C#3.0入门系列(三)
GroupBy操作
换一种写作风格。本节讲groupby操作。
在所有的Linq To Sql操作中,GroupBy是最难理解的一个。因为,这里和Sql的出入较大。而Group真的就能返回n多组。
打开vs,新建一工程,加入System.Data.Linq.dll的引用。把northwind数据库做个映射,添加到工程里。创建一Northwind类的对象。在这里呢,我们要做分组统计,我们要先明白什么是分组。在我们开始设计product表时,我们欲留了一列叫做CategoryID。 这个字段,代表了这条记录中的产品,归属于那个类别。如图,字段的设计。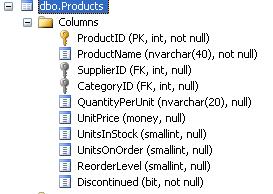
可以简单的举例,比如,当CategoryID的值为1时,就表示,对应的记录的产品是饮料类的。当它为2时,代表调味品类的。具体代表那一类,要看事先的约定。一般会专门有个表来保存这个约定。在northwind中,用Categories 表来保存这个约定。下面是catagories表中的纪录。
Categories 和Product表,通过CategoryID字段关联关系。也就是说,Product表中,CategoryID字段所代表的意思,保存在Categories 表中。好了,知道分组的概念了,我们开始分类统计吧。在Linq To Sql的所有操作中,groupby算是比较难理解的一个。我要友好的提醒你注意下这里的分组所用的字段哦,这个将来是要被用做继承的哦。
我们来看下面的例子。
 varq
=
fromp
in
db.Productsgrouppbyp.CategoryIDintogselectg;
varq
=
fromp
in
db.Productsgrouppbyp.CategoryIDintogselectg;
在这里,from p in db.Products表示从表中将对象纪录取出来。p就是每一个产品。而后面一句,group p by p.CategoryID into g表示对p进行归类,按什么归类呢,就是要按我们设定的CategoryID这个字段。而这个归类的结果,被重新命名为g,而且是必须重新命名。一旦重新命名,p的作用域就结束了,所以,最后select时,只能select g。
那有人就要问了,不重新命名可以吗?回答,可以。那你的select语句就没有了,上面语句等同与整个查询语句返回八个组,这和我们数据库的八种产品是对应的。找到最后一个group,点开+号,我们可以看到,里面有个Key和Results View字段,其中Key为8,是数据库里对应的Seafood分类,点开Results View你会惊奇的发现,所有的Seafood都在里面。我们把代码改一下,看看dlinq究竟做了什么。
varq
=
fromp
in
db.Productsgrouppbyp.CategoryID;
这是query表达式中,很少见的没有select语句的情况。我记忆中,好像只有此一种。我们还是按
var q =
from p in db.Products
group p by p.CategoryID into g
select g;
来讲解。因为这种更好理解。在T-Sql中,groupby只是用来做分组统计,计算平均值,最大值,求和等等,而在dlinq中的groupby,则发挥到了极值。我们用ToList()取到结果,来看看上面语句返回的结果。如图:
Northwinddb
=
new
Northwind(ConStr);db.Log
=
Console.Out;
 Query
#regionQuery
Query
#regionQuery varq=frompindb.Productsgrouppbyp.CategoryIDintogselectg;
varq=frompindb.Productsgrouppbyp.CategoryIDintogselectg; #endregion
Query
Verification
#regionVerificationforeach(vargpinq)
#endregion
Query
Verification
#regionVerificationforeach(vargpinq)

 {
{ }return;#endregion
Verification
}return;#endregion
Verification
单步调试该foreach段代码,foreach的目的是让dlinq加载数据。在console windows上,你可以看到如下输出。
SELECT
[
t0
]
.
[
CategoryID
]
AS
[
Key
]
FROM
[
Products
]
AS
[
t0
]
GROUP
BY
[
t0
]
.
[
CategoryID
]
--
Context:SqlProvider(Sql2005)Model:AttributedMetaModelBuild:2.0.20612.0
SELECT
[
t0
]
.
[
ProductID
]
,
[
t0
]
.
[
ProductName
]
,
[
t0
]
.
[
SupplierID
]
,
[
t0
]
.
[
CategoryID
]
,
[
t0
]
.
[
QuantityPerUnit
]
,
[
t0
]
.
[
UnitPrice
]
,
[
t0
]
.
[
UnitsInStock
]
,
[
t0
]
.
[
UnitsOnOrder
]
,
[
t0
]
.
[
ReorderLevel
]
,
[
t0
]
.
[
Discontinued
]
FROM
[
Products
]
AS
[
t0
]
WHERE
((
@x1
IS
NULL
)
AND
(
[
t0
]
.
[
CategoryID
]
IS
NULL
))
OR
((
@x1
IS
NOT
NULL
)
AND
(
[
t0
]
.
[
CategoryID
]
IS
NOT
NULL
)
AND
(
@x1
=
[
t0
]
.
[
CategoryID
]
))
--
@x1:InputInt32(Size=0;Prec=0;Scale=0)[1]
--
Context:SqlProvider(Sql2005)Model:AttributedMetaModelBuild:2.0.20612.0
原来dlinq不仅仅是做了一个groupby操作呀,他还针对每个组,都去做了一个遍历呀。我们可以用下面的图来理解。
外面的大圈,表示全集。而这个全集被分成了若干个小的集合。每个集合就叫做g。在g集合中,包含一个系统定义的Property,叫做Key。key值实际为分类时所用字段的值。而另外一部分,是该类别中所有的product.所以,我们如果想遍历某类别中所有的纪录,要这么来做。
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
g;foreach(
var
gp
in
q){
if
(gp.
Key
==
7
){foreach(
var
p
in
gp){
//
dosomething}}}
有朋友反馈说我提供的sample不能编译。大概是版本的问题,可以到http://msdn2.microsoft.com/en-us/bb330936.aspx下载for beta1的版本。本节接着讲groupby。
上一节,我们讲了如何理解groupby返回的结果。本节会延这个思路阐述下去。先来看下面的例子
GroupBy操作中Select的匿名类
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{CategoryID
=
g.
Key
,g};
本例中,select操作中使用了匿名类。本系列中第一次提到匿名类是在http://www.cnblogs.com/126/archive/2006/12/20/503519.html一文中。本文将再一次,阐述匿名类的理解。所谓匿名类,其实质,并不是匿名,而是编译器帮你去创建了这么一个类,在用户看来,好像并没有去创建,此所谓匿名类。也就是说,编译器在编译时,还是有这个类的,这个类是编译器自己创建的,其名称是编译器界定的。 在上例的匿名类中,有2个property,一个叫CategoryID, 一个叫g。 大家要注意了,这个匿名类,其实质是对返回结果重新进行了包装。而那个叫做g的property,就封装了一个完整的分组。如图,仔细比较和上篇图的区别。
如果,使用下面的语句。
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{CategoryID
=
g.
Key
,GroupSet
=
g};
只是把g重新命名为GroupSet.需要用下面的遍历,获取每个产品纪录。
foreach
(vargp
in
q)
{if(gp.CategoryID==7){foreach(varpingp.GroupSet){}}}
这里groupby的操作相对难理解些,主要原因,它包含了整个分组的具体信息,而不是简单的求和,取平均值等。如果在最终结果中,也就是在select语句中,不包含g的全部信息,而只是g的聚合函数。又会是怎么样的一番风景呢?
GroupBy中的Max, Min, Sum, Average,Count
如果,只想取每类产品中,单价为最大,用T-sql该怎么办呢?是不是要这么来写
SELECT
MAX
(
[
t0
]
.
[
UnitPrice
]
)
AS
[
MaxPrice
]
,
[
t0
]
.
[
CategoryID
]
FROM
[
dbo
]
.
[
Products
]
AS
[
t0
]
GROUP
BY
[
t0
]
.
[
CategoryID
]
我们来看看,dlinq如何来做同样的事情.如下,先按CategoryID归类,然后,只取CategoryID值和同类产品中单价最大的。
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{g.
Key
,MaxPrice
=
g.
Max
(p
=>
p.UnitPrice)};
在这里,Max函数只对每个分组进行操作。我们来看看其结果
呀,这次,dlinq并没有把组里所有的纪录都取出来的吗。(请参考http://www.cnblogs.com/126/archive/2006/09/01/486388.html一文中的方法,配置sample.) dlinq只是简单做了统计,并返回结果。
每类产品中,单价为最小的,
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{g.
Key
,MinPrice
=
g.
Min
(p
=>
p.UnitPrice)};
每类产品的价格平均值
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{g.
Key
,AveragePrice
=
g.Average(p
=>
p.UnitPrice)};
每类产品,价格之和
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{g.
Key
,TotalPrice
=
g.
Sum
(p
=>
p.UnitPrice)};
各类产品,数量之和
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{g.
Key
,NumProducts
=
g.
Count
()};
如果用OrderDetails表做统计,会更好些,因为,不光可以统计同一种产品,还可以统计同一订单。
接着统计,同各类产品中,断货的产品数量。使用下面的语句。
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
select
new{g.
Key
,NumProducts
=
g.
Count
(p
=>
p.Discontinued)};
在这里,count函数里,使用了Lambda表达式。在上篇中,我们已经阐述了g是一个组的概念。那在该Lambda表达式中的p,就代表这个组里的一个元素或对象,即某一个产品。还可以使用where条件来限制最终筛选结果
var
q
=
from
p
in
db.Products
group
p
by
p.CategoryID
into
g
where
g.
Count
()
>=
10
select
new{g.
Key
,ProductCount
=
g.
Count
()};
这句在翻译成sql语句时,欠套了一层,在最外层加了条件。
SELECT
[
t1
]
.
[
CategoryID
]
,
[
t1
]
.
[
value2
]
AS
[
ProductCount
]
FROM
(
SELECT
COUNT
(
*
)
AS
[
value
]
,
COUNT
(
*
)
AS
[
value2
]
,
[
t0
]
.
[
CategoryID
]
FROM
[
dbo
]
.
[
Products
]
AS
[
t0
]
GROUP
BY
[
t0
]
.
[
CategoryID
]
)
AS
[
t1
]
WHERE
[
t1
]
.
[
value
]
>=
@p0
--
@p0:InputInt32(Size=0;Prec=0;Scale=0)[10]
--
Context:SqlProvider(Sql2005)Model:AttributedMetaModelBuild:2.0.20612.0
GroupBy操作中GroupBy的匿名类
在第一次谈到匿名类时,我们就提到不光Select操作可以使用匿名类,其他操作符也可以。但是,OrderBy不支持。请参考C#3.0入门系列(六)-之OrderBy操作
当用户既想按产品的分类,又想按供应商来做分组,该怎么办呢。这时,我们就该使用匿名类。
var
categories
=
from
p
in
db.Products
group
p
by
new{p.CategoryID,p.SupplierID}
into
g
select
new{g.
Key
,g};
在by后面,new出来一个匿名类。这里,Key其实质是一个类的对象,Key包含两个Property,一个是CategoryID,再一个是SupplierID ,要想取到具体CategoryID的值,需要g.Key.CategoryID,才能访问到。我们来看dlinq翻译的T-sql语句。
SELECT
[
t0
]
.
[
SupplierID
]
,
[
t0
]
.
[
CategoryID
]
FROM
[
dbo
]
.
[
Products
]
AS
[
t0
]
GROUP
BY
[
t0
]
.
[
CategoryID
]
,
[
t0
]
.
[
SupplierID
]
--
Context:SqlProvider(Sql2005)Model:AttributedMetaModelBuild:2.0.20612.0
先按CategoryID,再按SupplierID ,和匿名类中的循序一样。
最后一个例子。