linux---内存管理
一 虚拟内存
即使是现代操作系统中,内存依然是计算机中很宝贵的资源,看看你电脑几个T固态硬盘,再看看内存大小就知道了。
为了充分利用和管理系统内存资源,Linux采用虚拟内存管理技术,利用虚拟内存技术让每个进程都有4GB 互不干涉的虚拟地址空间。
进程初始化分配和操作的都是基于这个「虚拟地址」,只有当进程需要实际访问内存资源的时候才会建立虚拟地址和物理地址的映射,调入物理内存页。
1.1 虚拟地址的好处
- 避免用户直接访问物理内存地址,防止一些破坏性操作,保护操作系统
- 每个进程都被分配了4GB的虚拟内存,用户程序可使用比实际物理内存更大的地址空间
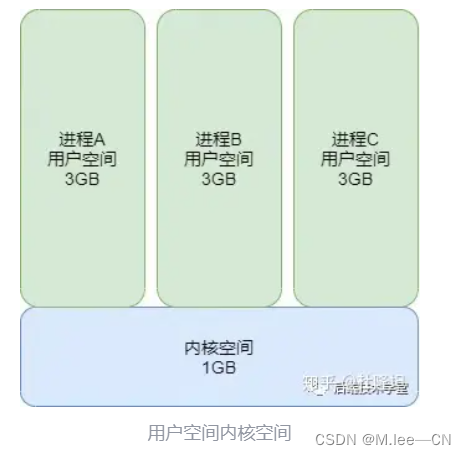
4GB 的进程虚拟地址空间被分成两部分:「用户空间」和「内核空间」

二 物理内存
2.1物理内存区域
内存节点下面再划分为不同的区域。划分区域的原因是什么呢?主要是因为各种软硬件的限制导致的。目前Linux中最多可以有6个区域,这些区域并不是每个都必然存在,有的是由config控制的。有些区域就算代码中配置了,但是在系统运行的时候也可能为空。下面我们依次介绍一下这6个区域。
ZONE_DMA:由配置项CONFIG_ZONE_DMA决定是否存在。在x86上DMA内存区域是物理内存的前16M,这是因为早期的ISA总线上的DMA控制器只有24根地址总线,只能访问16M物理内存。为了兼容这些老的设备,所以需要专门开辟前16M物理内存作为一个区域供这些设备进行DMA操作时去分配物理内存。
ZONE_DMA32:由配置项CONFIG_ZONE_DMA32决定是否存在。后来的DMA控制器有32根地址总线,可以访问4G物理内存了。但是在32位的系统上最多只支持4G物理内存,所以没必要专门划分一个区域。但是到了64位系统时候,很多CPU能支持48位到52位的物理内存,于是此时就有必要专门开个区域给32位的DMA控制器使用了。
ZONE_NORMAL:常规内存,无配置项控制,必然存在,除了其它几个内存区域之外的内存都是常规内存ZONE_NORMAL。
ZONE_HIGHMEM:高端内存,由配置项CONFIG_HIGHMEM决定是否存在。只在32位系统上有,这是因为32位系统的内核空间只有1G,这1G虚拟空间中还有128M用于其它用途,所以只有896M虚拟内存空间用于直接映射物理内存,而32位系统支持的物理内存有4G,大于896M的物理内存是无法直接映射到内核空间的,所以把它们划为高端内存进行特殊处理。对于64位系统,从理论上来说,内核空间最大263-1,物理内存最大264,好像内核空间还是不够用。但是从现实来说,内核空间的一般配置为247,高达128T,物理内存暂时还远远没有这么多。所以从现实的角度来说,64位系统是不需要高端内存区域的。
ZONE_MOVABLE:可移动内存,无配置项控制,必然存在,用于可热插拔的内存。内核启动参数movablecore用于指定此区域的大小。内核参数kernelcore也可用于指定非可移动内存的大小,剩余的内存都是可移动内存。如果两者同时指定的话,则会优先保证非可移动内存的大小至少有kernelcore这么大。如果两者都没指定,则可移动内存大小为0。
ZONE_DEVICE:设备内存,由配置项CONFIG_ZONE_DEVICE决定是否存在,用于放置持久内存(也就是掉电后内容不会消失的内存)。一般的计算机中没有这种内存,默认的内存分配也不会从这里分配内存。持久内存可用于内核崩溃时保存相关的调试信息。

2.2 物理内存页面
每个内存区域下面再划分为若干个面积比较小但是又不太小的页面。页面的大小一般都是4K,这是由硬件规定的。内存节点和内存区域从逻辑上来说并不是非得有,只不过是由于各种硬件限制或者特殊需求才有的。内存页面倒不是因为硬件限制才有的,主要是出于逻辑原因才有的。页面是分页内存机制和底层内存分配的最小单元。如果没有页面的话,直接以字节为单位进行管理显然太麻烦了,所以需要有一个较小的基本单位,这个单位就叫做页面。页面的大小选多少合适呢?太大了不好,太小了也不好,这个数值还得是2的整数次幂,所以4K就非常合适。为啥是2的整数次幂呢?因为计算机是用二进制实现的,2的整数次幂做各种运算和特殊处理比较方便,后面用到的时候就能体会到。为啥是4K呢?因为最早Intel选择的就是4K,后面大部分CPU也都跟着选4K作为页面的大小了。
物理内存页面也叫做页帧。物理内存从开始起每4K、4K的,构成一个个页帧,这些页帧的编号依次是0、1、2、3......。页帧的编号也叫做pfn(page frame number)。很显然,一个页帧的物理地址和它的pfn有一个简单的数学关系,那就是其物理地址除以4K就是其pfn,其pfn乘以4K就是其物理地址。由于4K是2的整数次幂,所以这个乘除运算可以转化为移位运算。下面我们看一下相关的宏操作。
2.3 三级区划关系
我们对物理内存的三级区划有了简单的了解,下面我们再对它们之间的关系进行更进一步地分析。虽然在节点描述符中包含了所有的区域类型,但是除了第一个节点能包含所有的区域类型之外,其它的节点并不能包含所有的区域类型,因为有些区域类型(DMA、DMA32)必须从物理内存的起点开始。Normal、HighMem和Movable是可以出现在所有的节点上的。页面编号(pfn)是从物理内存的起点开始编号,不是每个节点或者区域重新编号的。所有区域的范围都必须是整数倍个页面,不能出现半个页面。节点描述符不仅记录自己所包含的区域,还会记录自己的起始页帧号和跨越页帧数量,区域描述符也会记录自己的起始页帧号和跨越页帧数量。
下面我们来画个图看一下节点与页面之间的关系以及x86上具体的区分划分情况。


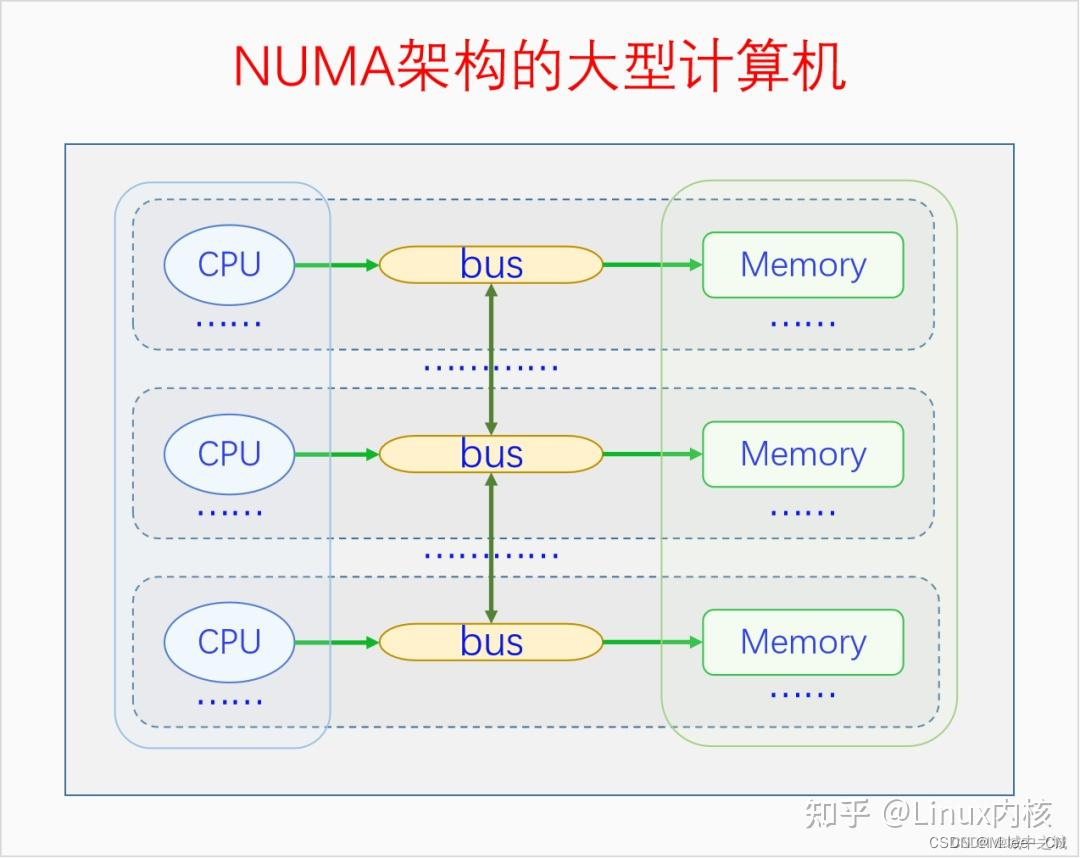 当一个系统中的CPU越来越多、内存越来越多的时候,内存总线就会成为一个系统的瓶颈。如果大家都还挤在同一个总线上,速度必然很慢。于是我们可以采取一种方法,把一部分CPU和一部分内存直连在一起,构成一个节点,不同节点之间CPU访问内存采用间接方式。节点内的内存访问速度就会很快,节点之间的内存访问速度虽然很慢,但是我们可以尽量减少节点之间的内存访问,这样系统总的内存访问速度就会很快。
当一个系统中的CPU越来越多、内存越来越多的时候,内存总线就会成为一个系统的瓶颈。如果大家都还挤在同一个总线上,速度必然很慢。于是我们可以采取一种方法,把一部分CPU和一部分内存直连在一起,构成一个节点,不同节点之间CPU访问内存采用间接方式。节点内的内存访问速度就会很快,节点之间的内存访问速度虽然很慢,但是我们可以尽量减少节点之间的内存访问,这样系统总的内存访问速度就会很快。
三、物理内存分配
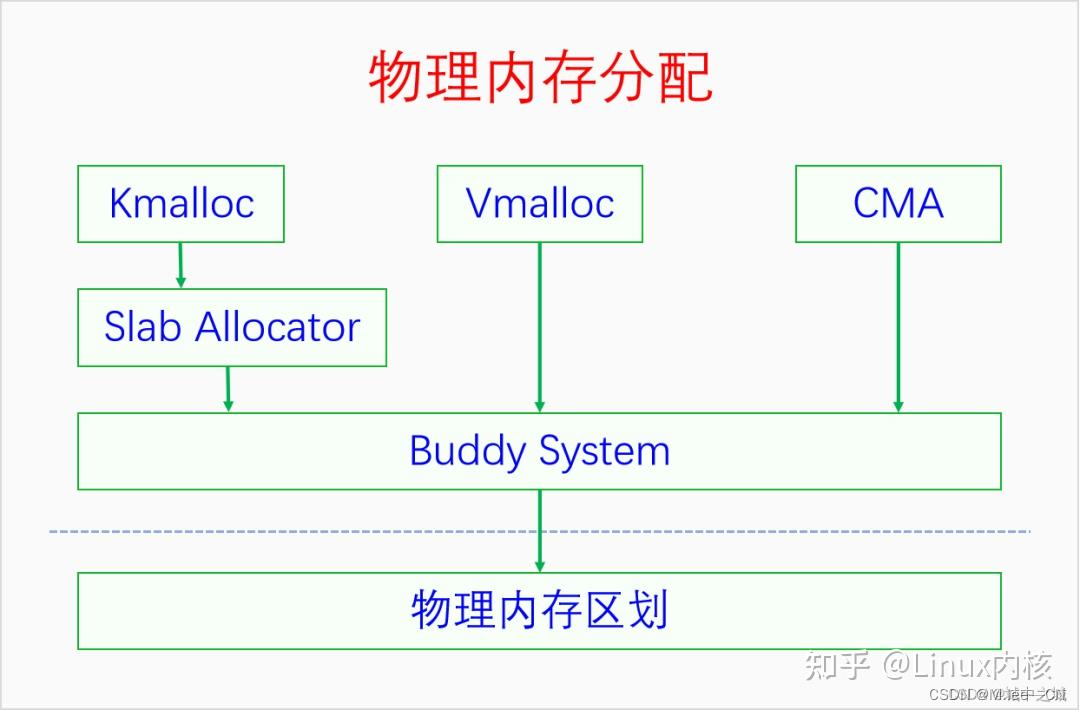
当我们把物理内存区划弄明白之后,再来学习物理内存分配就比较容易了。物理内存分配最底层的是页帧分配。页帧分配的分配单元是区域,分配粒度是页面。如何进行页帧分配呢?Linux采取的算法叫做伙伴系统(buddy system)。只有伙伴系统还不行,因为伙伴系统进行的是大粒度的分配,我们还需要批发与零售,于是便有了slab allocator和kmalloc。这几种内存分配方法分配的都是线性映射的内存,当系统连续内存不足的时候,Linux还提供了vmalloc用来分配非线性映射的内存。下面我们画图来看一下它们之间的关系。
3.1 Buddy System
伙伴系统的基本管理单位是区域,最小分配粒度是页面。因为伙伴系统是建立在物理内存的三级区划上的,所以最小分配粒度是页面,不能比页面再小了。基本管理单位是区域,是因为每个区域的内存都有特殊的用途或者用法,不能随便混用,所以不能用节点作为基本管理单位。伙伴系统并不是直接管理一个个页帧的,而是把页帧组成页块(pageblock)来管理,页块是由连续的2^n^个页帧组成,n叫做这个页块的阶,n的范围是0到10。而且2^n^个页帧还有对齐的要求,首页帧的页帧号(pfn)必须能除尽2^n^,比如3阶页块的首页帧(pfn)必须除以8(2^3^)能除尽,10阶页块的首页帧必须除以1024(2^10^)能除尽。0阶页块只包含一个页帧,任意一个页帧都可以构成一个0阶页块,而且符合对齐要求,因为任何整数除以1(2^0^)都能除尽。
具体的,所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。

3.2 Slab Allocator
伙伴系统的最小分配粒度是页面,但是内核中有很多大量的同一类型结构体的分配请求,比如说进程的结构体task_struct,如果使用伙伴系统来分配显然不合适,如果自己分配一个页面,然后可以分割成多个task_struct,显然也很麻烦,于是内核中给我们提供了slab分配机制来满足这种需求。Slab的基本思想很简单,就是自己先从伙伴系统中分配一些页面,然后把这些页面切割成一个个同样大小的基本块,用户就可以从slab中申请分配一个同样大小的内存块了。如果slab中的内存不够用了,它会再向伙伴系统进行申请。不同的slab其基本块的大小并不相同,内核的每个模块都要为自己的特定需求分配特定的slab,然后再从这个slab中分配内存。
3.2.1 Slab接口
下面我们来看一下slab的接口:linux-src/include/linux/slab.h
struct kmem_cache *kmem_cache_create(const char *name, unsigned int size,unsigned int align, slab_flags_t flags,void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *);
void *kmem_cache_alloc(struct kmem_cache *, gfp_t flags);
void kmem_cache_free(struct kmem_cache *, void *);
我们在使用slab时首先要创建slab,创建slab用的是接口kmem_cache_create,其中最重要的参数是size,它是基本块的大小,一般我们都会传递sizeof某个结构体。创建完slab之后,我们用kmem_cache_alloc从slab中分配内存,第一个参数指定哪个是从哪个slab中分配,第二个参数gfp指定如果slab的内存不足了如何从伙伴系统中去分配内存,gfp的函数和前面伙伴系统中讲的相同,此处就不再赘述了,函数返回的是一个指针,其指向的内存大小就是slab在创建时指定的基本块的大小。当我们用完一块内存时,就要用kmem_cache_free把它还给slab,第一个参数指定是哪个slab,第二个参数是我们要返回的内存。如果我们想要释放整个slab的话,就使用接口kmem_cache_destroy。
3.3 Kmalloc
内存中还有一些偶发的零碎的内存分配需求,一个模块如果仅仅为了分配一次5字节的内存,就去创建一个slab,那显然不划算。为此内核创建了一个统一的零碎内存分配器kmalloc,用户可以直接请求kmalloc分配若干个字节的内存。Kmalloc底层用的还是slab机制,kmalloc在启动的时候会预先创建一些不同大小的slab,用户请求分配任意大小的内存,kmalloc都会去大小刚刚满足的slab中去分配内存。
kmalloc() 分配的虚拟地址范围在内核空间的「直接内存映射区」。
按字节为单位虚拟内存,一般用于分配小块内存,释放内存对应于 kfree ,可以分配连续的物理内存。
3.4 Vmalloc
vmalloc 分配的虚拟地址区间,位于 vmalloc_start 与vmalloc_end 之间的「动态内存映射区」。
一般用分配大块内存,释放内存对应于 vfree,分配的虚拟内存地址连续,物理地址上不一定连续。函数原型在 <linux/vmalloc.h> 中声明。一般用在为活动的交换区分配数据结构,为某些 I/O 驱动程序分配缓冲区,或为内核模块分配空间。
下面的图总结了上述两种内核空间虚拟内存分配方式。

3.5 CMA
CMA 全称是 Contiguous Memory Allocator(连续内存分配器)。
CMA通过reserve一块大块连续内存,当设备驱动不用时,内存管理系统将该区域用于分配和管理可移动类型页面;当设备驱动使用时,此时已经分配的页面需要进行迁移,又用于连续内存分配;详细内存可参阅如下博客Linux内存管理:CMA(连续内存分配)(DMA)_cma dma-CSDN博客
四、物理内存回收
内存作为系统最宝贵的资源,总是不够用的。当内存不足的时候就要对内存进行回收了。内存回收按照回收时机可以分为同步回收和异步回收,同步回收是指在分配内存的时候发现无法分配到内存就进行回收,异步回收是指有专门的线程定期进行检测,如果发现内存不足就进行回收。内存回收的类型有两种,一是内存规整,也就是内存碎片整理,它不会增加可用内存的总量,但是会增加连续可用内存的量,二是页帧回收,它会把物理页帧的内容写入到外存中去,然后解除其与虚拟内存的映射,这样可用物理内存的量就增加了。内存回收的时机和类型是正交关系,同步回收中会使用内存规整和页帧回收,异步回收中也会使用内存规整和页帧回收。在异步回收中,内存规整有单独的线程kcompactd,此类线程一个node一个,线程名是[kcompactd/nodeid],页帧回收也有单独的线程kswapd,此类线程也是一个node一个,线程名是[kswapd/nodeid]。在同步回收中,还有一个大杀器,那就是OOM Killer,OOM是内存耗尽的意思,当内存耗尽,其它所有的内存回收方法也回收不到内存的时候,就会使用这个大杀器。下面我们画个图来看一下:

4.1 内存规整
系统运行的时间长了,内存一会儿分配一会儿释放,慢慢地可用内存就会变得很碎片化不连续。虽然总的可用内存还不少,但是却无法分配大块连续内存,此时就需要进行内存规整了。内存规整是以区域为基本单位,找到可用移动的页帧,把它们都移到同一端,然后连续可用内存的量就增大了。其逻辑如下图所示:

4.2 页帧回收
内存规整只是增加了连续内存的量,但是可用内存的量并没有增加,当可用内存量不足的时候就要进行页帧回收。对于内核来说,其虚拟内存和物理内存的映射关系是不能解除的,所以必须同时回收物理内存和虚拟内存。对此采取的办法是让内核的每个模块都注册shrinker,当内存紧张时通过shrinker的回调函数通知每个模块尽量释放自己暂时用不到的内存。对于用户空间,其虚拟内存和物理内存的映射关系是可以解除的,我们可以先把其物理内存上的内容保存到外存上去,然后再解除映射关系,这样其物理内存就被回收了,就可以拿做它用了。如果程序后来又用到了这段内存,程序访问其虚拟内存的时候就会发生缺页异常,在缺页异常里再给它分配物理内存,并把其内容从外存中加载建立,这样程序还是能正常运行的。
4.3 交换区
我们一般所说的swap,指的是一个交换分区或文件。在Linux上可以使用swapon -s命令查看当前系统上正在使用的交换空间有哪些,以及相关信息:
-
[zorro@zorrozou-pc0 linux-4.4]$ swapon -s -
Filename Type Size Used Priority -
/dev/dm-4 partition 33554428 0 -1
从功能上讲,交换分区主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致oom或者更致命的情况出现。
所以,当内存使用存在压力,开始触发内存回收的行为时,就可能会使用swap空间。
linux swap 内存交换分区 详细介绍-CSDN博客
4.4 OOM Killer
如果用尽了上述所说的各种办法还是无法回收到足够的物理内存,那就只能使出杀手锏了,OOM Killer,通过杀死进程来回收内存。
五 Linux用户态进程的内存管理
5.1 进程的虚拟地址空间VMA(Virtual Memory Area)
在linux操作系统中,每个进程都通过一个task_struct的结构体描叙,每个进程的地址空间都通过一个mm_struct描叙,c语言中的每个段空间都通过vm_area_struct表示,他们关系如下 :

上图中,task_struct中的mm_struct就代表进程的整个内存资源,mm_struct中的pgd为页表,mmap指针指向的vm_area_struct链表的每一个节点就代表进程的一个虚拟地址空间,即一个VMA。一个VMA最终可能对应ELF可执行程序的数据段、代码段、堆、栈、或者动态链接库的某个部分。
5.2 malloc分配的原理
malloc的过程其实就是把VMA分配到各种段当中,这时候是没有真正分配物理地址的。malloc 调用后,只是分配了内存的逻辑地址,在内核的mm_struct 链表中插入vm_area_struct结构体,没有分配实际的内存。当分配的区域写入数据是,引发页中断,建立物理页和逻辑地址的映射。
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
- malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系)
- malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0)
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。

5.3 内存的消耗VSS RSS PSS USS
- VSS -Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)
- RSS -Resident Set Size 实际使用物理内存(包含共享库占用的内存)
- PSS -Proportional Set Size 实际使用的物理内存(比例分配共享库占用的内存)
- USS -Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)

六、总结
linux内存管理极其复杂。本文内容只是将主要部分进行了大概的介绍,且本文大多引用的其它博客的内容,如五万字 | 深入理解Linux内存管理 - 知乎 (zhihu.com),linux内存管理(详解) - 知乎 (zhihu.com)
Linux用户态进程的内存管理 - 知乎 (zhihu.com)
浅析进程分配内存的两种方式——brk()和mmap() - 知乎 (zhihu.com)