表的增删改查 进阶(二)

- 🎥 个人主页:Dikz12
- 🔥个人专栏:MySql
- 📕格言:那些在暗处执拗生长的花,终有一日会馥郁传香
- 欢迎大家👍点赞✍评论⭐收藏
目录
3.新增
4.查询
聚合查询
聚合函数
GROUP BY子句
HAVING
联合查询
内连接(重点)
外连接(重点)
左外连接
右外连接
自连接
子连接
合并查询
3.新增
- 先创建两个列数,类型相匹配的表
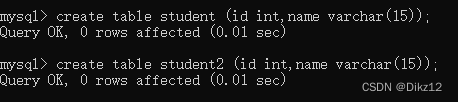
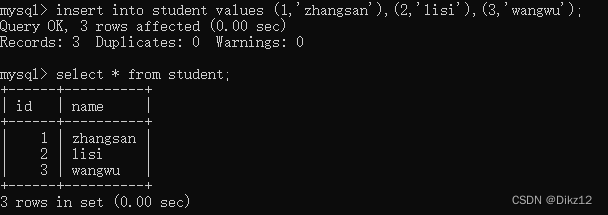
- 在第一张表(student)里添加一些数据
- 把查询语句的查询结果,作为插入的数据
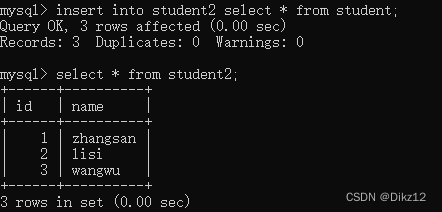
此处操作,要求查询出来的结果集合的列数和类型必须要和插入的表相匹配!
4.查询
聚合查询
表达式查询,是针对 列 和 列之间进行运算的;聚合函数,相当于是在 行 与 行 之间进行运算。
聚合函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
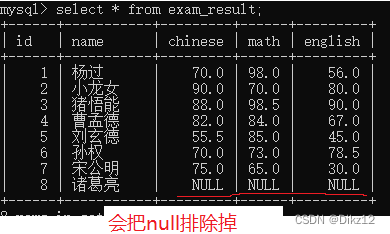
- COUNT

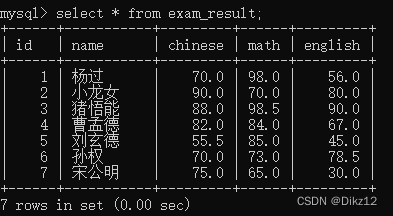
先执行select * ,在针对结果集合进行统计(看看具体有几行);、
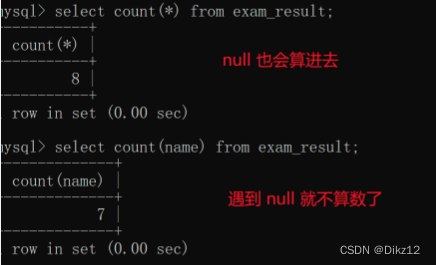
count(*)和count(列名)这两种计算方式,如果有空null,计算的count就不同了。
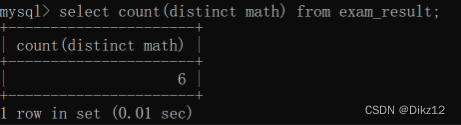
指定具体列,是可以进行去重的;
- SUM
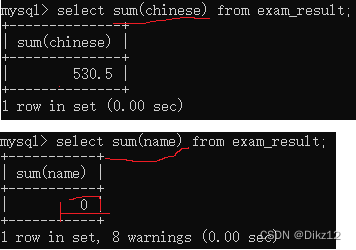
把这一列的若干行,给进行求和.(算术运算)只能针对数字类型使用;字数串可以相加,不会报错,但不是算术运算,没有意义。
sum(表达式) 查询; sum,avg,max,min基本相同;

GROUP BY子句
针对指定的列进行分组,把这一列中,相同的行,分到一组中,得到若干组,针对这些组使用聚合函数。
select 列名, sum(列名), ... from 表名 group by 列名; 
使用group by 往往还是要搭配聚合函数,否则查询的结果,基本都是没有意义的!
使用group by 时,还可以搭配条件.需要区分是你该条件是分组之前的还是分组之后的.
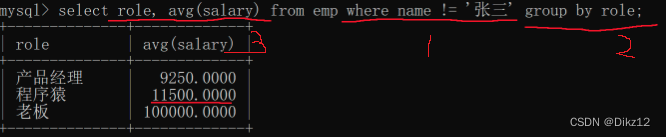
- 查询每个岗位的平均工资,排除张三
这个就是分组之前的,使用WHERE 即可. 写在group by的前面。
HAVING
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING.
- 查询每个岗位的平均工资,排除平均工资超过2w的结果

联合查询
联合查询也称为多表查询;前面的查询都是针对一个表,有些查询,则是要一次性从多个表中进行查询.联合查询的关键思路,在于理解“笛卡尔积”工作过程。会把所有情况都穷举一遍,也包含了一些非法数据无意义的数据。进行多表查询就是根据一些条件要把有意义的数据筛选出来保留,无意义的数据过滤掉。

内连接(重点)
select ... from 表1,表2 where 条件
-- inner可以缺省
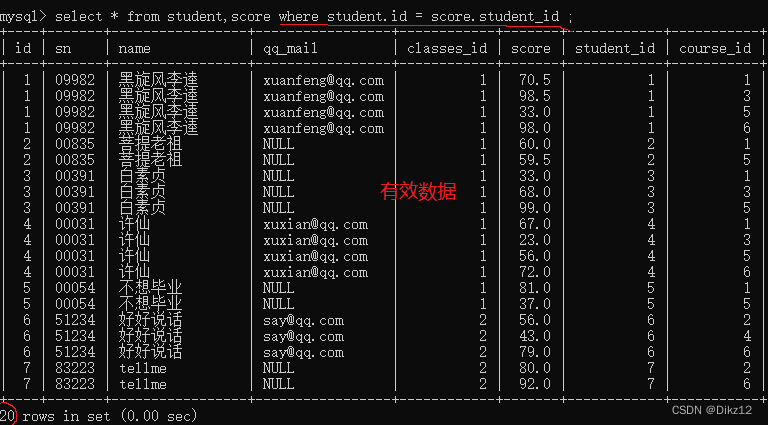
select ... from 表1 [inner] join 表2 on 条件 - 例如:查询 许仙同学的成绩
1. 先把这两个表进行笛卡尔积。


2.加上连接条件,筛选出有效数据
本体示例连接条件:
学生表的id = 分数表的seudent_id .(建议写作表名.列名)
3. 结合需求,进一步添加条件,得到自己想要的结果

注意:一旦表的数据量很大,或者表数目很多,此时得到的笛卡尔积就会非常庞大;因此,如果针对表进行笛卡尔积(多表查询),就会生成大量的临时结果,这个过程是非常消耗时间的,此时,sql就会非常复杂,可读性大大降低。
外连接(重点)
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;如果两个表,里面的记录都是存在对应关系,则内连接和外连接的结果是一致;不存在对应关系,结果就会有一些差别。

 (内连接)
(内连接)
左外连接
左外连接,就是以左侧为基准,保证左侧表的每个数据都会出现在最终结果里;如果在右侧表中不存在,对应的列就填成null。
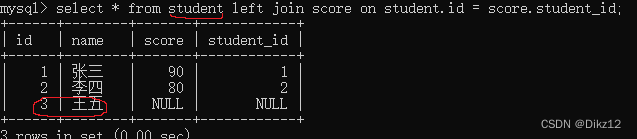
右外连接


自连接
自连接,就是一张表,自己跟自己进行笛卡尔积;sql里写个条件,都是列与列之间进行比较,但是有的时候可能会涉及到需求是进行行与行之间进行比较.就需要使用自连接,把行的关系转换成列的关系.
注意:在进行笛卡尔积时,不能直接用表名,要对表进行起别名。

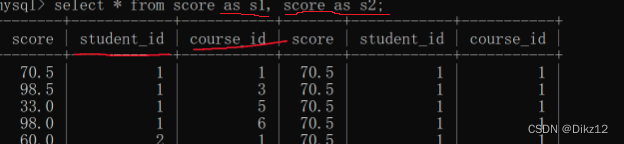
在根据自己需要的结果,找到连接条件,筛选数据
子连接
就是把多个简单的SQL拼成一个复杂的SQL;平时写代码都时把复杂的拆分成多个简单的,违背了一贯的编程原则;子连接很少使用,简单了解一下,即可。
单行子查询:
合并查询
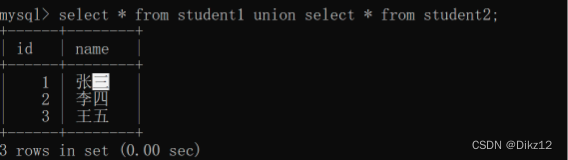
把多个sql查询结果集合,合并到一起。关键字:union.
合并两个sql结果集的列是要匹配的,列的个数和类型,是要一致的,合并的时候是会去重的,不想去重可以使用union all。