Fastwhisper + Pyannote 实现 ASR + 说话者识别
文章目录
- 前言
- 一、faster-whisper简单介绍
- 二、pyannote.audio介绍
- 三、faster-whisper + pyannote.audio 实现语者识别
- 四、多说几句
前言
最近在研究ASR相关的业务,也是调研了不少模型,踩了不少坑,ASR这块,目前中文普通话效果最好的应该是阿里的modelscope上的中文模型了,英文的话,还是非whisper莫属了,而且whisper很变态,粤语效果也还不错,因此,如果实际业务中需要涉及到不同的语言,还是更推荐whisper多一点
一、faster-whisper简单介绍
faster-whisper是使用CTranslate2对OpenAI的Whisper模型的重新实现,CTranslate2是一个用于Transformer模型的快速推理引擎。
在使用更少内存的情况下,该实现比openai/whisper在相同精度下快4倍。同时在CPU和GPU上进行8位量化,可以进一步提高算法效率。
官方仓库:https://github.com/SYSTRAN/faster-whisper
二、pyannote.audio介绍
pyannote.audio是一个用Python编写的用于扬声器diarization的开源工具包。基于PyTorch机器学习框架,它具有最先进的预训练模型和管道,可以进一步对自己的数据进行微调,以获得更好的性能。
官方仓库:https://github.com/pyannote/pyannote-audio
三、faster-whisper + pyannote.audio 实现语者识别
实际上只要将二者的识别结果进行结合即可
from pyannote.core import Segmentdef get_text_with_timestamp(transcribe_res):timestamp_texts = []for item in transcribe_res:start = item.startend = item.endtext = item.text.strip()timestamp_texts.append((Segment(start, end), text))return timestamp_textsdef add_speaker_info_to_text(timestamp_texts, ann):spk_text = []for seg, text in timestamp_texts:spk = ann.crop(seg).argmax()spk_text.append((seg, spk, text))return spk_textdef merge_cache(text_cache):sentence = ''.join([item[-1] for item in text_cache])spk = text_cache[0][1]start = round(text_cache[0][0].start, 1)end = round(text_cache[-1][0].end, 1)return Segment(start, end), spk, sentencePUNC_SENT_END = [',', '.', '?', '!', ",", "。", "?", "!"]def merge_sentence(spk_text):merged_spk_text = []pre_spk = Nonetext_cache = []for seg, spk, text in spk_text:if spk != pre_spk and pre_spk is not None and len(text_cache) > 0:merged_spk_text.append(merge_cache(text_cache))text_cache = [(seg, spk, text)]pre_spk = spkelif text and len(text) > 0 and text[-1] in PUNC_SENT_END:text_cache.append((seg, spk, text))merged_spk_text.append(merge_cache(text_cache))text_cache = []pre_spk = spkelse:text_cache.append((seg, spk, text))pre_spk = spkif len(text_cache) > 0:merged_spk_text.append(merge_cache(text_cache))return merged_spk_textdef diarize_text(transcribe_res, diarization_result):timestamp_texts = get_text_with_timestamp(transcribe_res)spk_text = add_speaker_info_to_text(timestamp_texts, diarization_result)res_processed = merge_sentence(spk_text)return res_processeddef write_to_txt(spk_sent, file):with open(file, 'w') as fp:for seg, spk, sentence in spk_sent:line = f'{seg.start:.2f} {seg.end:.2f} {spk} {sentence}\n'fp.write(line)import torch
import whisper
import numpy as np
from pydub import AudioSegment
from loguru import logger
from faster_whisper import WhisperModel
from pyannote.audio import Pipeline
from pyannote.audio import Audiofrom common.error import ErrorCodemodel_path = config["asr"]["faster-whisper-large-v3"]# 测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_speaker_demo.wav
audio = "./test/asr/data/asr_speaker_demo.wav"
asr_model = WhisperModel(model_path, device="cuda", compute_type="float16")
spk_rec_pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token="your huggingface token")
spk_rec_pipeline.to(torch.device("cuda"))asr_result, info = asr_model.transcribe(audio, language="zh", beam_size=5)
diarization_result = spk_rec_pipeline(audio)final_result = diarize_text(asr_result, diarization_result)
for segment, spk, sent in final_result:print("[%.2fs -> %.2fs] %s %s" % (segment.start, segment.end, sent, spk))结果
[0.00s -> 9.80s] 非常高兴能够和几位的话一起来讨论互联网企业如何决胜全球化新高地这个话题 SPEAKER_01
[9.80s -> 20.20s] 然后第二块其实是游戏平台所谓游戏平台它主要是简单来说就是一个商店家社区的这样一个模式而这么多年 SPEAKER_03
[20.20s -> 35.70s] 我们随着整个业务的拓张会发现跟阿里云有非常紧密的联系因为刚开始伟光在介绍的时候也讲阿里云也是阿里巴巴的云所以这个过程中一会儿也可以稍微展开跟大家讲一下我们跟云是怎么一路走来的 SPEAKER_04
[35.70s -> 62.40s] 其实的确的话就对我们互联网公司来说如果不能够问当地的人口的话我想我们可能整个的就失去了后边所有的动力不知道你们各位怎么看就是我们最大的这个问题是不是效率优先Yes or No然后如果是讲一个最关键的你们是怎么来克服这一些挑战的 SPEAKER_01
[62.40s -> 90.50s] 因为其实我们最近一直在做海外业务所以说我们碰到了一些问题可以一起分享出来给大家其实一起探讨一下其实海外我们还是这个观点说是无论你准备工作做得有多充分无论你有学习能力有多强你一个中国企业的负责人其实在出海的时候它整体还是一个强势的是做的过程 SPEAKER_03
[90.50s -> 101.60s] 后来推到德国或者推到新加坡 印尼 越南等等这些地方每一个地方走过去都面临的一个问题是建站的效率怎么样能够快速地把这个站点建起来 SPEAKER_04
[101.60s -> 122.90s] 一方面我们当初刚好从2014年刚好开始要出去的时候国内就是三个北上广深但在海外要同时开服北美 美东 美西 欧洲 日本我还记得那个时候我们在海外如何去建立这种IDC的康碳建设基础设施建设云服务的部署那都是一个全新的挑战 SPEAKER_02
四、多说几句
pyannote的模型都是从huggingface上下载下来的,所以没有magic直接运行上面代码可能会报443,自己想办法搞定网络问题。
地址:https://huggingface.co/pyannote/speaker-diarization-3.1
以上代码即使你运行的时候把模型下载到缓存里了,偶尔还是会443,笔者猜测这玩意就算你下载下来了还是还是要联网推理,所以,要部署到生产环境的同学最好还是使用离线加载。
pyannote离线加载模型的方式和之前NLP的模型不一样,首先你需要配置的是config.yaml的路径,请看:
spk_rec_pipeline = Pipeline.from_pretrained("./data/models/speaker-diarization-3.1/config.yaml")
只下载这一个模型是不行的哦,这个只是个config文件,你还要下载另外两个模型:
https://huggingface.co/pyannote/wespeaker-voxceleb-resnet34-LM
https://huggingface.co/pyannote/segmentation-3.0
最后再修改下config.yaml里的模型路径,参考我的:
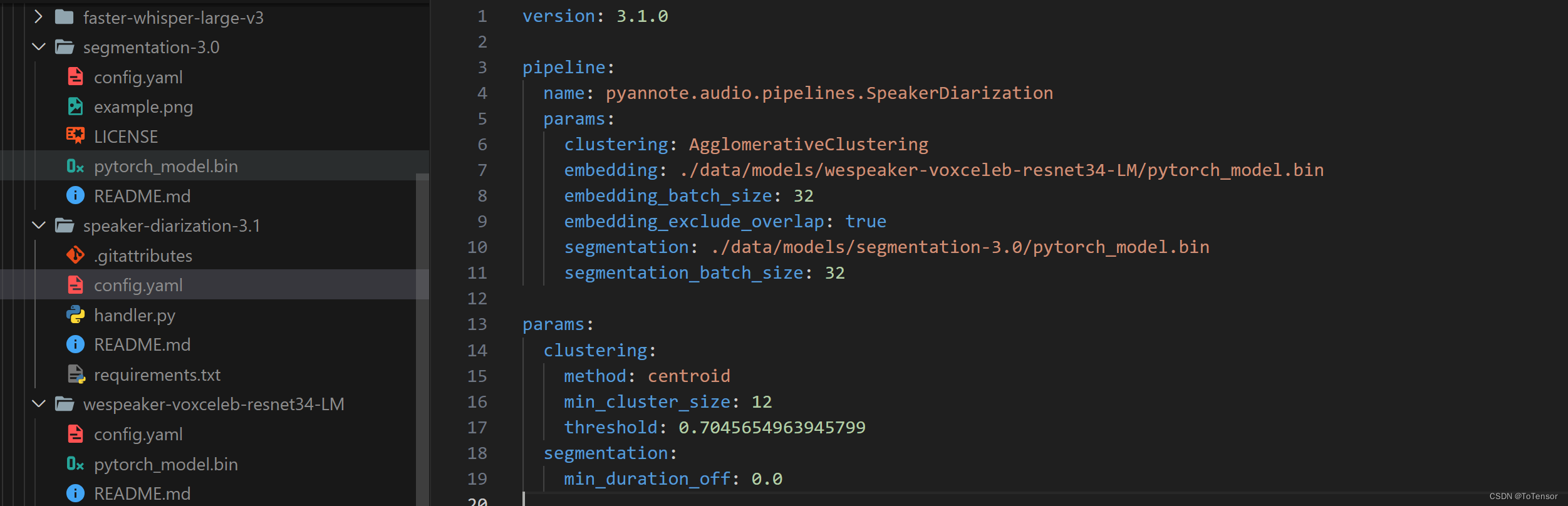
当这些都搞好后,你是不是以为完了?
正常来说应该不会有什么问题,但是我在服务器上碰到了如下问题:

而且官方也有相关的issue:https://github.com/pyannote/pyannote-audio/issues/1599
我试了,在我服务器上是没用的
有些人说是onnx模型有问题,比如说模型下载出了问题,我重新下载了好几遍,都无法解决,所以如果真的是模型的问题,那应该就是pyannote官方push的模型有问题。还有说是Protobuf的问题的,我认为应该不是,最后我也没找出问题在哪,所以最后我不用pyannote了
但神奇的是,用Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token="your huggingface token")直接从缓存里加载模型就没问题,只是偶尔报443。
最后,祝大家好运。pyannote不行,完全可以用其他模型替代的,笔者推荐去modelscope上看看。
2024/03/04更新
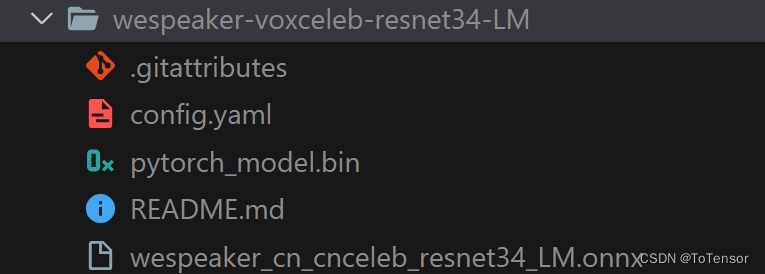
离线加载的Protobuf问题已找到原因:确实是官方提供的模型有问题,官方仓库提供的是pytorch模型,非onnx模型,从报错也可以看的出来,我找了半天也没找到onnx模型在哪里,应该可以自己从pytorch模型转到onnx模型,还有个办法是大家可以从https://modelscope.cn/models/manyeyes/speaker_recognition_task_models_onnx_collection/files下载,下载wespeaker开头的onnx模型就可以了,然后放到wespeaker-voxceleb-resnet34-LM目录下,如图:
然后再修改speaker-diarization-3.1下的config.yaml文件:
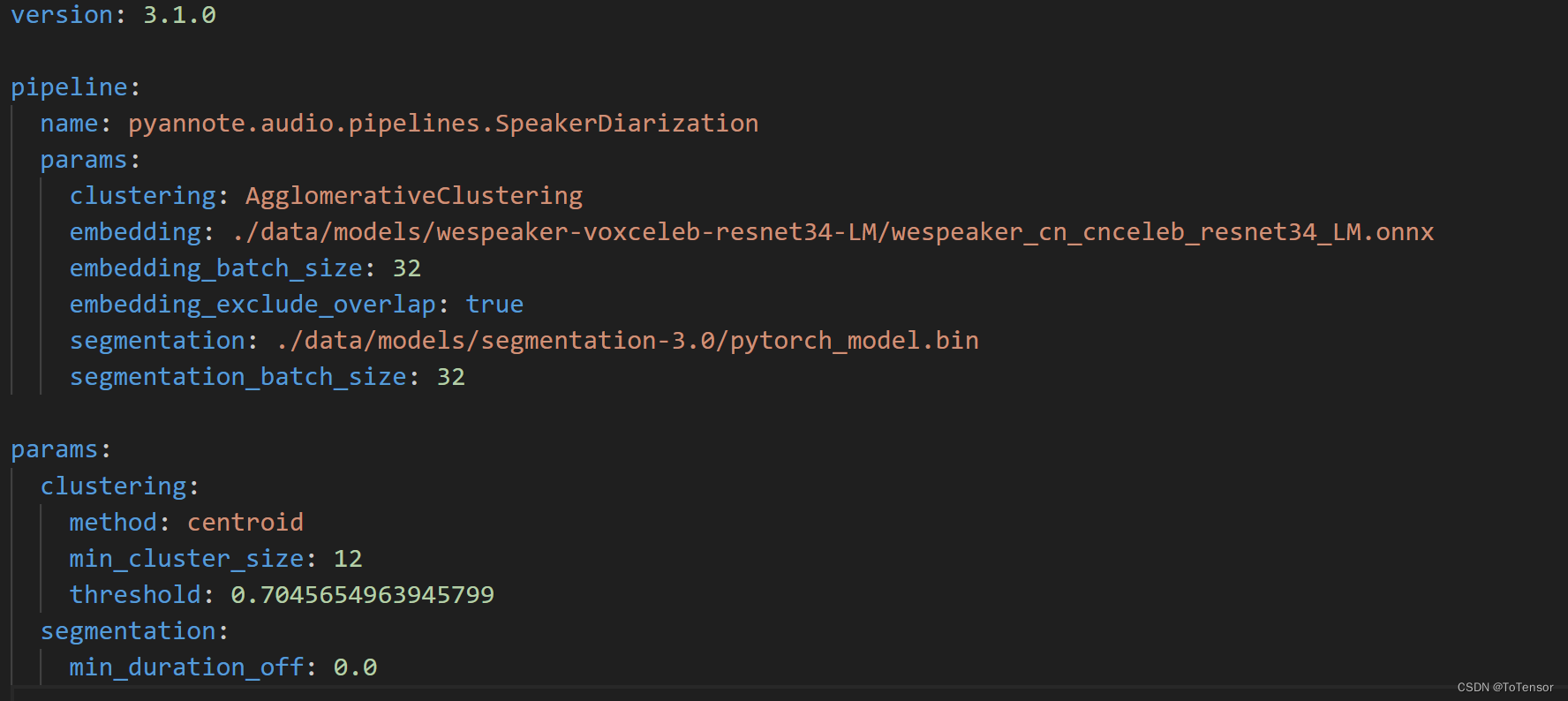
至此,大功告成啦!这都不点赞收藏实在没良心!!!
另外,实际上我发现用whisperx来实现,更方便,但推理速度慢一点。