缩小网络规模、精简网络结构,从而达到减少计算量和内存消耗的目的。剪枝通过剔除模型中冗余的参数降低了模型的复杂度,实现了模型的压缩和加速,并一定程度上缓解了过拟合的问题,其示意图如图3左图所示。
(2)量化
量化是降低网络参数的位宽来压缩模型和高效计算的神经网络轻量化方法。降低网络参数位宽可以很大程度上降级模型的存储量,并减少运算器的面积,进而降低了对访存带宽的需求和运算带来的功耗。量化压缩效果示意图如图2所示,低位宽推理能够提供更好的能效比和更高的吞吐量。
 图 2量化压缩效果示意图(左:Titan RTX和A100GPU上不同位宽参数的峰值吞吐量比较; 右:45nm工艺下不同位宽功耗和面积比较)[4]
图 2量化压缩效果示意图(左:Titan RTX和A100GPU上不同位宽参数的峰值吞吐量比较; 右:45nm工艺下不同位宽功耗和面积比较)[4]
(3)知识蒸馏
知识蒸馏是利用大型教师模型的知识来监督小型学生模型训练的方法,其基本思想是将教师模型的输出概率分布作为一种“暗知识”以供学生模型模仿,使用知识蒸馏训练的精简模型的精度往往能够接近冗余模型的精度,其示意图如图3右图所示。
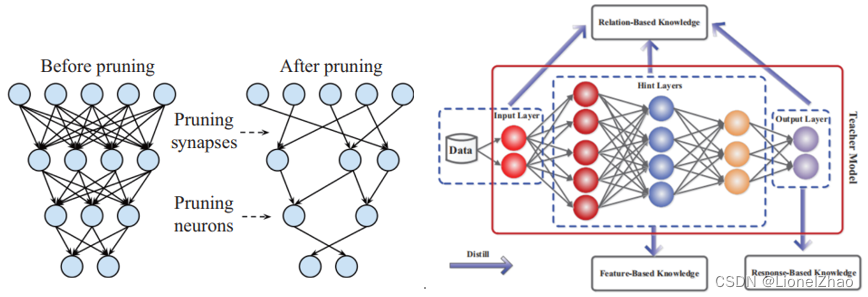 图 3神经网络压缩算法示意图(左:剪枝示意图; 右:知识蒸馏示意图)
图 3神经网络压缩算法示意图(左:剪枝示意图; 右:知识蒸馏示意图)
实验和研究表明,联合多种神经网络轻量化方法从算法层面对神经网络进行算法优化能够优势互补,更好的降低模型参数量和计算复杂度,进行更高效的神经网络推理计算。
三、深度神经网络硬件优化
目前,DNN的硬件加速方法主要有卷积加速算法优化方法和卷积加速硬件优化方法。算法优化方法主要有im2col+GEMM、FFT、Winograd等快速卷积算法;硬件优化方法只要有快速卷积、计算分块、并行流水、数据复用等方法。
1、卷积运算加速算法优化方法
目前,经典的卷积加速算法主要有im2col+GEMM、FFT、Winograd,个方法各有优缺点,适用于不同的应用场景。
(1)im2col+GEMM
im2col[8]是一种将卷积计算展开为矩阵乘法运算,再利用GEMM(General Matrix Multiplication)等现有的矩阵运算加速库来加速卷积计算的方法。其基本思想是将卷积运算循环展开,卷积展开方法示意图如下。

图 4 im2col+GEMM计算加速示意图
Im2col的优点在于可以使用现有的矩阵运算加速库来进行卷积加速,不需要额外的设计。但是将卷积循环展开会产生大量重复数据,造成内存资源的浪费,对于存储资源有限的边缘设备不友好。
(2)FFT
FFT[9]卷积计算是指将时域卷积转化为频域乘法计算,将计算复杂度由O(N2)减少到O(NlogN),大幅降低乘法计算的数量。在计算完毕后再转化回到时域卷积,FFT的经典实现结构为蝶形计算结构,其示意图如下。

图 5 FFT蝶形运算示意图
根据FFT算法,在蝶形运算将卷积进行时域、频域转化的时候会引入额外的转化操作,对于小尺度卷积而言,其转化带来的速度收益并不高,而对于大尺度卷积加速效果较好。因此FFT卷积加速适用于大尺度卷积运算的加速。
(3)Winograd
Winograd卷积算法[10]利用图像像素点之间的结构相似性,将滑窗卷积变为矩阵点乘运算,大幅降低了卷积运算中乘法计算的数量,但加法数量会有所增加。由于乘法运算速度慢于加法,因此通过引入额外的加法来降低乘法运算量可以提高卷积计算速度。Winograd卷积加速过程如下图所示。
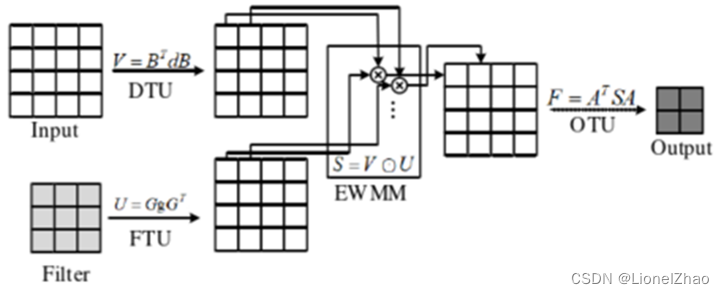 图 6 Winograd卷积运算示意图
图 6 Winograd卷积运算示意图
Winograd卷积的优点在于降低计算中乘法的数量。从图中可以看出,Winograd卷积运算需要对输入特征图和卷积核进行预处理变为Winograd域的点乘运算,然后再进行反变换回到时域。对于卷积核尺度较大的卷积运算将矩阵预处理的过程往往很长,起不到明显的加速效果,因此Winograd卷积加速算法适用于小尺度卷积。
2、卷积运算加速硬件优化方法
在硬件上实现卷积运算加速的优化方法主要有流水并行和数据复用。流水并行的基本思想时以面积换速度,以额外的运算电路同时计算多个数据,从粗粒度到细粒度排序主要有:卷积层间并行、卷积核间并行、卷积通道间并行和卷积tile间并行。数据复用的基本思想则是减少访存次数,降低由于内存访问带来的延时,从而加速卷积计算,按照数据类型可划分为:输入数据复用、输出数据复用、权重数据复用。
(1)计算分块
对于大尺寸的输入特征图,其长、宽、输入通道数往往非常大,要将整个图片缓存在片上需要消耗大量的存储资源,这对资源有限的边缘设备很不友好,可以通过计算分块的方式划分小的tile来进行卷积计算,将大尺度输入特征图拆分成小尺度输入特征图进行分别计算,再将计算结果合并为大尺度输入特征图卷积产生的输出特征图。
 图 7卷积计算伪代码(左为未分块卷积,右为分块卷积)
图 7卷积计算伪代码(左为未分块卷积,右为分块卷积)
传统卷积和计算分块后的卷积循环伪代码如图所示,通过计算分块,可降低卷积层加速器设计复杂度,减少片上存储压力,但会引入额外的存储器控制逻辑,以保证分块前后计算的正确性。
(2)流水并行
层间并行
层间并行是指神经网络前后层同时计算而非顺序计算,这需要硬件实现前后层的所有运算单元。当前层部分数据计算完毕后,可以直接输入下一层进行计算,而不用等待前层所有数据计算完毕再输入下一层进行计算。层间并行计算流水示意图如下所示。
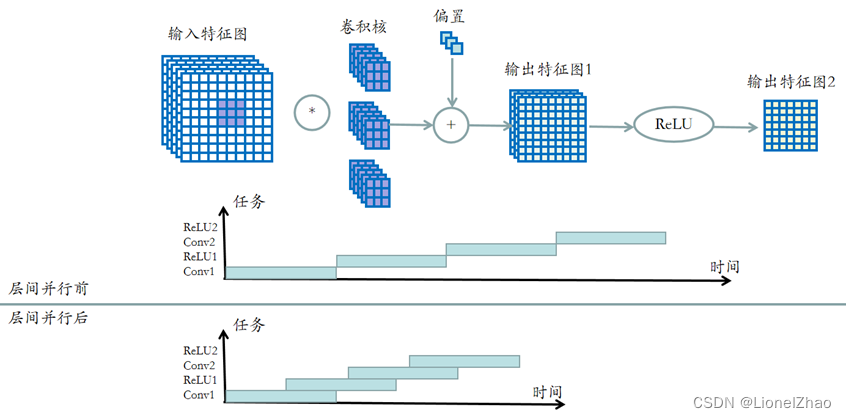 图 8层间并行示意图
图 8层间并行示意图
卷积核间并行
卷积核间并行是指将同一层卷积的不同卷积核同时计算,而非单个卷积核依次计算,其示意图如下所示。

图 9卷积核间并行示意图
卷积通道间并行
卷积通道间并行是指同一个卷积核不同通道同时计算,而非逐通道计算,其示意图如下所示。
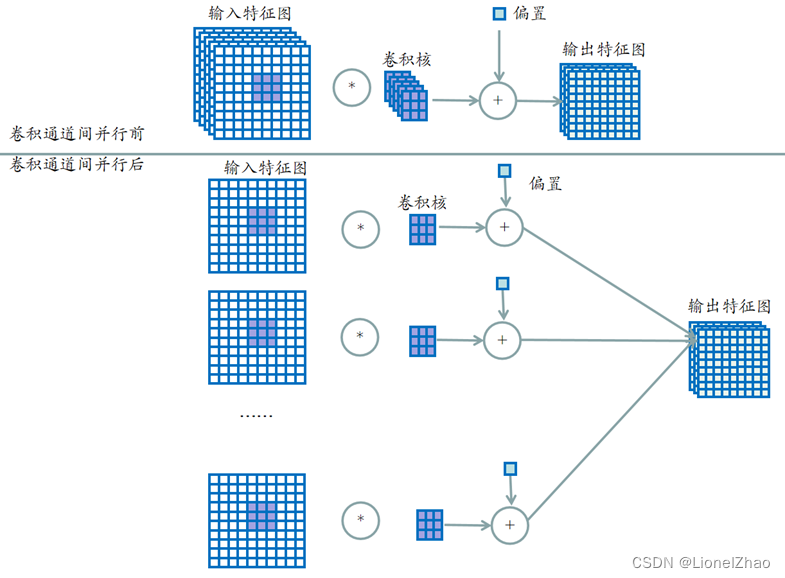 图 10 卷积通道间并行示意图
图 10 卷积通道间并行示意图
卷积tile间并行
当输入特征图过大时,由于片上资源有限,不能存放所有的数据进行同时计算,可以通过分tile的方法来避免大尺度特征图的卷积运算。卷积tile间并行是指再计算一个通道的时候不同的tile同时计算,而非顺序滑窗计算,其示意图如下。
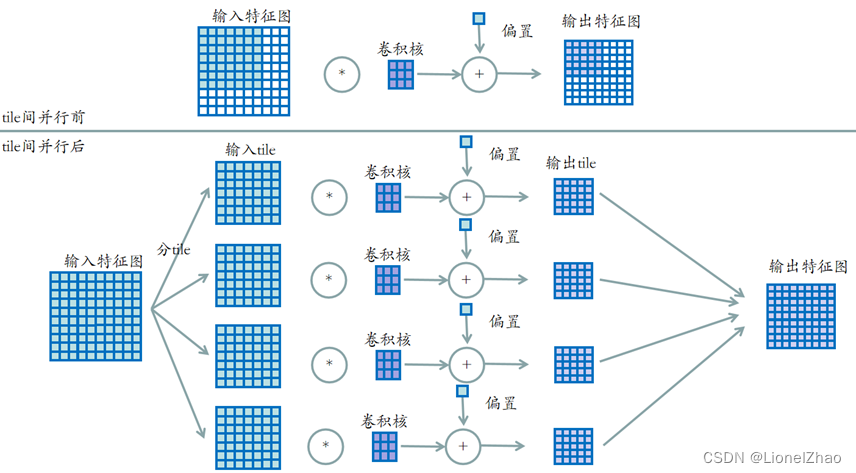 图 11 卷积tile间并行示意图
图 11 卷积tile间并行示意图
3、数据复用
(1)输入数据复用
输入数据复用(Input Reuse,IR)是指充分利用输入特征图数据,在更新遍历所有输出通道之后再加载新的输入特征图,其相对应的卷积循环如下图所示。

图 12 卷积计算伪代码(左为普通卷积,右为IR卷积)
图13是一种基本的IR模式,分为三个步骤:计算核心将输入特征图读入输入寄存器;计算核心充分利用输入数据更新输出缓存中所有相关的输出部分和;更新后的输出部分写回输出缓存。
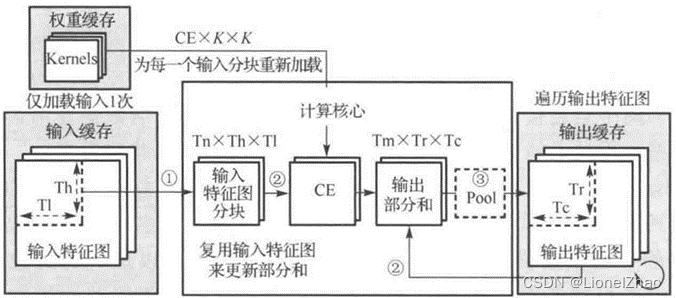 图 13 IR计算模型
图 13 IR计算模型
(2)输出数据复用
输出数据复用(Output Reuse,IR)与IR相对,是指通过更新输入数据优先计算某一输出通道的数据,在计算完毕该输出通道之后再计算下一输出通道的数据,其卷积计算伪码如下图所示。
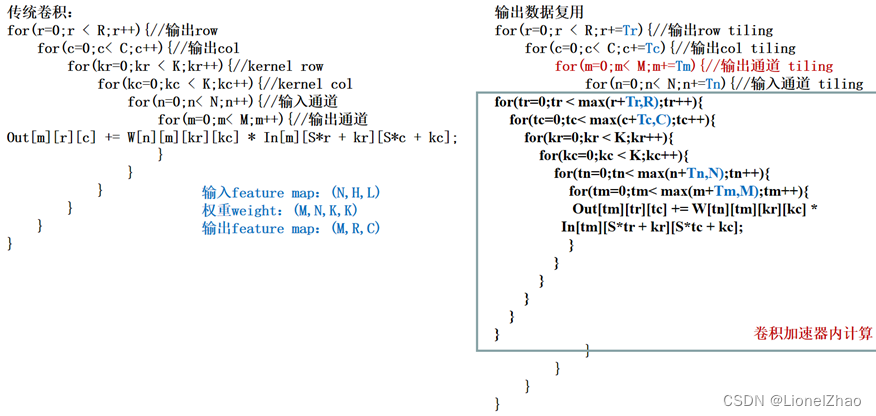
图 14卷积计算伪代码(左为普通卷积,右为OR卷积)
图15是一种基本的OR模式,分为三个步骤:计算核心将输入特征图各通道读入输入寄存器;存储在计算核心中的输出部分和被充分利用以完成该输出通道的计算;输出通道数据直接送入下一层进行池化,然后写回输出缓存。

图 15 OR计算模型
(3)权重数据复用
权重数据复用(Weight Reuse,WR)是指充分利用卷积权重数据,进行各个输入通道的计算,在计算完整个输入特征图之后再更新权重数据,其卷积循环伪码如下图所示。

图 16 卷积计算伪代码(左为普通卷积,右为WR卷积)
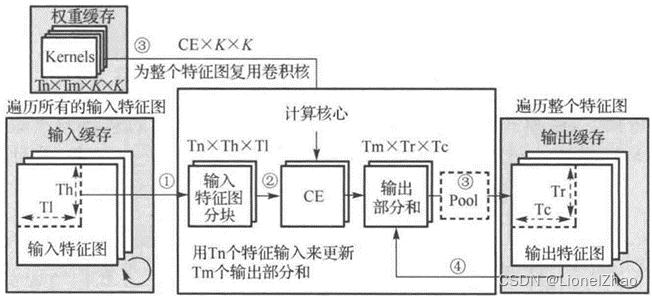
图17是一种基本的WR模式,共分为三步:计算核心读取Tn个通道的输入特征图tile到输入寄存器;计算核心利用输入数据更新Tm个通道的输出部分和;存储在权重缓存中的Tm个Tn通道的卷积核权重被充分复用以更新存储在输出缓存中Tm个通道的R*C个输出部分和。
四、参考文献
[1]Howard A G., Zhu M., Chen B., et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[2]Sandler M., Howard A., Zhu M., et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
[3]Howard A., Sandler M., Chu G., et al. Searching for mobilenetv3[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 1314-1324.
[4] M. Xu, Y. Hu, K. Ma, Y. Wang and X. Li, "A Survey of Quantization Methods for Efficient Neural Network Inference," in IEEE Access, vol. 7, pp. 128774-128786, 2019.
[5]S. Zhou, Y. Wu, Z. Ni, X. Zhou, H. Wen, and Y. Zou, "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2704-2713.
[6]K. Matin, M. R. Islam, M. N. Uddin, and S. N. Khan, "Light-DehazeNet: A Novel Lightweight CNN Architecture for Single Image Dehazing," in Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), 2020, pp. 1-4.
[7]B. Luo, Z. Zhang, K.-M. Lam, and L. Zhang, "AOD-Net: All-in-One Dehazing Network," in IEEE Transactions on Image Processing, vol. 27, no. 3, pp. 1456-1467, March 2018.
[8]A. Author et al., "High Performance Convolutional Neural Networks for Document Processing," in Proceedings of the IEEE International Conference on Computer Vision (ICCV)
[9]A. V. Oppenheim and R. W. Schafer, "Digital Signal Processing," Proceedings of the IEEE, vol. 61, no. 6, pp. 677-691, June 1973. DOI: 10.1109/PROC.1973.9030
[10]A. Lavin and S. Gray, "Fast Algorithms for Convolutional Neural Networks," Computer Vision and Pattern Recognition (CVPR), 2015, pp. 4013-4021. DOI: 10.1109/CVPR.2015.7299106