pytorch 实现线性回归(深度学习)
一 查看原始函数
初始化
%matplotlib inline
import random
import torch
from d2l import torch as d2l1.1 生成原始数据
def synthetic_data(w, b, num_examples):x = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(x, w) + bprint('x:', x)print('y:', y)y += torch.normal(0, 0.01, y.shape) # 噪声return x, y.reshape((-1 , 1))true_w = torch.tensor([2.])
true_b = 4.2
print(f'true_w: {true_w}, true_b: {true_b}')features, labels = synthetic_data(true_w, true_b, 10)
1.2 数据转换
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))random.shuffle(indices)for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]batch_size = 10
for x, y in data_iter(batch_size, features, labels):print(f'x: {x}, \ny: {y}')
1.3 初始化权重
随机初始化,w使用 均值0,方差 0.01 的随机值, b 初始化为1。
w = torch.normal(0, 0.01, size = (1,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
w, b![]()
二 执行训练
查看训练过程中的 参数变化:
print(f'true_w: {true_w}, true_b: {true_b}')def squared_loss(y_hat, y):return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2def linreg(x, w, b):return torch.matmul(x, w) + bdef sgd(params, lr, batch_size):with torch.no_grad():for param in params:# print('param:', param, 'param.grad:', param.grad)param -= lr * param.grad / batch_sizeparam.grad.zero_()lr = 0.03
num_epochs = 1000
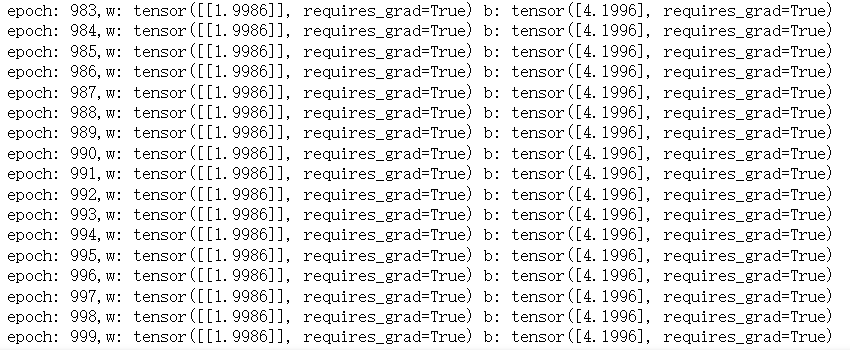
for epoch in range(num_epochs):for x, y in data_iter(batch_size, features, labels):l = squared_loss(linreg(x, w, b), y) # 计算总损失print('w:', w, 'b:', b) # l:', l, '\nl.sum().backward()sgd([w, b], lr, batch_size)
三 测试梯度更新
初始化数据
%matplotlib inline
import random
import torch
from d2l import torch as d2ldef synthetic_data(w, b, num_examples):x = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(x, w) + bprint('x:', x)print('y:', y)y += torch.normal(0, 0.01, y.shape) # 噪声return x, y.reshape((-1 , 1))true_w = torch.tensor([2.])
true_b = 4.2
print(f'true_w: {true_w}, true_b: {true_b}')features, labels = synthetic_data(true_w, true_b, 10)def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))random.shuffle(indices)for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]batch_size = 10
for x, y in data_iter(batch_size, features, labels):print(f'x: {x}, \ny: {y}')w = torch.normal(0, 0.01, size = (1,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
w, b3.1 测试更新
print(f'true_w: {true_w}, true_b: {true_b}')def squared_loss(y_hat, y):return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2def linreg(x, w, b):return torch.matmul(x, w) + bdef sgd(params, lr, batch_size):with torch.no_grad():for param in params:print('param:', param, 'param.grad:', param.grad)
# param -= lr * param.grad / batch_size
# param.grad.zero_()lr = 0.03
num_epochs = 2
for epoch in range(num_epochs):for x, y in data_iter(batch_size, features, labels):l = squared_loss(linreg(x, w, b), y) # 计算总损失print(f'\nepoch: {epoch},w:', w, 'b:', b) # l:', l, '\nl.sum().backward() # 计算更新梯度sgd([w, b], lr, batch_size)使用 l.sum().backward() # 计算更新梯度:

不使用更新时:
print(f'true_w: {true_w}, true_b: {true_b}')def squared_loss(y_hat, y):return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2def linreg(x, w, b):return torch.matmul(x, w) + bdef sgd(params, lr, batch_size):with torch.no_grad():for param in params:print('param:', param, 'param.grad:', param.grad)
# param -= lr * param.grad / batch_size
# param.grad.zero_()lr = 0.03
num_epochs = 2
for epoch in range(num_epochs):for x, y in data_iter(batch_size, features, labels):l = squared_loss(linreg(x, w, b), y) # 计算总损失print(f'\nepoch: {epoch},w:', w, 'b:', b) # l:', l, '\n# l.sum().backward() # 计算更新梯度sgd([w, b], lr, batch_size)# break