CTR之行为序列建模用户兴趣:DIN
在前面的文章中,已经介绍了很多关于推荐系统中CTR预估的相关技术,今天这篇文章也是延续这个主题。但不同的,重点是关于用户行为序列建模,阿里出品。
概要
论文:Deep Interest Network for Click-Through Rate Prediction
链接:https://arxiv.org/pdf/1706.06978.pdf
这篇论文是阿里2017年发表在KDD上,提出了一种新的CTR建模方法:Deep Interest Network (DIN),它最大的创新点是引入了局部激活单元(local activation unit,其实是一种Attention机制),对于不同的候选item,可以根据用户的历史行为序列,动态地学习用户的兴趣表征向量。
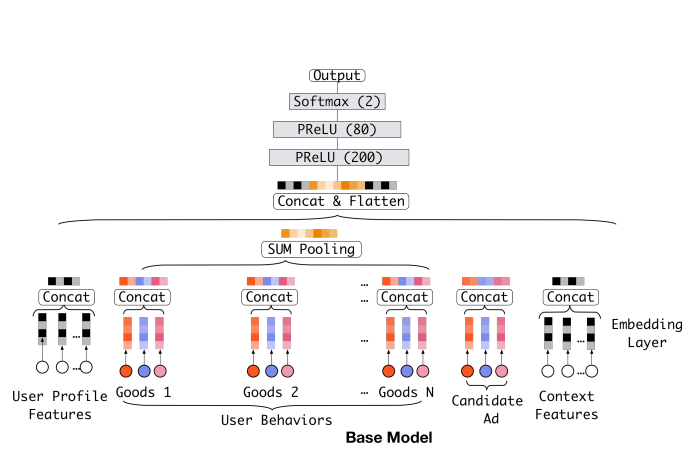
- 在此之前,在DNN中,对于用户历史行为序列的处理方法一般都是pooling(sum pooling或者mean pooling等),即等同对待历史序列中的所有行为,无关于当前的候选item,如下图所示:
- **但用户当前的兴趣或者说当前对某个特定的item是否感兴趣,实际上应该只与某些行为是相关的。**如下图所示,用户对Candidate的大衣是否感兴趣,其实主要跟用户看过的衣服类型比较有关联,而跟其它如包包和鞋子则基本不相关。

- 联想到FMs中,因为存在候选item和历史行为item的交叉特征,也是有类似的思想存在,但实际推荐系统工程中,很难实现所有item的交叉计算
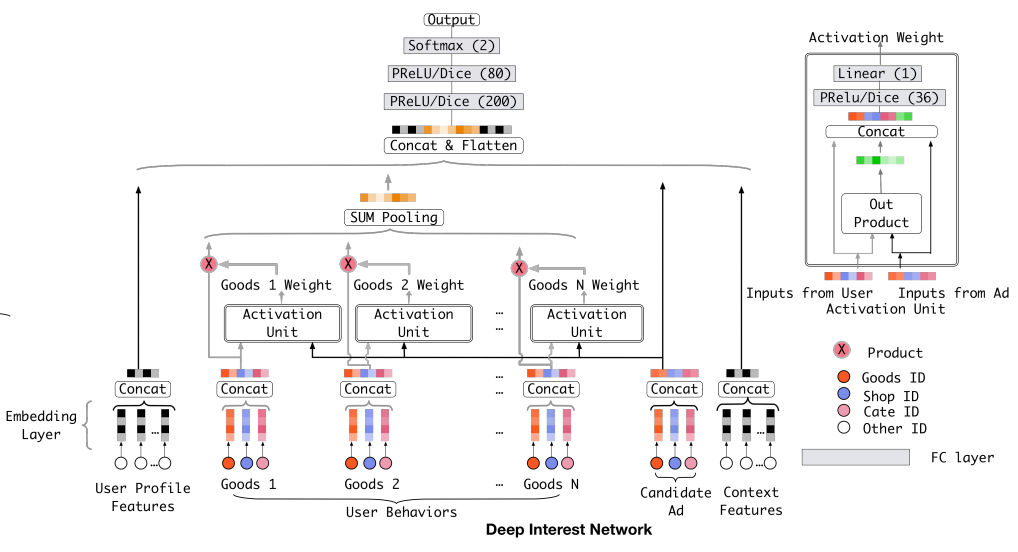
DIN的整体网络结构其实与Base Model是差不多的,唯一的区别就是在User Behaviors建模上,如下图:
Base Model
Feature Reresentation.
首先,离散特征会进行one-hot或者multi-hot编码:
x = [ t 1 T , t 2 T , . . . , t M T ] T , t i ∈ R K i x=[t^T_1,t^T_2,...,t^T_M]^T,\ t_i \in R^{K_i} x=[t1T,t2T,...,tMT]T, ti∈RKi
- K i K_i Ki 是第i个field的unique feature数量, t i [ j ] ∈ { 0 , 1 } t_i[j] \in \{0,1\} ti[j]∈{0,1}是一个0-1向量;
- ∑ j = 1 K i t i [ j ] = k \sum_{j=1}^{K_i}t_i[j]=k ∑j=1Kiti[j]=k,当k=1时, t i t_i ti是one-hot编码,k>1则是multi-hot编码。
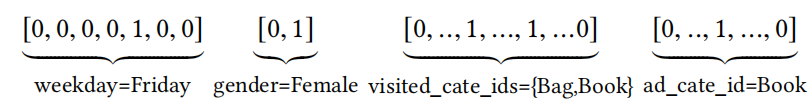
Embedding layer.
对于第i个field的特征 t i t_i ti,有着对应的embedding字典: W i = [ w 1 i , w 2 i , . . . , w K i i ] ∈ R D × K i W^i=[w^i_1,w^i_2,...,w^i_{K_i}] \in \mathbb{R}^{D \times K_i} Wi=[w1i,w2i,...,wKii]∈RD×Ki。而 w j i ∈ R D w^i_j \in R^D wji∈RD则是维度为D的embedding向量。
Embedding操作其实是一种表检索机制,具体如下:
- 如果 t i t_i ti是one-hot向量,并且第j个元素 t i [ j ] = 1 t_i[j]=1 ti[j]=1,那么 t i t_i ti的embedding表征则为 e i = w j i e_i=w^i_j ei=wji
- 如果 t i t_i ti是multi-hot向量,并且 t i [ j ] = 1 , j ∈ { i 1 , i 2 , . . . , i k } t_i[j]=1,\ j\in\{i_1,i_2,...,i_k\} ti[j]=1, j∈{i1,i2,...,ik},那么 t i t_i ti的embedding表征则是一个embedding向量列表: { e i 1 , e i 2 , . . . , e i k } = { w i 1 i , w i 2 i , . . . , w i k i } \{e_{i_1},e_{i_2},...,e_{i_k}\}=\{w^i_{i_1},w^i_{i_2},...,w^i_{i_k}\} {ei1,ei2,...,eik}={wi1i,wi2i,...,wiki}
Pooling layer and Concat layer.
像这种multi-hot向量特征,其实就非常符合用户的行为序列特点:序列即代表存在多个行为(如点击了多个商品),并且每一个不同的用户的行为序列长度也不同。一般的处理方法则是通过pooling layer,将embedding向量列表转换为固定长度的向量(因为MLP只能处理固定长度的输入):
e i = p o o l i n g ( e i 1 , e i 2 , . . . , e i k ) e_i=pooling(e_{i_1},e_{i_2},...,e_{i_k}) ei=pooling(ei1,ei2,...,eik)
而最常用的pooling layer则是sum pooling和average pooling,即将列表中的所有向量进行element-wise的相加或者均值操作。
接着,再将所有处理过的表征向量进行拼接,得到的最终的表征向量输入。
MLP&Loss.
MLP仍然是常规的全连接网络层,为了自动学习特征组合,如PNN、Wide&Deep和DeepFM。
Base Model的目标函数使用negative log-likehood:
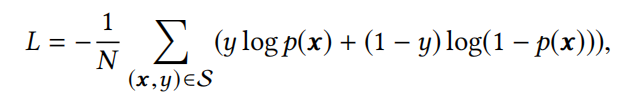
p ( x ) p(x) p(x)是最终网络softmax layer之后的输出,代表样本x是否被点击的概率。
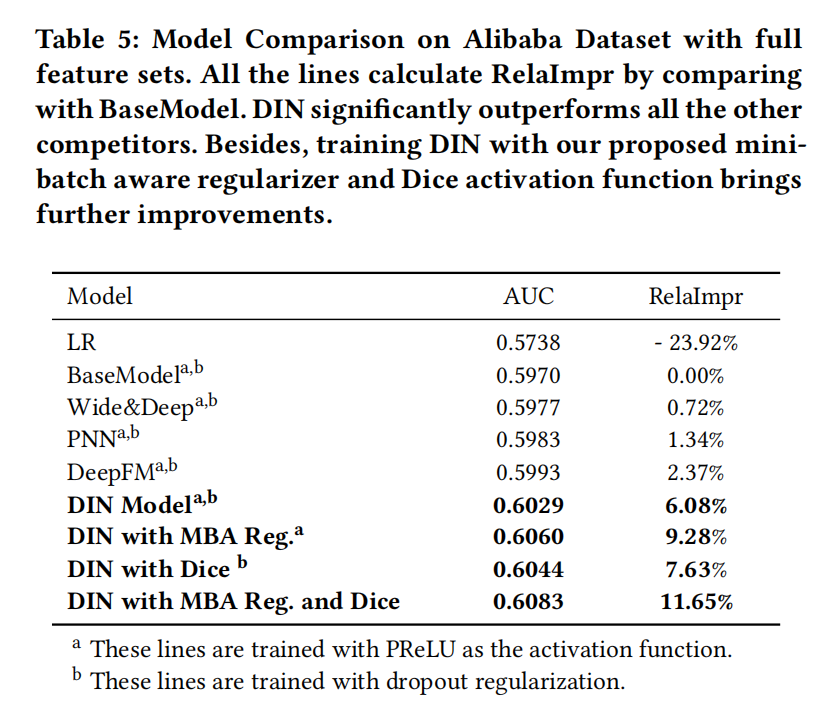
Deep Interest Network
一开始提到了,用户行为序列pooling的缺点在于同等地对待序列中所有行为的item,并且对于任何候选item,同一个用户的行为序列计算的兴趣表征向量是同样不变的。另外,论文还指出固定的有限制的维度的表征向量,成为了表征用户多样的兴趣的瓶颈,但向量的维度扩展又严重增加了学习参数的规模和存储负担,这在实时推荐系统中是难以接受的,并且在有限的训练样本下也容易导致过拟合。
在这种动机下,提出了能够考虑历史行为序列和候选集的相关性来自适应计算用户的兴趣表征向量的模型DIN。通过解刨用户的点击行为动机,发现与展示的item相关的历史行为极大地贡献了点击。
给定一个候选item,DIN将attention给到局部活跃的历史行为的表征,来实现这种兴趣表征自适应计算。具体做法是引入了一种局部激活单元,应用在用户的行为序列特征上,数学上则是一种加权sum pooling来得到在候选item A A A 下用户的兴趣表征 v U v_U vU,如下式:
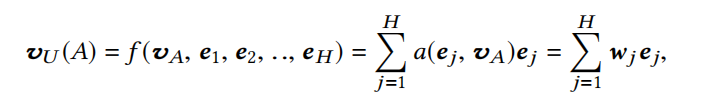
{ e 1 , e 2 , . . . , e H } \{e_1,e_2,...,e_H\} {e1,e2,...,eH} 是用户历史行为的embedding向量列表,长度为H, v A v_A vA则为候选item的embedding向量。
- a ( ⋅ ) a(\cdot) a(⋅) 是一种前馈网络,其输出便作为激活权重。
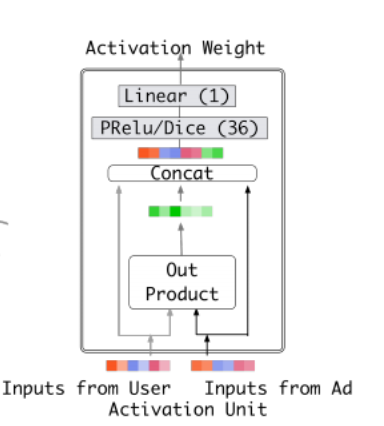
- 如下图,两个embedding向量的激活权重计算是原向量拼接它们的out product作为输入,喂给后续的网络,输出一个标量权重。这是一种显式的知识,能够帮助相关性建模。
- 从公式明显看出,对于不同的候选item, v U v_U vU的计算结果是不同的。
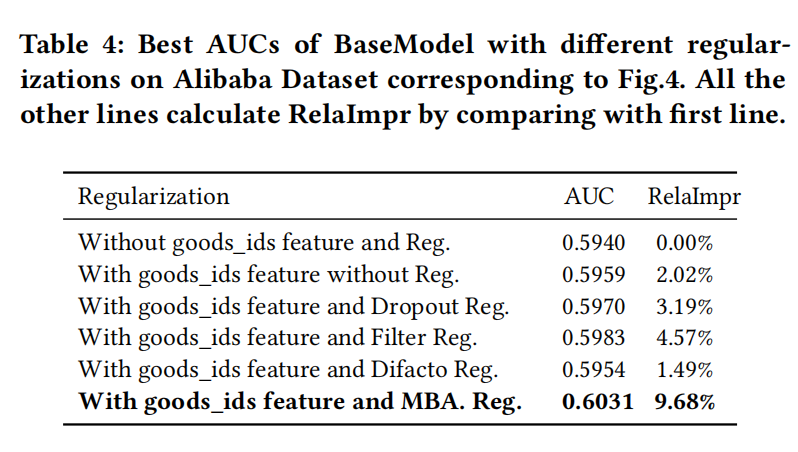
Mini-batch Aware Regularization
过拟合是深度网络训练中一个关键的挑战,比如加入一些细粒度的特征,比如商品ID,模型的效果会在第一个epoch之后迅速地下降。
通常的做法是加入L1或者L2正则惩罚。在没有加入正则惩罚的情况下,每一个batch中,只有那些出现过即不为0的离散特征的参数需要更新,但L2正则惩罚却会计算整个参数的L2-norm,这会造成极其沉重的计算。
因此,论文提出Mini-batch Aware Regularization,只计算在每个batch出现过的离散特征的参数的L2-norm,并且ID类即离散特征的embedding矩阵贡献了CTR网络的绝大部分参数,只在ID类特征参数上应用。
记 W ∈ R D × K W \in \mathbb{R}^{D\times K} W∈RD×K 为embedding矩阵,embedding向量维度为D,离散特征的空间维度,即离散特征的unique id数量。在 W W W 上扩展 l 2 l_2 l2 正则如下式:
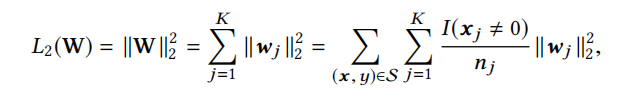
w j ∈ R D w_j \in \mathbb{R}^D wj∈RD 是第j个embedding向量, I ( x j ≠ 0 ) I(x_j \neq 0) I(xj=0) 表示实例x的feature id是 j j j, n j n_j nj 则表示feature id j j j 在所有样本出现的次数。
上式可以简化为下式:
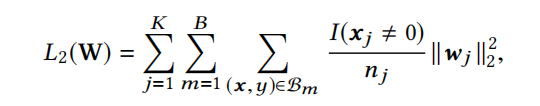
B是mini-batches的批次数量, B m \mathcal{B}_m Bm 则是第m个批次。
α m j = m a x ( x , y ) ∈ B m I ( x j ≠ 0 ) \alpha_{mj}=max_{(x,y)\in \mathcal{B}_m} I(x_j \neq 0) αmj=max(x,y)∈BmI(xj=0),表示第m个批次 B m \mathcal{B}_m Bm 至少有一个实例存在feature id j j j,那么,上式又可以近似等于下式:

最后,加入mini-batch aware regularization的embedding参数的梯度下降如下式:

自适应的激活函数
PReLU是ReLU之后最经常被使用的激活函数,其公式如下式:
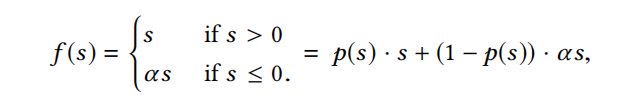
PReLU优化了ReLU在输入s小于0的场景,但仍然存在hard rectified(矫正) point,即当输入s=0时,这可能会让每一个网络层的输入变成不同的分布。
基于这种考虑,论文提出了一种数据自适应的激活函数Dice,如下式:
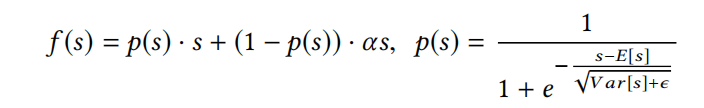
看到这个公式,很容易就联想到batch normalization,这两者的计算存在很多相似之处。Dice在训练阶段, E [ s ] E[s] E[s]和 V a r [ s ] Var[s] Var[s]是每一个批次的输入的均值和方差;而在推理阶段, E [ s ] E[s] E[s]和 V a r [ s ] Var[s] Var[s]则是所有训练批次数据的移动均值版本,与bn是一样的方式。
ϵ \epsilon ϵ是一个平滑常量,避免出现分母为0的情况。
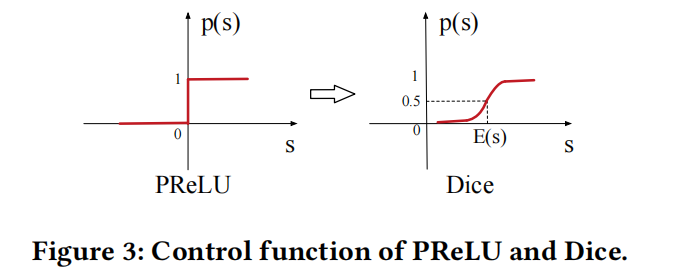
Dice可以看成是PReLU的泛化版本,其关键idea是根据数据去自适应调节rectified point。 当 E [ s ] = 0 a n d V a r [ s ] = 0 E[s]=0\ and\ Var[s]=0 E[s]=0 and Var[s]=0 时,Dice则退化为PReLU,两者的对比如下图:
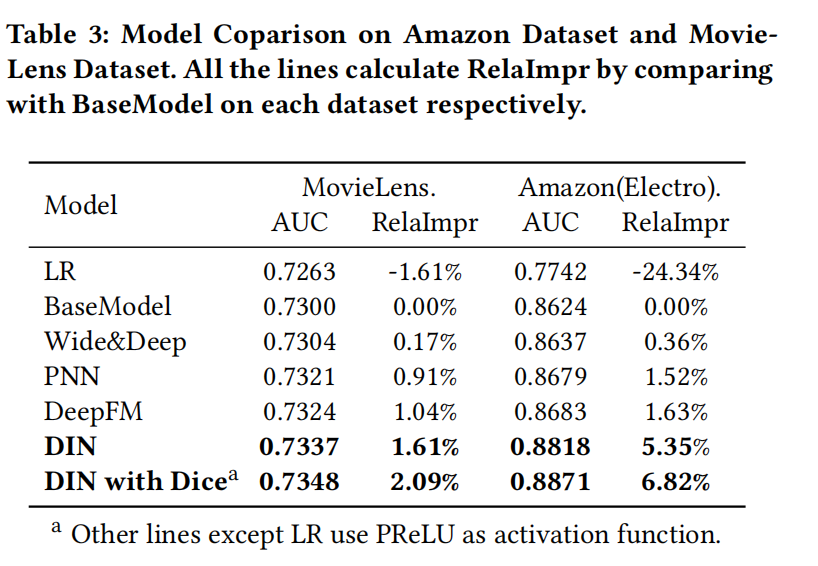
实验结果
指标
论文衡量模型效果,使用的指标是用户加权的AUC,为了简化,还是以AUC表示,如下式:

n是用户的数量,# i m p r e s s i o n i impression_i impressioni和 A U C i AUC_i AUCi是第i个用户的曝光量和AUC。
另外,还加入了相比Base Model的相对提升指标,如下式:

代码实现
git
推荐系统CTR建模系列文章:
CTR特征重要性建模:FiBiNet&FiBiNet++模型
CTR预估之FMs系列模型:FM/FFM/FwFM/FEFM
CTR预估之DNN系列模型:FNN/PNN/DeepCrossing
CTR预估之Wide&Deep系列模型:DeepFM/DCN
CTR预估之Wide&Deep系列(下):NFM/xDeepFM
CTR特征建模:ContextNet & MaskNet(Twitter在用的排序模型)