MySQL——性能调优
性能调优(重要)
SQL 优化的目的
- 减少磁盘 IO:尽可能避免全表扫描、尽量使用索引、尽量使用覆盖索引减少回表操作
- 减少 CPU 和内存的消耗,尽可能减少排序、分组、去重之类的操作,尽量减少事务持有锁的时间
优化途径:找到 慢 SQL 语句 -> explain 分析 SQL,针对性优化 SQL
找到慢 SQL
使用慢查询日志,会帮我们记录耗时超过 n 秒的 SQL 语句,可以通过这个慢查询日志,发现慢 SQL
# 怎么发现慢SQL
show variables like '%slow_query_logs';# 开启慢SQL日志命令
set global show_query_log='ON';# 设置慢查询门限时间,如2s
set global long_query_time=2;# 也可以修改my.cnf文件,设置参数,然后重启MySQLexplain 的使用
找到慢 SQL 的语句后,explain 进行分析
explain select * from test
重点关注的列
type
执行效率由低到高
- ALL(全表扫描):性能最差,需要避免,上面的例子就用到了全表扫描
- index(全索引扫描):对二级索引进行全扫描,性能跟全表扫描差不多
- range
- ref
- eq_ref
- const
key:
表示实际用到的索引,如果为 NULL,则表示没用到索引。这种情况需要注意!
extra:记录一些额外的信息
- Using filesort:表示 SQL 需要进行额外的步骤来对返回的结构进行排序。它会根据连接类型、存储排序键值和匹配条件的全部行记录进行排序
- Using tempory:表示 MySQL 需要创建一个临时表来存储结构,非常消耗性能
rows
表明 SQL 返回请求数据的行数
如何设计索引
一张表中只有主键的默认添加索引的,还可以针对其他列建立索引来提高查询性能
通常情况下:
- 频繁出现在 WHERE 中的列
- 通常出现在 ORDER BY 中的列,这样查询的时候就不需要再进行一次排序了,因为建立在索引之后再 B+树中的记录都是按顺序排好的
- 区分度很高的列,如我们在联合查询的时候,经常用用户名 + 其他一起查询,那么可以给用户名建立索引,因为用户名唯一,但是不能给性别建立索引,因为区分度不高,建索引没意义
注:建联合索引目的是减少回表
减少锁持有时间
案例 1 改语句顺序
执行 update 语句的时候,会对记录加行级锁,这个锁是在事务提交之后才会释放。
如果 update 和 select 语句之间没有什么依赖关系,那么应该把加锁的语句,放在事务靠后的位置,减少加锁的时间,这样能提高整体的并发性能

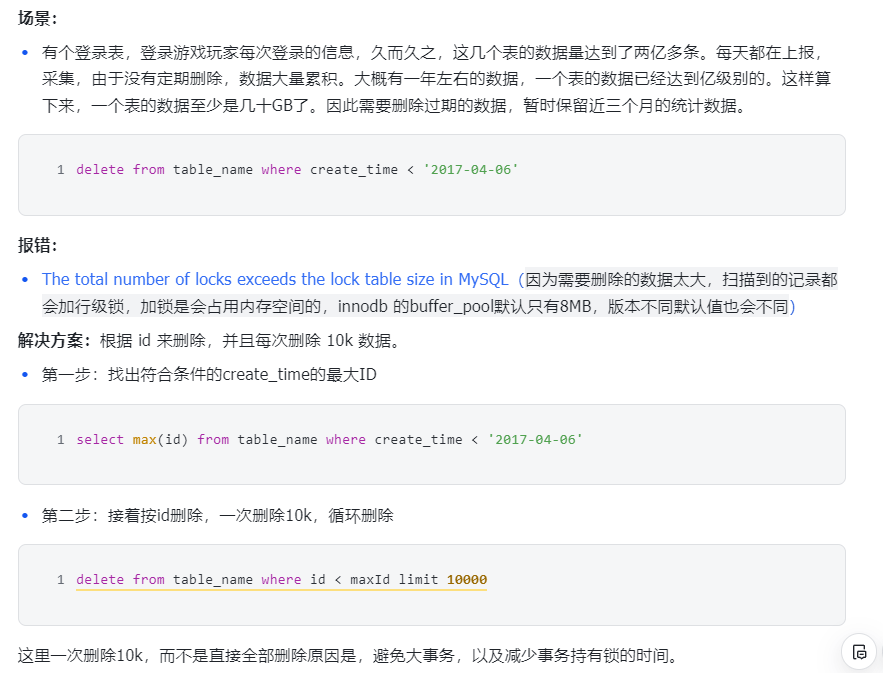
案例 2 分批删除
删除大量数据表数据的时候,最好采用分批删除的方式,如果直接执行删除操作 ,那么delete 语句产生的行锁,要在所有数据删除完之后,才会释放锁,锁持有的时间会很长,会影响其他事务的操作。改进方式,采用 limit 的方式来分批删除,比如每次取 1000 条记录进行删除,这也可以减少锁持有的时间。
其他
1、 避免索引失效
索引失效的七个场景:模型数空运最快
模糊查询、数据类型不匹配、函数、空值、运算、最左前缀匹配、全表更快
2、设计表的时候要做一定的反范式设计,建表的时候考虑增加冗余字段,尽可能保持单表查询,而非多表 JOIN
总结
如何优化慢 SQL?
- 优化数据访问:使用 select + limit 避免使用 select * ,减少非必要的数据返回
- 切分查询,针对一个大查询拆分成多个小查询,每个小查询只返回一部分数据,比如,批量删除 1000 万条数据,可以改成分批查询,一次删除 1000 条。
- 覆盖索引:如果没有索引,就考虑建立普通索引或覆盖索引,通过覆盖索引的查询,避免回表
- 避免索引失效
- 减少连表查询
- 优化排序
如果 SQL 和索引都没问题,查询还是很慢怎么办?
分析:往系统架构方向上思考
- 分批查询:针对一个大查询,拆分成多个小查询,每个查询只返回一部分数据
- 增加缓存,针对频繁查询的热点数据,我们可以方法 redis 中
- 分表:如果表中的数据量很大了,比如表达到千万级别了,这时就可以考虑分表了,通过减少每次查询数据总量来解决数据查询缓慢的问题。
- 主从复制:针对读多写少的情况,我们可以搭建 MySQL 主从模式来分摊请求的数量
- 分库:针对写多读少的情况,单库的性能无法抗住高并发流量,就要进行分库,把请求分摊到多个实例中去