半小时到秒级,京东零售定时任务优化怎么做的?
导言:
京东零售技术团队通过真实线上案例总结了针对海量数据批处理任务的一些通用优化方法,除了供大家借鉴参考之外,也更希望通过这篇文章呼吁大家在平时开发程序时能够更加注意程序的性能和所消耗的资源,避免在流量突增时给系统带来不必要的压力。
业务背景:
站外广告投放平台在做推广管理状态优化重构的时候,引入了四个定时任务。分别是单元时间段更新更新任务,计划时间段更新任务,单元预算撞线恢复任务,计划预算撞线恢复任务。导言:京东零售技术团队通过真实线上案例总结了针对海量数据批处理任务的一些通用优化方法,除了供大家借鉴参考之外,也更希望通过这篇文章呼吁大家在平时开发程序时能够更加注意程序的性能和所消耗的资源,避免在流量突增时给系统带来不必要的压力。
时间段更新更新任务:
由于单元上可以设置分时段投放,最小粒度是半个小时,每天没半个小时都已可以被广告主设置为可投放或者不可投放,当个广告主修改了,这个时间段,我们可以通过binlog来异步更新这个状态,但是,随着时间的流逝,单元有可能在上半个小时处于可投放状态,来到下半个小时就处于不可投放状态。此时我们的程序是无法感知的,只能通过定时任务,计算每个单元在当前时间段是否需要被更新子状态。计划时间段更新任务类似,也需要半个小时跑一次。
单元预算恢复任务:
当单元的当天日预算被消耗完之后,我们接收到计费的信号后会把该单元的状态更新为预算已用完子状态。但是到第二天凌晨,随着时间的到来,需要把昨天带有预算已用完子状态的单元全部查出来,然后计算当前是否处于撞线状态进行状态更新,此时大部分预算已用完的单元都处于可播放状态,所以这个定时任务只需要一天跑一次,计划类似。
本次以单元和计划的时间段更新为例,因为时间段每半个小时需要跑一次,且数据量多。
数据库:
我们的数据库64分片,一主三从,分片键user_id(用户id)。
定时任务数据源:
我们选取只有站外广告在用的表dsp_show_status作为数据源,这个表总共8500万(85625338)条记录。包含三层物料层级分别是计划,单元,创意通过type字段区分,包含四大媒体(字节,腾讯,百度,快手)和京东播放的物料,可以通过campaignType字段区分。
机器配置和垃圾回收器:
单台机器用的8C16G
-Xms8192m -Xmx8192m -XX:MaxMetaspaceSize=1024m -XX:MetaspaceSize=1024m -XX:MaxDirectMemorySize=1966m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8
定时任务处理逻辑
对于单元,
第一步、先查出来出来dsp_show_status 最大主键区间MaxAutoPk和最小区间MinAutoPk。
第二步、根据Ducc里设置的步长,和条件,去查询dsp_show_status表得出数据。其中条件包含层级单元,腾讯渠道(只有腾讯渠道的单元上有分时段投放),不包含投放已过期的数据(已过期的单元肯定不在投放时间段)
伪代码:
startAutoPk=minAutoPk;
while (startAutoPk <= maxAutoPk) {//每次循环的开始区间startAutoPkFinal = startAutoPk;//每次循环的结束区间endAutoPkFinal = Math.min(startAutoPk + 步长, maxAutoPk);List<showSatusVo> showSatusVoList =showStatusConsumer.betweenListByParam(startAutoPkL, endAutoPkL, 条件(type=2单元层级,不包含已过期的数据,腾讯渠道))startAutoPk = endAutoPkFinal + 1;
}第三步、遍历第二步查询出来showSatusVoList,得到集合单元ids,然后根据集合ids去批量查询单元扩展表,取出单元扩展表里每个单元对应的start_time,end_time,time_range_price_coef字段。进行子状态计算。
计算逻辑伪代码:
1、当前时间<start_time, 子状态为 单元未开始投放
2、end_time <当前时间 ,子状态为 单元投放已结束
3、start_time<当前时间<end_time 且当前时间不在投放时间段 ,子状态为单元不在投放时间段
4、其他,移除单元未开始投放,单元投放已结束,单元不在投放时间段 三个子状态
然后对这批单元按上面的四种情况进行分组,总共分为四组。如果查询来的dsp_show_status表的子状态和算出来的子状态一样则不加入分组,如果不一样则加入相应分组。
最后对这批单元对应的dsp_show_status表里的记录进行四次批量更新。
计划时间段任务处理逻辑类似,但是查询出来的数据源不包含腾讯渠道的,因为腾讯的渠道的时间段在单元上,计划上没有。
任务执行现象:
(一阶段)任务执行时间长且CPU利用率高
按某个pin调试任务,逻辑上落数据没有问题,但是任务时长在五分钟左右。当时是说产品可以接受这个时间子状态更新延迟。
但当不按pin调试进行计划时间段任务更新时,相对好点,十分钟左右,cpu不到50%。
进行单元时间段任务更新时,机器的cpu是这样的:
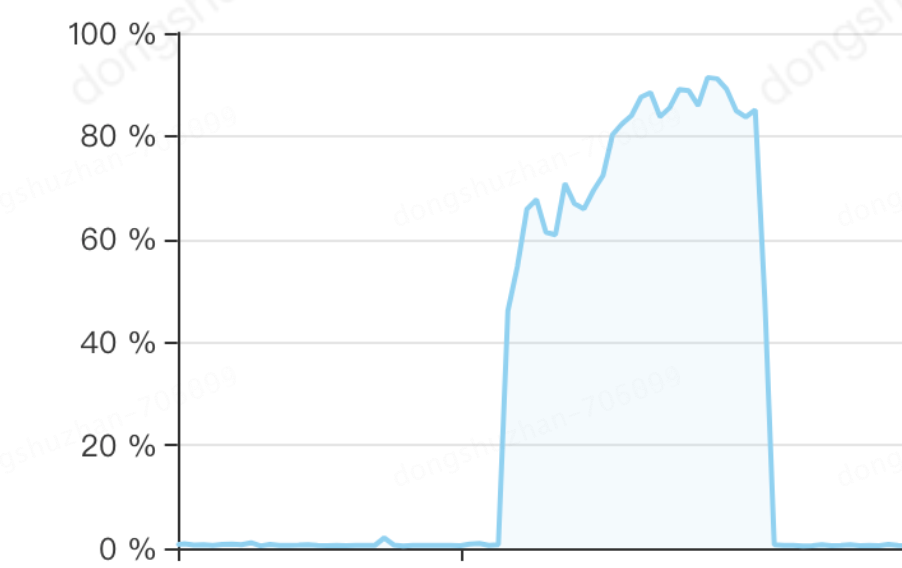
cpu80%,且执行了半个小时才执行完成。如果这样,按业务需求,这个批次执行完成就要继续执行下一次了,肯定是不满需求的。
那怎么缩短CPU利用率,缩短任务执行时间呢?听我慢慢讲解。
(二阶段)分析数据源,调大步长缩短任务运行时间
上面这个情况肯定满足不了业务需求的。
第一感觉优化的方向应该往着数据分布上想,于是去分析dsp_show_status表里的数据,发现表里数据稀疏主要是因为两个点。
(1)程序问题。这个表里不仅存在站外的数据,还因为某些程序问题无意落了站内的数据。我们查询数据的时候卡了计划类型,不会处理站内的数据。但是表里存在会增大主键区间。导致我们每个批次出来的数据比较稀疏。
(2)业务背景。由于百度量小,字节则最近进行了升级,历史物料不多,快手之前完全处于停投。所以去除出腾讯渠道,计划需要处理的数据量比较少18万(182934)。但是腾讯侧一直没有进行升级,而且量大,所以需要处理的单元比较多130万左右(1309692 )。
于是我们为了避免每个批次查出来要处理数据比较少,导致空跑,调大了步长。
再次执行任务
果然有效,计划时间段任务计,cpu虽然上去了,但是任务5分钟就执行完了。
执行执行单元时间段更新的时候,时间缩短到十几分钟,但是cpu却是这样的,顶着100%cpu跑任务。
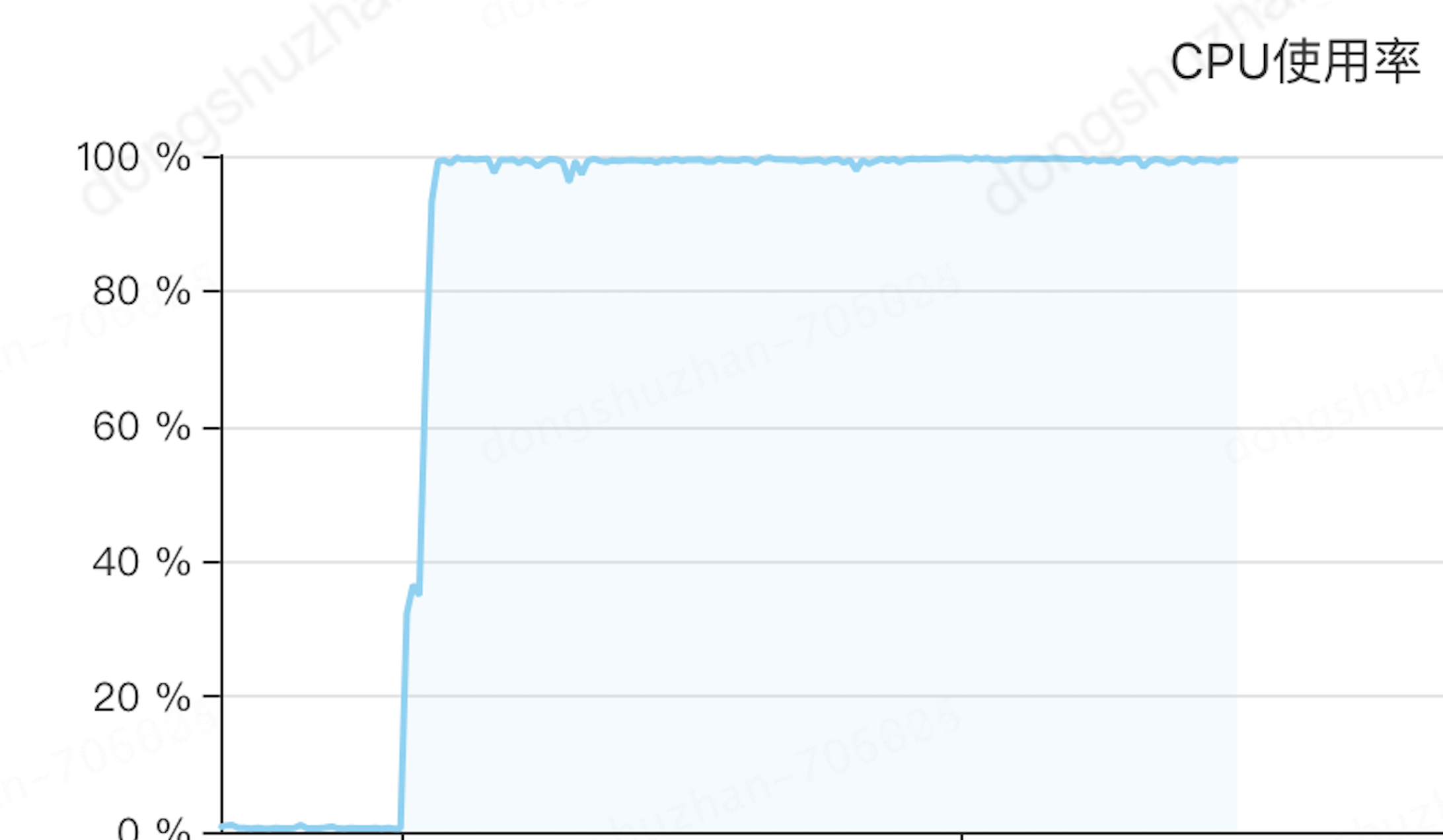
道路且长,那我们怎么解决这个cpu问题呢,请看下一阶段。
(三阶段)减少临时对象大小和无效日志,避免多次ygc
这个cpu确实令人悲伤。当时我们
第一想法是,为了尽快满足产品需求,先用我们的组件事件总线进行负载(底层是用的mq)到多台机器。这样不但解决了cpu利用率高的问题,还能解决任务执行时间长的问题。这个想法确实能解决问题,但是还是耗用机器资源。
第二想法是,由于时间段在表里是个json存储,在执行查询的时候不好进行条件查询。于是想着单独在建一张表,拉平时间段,在进行查询的时候直接查新建的表,不再查询存储json时间段的表。但是这张表相当于异构了数据源,不但要新建表还要考虑这张表的维护。
于是我们继续分析cpu高用在哪里,理论上这个定时任务是IO型任务,cpu利用率应该比较低。在执行任务的时候,我们仔细观察了机器的监控,发现在执行单元时段更新任务时,机器每分钟不断地进行多次ygc。之前刚和组内同学分享过gc相关知识。这里说一下,虽然我们的机器用的是G1垃圾回收器,没有进行full gc,但是G1在ygc的时候会比jdk1.8默认的垃圾回收器要更耗资源,因为G1还要mixgc兼顾回收老年代的垃圾。G1用于响应优先,默认的垃圾回收器吞吐量优先。这样的批量任务其实更适合用默认垃圾回收器。
不断进行ygc肯定是因为我们在执行任务的时候产生大量的临时对象导致的。
这里我们采取了两条有效措施:
(1)去掉无效日志。由于调试时加了大量日志,java进行序列化的时候会产生比原来的对象占用更多内存的临时变量。于是我们去掉了所有的无效日志。
(2)减少临时对象占用的内存。代码对象的个数肯定不能减少,于是我们我们减少对象的的大小。之前是我们用的proxy工程现成接口,把表里的每个字段都查出来了,但是表里那么多字段,实际我们每张表也就用2-3个字段。于是我们为这个定时任务写了专用的查询接口,每个接口只查我们需要的字段。
结果果然有效,单元时间段更新任务从原来的顶着100%cpu跑了十几分钟,瞬间降到了cpu不到60%,五分钟执行完成。ycg次数也有明显的下降。
刷数任务:这两个措施到底多有效呢,说另一个栗子也与这个需求相关。在没有减少临时变量大小(把单元表和单元扩展表中的所有字段都查出来)把单元表的启停状态和单元扩展表的审核状态刷到dsp_show_status时,涉及1400百万数据,刷了两个小时也没刷完,最后怕影响物料传输工程查询数据库给停了。之后减少临时变量后,九分钟就刷完了。
经过上述的优化看似皆大欢喜,但还存在很大的问题。给大家看一个监控图。
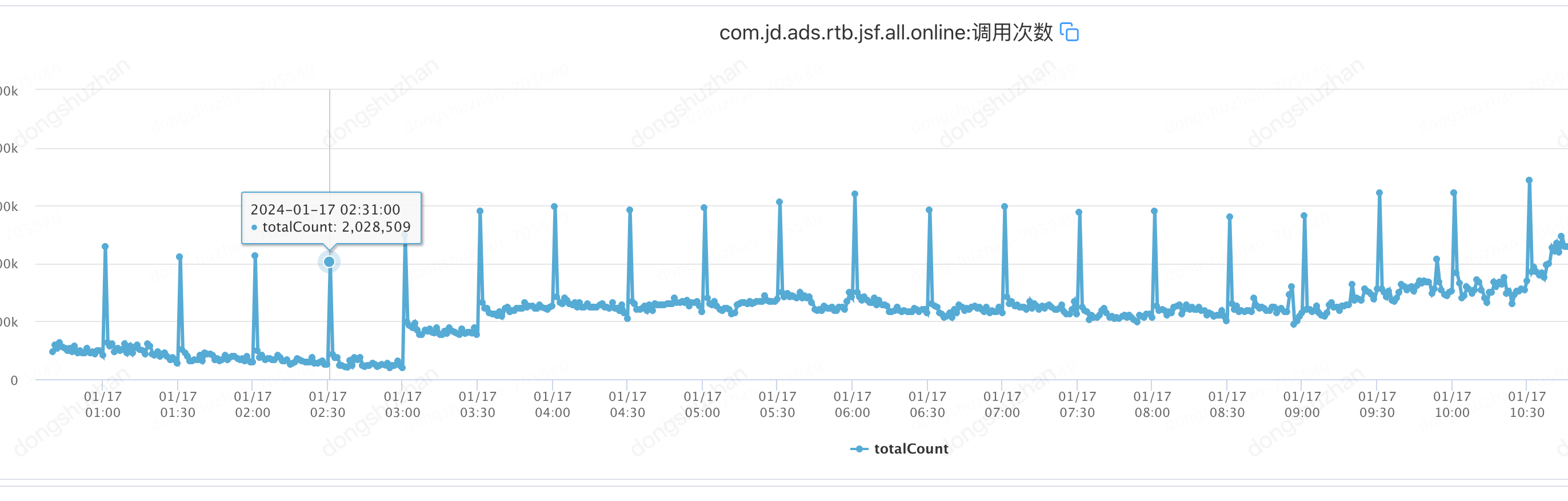
看完这个监控图,我们慌了,计划和单元更新时间段任务每半个小时运行一次,都给数据库带来了200万qpm的增长,这无疑给我们的数据库带来了巨大隐患。
此时总结下来存在两个问题有待解决。
(1)、怎么减少与数据库的交互次数,消除给数据库带来的安全隐患。
(2)、怎么降低任务的执行的时间,五分钟的子状态更新延迟是不可以接受的。对广告主来说更是严重的bug。
这两个问题让我们觉得这个任务还有很大的优化空间,于是我们继续分析优化。下一阶段的措施很好的解决了这两个问题。
(四阶段)基于游标查询数据源,基于数据库分片批量更新,降低数据库交互次数,避免空跑缩短任务运行时间。
对于上面的问题(1),我们分析这么大的调用量主要用在了哪里。
发现由于站内数据的存在和历史数据的删除以及dsp_show_status和其他表公用一个主键id生成序列,导致dsp_show_status表的MaxAutoPk到达90多亿。
也就是所及时我们步长达到2万,光查询数据调用次数就达到了45万次,在加上每次都有可能产生小于四次的更新操作。也就是一个定时任务都会产生高大100万的qpm,两个任务产生200万也就符合预期了。于是我们把步长调整为4万,qpm降到了130万左右,但还是很高。

于是我们继续分析,就单元时间段更新任务而言,其实我们需要查出来的数据也就是上面提到的腾讯的130万左右(1309692 )。但是我们查询了45万次且步长是2万。也就是说我们每次查出来的数据还是很稀疏且个数不确定,如果忙盲目的调大步长,很可能由于某个区间数据量特别多导致负载不均衡,还有可能rpc超时。
那怎么才能做到每次查出来数据个数就是我们的设置的步长呢,我们想到了mysql里面的游标查询。但是jed弹性数据库并不支持,于是我们就要手动实现游标的逻辑。此时我们考虑dsp_show_status是否有唯一主键能标识唯一记录。假如主键不唯一,就有可能出现漏查和重复查询的情况。幸运的是我们的jed数据库所有的表里都有唯一主键。于是我们手写了一个游标查询。
(1)游标查询
伪代码如下
//上层业务代码
Long maxId = null;
do {showStatuses = showStatusConsumer.betweenListByParam(startAutoPkL, endAutoPkL, maxId,每次批次要查出来的数据,其他条件(type=2单元层级,不包含已过期的数据,腾讯渠道))if (CollectionsJ.isEmpty(showStatuses)) {//如果为空的,直接推出,代表已经查到最后了。break;}//循环变量值叠加,查出来的数据最后一行的id,数据库进行了升序,也就是这批记录的最大idmaxId = showStatuses.get(showStatuses.size() - 1).getId();//处理查出来的数据processShowStatuses( showStatuses);} while (CollectionsJ.isNotEmpty(showStatuses));//下层sql</select>SELECTid,cga_id,status_bitmap1,user_idFROM dsp_show_status<where>id BETWEEN #{startAutoPk,jdbcType=BIGINT} AND #{endAutoPk,jdbcType=BIGINT}//param.maxId 上一批次查出数据的最大maxId<if test="param.maxId != null">AND id >#{param.maxId,jdbcType=BIGINT}</if><----!其他条件------></where>order by id<if test="param.batchSize != null">//上层传过来的每个批次要查询的出来的数据量limit #{param.batchSize}</if></select>这里可以思考一下基于游标的查询方式在什么场景下有效? 如果有效需要满足一下两个条件
1、jed表里有唯一键,且基于唯一键查询排序
2、区间满足查询条件的记录越稀疏越有效
这里要一定注意排序的顺序,是升序不是降序。如果你无意间按降序排序,那么每次查询的都是最后的满足条件的batch大小的数据。
(2)深度分页引起慢sql
此时组内同学提出了一个疑问,深度分页引起慢sql问题。这里解释一下到底会不会产生慢sql。
当进行分页的时候一般sql会这样写
select *
from dsp_show_status
where 其他查询条件
limit 50000000 , 10;当limit 的初始位置非常靠后时,即使压中查询条件里的二级索引,也需从二级索引得到的主键索引去加载所有的磁盘记录,然后扫描50000000行记录取50000000到-50000010条返回,这里涉及到记录的扫描,和多次磁盘到内存的IO,所以比较耗时。
但是我们的sql
select *
from dsp_show_status
where 其他查询条件
and id >maxId
oder by id
limit 100当maxId非常大时,比如50000000 时,mysql压中查询条件的里的二级索引,得到主键索引。然后MySQL会直接过滤掉 id<50000000 的主键id,然后从主键50000000开始查询数据库得到满足条件的100条记录。所以他会非常快,并不是产生慢sql。实际sql执行只需要37毫秒。

(3) 按数据库分片进行批量更新
但是又遇到了另一个数据库长事务问题,由于使用了基于游标的方式,查出来的数据都是需要进行计算的数据,且任务运行时间缩短到到30秒。那在进行数据更新时,每次批量更新都比之前(不使用游标的方式)更新的数据量要多,且并发度高。其次由于批量更新的时候更新多个单元id,这些id不一定属于某一个user_id,所以在执行更新的时候没有带分片键,此时数据库jed网关又出现了问题。
当时业务日志的报错的信息是这样的,出现了执行时间超过了30秒的sql,被kill掉:
{"error":true,"exception":{"@type":"org.springframework.jdbc.UncategorizedSQLException","cause":{"@type":"com.mysql.cj.jdbc.exceptions.MySQLQueryInterruptedException","errorCode":1317,"localizedMessage":"transaction rolled back to reverse changes of partial DML execution: target: dsp_ads.c4-c8.primary: vttablet: (errno 2013) due to context deadline exceeded, elapsed time: 30.000434219s, killing query ID 3511786 (CallerID: )","message":"transaction rolled back to reverse changes of partial DML execution: target: dsp_ads.c4-c8.primary: vttablet: (errno 2013) due to context deadline exceeded, elapsed time: 30.000434219s, killing query ID 3511786 (CallerID: )","sQLState":"70100","stackTrace":[{"className":"com.mysql.cj.jdbc.exceptions.SQLError","fileName":"SQLError.java","lineNumber":126,"methodName":"createSQLException","nativeMethod":false},{"className":"com.mysql.cj.jdbc.exceptions.SQLError","fileName":"SQLError.java","lineNumber":97,"methodName":"createSQLException","nativeMethod":false},
数据库的监控也发现了异常,任务执行的时候出现了大量的MySQL rollbakc:
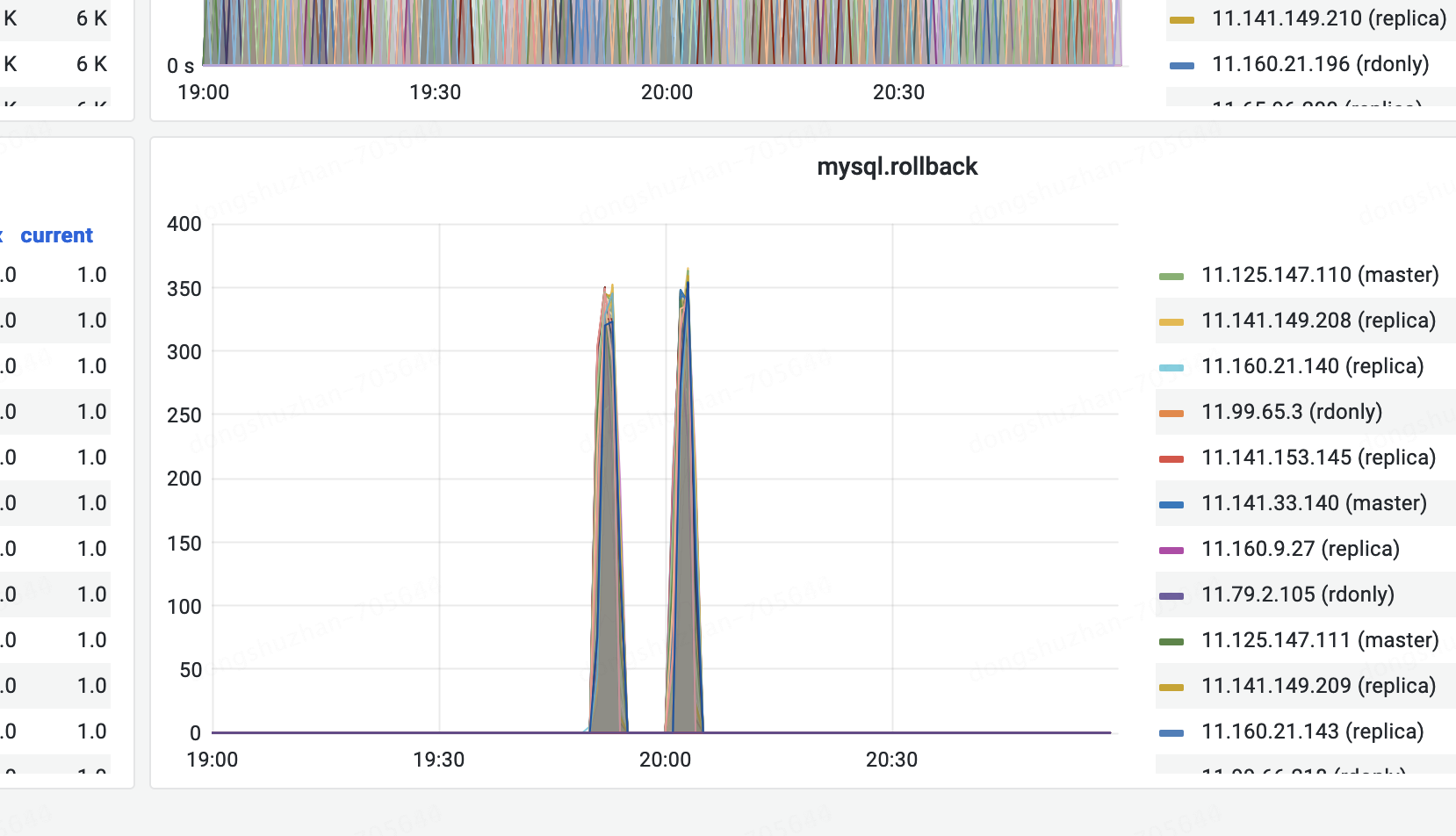
当时联系dba suport ,dba排查后告诉我们,我们的批量更新sql在数据库执行非常快,但是我们用了长事务超过30秒没有提交,所以被kill掉了。但是我们检查了我们的代码,发现并没有使用事务,且我们的事务是单库跨rpc事务,从发起事务到提交事务对于数据库来说执行时间非常快,并不会出现长事务。我们百思不得其解,经过思考我们觉得可能是jed网关出现了问题,jed网关的同学给的答复是。由于没有带分片键导致jed网关会把sql分发到64分片,如果某个分片上没有符合条件的记录,就会产生间隙锁,其他sql更新的时候一直锁更待从而导致事务一直没有提交出现长事务。
对于网关同学给我们的答复,我们仍然持有怀疑态度。本来我们想改下数据库的隔离级别验证一下这个回复,但是jed并不支持数据库隔离级别的更改。
但是无论如何我们知道了是因为我们批量更新时不带分片键导致的,但是如果按userId进行更新,将会导致原来只需要一次进行更新,现在需要多次更新。于是我们想到循环64分片数据库进行批量更新。但是jed并不支持执行sql时指定分片,于是我们给他们提了需求。
后来我们想到了折中的方式,我们按数据库分片对要执行的单元id进行分组,保证每个分组对应的单元id落到数据库的一个分片上,并且执行更新的时候加上userId集合。这个方案要求jed网关在执行带有多个分片键sql时能进行路由。这边jed的同事验证了一下是可以的。

于是我们在进行更新的时候对这些ids按数据库分片进行了分组。
伪代码如下:
//按数据库分片进行分组
adgroups.stream().collect(Collectors.groupingBy(Adgroup::shardKey));
// 按计算每个userId对象的数据库分片,BinaryHashUtil是jed网关的jar包
public String shardKey() {try {return BinaryHashUtil.getShardByVindex(ShardEnum.SIXTY_FOUR_SHARDS, this.userId);} catch (SQLException ex) {throw new ApplicationException(ex);}}在上述的刷数任务中能够执行那么快,并且更新数据没有报错,一方面也得益于这个按数据库分片进行分组更新数据。
(4)优化效果
经过基于游标查询的方式进行任务优化,就单元时间段更新时。从原来的五分钟,瞬间降为30秒完成。cpu不到65%。由于计划记录更稀疏,所以更快。
对数据库的查询更新操作,也从原来的也从原来的200万qpm降为2万多(早上高峰的时候),低峰的时候甚至不到两万。当我们把batchSize设置为100时,通过计算单元的130多万/100 +计划的18万/100=1.4万次qpm 也是符合预期的。
查询db监控:
更新db的监控,也符合预期
虽然引入基于游标的方式进行查询非常有效,把原来的200万qpm数据库交互降到了2万,把任务运行时间从5分钟降到了30秒。但是仔细分析你还会发现,还存在如下问题。
1、单台机器cpu高,仍然在60%,对于健康的程序来说,这个数值仍然不被接受。
2、查询和更新数据量严重不符,每次定时任务更新只更新了上万行记录,但是我们却查出来了上百万(130万)行记录进行子状态,这无疑还在浪费CPU和磁盘IO资源。
监控如下
每次查询出来的记录数:
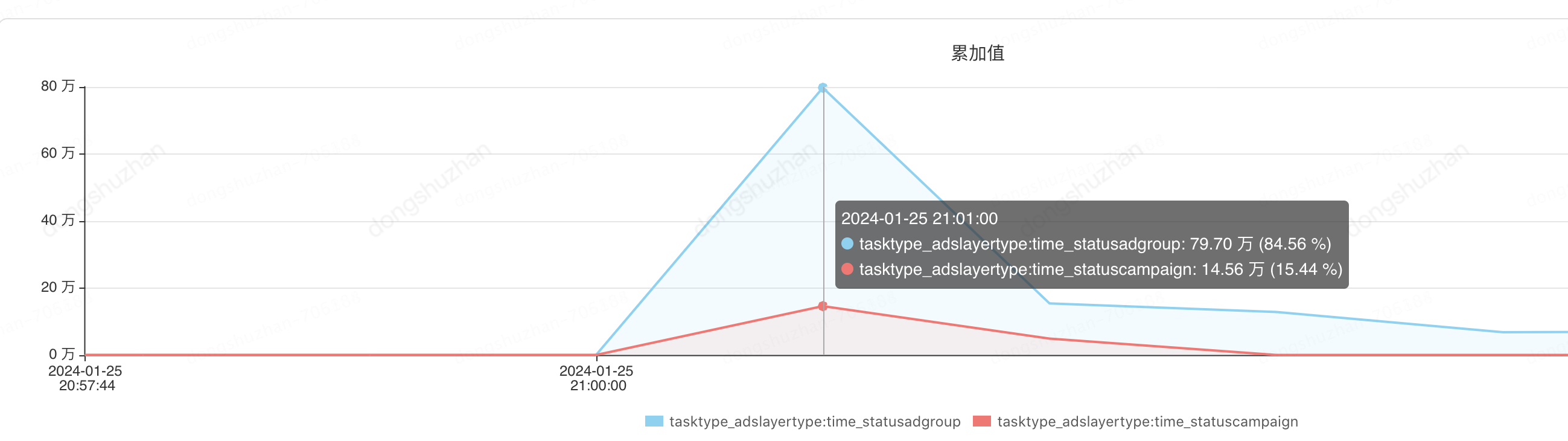
每次需要更新的记录数:
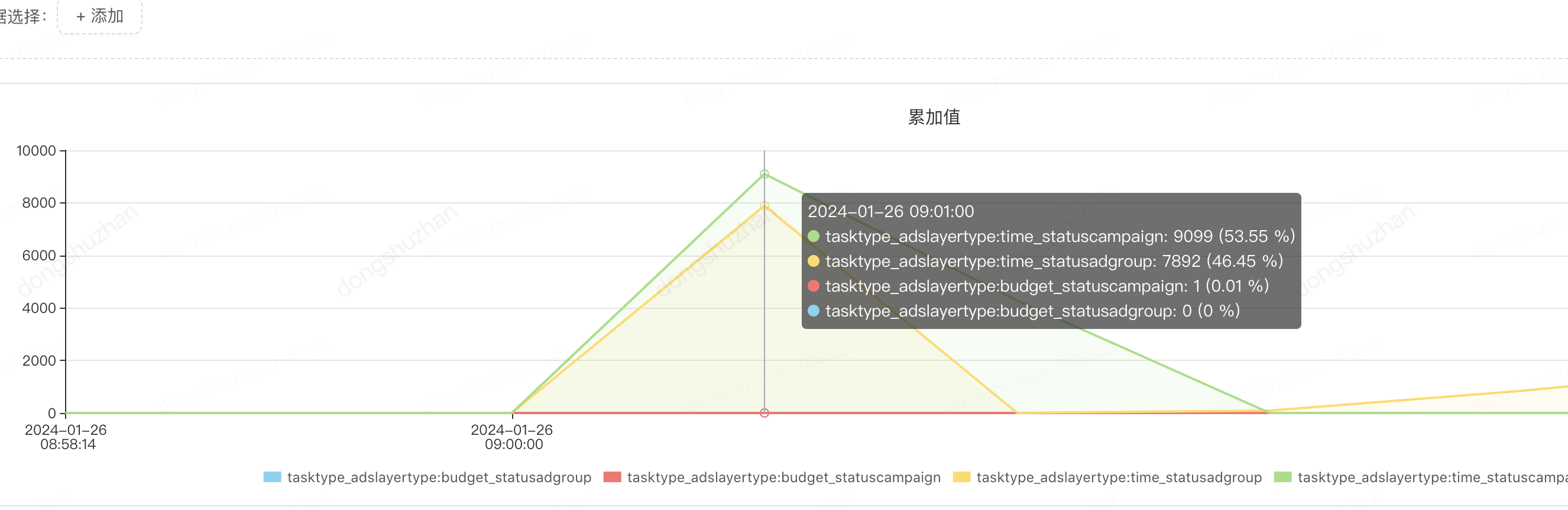
经过上面的不断优化,我们更加相信,资源不能被浪费,作为程序员应该追求极致。于是我们还继续优化。解决上面两个问题
(五阶段)异构要更新状态的数据源,降低数据库交互次数,降低查询出来的数据量,降低机器cpu利用率。
为了减少无效数据查询和计算,我们还是决定冗余数据,但是不是像前面提到的新建一张表,而是在dsp_show_status 表里冗余一个nextTime字段,来存储这个物料下一次需要被定时任务拉起更改状态的时间戳,(也就是物料在投放时间段子状态和不在投放时间段子状态转变的时间戳),举个栗子,广告主设置某个单元早上8点开始投放,晚上8点结束投放,其他时间不投放。那早8点的时候,这个单元就会被我们的定时任务扫描到,然后计算更新这个单元从不投放变为投放,同时计算比较投放时间段,下一个状态变更的时间段,经过计算得知,广告主在晚上8点需要状态变更,也就是从投放变为不投放,那nextTime字段就落晚上8点的时间戳。这个字段的维护逻辑分为两部分,一部分是广告主主动更改了时间段需要更新计算这个nextTime,另一部分是定时任务拉起这个物料更改完子状态后,再次计算下一次需要被拉起的nextTime。
这样我们定时任务在查询数据源的时候只需新增一个查询条件(因为是存的是时间戳,所以需要卡个范围)就可以查出我们需要真正要更新的数据了。
当维护投放时间段这个异构数据,就要考虑异构数据和源数据的一致性问题。假如某次定时任务执行失败了,就会导致nextTime 和投放时间段数据不一致,此时我们的解决办法时,关闭基于nextTime的优化查询,进行上一阶段(第四阶段)基于游标的全量更新。
sql查询增加条件:
next_time_change between ADDTIME(#{param.nextTimeChange}, '-2:0:0')
and ADDTIME(#{param.nextTimeChange}, '0:30:0')优化之后我们每次查询出来的记录从130万降到了1万左右。
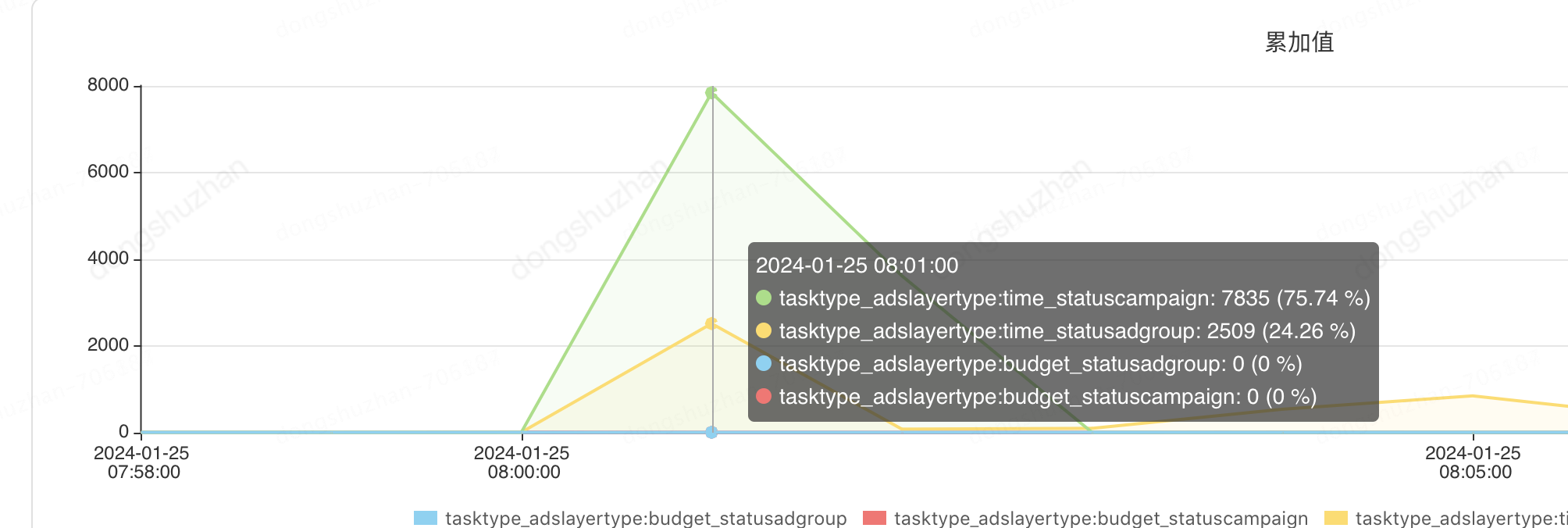
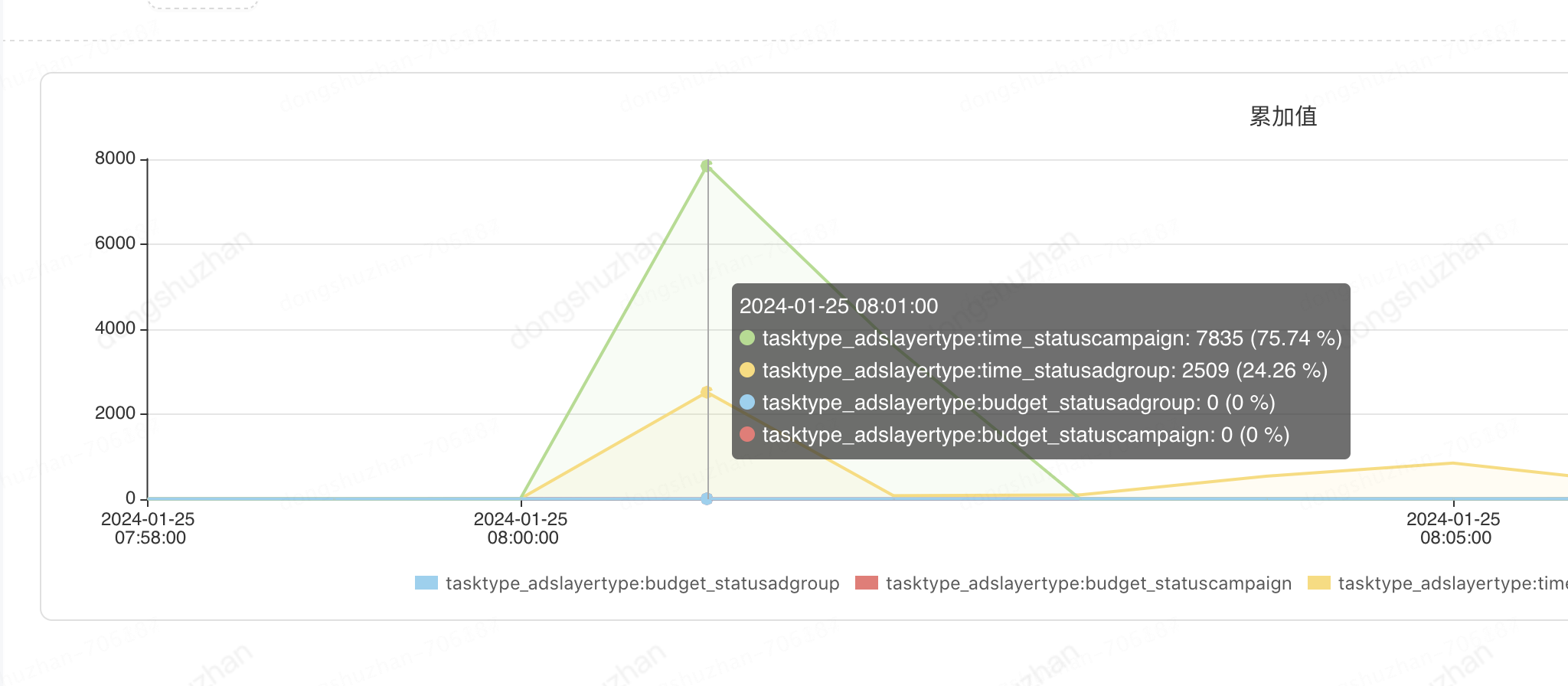
11点的时候计划和单元总共查出来6000个,监控如下:

11点的时候计划和单元总共更新5000个,由于查询数据源的时候卡了时间戳范围,所以符合预期,查出来的个数基本就是要更新的记录。监控如下:

查询次数也从原来的1万次降到了200次。监控如下:

机器的监控如下cpu只用了28%,且只ygc了1次,任务执行时间30秒内完成。

这个增加next_time 这个字段进行查询的思路,和之前做监控审核中的创意定时任务类似。创意表20亿行数据,怎么从20亿行记录表里实时找出哪些创意正在审核中。当时的想法也是维护一个异构的redis数据源,送审的时候把数据写入redis,审核消息过来后再移除。但是当我们分析数据源的时候,幸运的发现审核中的创意在20亿数据中只占几万,大部分创意都是在审核通过和审核驳回,之前大家都了解到建立索引要考虑索引的区分度,但是在这种数据分布严重不均匀的场景,我们建立yn_status联合索引,在取数据源的时候,直接压数据库索引取出数据,sql执行的非常快,20毫秒左右就能执行完成,避免走了很多弯路。
你以为优化结束了? 不,合格的程序员怎么允许系统中存在cpu不稳定的场景存在,即使只增加28%。
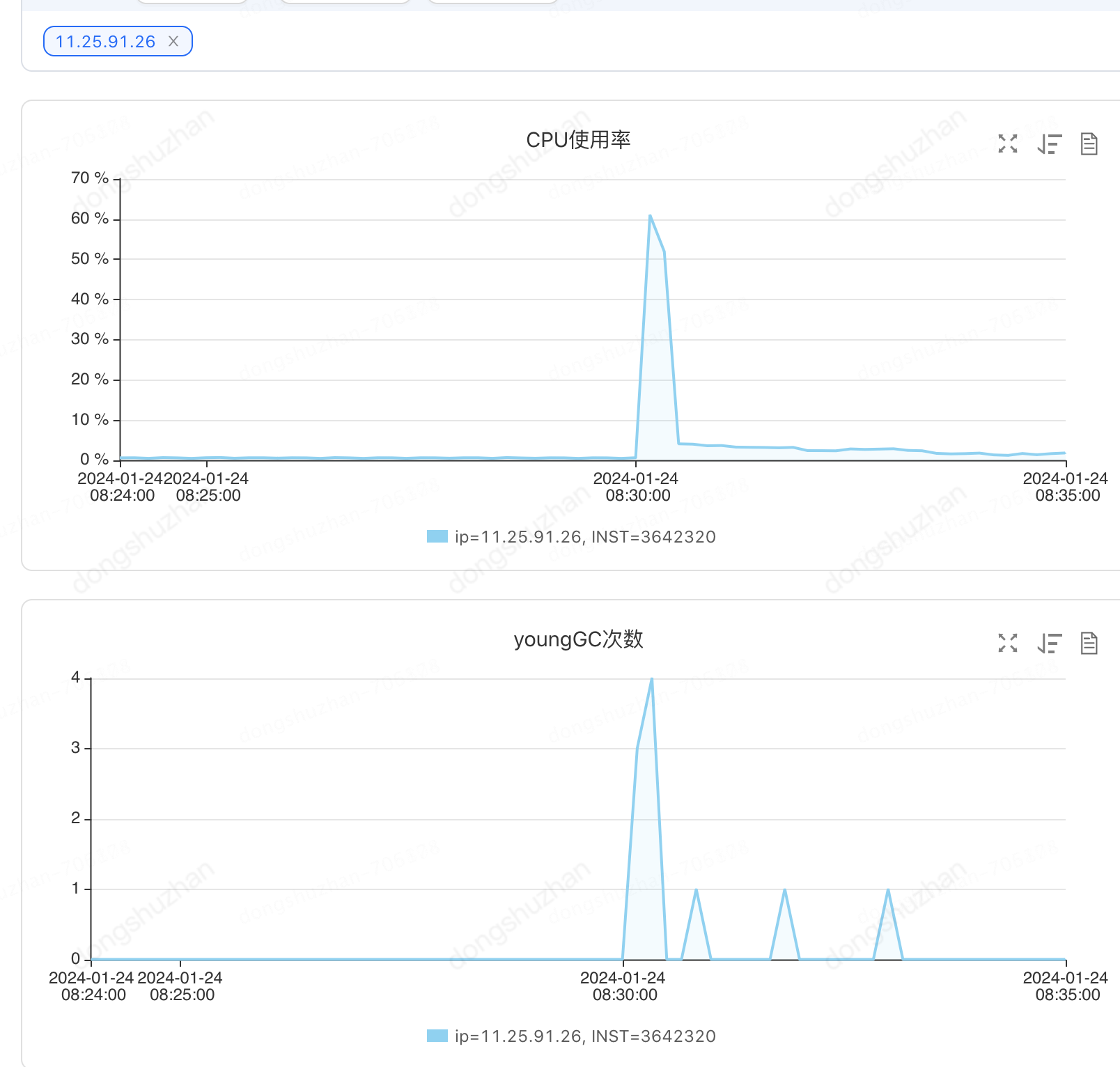
(六阶段)负载均衡,消除所有风险,让系统程序稳定运行。
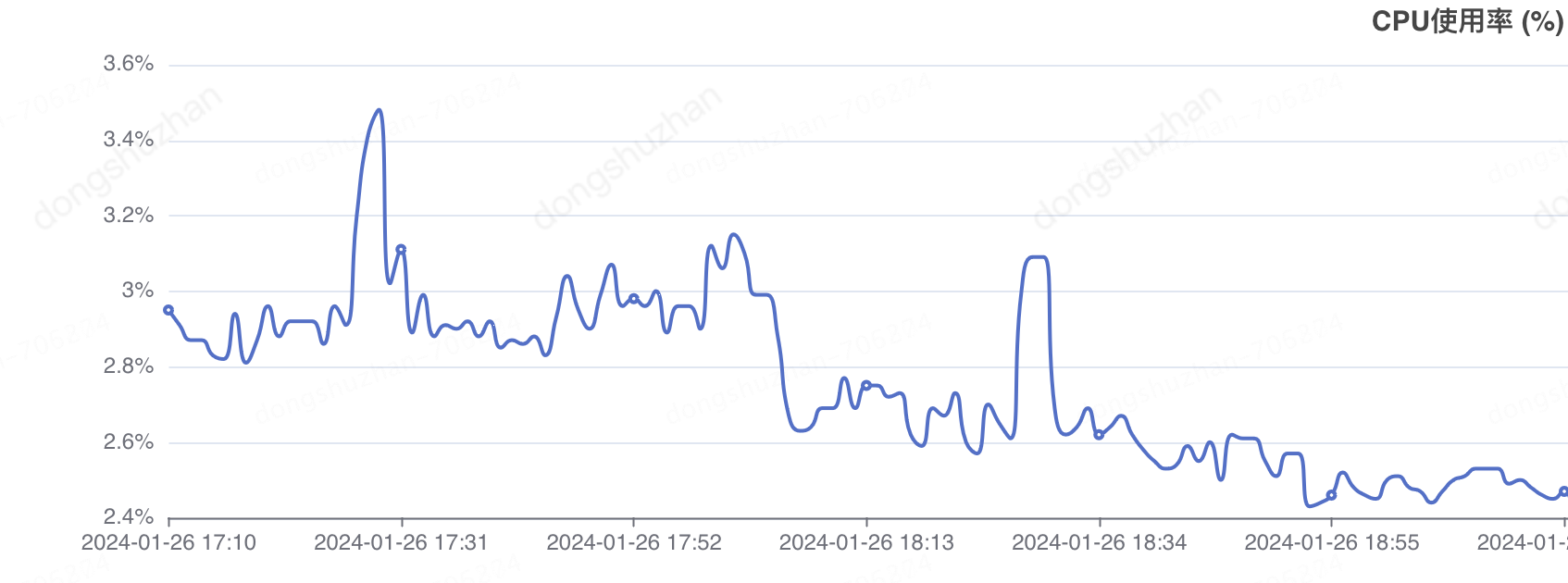
消除单台机器cpu不稳定的最有效办法就是,把大任务拆分为小任务,然后分发到不同的机器上进行执行。我们的定时任务本来就是按批次进行查询计算的,所以本身就是小任务。剩下的就是分发任务,很多人想到的就是利用mq的负载进行分发,但是mq不可控,不可控制失败重试时间。如果一个小任务失败了,下次什么时候被拉起重试就不得而知了,或许半个小时以后?这里用到了我们非常牛逼的一个组件,可重试总线进行负载,支持自定义重试频率,支持自动识别无效重试,防止重试叠加。
负载后的机器cpu是这样的
优化效果数据汇总:
这里列一下任务从写出来到被优化后的数据对比。
优化前,cpu增加80%,任务运行半个小时,查询数据库次数百万次,查询出来130万行记录。
优化后,cpu增加1%,任务30秒以内,查询数据库200次,查询出来1万行记录。
写到最后:
通过本次优化让我收获许多,最大的收获是让我深刻明白了,对于编码人员,要时刻考虑资源的消耗。举个不太恰当的栗子,假如每个人在工程里都顺手打印一行无效日志,随着时间的积累整个工程都会到处打印在无效日志。毫不夸张的讲,或许只是因为你多打印了一行log.info日志,在请求量猛增达到一定程度时都会导致机器和应用的不良连锁反应。建议大家在开发的时候在关键点加上关键日志,并且合理利用Debugger,结合ducc进行动态日志调整排查问题。
作者:京东零售广告研发 董舒展
来源:京东零售技术 转载请注明来源