不到1s生成mesh! 高效文生3D框架AToM


论文题目: AToM: Amortized Text-to-Mesh using 2D Diffusion
论文链接: https://arxiv.org/abs/2402.00867 项目主页: AToM: Amortized Text-to-Mesh using 2D Diffusion
随着AIGC的爆火,生成式人工智能在3D领域也实现了非常显著的效果,但是现有的文生3D模型仍然存在很多局限,例如主流的文生3D方法需要逐文本优化(per-prompt optimization),生成过程非常耗时。此外,这些方法的可扩展性仍有待提高,对于训练分布之外的未见文本(unseen prompt),模型无法生成。
本文介绍一篇来自Snapchat、KAUST和多伦多大学合作完成的工作AToM(Amortized Text-to-Mesh using 2D Diffusion)。AToM是一种可以跨多个文本提示进行优化的三维生成框架,其可以在不到1秒的时间内直接生成高质量的纹理网格,训练成本相比逐文本优化方法至少降低 10 倍,并且具有更好的泛化性能,对未见的文本提升,可以轻松地应对。AToM的关键idea是构建了一种基于triplane的文本到3D模型生成框架,并且设计了一种两阶段Amortized优化策略,这样可以保证模型训练过程的稳定性,同时提高可扩展性。AToM可以灵活的掌握2D扩散模型中的先验,根据用户输入的文本提示在短时间内完成相应3D模型的生成。

本文作者在多个标准评估基准上进行了大量的实验,实验结果表明AToM的精度显著优于目前的SOTA方法ATT3D[1],同时与per-prompt方法相比,AToM展示出了强大的通用能力,下图展示了AToM生成各种三维模型的效果。

01. 引言
生成式人工智能的迅速发展,使得3D模型的构建过程越来越方便直接,设计师们无需进行复杂的手工绘制,而是只输入几个单词就可以创建一个逼真的模型。当前主流的文本到3D模型方法可以在无需三维监督信号的情况下进行训练。但是这种方法需要根据用户输入的每个提示进行优化,这导致了模型无法推广到真实场景中的unseen提示。近期,发表在ICCV2023上的ATT3D方法[1]提出了一种Amortized文本到3D模型生成技术,大幅度地缩减模型的训练时间,但是其仍局限于NeRF格式的输入。直观上分析,将NeRF转换为3D模型是不够精确的。另外更重要的是,由于HyperNets训练不稳定性,基于HyperNets的ATT3D在大规模数据集中表现欠佳,对于不同的提示词,容易生成无法分辨的3D模型。

因此本文引入了一种全新的AToM,直接将Amortized技术应用到文本到三维纹理网络mesh生成中。然而,盲目的将ATT3D方法扩展为Text-to-Mesh形式,也会面临在几何拓扑方面出现偏差的问题,如下图第二列所示。

为此,AToM引入了基于triplane的mesh生成框架以及二阶段Amortized优化策略,以稳定Text-to-Mesh的训练稳定性,增强生成的可扩展性。与ATT3D相比,AToM可以产生质量更好效果更逼真的3D内容,在大数据集上表现更佳。 上图分别展示了本文方法与ATT3D的生成效果对比。
02. 本文方法
2.1 AToM Pipeline
下图展示了本文方法在训练和推理过程中的pipeline,与针对特征提示的主流3D模型生成方法不同,AToM的网络架构由一个文本编码器、一个text-to-triplane网络和一个triplane-to-mesh生成器构成。
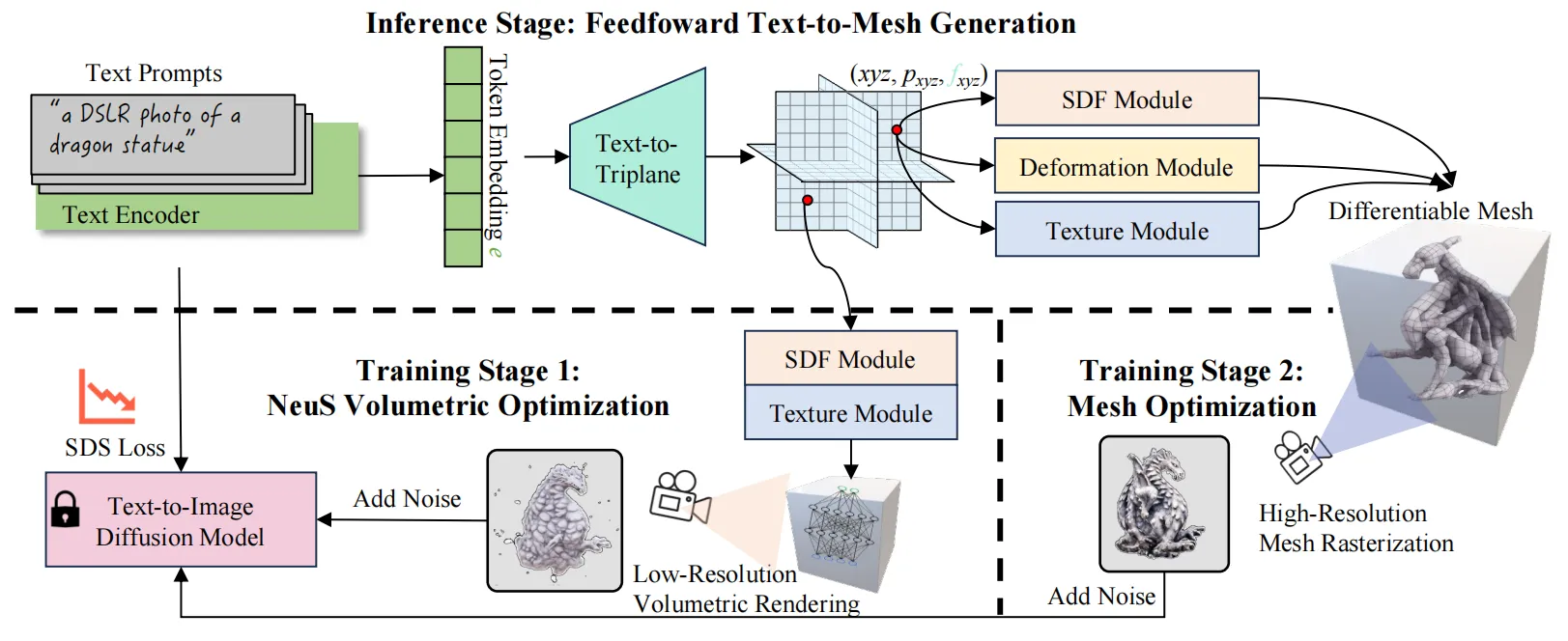

2.2 两阶段的Amortized优化
2.2.1 体积优化

2.2.2 网格优化
AToM的第二阶段优化是使用网格光栅化通过高分辨率渲染来优化整个网络。此时作者使用了可微的网格表示,同时使用网格光栅化可以节省内存并提高计算速度,这允许整体框架使用更高分辨率(例如尺寸为例如 512×512)的渲染进行训练。训练损失使用与第一阶段相同的SDS损失,由于SDF和颜色网络已在第一阶段得到了优化,因此第二阶段的主要目标是通过网格表示中的高分辨率渲染来提高几何和纹理的质量。需要指出的是,在这两个优化阶段中,AToMs没有接收任何 3D 数据的监督信号,仅在文本到图像扩散模型的指导下完成训练。
03. 实验效果
本文的实验在多个标准评估基准上进行,包括Pig64、Animal2400, DF27和DF415。评价指标使用与ATT3D方法相同的CLIP-R概率,其可以衡量输入文本与生成3D模型的均匀渲染视图的平均距离。下表展示了本文方法与其他baseline方法的对比结果。
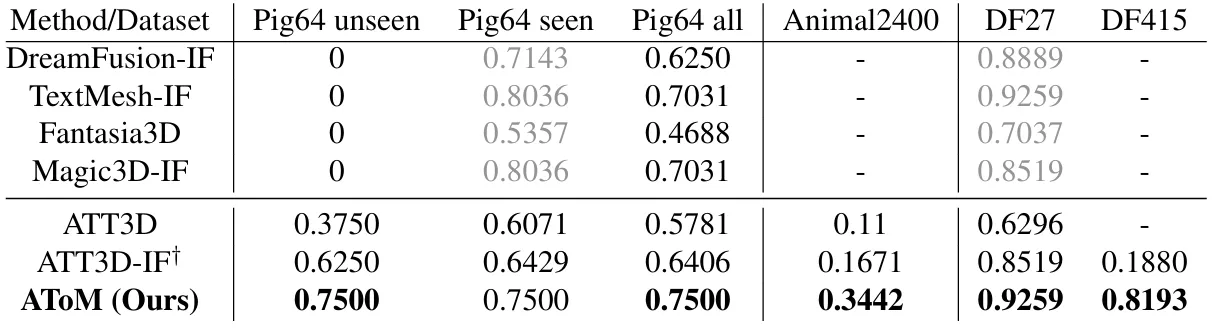
从表中可以观察到,AToM 在 Pig64 的unseen提示上获得了比 ATT3D(64.29%)更高的 CLIP R 概率 75.00%,这表明AToM拥有更强的泛化能力。此外,在Pig64 和 DF27 的训练提示中,AToM 在两个数据集上都超越了其他方法。
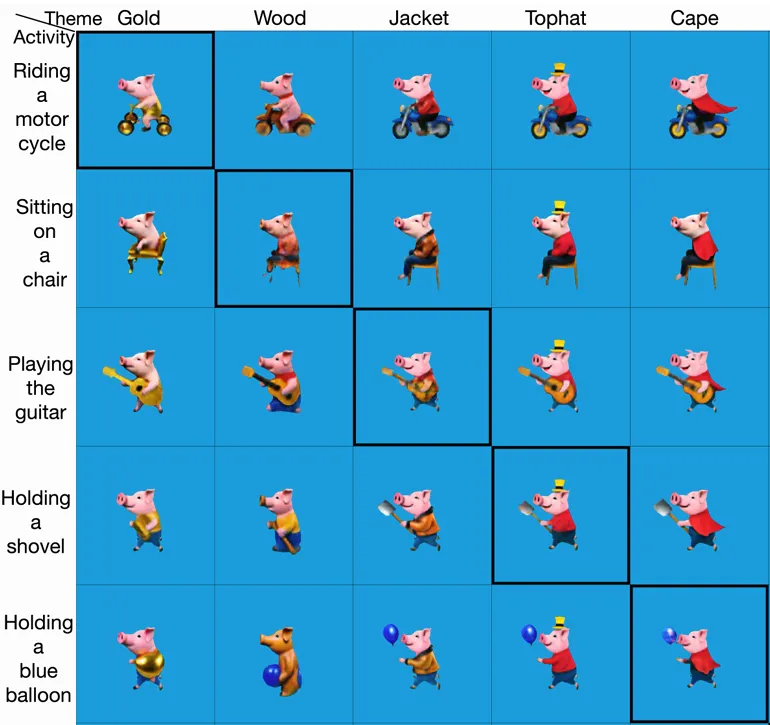
AToM框架的一个优点是,其可以轻松推广到模型训练分布之外的插值提示中,而普通的per-prompt方法不具备这种通用性。上图展示了AToM方法在Pig64中的unseen生成效果,AToM 无需进一步优化就可以对unseen提示生成高质量的结果,如上图对角线所示。 在Animal2400 12.5%数据集中,AToM仅在300个文本上训练,便可扩展至2400个文本的生成,下图展现了部分文本的生成效果:

此外,作者在下图中对AToM中的关键模块和操作进行了消融研究,从图中可以观察到,当仅使用单阶段进行训练时,模型的收敛稳定性会受到明显影响,生成的准确率较低,只有7.47%,明显低于 AToM full(81.93%)。这表明,本文所提的两阶段优化策略非常重要,经过第二阶段训练产生的网格具有更高的视觉质量。

04. 总结
本文提出了一种新颖的Amortized文本到3D模型生成框架AToM,AToM可以在没有3D 监督的情况下跨多个文本提示进行网络优化。AToM的训练过程基于三平面的网格生成器,这有助于更稳定的优化和提高对大规模数据集的通用性。此外,作者针对文本到3D网格生成过程,设计了一种两阶段Amortized优化策略,与普通的per-prompt方法相比,AToM 显着减少了训练时间,更重要的是,AToM 表现出很强的通用性,无需进一步优化即可为下游环境中的unseen提示生成高质量的 3D 内容。
参考
[1] Jonathan Lorraine, Kevin Xie, Xiaohui Zeng, Chen-Hsuan Lin, Towaki Takikawa, Nicholas Sharp, Tsung-Yi Lin, Ming Yu Liu, Sanja Fidler, and James Lucas. Att3d: Amortized text-to-3d object synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17946–17956, October 2023.
[2] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020.
[3] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
[4] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. International Conference on Learning Representations (ICLR), 2022.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区