python使用multiprocessing
multiprocessing
multiprocessing是Python标准库中的一个模块,用于实现多进程编程。它提供了一种简单而高效的方式来利用多核处理器的能力,通过在多个进程中同时执行任务,加快程序的执行速度和提高系统的吞吐量。
下面是使用multiprocessing模块的一些常见操作:
- 创建进程:
- 使用Process类创建进程对象,指定要执行的函数或方法。
- 使用Process类的start()方法启动进程。
- 进程间通信:
- 使用Queue类实现进程间的队列通信。
- 使用Pipe类实现进程间的管道通信。
- 使用共享内存(Value和Array)实现进程间的数据共享。
- 进程管理:
- 使用Process类的join()方法等待进程结束。
- 使用Process类的terminate()方法终止进程。
process
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
参数介绍:
- group默认为None(目前未使用)
- target代表调用对象,即子进程执行的任务
- name为进程名称
- args调用对象的位置参数元组,args=(value1, value2, …)
- kwargs调用对象的字典,kwargs={key1:value1, key2:value2, …}
- daemon表示进程是否为守护进程,布尔值
方法介绍:
- Process.start() 启动进程,并调用子进程中的run()方法
- Process.run() 进程启动时运行的方法,在自定义时必须要实现该方法
- Process.terminate() 强制终止进程,不进行清理操作,如果Process创建了子进程,会导致该进程变成僵尸进程
- Process.join() 阻塞进程使主进程等待该进程终止
- Process.kill() 与terminate()相同
- Process.is_alive() 判断进程是否还存活,如果存活,返回True
- Process.close() 关闭进程对象,并清理资源,如果进程仍在运行则返回错误
multiprocessing.Queue()
multiprocessing.Queue()是multiprocessing模块中的一个类,用于实现进程间通信的队列(Queue)。它提供了一种安全的方式,让多个进程之间可以共享数据。multiprocessing.Queue()类的主要特点包括:
-
安全性:multiprocessing.Queue()是线程安全的,可以在多个进程中同时使用,而无需担心数据竞争或不一致性问题。
-
先进先出(FIFO):它遵循先进先出的原则,保证了添加到队列中的元素按照添加的顺序被取出。
-
阻塞操作:当队列为空时,使用get()方法从队列中获取元素会阻塞进程,直到队列中有可用的元素。当队列满时,使用put()方法向队列中添加元素会阻塞进程,直到队列有空闲空间。
import multiprocessingdef worker(queue):data = queue.get() # 从队列中获取数据# 处理数据if __name__ == '__main__':queue = multiprocessing.Queue()process = multiprocessing.Process(target=worker, args=(queue,))process.start()queue.put(data) # 向队列中添加数据process.join()
在上面的示例中,首先创建了一个multiprocessing.Queue()对象,然后将该队列对象作为参数传递给子进程的worker()函数。在子进程中,使用get()方法从队列中获取数据进行处理。在主进程中,使用put()方法向队列中添加数据。通过使用multiprocessing.Queue(),可以让多个进程之间安全地传递数据,实现进程间的通信和协作。这对于并行计算、任务分发和处理等场景非常有用。
拿之前的点点带宽举例
七个节点不重复取两个,C72也就是21组,即21次循环,每次循环sleep5秒,串行就是21x5=105秒,21个线程并行5秒。
import multiprocessing
import time
import randomdef get_oobw_parallel(node_names):results = []for i in range(0, len(node_names) - 1):for j in range(i + 1, len(node_names)):result = get_oobw(node_names[i], node_names[j])results.append(result)return resultsdef get_oobw(node_name1, node_name2):# 执行 get_oobw 的逻辑# ...time.sleep(5)latency, bandwidth = round(random.uniform(100.0, 200.0), 4), round(random.uniform(100.0, 200.0), 4)result = (node_name1, node_name2, latency, bandwidth)return resultstart_time = time.time()node_names = ["cn1", "cn2", "cn3", "cn4", "cn5", "cn6", "cn7"] # 填入你的节点名称列表results = get_oobw_parallel(node_names)for result in results:node_name1, node_name2, latency, bandwidth = resultprint(node_name1, node_name2, latency, bandwidth)end_time = time.time()
# 计算执行时间
execution_time = end_time - start_time
print("程序执行时间:", execution_time, "秒")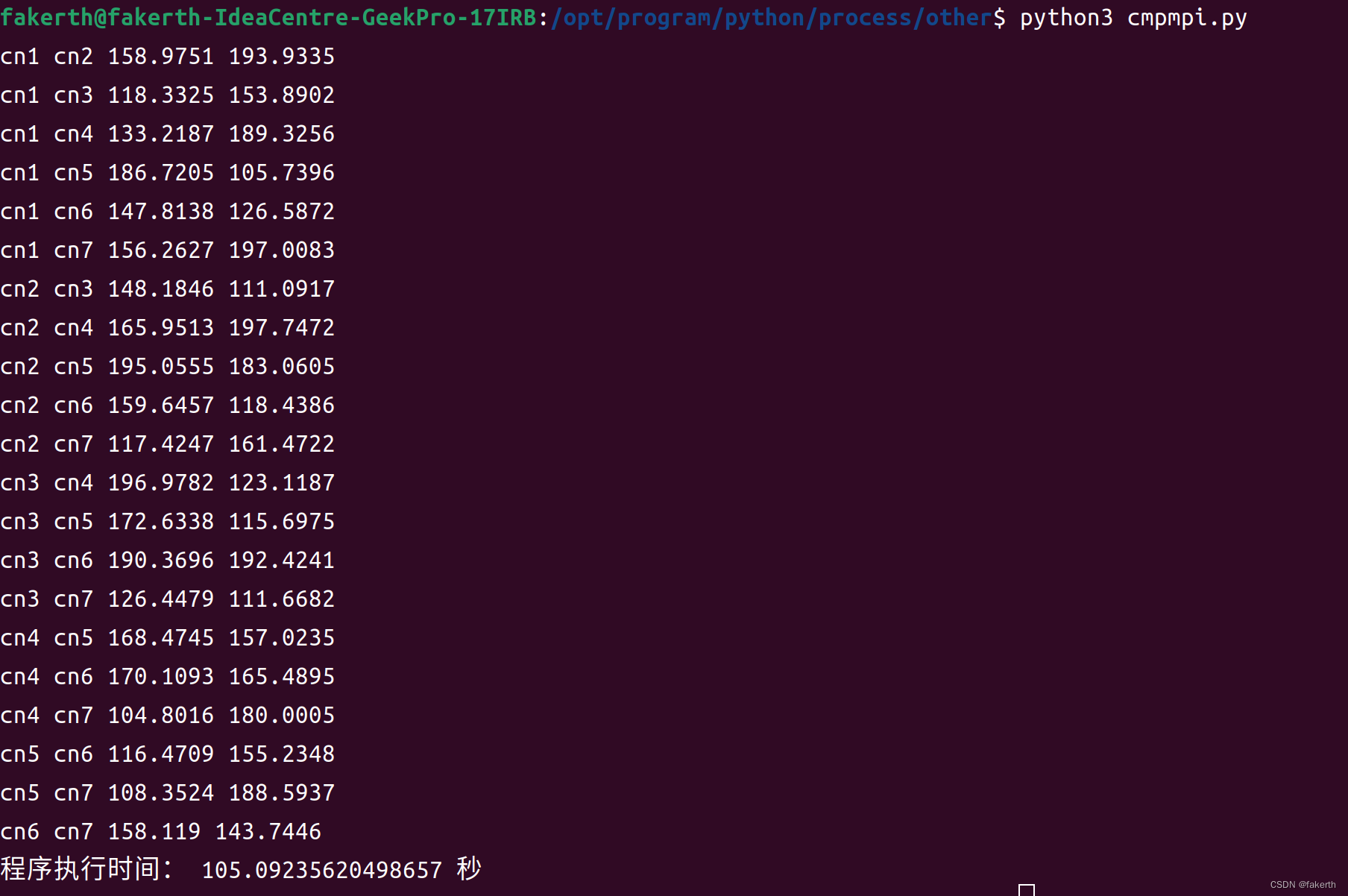
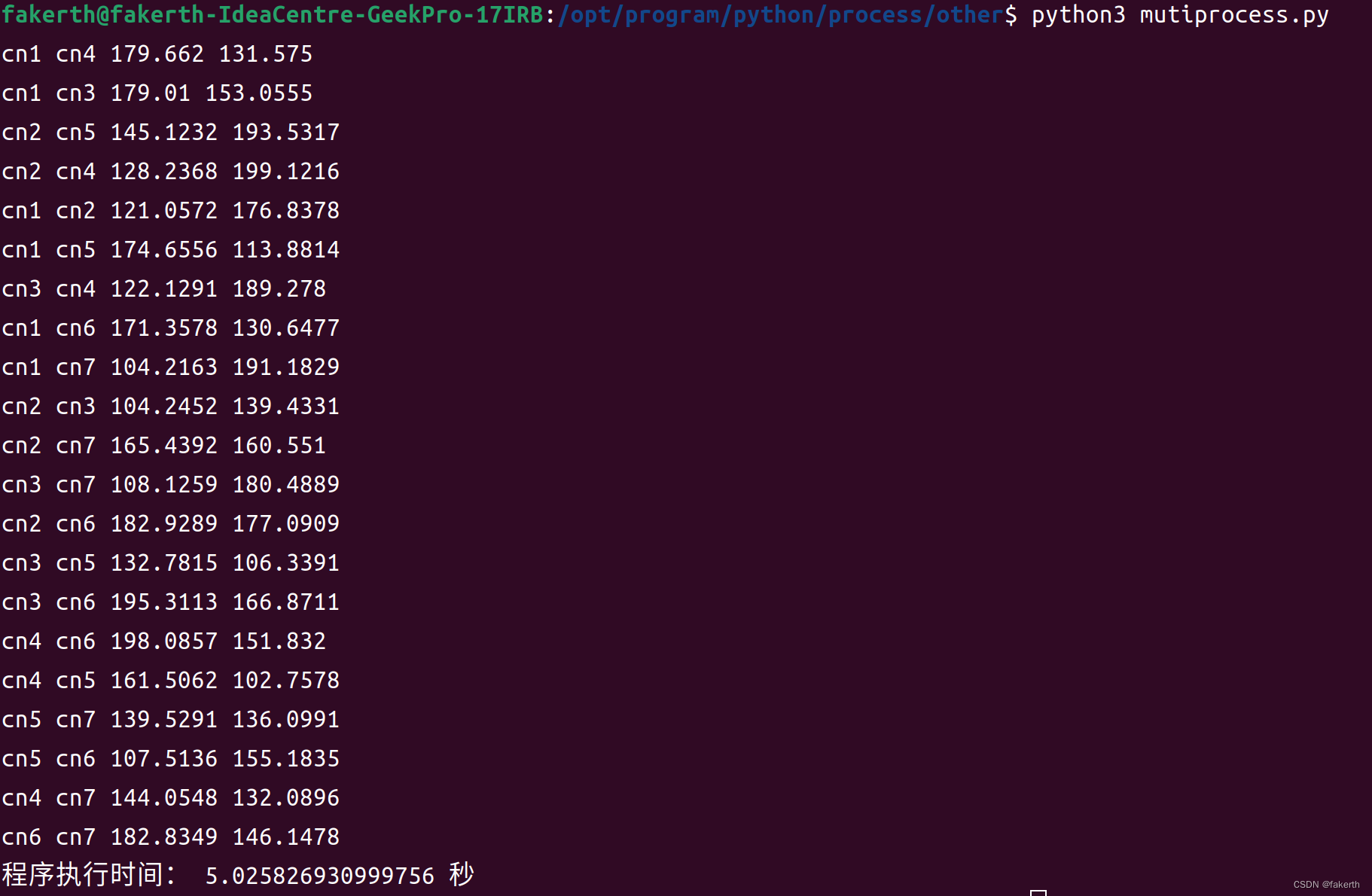
import multiprocessing
import time
import randomdef get_oobw_parallel(node_names):results = []processes = []result_queue = multiprocessing.Queue()for i in range(0, len(node_names) - 1):for j in range(i + 1, len(node_names)):process = multiprocessing.Process(target=get_oobw, args=(node_names[i], node_names[j], result_queue))process.start()processes.append(process)for process in processes:process.join()while not result_queue.empty():result = result_queue.get()results.append(result)return resultsdef get_oobw(node_name1, node_name2, result_queue):# 执行 get_oobw 的逻辑# ...time.sleep(5)latency, bandwidth = round(random.uniform(100.0, 200.0), 4), round(random.uniform(100.0, 200.0), 4)result = (node_name1, node_name2, latency, bandwidth)result_queue.put(result)# return latency, bandwidthstart_time = time.time()node_names = ["cn1", "cn2", "cn3", "cn4", "cn5", "cn6", "cn7"] # 填入你的节点名称列表results = get_oobw_parallel(node_names)for result in results:node_name1, node_name2, latency, bandwidth = resultprint(node_name1, node_name2, latency, bandwidth)end_time = time.time()
# 计算执行时间
execution_time = end_time - start_time
print("程序执行时间:", execution_time, "秒")