GNER: 生成式实体识别的新 SoTA

作者:dyy
深度学习自然语言处理 分享
论文:Rethinking Negative Instances for Generative Named Entity Recognition
地址:https://arxiv.org/abs/2402.16602
Github:https://github.com/yyDing1/GNER
一句话概括:将负样本融入训练,模型表现远超现有 SoTA
简要介绍
研究背景: 生成式大语言模型,如 ChatGPT,在实体识别方面与监督学习模型相比仍存在差距。为了弥补这一能力的不足,目前的研究主要集中在使用开源大语言模型(例如 LLaMA)对 NER 数据集进行微调。然而,现有的工作往往关注于文本中的实体部分(正样本),而忽视了非实体部分(负样本)的价值。如下图所示,传统的训练方法主要指导模型识别文本中的实体及其相应的类别,却往往忽视了非实体文本的作用。

动机: 在传统的分类范式下(例如 BERT tagging),负样本在训练过程中扮演着重要的角色。受此启发,我们对生成式大语言模型中负样本的影响进行了深入探索。通过实验我们发现负样本的引入可以显著提高模型性能,这一提升主要体现在两个方面:首先,包含实体上下文的负样本有效地促进了模型对实体的识别能力;其次,它们帮助模型更清晰地界定实体边界。然而,负样本的使用同样带来了一系列后处理挑战。为应对这些挑战,我们开发了一种高效的结构化处理方法,该方法可以在 的时间复杂度内有效解决多词缺失等问题,极大提高了系统的准确性和鲁棒性。
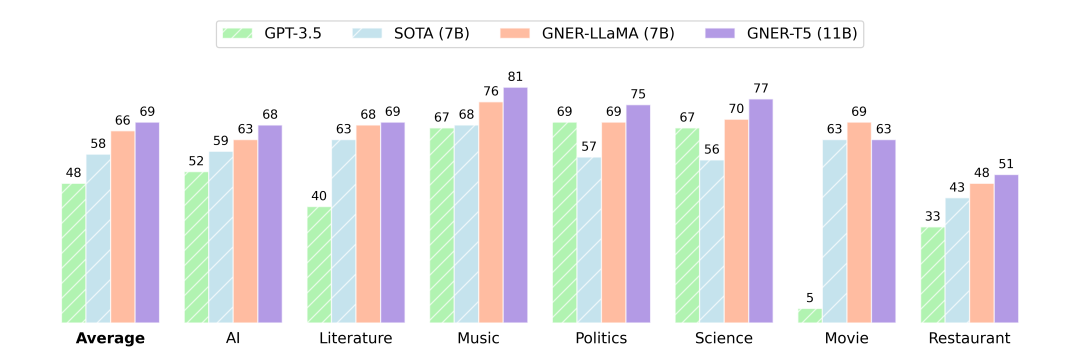
实验结果: 我们对两种代表性的生成式大语言模型,LLaMA 和 Flan-T5,进行了一系列实验。为了更接近现实应用场景,我们的评估重点放在了模型未曾见过的实体类别上。如上图展示的结果,我们开发的 GNER-LLaMA 和 GNER-T5 模型在 分数上分别超过了目前最优模型 8 分和 11 分。我们已经将所有的模型和数据集开源。
负样本的作用
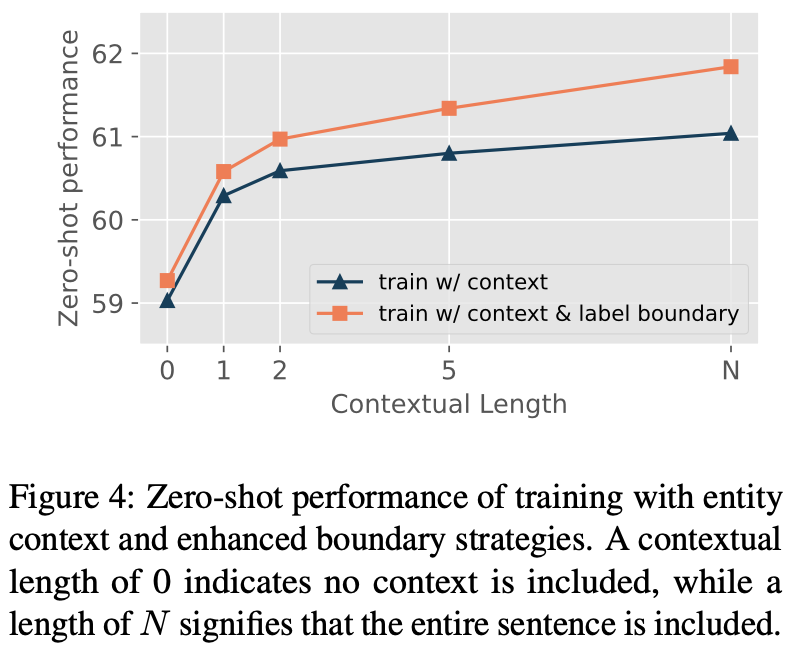
首先我们将实体周围的上下文引入训练,样例如下图所示,对于每个实体,我们引入最靠近实体的 个单词作为训练的负样本,其他的词用省略号代替, 称为上下文长度。

通过不断增大实体的上下文长度,我们发现模型的效果有所提升,并不断接近饱和。同时我们发现,增强实体边界的 prompt 有利于模型对实体边界的判别能力。
但是在引入负样本后,模型预测的长度变长,我们也发现了一些问题,如缺词漏词等问题,为后处理过程提出了新的挑战。

总结来说,我们发现负样本对于模型的表现有很大的提升作用,主要体现在两个方面
非实体文本(即负样本),特别是实体周围的文本,对于促进模型识别实体极为关键。例如,在下面的例子中,“fly to”后面很可能跟随的是一个地名(如“New York”)。将这样的上下文引入训练可以使模型学会这种语义关联,而不仅仅是死记硬背 “New York” 是一个地名。特别是在零样本的情况下,这种语义学习比简单的记忆更为重要。
强化实体的边界定义。关于实体边界模糊的问题已经在现有的研究中被提及。我们通过明确标注非实体部分,并标明实体的确切边界,帮助模型在进行推理时更准确地识别实体的起止,进而提升模型的表现。
结构化方法
为了更好处理上述问题,我们提出了一套结构化方法,核心优化部分在于求序列 A 和序列 B 的最长公共子序列(LCS)上,主要包括两个优化:
算法复杂度 针对上述的 NER 实验结果,我们基于上述实验结果,首先判定 A = B 和 B 作为一个子序列在 A 中出现的情况,判定和匹配过程可以基于贪心算法在 的时间内解决。对于剩下的情况,我们基于实体识别文本中含有较少的重复单词这样一个前提条件,提出一个 复杂度的算法。首先将 LCS 问题转化为 LIS 问题,然后构建一个有向无环图来解决。具体的实现的步骤可见论文和 GitHub 仓库,这里不做赘述。
匹配条件 通过 Case Study 我们发现,相当一部分问题可以归因于模型的词表确实状况导致的生成词与原序列不匹配,我们设计了 back tokenization 的方法来优化 LCS 算法中的匹配条件。
实验结果
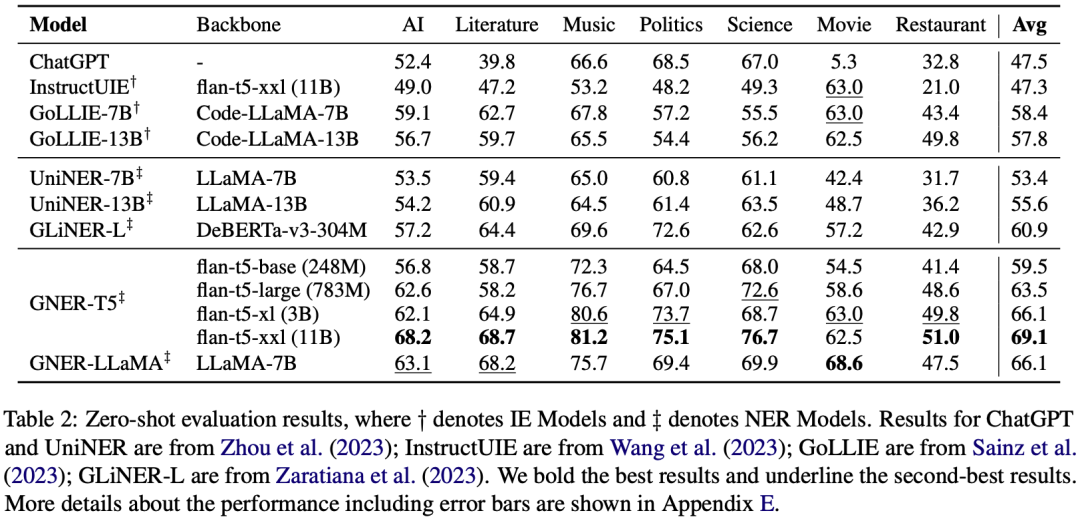
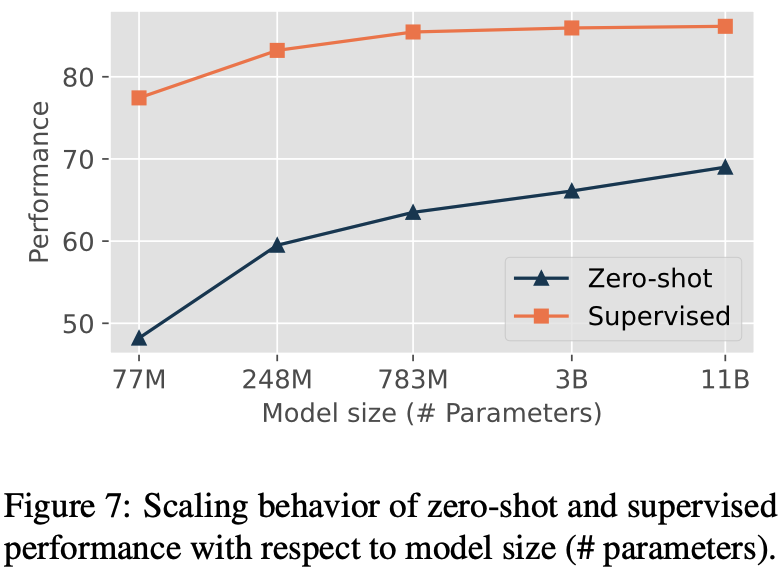
我们的实验重点在于零样本评估(zero-shot evaluation),即模型在训练过程中没见过的实体类别上的表现,具体结果如下图所示,模型在 7 个数据集上都实现了稳定的提升,并且平均效果远超现有的 SoTA 结果。并且 783M 参数量的 GNER-T5 模型就足以打败列出的所有的 baseline 模型。
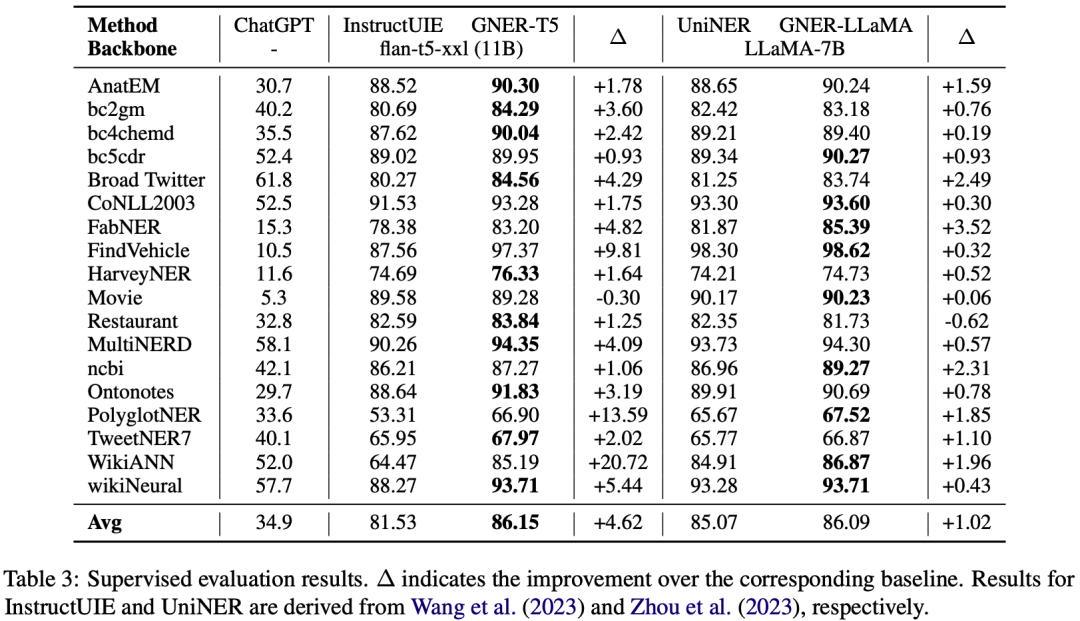
模型在监督设置下同样取得了稳定的提升,结果如下:
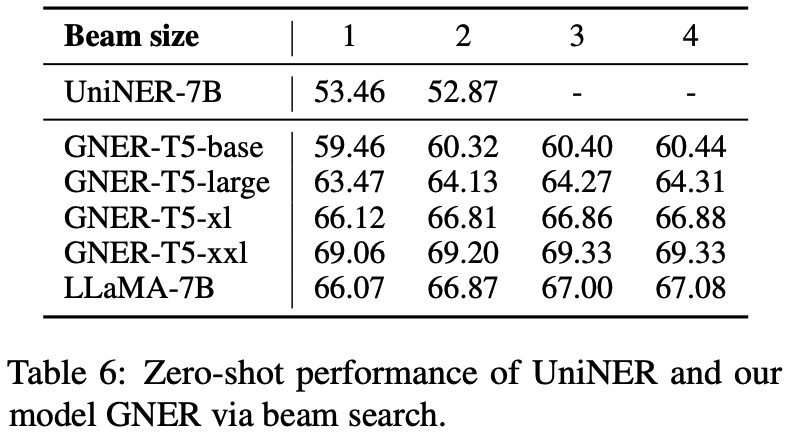
我们也探究了生成式 NER 模型的 scaling law,发现即使在较小模型上,我们的方法也展现了卓越的性能,特别是基于 Flan-T5-large 的模型,在两种设置下均已超越了所有 baseline 模型。此外,随着模型参数量的增加,在零样本设置下,模型的性能仍然很大的提升潜力。并且,beam search 带来的自我修正机制(self-correction mechanism)有助于继续增强模型的性能。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦