Vision Mamba:使用双向状态空间模型进行高效视觉表示学习
模型效果
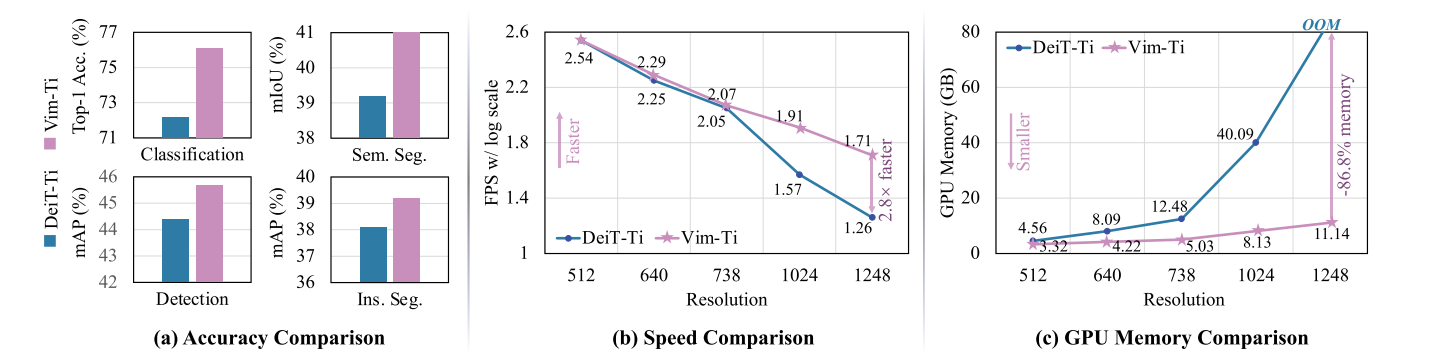
将DeiT和Vim模型之间的性能和效率比较,为了进行准确性比较,我们首先在IN1K分类数据集上预训练DeiT和Vim,然后在不同的下游密集预测任务上微调通用主干,即,语义分割、目标检测、实例分割。结果表明,所提出的Vim优于DeiT的预训练和微调任务。在处理高分辨率图像时,Vim的计算和内存效率也比DeiT高。例如,Vim比DeiT快2.8倍,在对分辨率为1248×1248的图像进行批量推理提取特征时,节省86.8%的GPU内存,即每张图片节省6084个token。
前言
该方法利用位置嵌入对图像序列进行标记,并利用双向状态空间模型对视觉表示进行压缩。
VIT的优点:
- ViT可以通过自注意为每个图像块提供数据/块相关的全局上下文
- 通过将图像视为没有2D归纳偏差的补丁序列来进行模态不可知建模,这使其成为多模态应用的优选架构
VIT的缺点:处理长距离视觉依赖时的速度和内存使用较差
Mamba用于视觉任务的挑战:单向建模和缺乏位置意识
- 本文提出Vision Mamba(Vim),它采用了双向SSM数据相关的全局视觉上下文建模和用于位置感知视觉理解的位置嵌入
- 在不需要注意的情况下,所提出的Vim具有与ViT相同的建模能力,而它仅具有次二次时间计算和线性存储复杂度。具体来说,Vim比DeiT快2.8倍,在1248×1248分辨率的图像上进行批量推理提取特征时,节省了86.8%的GPU内存。
- 本文对ImageNet分类和密集预测下游任务进行了广泛的实验。结果表明,与成熟且高度优化的普通视觉Transformer相比,Vim实现了更好的性能
方法
关于SSM和Mamba的知识参见下面的资料,这里不再详细赘述。
S4论文-SSM离散化公式推导 - coco的文章 - 知乎
https://zhuanlan.zhihu.com/p/677787187
一文通透想颠覆Transformer的Mamba:从SSM、S4到mamba、线性transformer(含RWKV解析)
http://t.csdnimg.cn/o0lXt
Vision Mamba
ViM模型首先将输入图像分成小块,然后将小块投影成token。然后将这些令牌输入 ViM 编码器。然后序列中的每个标记经历两个单独的线性变换。该算法在向前和向后两个方向上处理这些转换后的令牌,模拟双向神经网络层。与用于建模文本序列的 Mamba 模型不同,ViM 编码器可以向前和向后处理标记序列。对于每个方向,该过程涉及应用一维卷积,然后应用 Sigmoid 线性单元 (SiLU) 激活函数。对于像 ImageNet 分类这样的任务,额外的可学习分类标记会添加到标记标记序列中(该标记是 BERT 开始一致使用的标记)。
ViM 的突出特点之一是其类似于 LSTM 工作原理的双向处理能力。与许多以单向方式处理数据的模型不同,ViM 的编码器可以向前和向后方向处理标记。双向模型可以更丰富地理解图像上下文,这是准确图像分类和分割的关键因素。
一旦令牌被卷积并激活,算法就会执行额外的线性变换并应用 softplus 函数,以确保输出值保持正值。这些转换为 SSM 序列建模功能准备标记。
SSM 操作之后,该算法应用门控机制,通过 SSM 输出与 SiLU 激活的前向和后向序列的元素相乘来调制信息流。这种门控机制可能被设计为控制每个方向处理的贡献。
最后一步结合了残差连接,将原始输入序列添加到门控输出,这有助于保留早期层的信息并解决梯度消失问题。整个过程的输出是一个新的令牌序列,该序列可能经历了复杂的转换,捕获了序列两个方向上的复杂依赖关系。该算法通过返回这个转换后的标记序列来结束。
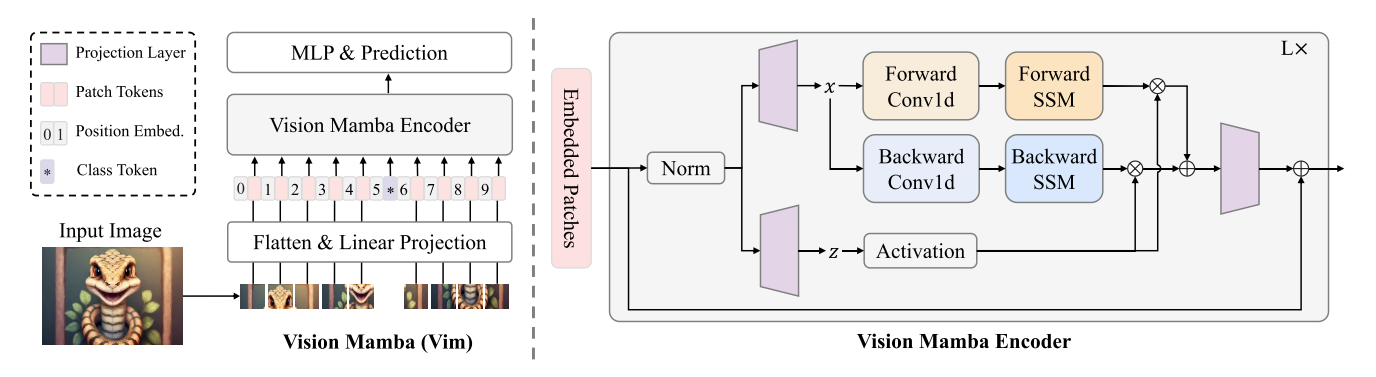
vim block
原始的Mamba块是为1-D序列设计的,这不适合需要空间感知理解的视觉任务。在本节中,我们将介绍Vim块,它包含视觉任务的双向序列建模。

架构细节
总之,我们的架构的超参数如下所示:
L:块的数量,D:隐藏状态维度,E:扩展状态维度,N:SSM维度。
和ViT和DeiT一样,我们首先使用16×16内核大小的投影层来获得非重叠补丁嵌入的一维序列。随后,我们直接堆叠L个Vim块。默认情况下,我们将块的数量L设置为24,SSM维度N设置为16。为了与DeiT系列的模型尺寸保持一致,我们将隐藏状态维度D设置为192,将扩展状态维度E设置为384。对于小尺寸变体,我们将D设置为384,E设置为768。
结论
本文提出了一种在视觉任务中应用 Mamba 的技术,使用双向状态空间模型 (SSM) 进行全局视觉上下文建模和位置嵌入。这种方法表明传统的注意力机制可能会过时,因为 ViM 可以有效地捕获视觉数据的位置上下文,而无需依赖基于 Transformer 的注意力机制。
ViM 以其次二次计算时间和线性内存复杂性而脱颖而出,这与 Transformer 模型中常见的二次增长形成鲜明对比。这种效率使得 ViM 特别擅长处理高分辨率图像。
对 ImageNet 分类等基准测试的广泛测试证实了 ViM 的性能和效率,展示了其作为计算机视觉领域强大工具的潜力。