Tomcat的部署及调优,jvm调优

一,tomcat相关知识
1.1,tomcat介绍
tomcat是一个开源的Web应用服务器,属于轻量级应用服务器,由Apache软件基金会维护,是Jakarta项目中的一个核心项目。它由Apache、Sun和其他一些公司及个人共同开发,由于Sun的支持,Tomcat能够体现最新的Servlet和JSP规范。Tomcat因其技术先进、性能稳定且免费,受到Java爱好者的喜爱,并被部分软件开发商认可,成为流行的Web应用服务器。
Tomcat服务器支持Servlet和JSP规范,允许用户运行Java Web应用程序。它能够接收和解析来自客户端的请求,并将这些请求转发给相应的Servlet或JSP文件,处理客户端的响应。Tomcat作为一个Servlet容器,负责创建ServletRequest和ServletResponse对象,并调用请求的Servlet或JSP文件的服务方法,将请求参数传递给这些方法。
Tomcat可以独立运行,不依赖于Apache服务器,但通常与Apache结合使用。Apache服务器负责响应HTML页面请求,而Tomcat则处理JSP页面和Servlet,提供动态内容。Tomcat还支持静态HTML内容,尽管它在处理静态HTML方面不如Apache服务器。
Tomcat是完全用Java编写的,可以在多种操作系统上运行,包括Windows、Linux和macOS。它的官方网站提供了下载和文档,用户可以根据需要选择合适的版本进行安装和使用。目前,Tomcat的最新版本是8.0。
1.2,tomcat的组件构成

web容器:完成web服务器的功能。
servlet容器:名字为catalina,用于处理servlet代码。
jsp容器:用于将jsp动态网页翻译成servlet代码
1.3,tomcat的功能组件结构
Tomcat 的核心功能有两个,分别是负责接收和反馈外部请求的连接器 Connector,和负责处理请求的容器 Container。 其中连接器和容器相辅相成,一起构成了基本的 web 服务 Service。每个 Tomcat 服务器可以管理多个 Service。
Connector:负责对外接收和响应请求。它是Tomcat与外界的交通枢纽,监听端口接收外界请求,并将请求处理后传递给容器做业务处理,最后将容器处理后的结果响应给外界。
Container:负责对内处理业务逻辑。其内部由 Engine、Host、Context和Wrapper 四个容器组成,用于管理和调用 Servlet 相关逻辑。
Service:对外提供的 Web 服务。主要包含 Connector 和 Container 两个核心组件,以及其他功能组件。Tomcat 可以管理多个 Service,且各 Service 之间相互独立。
1.4,tomcat的请求过程
1,连接器(connector)接受请求:负责接收输入的tcp连接请求,并创建一个request和response对象用于交互。
2,容器(container)处理请求:tomcat中的容器由Engine、Host、Context和Wrapper组成,用于处理请求并返回响应。
3,容器处理如何请求:
-
请求首先发送到Engine级别,进行交叉匹配。
-
如果没有匹配,请求将 bubble(冒泡)到上一级 Host,再次进行匹配。
-
如果仍然没有匹配,请求继续在 Context 级别进行匹配,这里通常对应具体的应用。
-
最后,如果仍然没有匹配的Wrapper,Tomcat将返回404错误。
4,响应:一旦容器确定了处理这个请求的Wrapper,请求就会被传递给对应的Servlet来处理。Servlet处理完请求后,将响应返回给容器。
5,响应返回给连接器:最后容器将Servlet处理的响应返回给Connector,并通过Socket发送回客户端。
以下是一个简化的Tomcat请求处理过程的伪代码示例:
// 1. 连接器接收请求
Socket socket = acceptConnection(); // 接收TCP连接
Request request = parseRequest(socket); // 解析请求
Response response = new Response(); // 创建响应对象// 2. 容器处理请求
Engine engine = getEngine();
engine.process(request, response);// 代码函数process的一个简化版本
void Engine::process(Request request, Response response) {// 匹配请求到适当的HostHost host = this.findHost(request);host.process(request, response);// ... 其他容器处理逻辑
}// Servlet处理请求
if (servletFound) {servlet.service(request, response);
} else {response.sendError(404); // 发送404错误
}// 3. 响应返回给连接器
sendResponse(socket, response); // 将响应发送回客户端二,tomcat服务部署
参考博客:csdn:xiaoyaoxiangnila 第七点 jdk及tomcat的安装
三,tomcat的优化

1、增加 Tomcat 的内存分配:可以通过调整 Tomcat 的启动脚本来增加其分配的内存,比如在 catalina.sh 或 catalina.bat 中设置环境变量 CATALINA_OPTS 为 -Xms512m -Xmx1024m,其中 -Xms 表示 Tomcat 启动时分配的最小内存, -Xmx 表示 Tomcat 允许使用的最大内存。

2、调整 Tomcat 的线程池设置:Tomcat 默认使用的线程池是 org.apache.tomcat.util.threads.ThreadPoolExecutor,可以通过修改 server.xml 中的 Connector 节点下的 maxThreads、minSpareThreads 和 acceptCount 参数来调整线程池的大小和性能。

3、优化 Tomcat 的缓存设置:可以通过调整 server.xml 中的 Connector 节点下的 enableLookups、maxKeepAliveRequests 和 keepAliveTimeout 等参数来优化 Tomcat 的缓存设置,减少网络连接的开销。

4、启用压缩:可以在 server.xml 中的 Connector 节点下启用压缩来减少网络传输的数据量,提高网站的响应速度,比如设置 compression 参数为 on、compressionMinSize 参数为 2048 等。
5、启用静态资源缓存:可以通过在 web.xml 中配置 filter,启用静态资源缓存,减少服务器的负载,提高访问速度。

6、使用 CDN 加速静态资源:可以使用 CDN(内容分发网络)来加速静态资源的传输,减少服务器的负载,提高网站的访问速度。
7、避免使用过多的 Session:可以在编写 Web 应用程序时避免过多地使用 Session,因为 Session 会占用服务器的内存资源,从而影响 Tomcat 的性能。


8、避免过多的 JDBC 操作:可以在编写 Web JDBC 操作数据库,因为数据库的访问是非常耗时的,从而影响 Tomcat 的性能。




优化这一部分仅供参考。
四,Tomcat性能调优
找到Tomcat根目录下的conf目录,修改server.xml文件的内容。对于这部分的调优,我所了解到的就是无非设置一下Tomcat服务器的最大并发数和Tomcat初始化时创建的线程数的设置,当然还有其他一些性能调优的设置,下图是我根据我机子的性能设置的一些参数值,给各位详细解释一下吧:

1、URIEncoding=“UTF-8”:设置Tomcat的字符集。这种配置我们一般是不会设置的,因为关于乱码的转换我们会在具体项目中具体处理,直接修改Tomcat的字符集未免过于太死板。
2、maxThreads=“300”:设置当前Tomcat的最大并发数。Tomcat默认配置的最大请求数是150个,即同时能支持150个并发。但是在实际运用中,最大并发数与硬件性能和CPU数量都有很大关系的,更好的硬件、更高的处理器都会使Tomcat支持更多的并发数。如果一般在实际开发中,当某个应用拥有 250 个以上并发的时候,都会考虑到应用服务器的集群。
3、minSpareThreads=“50”:设置当前Tomcat初始化时创建的线程数,默认值为25。
4、acceptCount=“250”:当同时连接的人数达到maxThreads参数设置的值时,还可以接收排队的连接数量,超过这个连接的则直接返回拒绝连接。指定当任何能够使用的处理请求的线程数都被使用时,能够放到处理队列中的请求数,超过这个数的请求将不予处理。默认值为100。在实际应用中,如果想加大Tomcat的并发数 ,应该同时加大acceptCount和maxThreads的值。整编:微信公众号,搜云库技术团队,ID:souyunku
5、enableLookups=“false”:是否开启域名反查,一般设置为false来提高处理能力,它的取值还有true,一般很少使用。
6、maxKeepAliveRequests=“1”:nginx动态的转给tomcat,nginx是不能keepalive的,而tomcat端默认开启了keepalive,会等待keepalive的timeout,默认不设置就是使用connectionTimeout。所以必须设置tomcat的超时时间,并关闭tomcat的keepalive。否则会产生大量tomcat的socket timewait。maxKeepAliveRequests=”1”就可以避免tomcat产生大量的TIME_WAIT连接,从而从一定程度上避免tomcat假死。
1,调整tomcat线程池
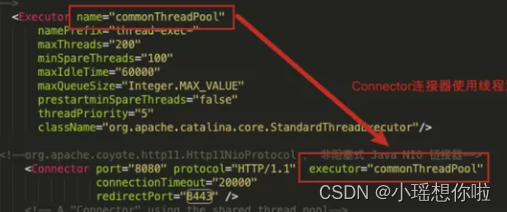
2,调整tomcat的连接器
调整tomcat/conf/server.xml 中关于链接器的配置可以提升应用服务器的性能。
参数及其说明:
maxconnetions:最大连接数,当到达该值后,服务器接收但不会处理更多的请求,额外的请求将会阻塞直到连接数低于maxconnections。可以通过ulimit - a查看服务器限制,对于cpu要求更高时,建议不用配置过大,对于cpu要求时,建议配置在2000左右,当然这个需要服务器硬件的支持。
maxthreads:最大线程数,需要更具服务器的硬件情况进行配置。
acceptcount:最大排队等待数,当服务器接收的请求到达maxconnections,此时tomcat会将后面的请求存放在任务队列中进行排序,acceptcount指的是任务队列中排队等待的请求数,一台tomcat的最大请求请求处理数量,是maxconnetions+acceptcount
3,禁用AJP连接器

4,调整io模式
Tomcat8之前的版本默认使用BIO(阻塞式IO),对于每一个请求都要创建一个线程来处理,不适
合高并发;Tomcat8以后的版本默认使用NIO模式(非阻塞式IO)。
当Tomcat并发性能有较高要求或者出现瓶颈时,我们可以尝试使用APR模式,APR(Apache Portable Runtime)是从操作系统级别解决异步IO问题,使用时需要在操作系统上安装APR和Native(因为APR 原理是使用使用JNI技术调用操作系统底层的IO接口)
5,动态分离
可以使用Nginx+Tomcat相结合的部署方案,Nginx负责静态资源访问,Tomcat负责Jsp等动态资源访问处理(因为Tomcat不擅⻓处理静态资源)。
五、jvm优化(参数调整)
Java 虚拟机的运行优化主要是内存分配和垃圾回收策略的优化:
- 内存直接影响服务的运行效率和吞吐量
- 垃圾回收机制会不同程度地导致程序运行中断(垃圾回收策略不同,垃圾回收次数和回收效率都是 不同的)
- Tomcat本身还是运行在JVM上的,通过对JVM参数的调整我们可以使Tomcat拥有更好的性能。目前针对JVM的调优主要有两个方面:内存调优和垃圾回收策略调优。
Java 虚拟机内存相关参数
| 参数 | 参数作用 | 优化建议 |
| -server | 启动server,以服务端模式运行 | 服务器模式建议开启 |
| -xms | 最小堆内存 | 建议与-xmx设置相同 |
| -xmx | 最大堆内存 | 建议设置为可用内存的80% |
| -xx:metaspacesize | 元空间初始值 | |
| -xx:maxmetaspacesize | 元空间最大内存 | 默认无限 |
| -xx:newratio | 取整数,默认为2 | 不需要修改 |
| -xx:survivoratio | 取整数,默认值为8 | 不需要修改 |
参数调整:
JAVA_OPTS="-server -Xms2048m -Xmx2048m -XX:MetaspaceSize=256m - XX:MaxMetaspaceSize=512m"4、调整后查看可使用JDK提供的内存映射工具

1,内存调优
找到Tomcat根目录下的bin目录,设置catalina.sh文件中JAVA_OPTS变量即可,因为后面的启动参数会把JAVA_OPTS作为JVM的启动参数来处理。再说Java虚拟机的内存结构是有点复杂的,相信很多人在理解上都是很抽象的,它主要分为堆、栈、方法区和垃圾回收系统等几个部分组成,下面是我从网上扒的内存结构图:

内存调优这块呢,无非就是通过修改它们各自的内存空间的大小,使应用能够更加合理的运用,下图是我根据我机子的性能设置的参数,给各位详细解释一下各个参数的含义吧

1、-Xmx512m:设置Java虚拟机的堆的最大可用内存大小,单位:兆(m),整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m。堆的不同分布情况,对系统会产生一定的影响。尽可能将对象预留在新生代,减少老年代GC的次数(通常老年回收起来比较慢)。实际工作中,通常将堆的初始值和最大值设置相等,这样可以减少程序运行时进行的垃圾回收次数和空间扩展,从而提高程序性能。整编:微信公众号,搜云库技术团队,ID:souyunku
2、-Xms512m:设置Java虚拟机的堆的初始值内存大小,单位:兆(m),此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
3、-Xmn170m:设置年轻代内存大小,单位:兆(m),此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。一般在增大年轻代内存后,也会将会减小年老代大小。
4、-Xss128k:设置每个线程的栈大小。JDK5.0以后每个线程栈大小为1M,以前每个线程栈大小为256K。更具应用的线程所需内存大小进行调整。
在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
5、-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 。
6、-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6。
7、-XX:MaxPermSize=16m:设置持久代大小为16m,上面也说了,持久代一般固定的内存大小为64m。
8、-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。
如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。
如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
2,垃圾回收策略调优
找到Tomcat根目录下的bin目录,也是设置catalina.sh文件中JAVA_OPTS变量即可。我们都知道Java虚拟机都有默认的垃圾回收机制,但是不同的垃圾回收机制的效率是不同的,正是因为这点我们才经常对Java虚拟机的垃圾回收策略进行相应的调整。下面也是通过我的一些需求来配置的垃圾回收策略:

Java虚拟机的垃圾回收策略一般分为:串行收集器、并行收集器和并发收集器。
串行收集器:
1、-XX:+UseSerialGC:代表垃圾回收策略为串行收集器,即在整个扫描和复制过程采用单线程的方式来进行,适用于单CPU、新生代空间较小及对暂停时间要求不是非常高的应用上,是client级别默认的GC方式,主要在JDK1.5之前的垃圾回收方式。
并发收集器:
1、-XX:+UseParallelGC:代表垃圾回收策略为并行收集器(吞吐量优先),即在整个扫描和复制过程采用多线程的方式来进行,适用于多CPU、对暂停时间要求较短的应用上,是server级别默认采用的GC方式。此配置仅对年轻代有效。该配置只能让年轻代使用并发收集,而年老代仍旧使用串行收集。整编:微信公众号,搜云库技术团队,ID:souyunku
2、-XX:ParallelGCThreads=4:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
3、-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集 。
4、-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
5、-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
并发收集器:
1、-XX:+UseConcMarkSweepGC:代表垃圾回收策略为并发收集器。
好了,到此我对虚拟机的垃圾回收策略总结就这么多,还是这句话:优化的学习一直在路上,下面还有一张从其他博客中偷到的图,据说以上三种GC机制是需要配合使用的。
