Oracle篇—分区表的管理(第二篇,总共五篇)
☘️博主介绍☘️:
✨又是一天没白过,我是奈斯,DBA一名✨
✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️
❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣️❣️❣️

在上一篇文章中,我为大家介绍了分区表和分区索引的概念、分类等方面的知识。相信大家对分区表有了初步的了解。然而对于分区表的管理,才是后续工作中最为关键的部分。分区表的增加、拆分、删除、截断、收缩、合并以及修改等操作都是日常维护中必不可少的技能。只有熟练掌握这些技能,我们才能更好地应对分区表的各种问题,确保数据库的高效运行。今天,我将深入探讨分区表的管理,带领大家进一步了解如何进行分区的增加、拆分、删除、截断、收缩、合并以及修改等操作。
因为分区技术需要介绍的太多,那么我将分成五篇来进行介绍,以便大家因为篇幅过长而感到阅读疲惫。五篇的内容分别如下:
第一篇:分区表和分区索引的介绍和分类
第二篇:分区表的管理(当前篇)
第三篇:分区索引的重建和管理
第四篇:分区表和分区索引常用的检查语句
第五篇:普通表迁移到分区表
点关注不迷路,开启缘分第一步!

目录
1、分区表的管理
1.1 增加表分区(add partition)
案例一:range/list分区添加2个新分区(分区无maxvalue/default值。不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
案例二:range/list分区添加一个新分区(分区有maxvalue/default值。不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
案例三:hash分区添加2个新分区(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
案例四:复合分区增加2个分区(range—hash / list—hash。不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
1.2 拆分表分区(split partition,支持范围、列表、间隔分区;不支持hash等。具体参考官方手册。并且一个分区一次只能拆分为2个分区,不能一条alter...split partition拆分2个以上分区会报错)
案例一:范围分区拆分at,将一个分区拆分为2个分区(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
案例二:列表分区拆分values,将一个分区拆分为2个分区(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
1.3 删除表分区(drop partition,支持范围、间隔、列表分区;不支持hash、引用分区等)
一、删除分区语法(不加update indexex全局分区索引、普通索引都将失效,本地分区索引自动维护,所以要加update indexes):
二、删除子分区语法(不加update indexex全局分区索引、普通索引都将失效,本地分区索引自动维护,所以要加update indexes):
1.4 截断表分区(truncate partition,支持范围、间隔、列表分区;不支持hash、引用分区等)
一、截断分区语法(不加update indexex仅全局分区索引失效,普通索引、本地分区索引自动维护,所以要加update indexes):
二、截断子分区语法(不加update indexex仅全局分区索引失效,普通索引、本地分区索引自动维护,所以要加update indexes):
1.5 收缩表分区(coalesce partition,只对hash分区有效,收缩分区的数据分配到其他分区不会丢失数据)
案例一:收缩hash表分区,将6个分区收缩为5个(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
案例二:收缩range/list--hash表分区(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
1.6 合并表分区(Merge Partitions,支持范围、间隔、列表分区;不支持hash、引用分区等。只能合并两个相邻的分区)
案例一:合并范围分区(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
案例二:合并复合分区list--hash(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
1.7 修改表分区(包括add/drop partition,只对list分区有效)
案例一:修改添加(modify....add)list分区一个分区的值(添加的值如在别的分区存在那么会报错,只能添加任何分区都没有的值;不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
1.8 修改表分区默认表空间属性(Modify Default Attributes)
一、修改表分区的默认表空间(现有分区的默认表空间不变更,后续增加的会变更)
二、修改表分区某一个分区的默认表空间(修改一个现有分区的默认表空间)
1.9 重命名表分区(rename partition)
一、重命名分区语法(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
二、重命名子分区语法(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
1、分区表的管理
1.1 增加表分区(add partition)
语法:
SQL> alter table table_name add
partition partition_name values less than (to_date('2014-01-01','yyyy-mm-dd')), ---添加range分区
partition prartition_name values('男') , ---添加list分区
partition partition_max values less than (maxvalue/default), --添加range、list的边界值分区
partition prartition_name tablespace tablespace_name ---添加hash分区
[update indexes]; ---针对hash分区在添加分区时,表中有全局和本地索引时新加入的分区会失效,加上uodate indexes不会导致分区失效
总结:与hash相关的表分区,如果有分区索引,不管是本地还是全局新加入的分区会失效,需要重建新的索引分区,加上update indexes不需要重建
案例一:range/list分区添加2个新分区(分区无maxvalue/default值。不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_R1';
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
SQL> select * from user_tab_partitions where table_name='TABLE_R1';
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME';
(4)增加2分区时根据上一个分区的范围来定义

SQL> alter table table_r1 add partition P2018 values less than (to_date('2018-01-01','yyyy-mm-dd')) [update indexes];
SQL> alter table table_r1 add partition P2019 values less than (to_date('2019-01-01','yyyy-mm-dd')) [update indexes];SQL> select * from user_tab_partitions where table_name='TABLE_R1';
(5)查看索引是否有效(上步增加2个分区时没有加update indexes,普通索引和本地索引都有效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME'; ---Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效
案例二:range/list分区添加一个新分区(分区有maxvalue/default值。不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_R1';
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
SQL> select * from user_tab_partitions where table_name='TABLE_R1';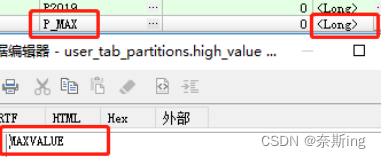
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME';
(4)增加1分区时根据上一个分区的范围来定义

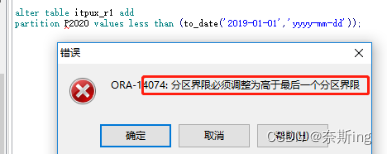
错误增加分区的写法:
SQL> alter table table_r1 add partition P2020 values less than (to_date('2019-01-01','yyyy-mm-dd')) [update indexes];
因为有范围分区中有maxvalue分区,所以在添加一个分区时表ora-14074错误,添加的分区的值一定要大于最后一个分区,所以只能拆分p_max分区或者删除后添加
正确增加分区的写法:拆分p_max分区
SQL> alter table table_r1 split partition p_max at (to_date('2020-01-01','YYYY-MM-DD')) into (partition p2020,partition p_max); ---一个分区一次只能拆分为2个分区,不能一条alter...split partition拆分2个以上分区会报错SQL> select * from user_tab_partitions where table_name='TABLE_R1';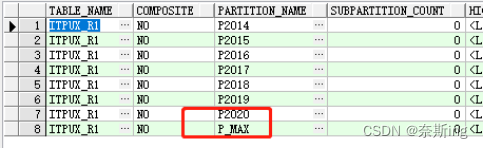
(5)查看索引是否有效(上步对分区进行拆分没有加update indexes,普通索引和本地索引都有效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME'; ---Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效
案例三:hash分区添加2个新分区(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_H1';
SQL> select * from user_tab_partitions where table_name='TABLE_H1';
(2)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_H1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_H1_NAME';
(3)增加2分区
系统自动命名分区名添加:
SQL> alter table table_h1 add partition; ---内部命名的分区名为SYS_P378
自定义分区名添加:
SQL> alter table table_h1 add partition p6 update indexes; ---注:添加hash分区时只能一个一个分区添加,不能一条alter...add添加2个分区会报错SQL> select * from user_tab_partitions where table_name='TABLE_H1';
(4)查看索引是否有效(上步系统自动命名的分区没有加update indexes,导致普通索引和创建的分区索引失效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_H1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_H1_NAME'; ---系统自动命名的分区没有加上update indexes,导致分区SYS_P378失效,也导致了p1失效。添加p6分区加上了update indexes索引分区p6可用
(5)对索引进行重建
SQL> alter index I_TABLE_H1_CARDID rebuild partition p1 online;
SQL> alter index I_TABLE_H1_CARDID rebuild partition SYS_P378 online;SQL> select * from user_ind_partitions where index_name='I_TABLE_H1_CARDID';
案例四:复合分区增加2个分区(range—hash / list—hash。不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_RH1';
SQL> select * from user_tab_partitions where table_name='TABLE_RH1';
SQL> select * from user_tab_subpartitions where table_name='TABLE_RH1';



(2)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_RH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_RH1_NAME';
SQL> select index_name,partition_name,status from dba_ind_subpartitions where index_name='TABLE_RH1_NAME';
(3)增加2分区
为复合分区增加分区之前,查看下最后一个分区建表语句,用于增加分区的参考

SQL> alter table table_rh1 add partition P2017 values less than (TO_DATE(' 2018-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')) subpartitions 2 [update indexes];
SQL> alter table table_rh1 add partition P2018 values less than (TO_DATE(' 2019-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')) subpartitions 1 [update indexes];select * from user_tab_subpartitions where table_name='TABLE_RH1';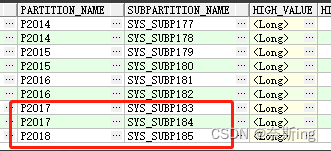
(4)查看索引是否有效(上步对分区进行添加没有加update indexes,普通索引和本地索引都有效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_RH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_RH1_NAME'; ---拥有子分区的索引需要用user_ind_subpartitions查看索引的状态
SQL> select index_name,partition_name,status from dba_ind_subpartitions where index_name='TABLE_RH1_NAME'; ---Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效
1.2 拆分表分区(split partition,支持范围、列表、间隔分区;不支持hash等。具体参考官方手册。并且一个分区一次只能拆分为2个分区,不能一条alter...split partition拆分2个以上分区会报错)
案例一:范围分区拆分at,将一个分区拆分为2个分区(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_R1';
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
select * from user_tab_partitions where table_name='TABLE_R1';
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME';
(4)将p_max拆分成2分区时根据边界分区的范围来定义


SQL> alter table table_r1 split partition p_max at (to_date('2020-01-01','YYYY-MM-DD')) into (partition p2020,partition p_max) [update indexes]; ---将表table_r1 p_max分区拆分,范围分区at为拆分的值,拆分成p2020、p_max二个分区SQL> select * from user_tab_partitions where table_name='TABLE_R1'; ---将p_max拆分为2个分区
(5)查看索引是否有效(上步对分区进行添加没有加update indexes,普通索引和本地索引都有效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME'; ---Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效
案例二:列表分区拆分values,将一个分区拆分为2个分区(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_L1';
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
SQL> select * from user_tab_partitions where table_name='TABLE_L1';
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_L1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_L1_NAME';
(4)拆分2分区时根据边界分区的值来定义


SQL> alter table table_l1 split partition p_max values ('中性') into
(partition par_03,partition p_max) [update indexes]; ---将表table_r1 p_max分区拆分,列表分区values为拆分的值,拆分成par_03、p_max二个分区SQL> select * from user_tab_partitions where table_name='TABLE_L1'; ---将p_max拆分为2个分区
(5)查看索引是否有效(上步对分区进行添加没有加update indexes,普通索引和本地索引都有效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_L1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_L1_NAME'; ---Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效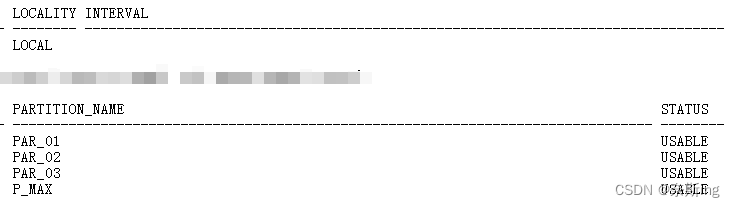
1.3 删除表分区(drop partition,支持范围、间隔、列表分区;不支持hash、引用分区等)
一、删除分区语法(不加update indexex全局分区索引、普通索引都将失效,本地分区索引自动维护,所以要加update indexes):
SQL> alter table table_name drop partition partition_name [update indexes];
二、删除子分区语法(不加update indexex全局分区索引、普通索引都将失效,本地分区索引自动维护,所以要加update indexes):
SQL> alter table table_name drop subpartition partition_name [update indexes];
1.4 截断表分区(truncate partition,支持范围、间隔、列表分区;不支持hash、引用分区等)
一、截断分区语法(不加update indexex仅全局分区索引失效,普通索引、本地分区索引自动维护,所以要加update indexes):
SQL> alter table table_name truncate partition partition_name [drop storage] [update indexes];
drop storage:truncate partiton不是物理删除,行所占用的空间不能重新分配;加上drop storage物理空间被重新分配其他对象可以使用
二、截断子分区语法(不加update indexex仅全局分区索引失效,普通索引、本地分区索引自动维护,所以要加update indexes):
SQL> alter table table_name truncate subpartition partition_name [drop storage] [update indexes];
drop storage:truncate partiton不是物理删除,行所占用的空间不能重新分配;加上drop storage物理空间被重新分配其他对象可以使用
1.5 收缩表分区(coalesce partition,只对hash分区有效,收缩分区的数据分配到其他分区不会丢失数据)
案例一:收缩hash表分区,将6个分区收缩为5个(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_H1';
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
SQL> select * from user_tab_partitions where table_name='TABLE_H1';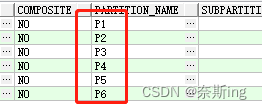
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_H1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_H1_NAME';
(4)收缩hash表分区
SQL> alter table table_h1 coalesce partition [update indexes]; ---执行一次收缩一次,以此类推SQL> select * from user_tab_partitions where table_name='TABLE_H1'; 
(5)查看索引是否有效(上步收缩p6分区没有加update indexes,导致普通索引和创建的分区索引失效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_H1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_H1_NAME'; ---收缩p6分区没有加上update indexes,导致了p2效。Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效
(5)对索引进行重建
SQL> alter index TABLE_H1_NAME rebuild partition p2 online; ---分区索引必须对每个分区重建,不能作为整体重建。如果将分区索引作为整体重建会报:ORA-14086: a partitioned index may not be rebuilt as a wholeSQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_H1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_H1_NAME';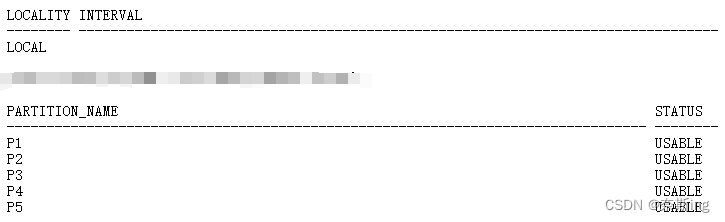
案例二:收缩range/list--hash表分区(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_RH1';
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
SQL> select * from user_tab_subpartitions where table_name='TABLE_RH1';
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_RH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_RH1_NAME';
SQL> select index_name,partition_name,status from dba_ind_subpartitions where index_name='TABLE_RH1_NAME';
(4)收缩表分区
SQL> alter table table_rh1 modify partition p2017 coalesce subpartition [update indexes]; ---对表的range---hash分区p2017进行hash收缩1次。执行一次收缩一次,以此类推SQL> select * from user_tab_partitions where table_name='TABLE_RH1';

(4)查看索引是否有效(上步收缩复合p2017分区没加update indexes,导致普通索引和创建的分区索引失效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_RH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_RH1_NAME';
SQL> select index_name,partition_name,status,SUBPARTITION_NAME from dba_ind_subpartitions where index_name='TABLE_RH1_NAME'; ---收缩p6分区没有加上update indexes,导致了p2效。Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效
(5)对索引进行重建
SQL> alter index TABLE_RH1_NAME rebuild subpartition SYS_SUBP387 online;
SQL> alter index TABLE_RH1_NAME rebuild subpartition SYS_SUBP389 online; ---分区索引必须对每个分区重建,不能作为整体重建。如果将分区索引作为整体重建会报:ORA-14086: a partitioned index may not be rebuilt as a wholeSQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_RH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_RH1_NAME';
SQL> select index_name,partition_name,status,SUBPARTITION_NAME from dba_ind_subpartitions where index_name='TABLE_RH1_NAME'; ---收缩p6分区没有加上update indexes,导致了p2效。Local索引进行add/drop/split/truncate表的分区时,会自动维护其索引分区不失效
1.6 合并表分区(Merge Partitions,支持范围、间隔、列表分区;不支持hash、引用分区等。只能合并两个相邻的分区)
案例一:合并范围分区(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_R1';![]()
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
SQL> select * from user_tab_partitions where table_name='TABLE_R1';
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME';
(3)合并2分区时根据上一个分区的范围来定义

SQL> alter table TABLE_r1 merge partitions p2016,p2017 into partition p2017 [update indexes]; ---在合并分区时,into partition的分区名要为下界分区(如:合并p2016,p2017,下界分区名为p2017),不然报:ORA-14275: 不能将下界分区作为结果分区重用SQL> select * from user_tab_partitions where table_name='TABLE_R1';
(5)查看索引是否有效(上步对分区进合并加没有加update indexes,普通索引和本地索引都有效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_R1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_R1_NAME'; ---Local索引进行add/drop/split/truncate表的分区时,被合并的分区的索引失效,除非加上update indexes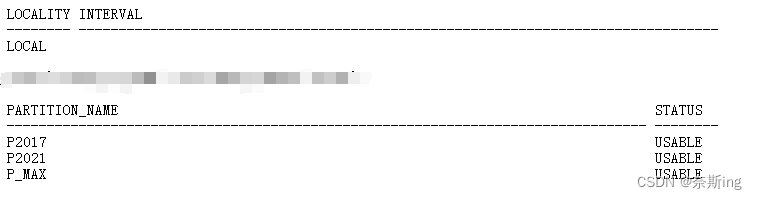
案例二:合并复合分区list--hash(不加update indexex,本地分区索引、全局分区索引、普通索引都将失效,所以要加update indexes)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_LH1';
(2)查看表的分区是否定义了最大值,也可以通过PL/SQL右键表查看
SQL> select * from user_tab_subpartitions where table_name='TABLE_LH1';
(3)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_LH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_LH1_NAME';
SQL> select index_name,partition_name,status from dba_ind_subpartitions where index_name='TABLE_LH1_NAME';
(4)合并2分区
为复合分区合并分区之前,查看分区建表语句,用于合并分区的参考

合并主分区:
SQL> alter table table_lh1 merge partitions p_M,p_W into partition p_W_M [subpartitions number] [update indexes];
subpartitions number:默认不加的话,会继承子分区的模板(如:2个分区都有2个子分区,合并主分区后,1主分区保持2个子分区) ---在合并分区时,into partition的分区名要为下界分区(如:合并p2016,p2017,下界分区名为p2017),不然报:ORA-14275: 不能将下界分区作为结果分区重用合并子分区:
SQL> alter table table_lh1 merge subpartitions SYS_SUBP95,SYS_SUBP96 into subpartition SYS_SUBP [subpartitions number] [update indexes]; ---不支持与hash相关的表分区。报:ORA-14206-表没有按列表或范围方法进行子分区SQL> select * from user_tab_subpartitions where table_name='TABLE_LH1';
(5)查看索引是否有效(上步合并复合分区没加update indexes,导致普通索引和创建的分区索引失效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_LH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_LH1_NAME';
SQL> select index_name,partition_name,SUBPARTITION_NAME,status from dba_ind_subpartitions where index_name='TABLE_LH1_NAME';
(6)对索引进行重建
SQL> alter index TABLE_LH1_NAME rebuild subpartition SYS_SUBP468 online;
SQL> alter index TABLE_LH1_NAME rebuild subpartition SYS_SUBP469 online; ---分区索引必须对每个分区重建,不能作为整体重建。如果将分区索引作为整体重建会报:ORA-14086: a partitioned index may not be rebuilt as a wholeSQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_LH1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_LH1_NAME';
SQL> select index_name,partition_name,SUBPARTITION_NAME,status from dba_ind_subpartitions where index_name='TABLE_LH1_NAME';
1.7 修改表分区(包括add/drop partition,只对list分区有效)
修改删除list分区值的语法(只对list分区):
SQL> alter table table_name modify partition partiton_name drop values (‘list分区的值’) [update indexes];
修改添加list分区值的语法(只对list分区):
SQL> alter table table_name modify partiton partition_name add values (‘添加list分区的值’) [update indexes];
案例一:修改添加(modify....add)list分区一个分区的值(添加的值如在别的分区存在那么会报错,只能添加任何分区都没有的值;不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
(1)查看表的分区类型
SQL> select * from user_part_tables where table_name='TABLE_L1';
SQL> select * from user_tab_partitions where table_name='TABLE_L1';
(2)查看索引状态
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_L1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_L1_NAME';
(3)添加par_01分区的值
添加分区内的值之前,查看分区建表语句,用于分区添加的参考

添加的值在default分区中:
SQL> alter table table_l1 modify partition par_01 add values ('山西省'); ---在对list分区的值进行add时,如果该值存在其他分区那么会报ORA-14324: 所要添加的值已存在于 DEFAULT 分区之中(不建议添加list分区中有数据的某个的值,建议新建表,将列的值加到分区中后进行迁移)
注:因为山西省在P_MAX分区(分区值为default)所以不能add,只能通过案例“拆分表分区”进行拆分添加值为新不在任何分区中:
SQL> alter table table_l1 modify partition par_01 add values ('马来西亚'); SQL> select * from user_tab_partitions where table_name='TABLE_L1'; ---par_01分区的“马来西亚”值添加 
(4)查看索引是否有效(上步对分区进行add没有加update indexes,普通索引和本地索引都有效)
SQL> select INDEX_NAME,LOCALITY,INTERVAL from dba_part_indexes where table_name='TABLE_L1';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_L1_NAME'; ---Local索引进行add/drop/split/truncate表的分区时,被修改的分区的索引有效
1.8 修改表分区默认表空间属性(Modify Default Attributes)
一、修改表分区的默认表空间(现有分区的默认表空间不变更,后续增加的会变更)
SQL> alter table table_name modify default attributes tablespace tablespace_name;
二、修改表分区某一个分区的默认表空间(修改一个现有分区的默认表空间)
修改复合分区的默认表空间(只对复合分区有效,亲测范围、hash、列表分区报ORA-14253: 表未按组合分区方法分区):
SQL> alter table table_name modify default attributes for partition partition_name tablespace tablespace_name [update indexes];
修改表分区某一个分区的默认表空间:
SQL> alter table table_name move partition partiton_name tablespace tablespace_name [update indexes];
SQL> alter table table_name move subpartition subpartition_name tablespace tablespace_name[update indexes];
1.9 重命名表分区(rename partition)
一、重命名分区语法(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
SQL> alter table table_name rename partition partition_name to partition_newname [update indexes];
二、重命名子分区语法(不加update indexex,本地分区索引、全局分区索引、普通索引都有效)
SQL> alter table table_name rename subpartition subpartition_name to subpartition_newname [update indexes];