C/C++代码性能优化——数据结构和算法
1. 数据结构
合适的数据结构,对代码的性能提升非常明显。针对数据结构,我们不需要可以做到白板手写的程度。只要熟知其特点,然后推导出其应用场景,等到了真正需要时,再查找示例代码来修改应用即可。
1.1. 数组
- 固定类型固定大小的集合,指针和数组基本等价。
- 适用于通过索引快速随机访问的场景,有序数据可以通过二分法快速查找。
1.2. 链表
- 线性数据结构,可以从头往后遍历。
- 适用于需要频繁插入删除操作的场景,对查找需求较低。普通链表适用于数据量较小的场景。
1.3. 块状链表
- 块状链表是将数组和链表结合起来的一种数据结构,链表的节点存储一个数组。块状链表有点类似简化的二层B+树,其插入和删除不用像平衡二叉树为了维持平衡进行更多修改,所以其平均性能优于平衡二叉搜索树(包括红黑树、B/B+树)。虽然块状链表节点处数据可以利用二分法,但是受限于链表的特性要遍历进行查找的特性,其综合性能依然低于基本全用二分法查找的平衡二叉搜索树(包括红黑树、B/B+树)。块状链表通常比平衡二叉树更节省空间,因为它们不需要存储平衡信息。
- 块状链表适用于数据量较小,且内存有限制的,插入和删除需求大于查找需求的场景。

1.4. 栈
- 后进先出(LIFO)的数据结构。
- 有后进先出需求的场景。
1.5. 队列
- 先进先出 (FIFO) 数据结构。
- 有先进先出需求的场景。
1.6. 树
一个分层的数据结构,其每个节点可以有多个子节点。树有比数组更好的插入删除性能,有比链表更好的随机访问性能。针对树的特性,又进一步进行了优化,不同的树有不同的应用重点。
1.6.1. 二叉搜索树
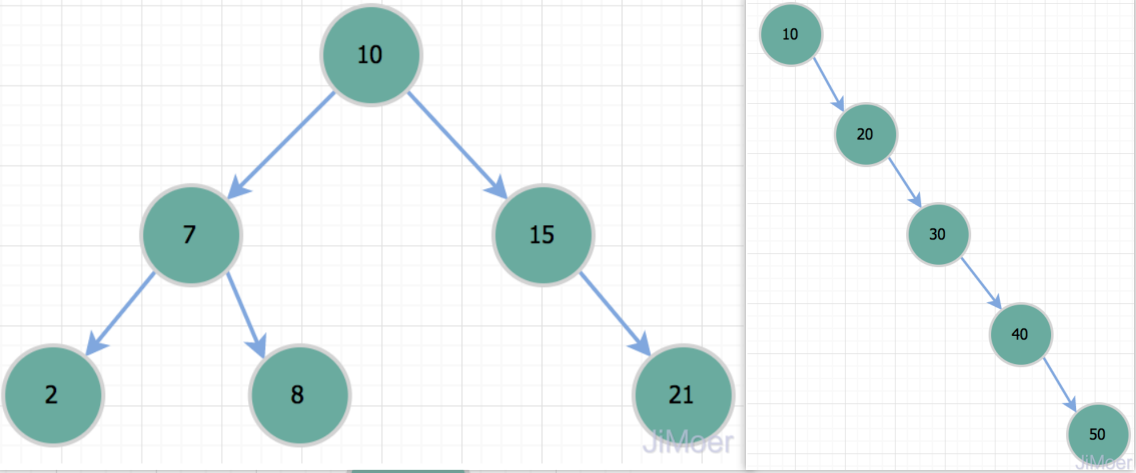
- 二叉树结构,其中每个节点的左子树中的值都小于节点的值,右子树中的值都大于节点的值。
- 因为其特点是数据排列有序,可以快速查找、删除,但是当数据有序性较强时,容易退化为一条线,导致性能降低。可以通过深度优先搜索和广度优先搜索来查找,添加和删除。
1.6.2. 平衡二叉搜索树
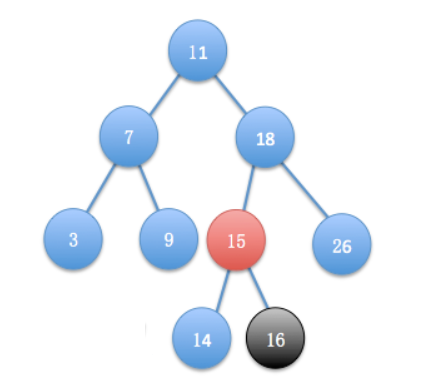
为了解决二叉搜索树退化导致性能降低的极端情况,出现了平衡二叉搜索树,其避免出现某一个分支过长的情况,操作性能较二权搜索树更加均衡。但是在数据量巨大时,其树高比较高,导致对根节点的操作性能较差。
AVL树和红黑树都是平衡二权搜索树,红黑树相对于AVL树规则更简单,所以平衡二叉树多使用红黑树。C++中的std::map即采用红黑树实现。
1.6.3. B树
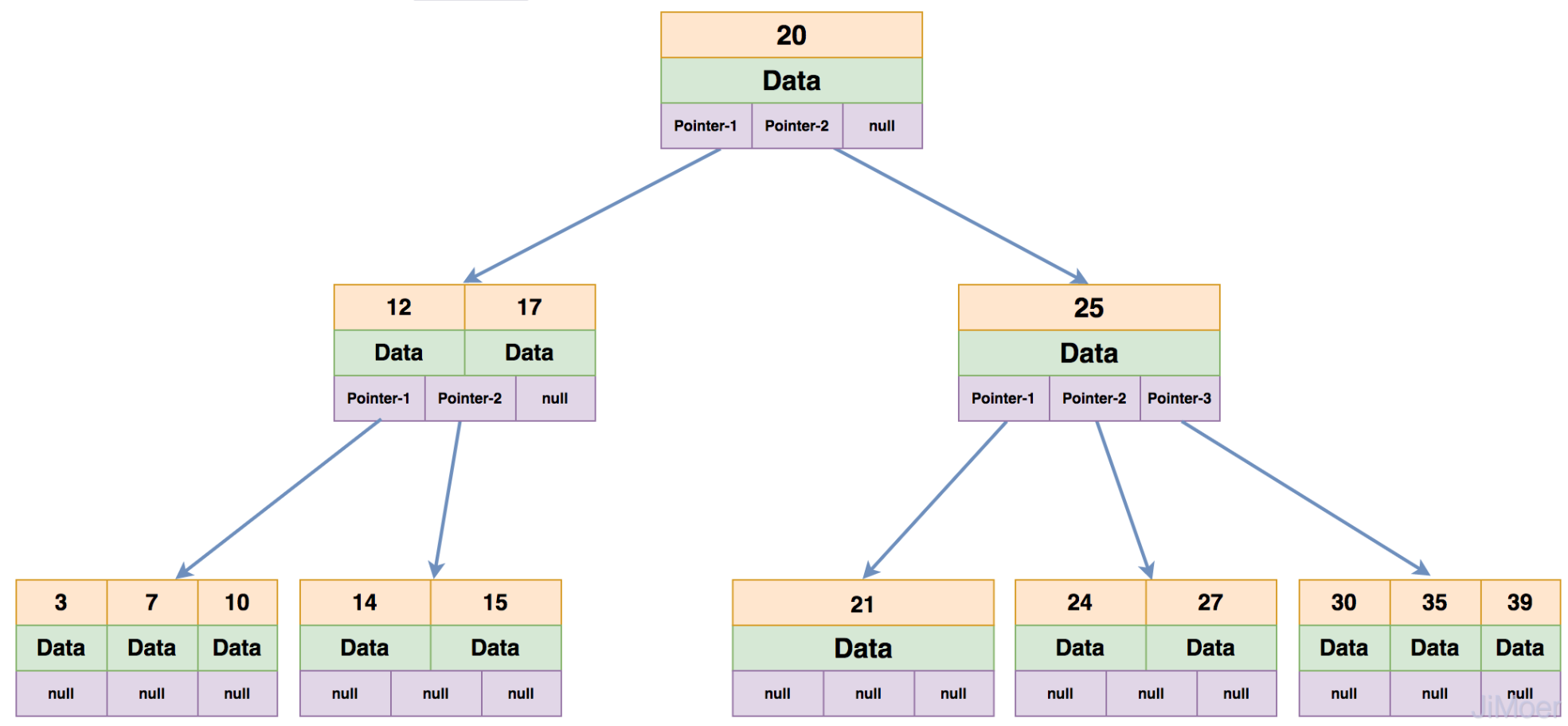
为了优化平衡二叉树在大量数据时容易根节点过深的问题,将平衡二叉树的每个节点存放更多数据。在数据量较小的时候,红黑树的平衡性能更优。在数据量比较大的时候,B树的平衡性能比红黑树更优。并且B树引入了更复杂的节点数据,每个非根节点存放3类数据,Key-Data-Pointer。这样就可以应对更复杂的数据存储查询删除需求。
1.6.4. B+树
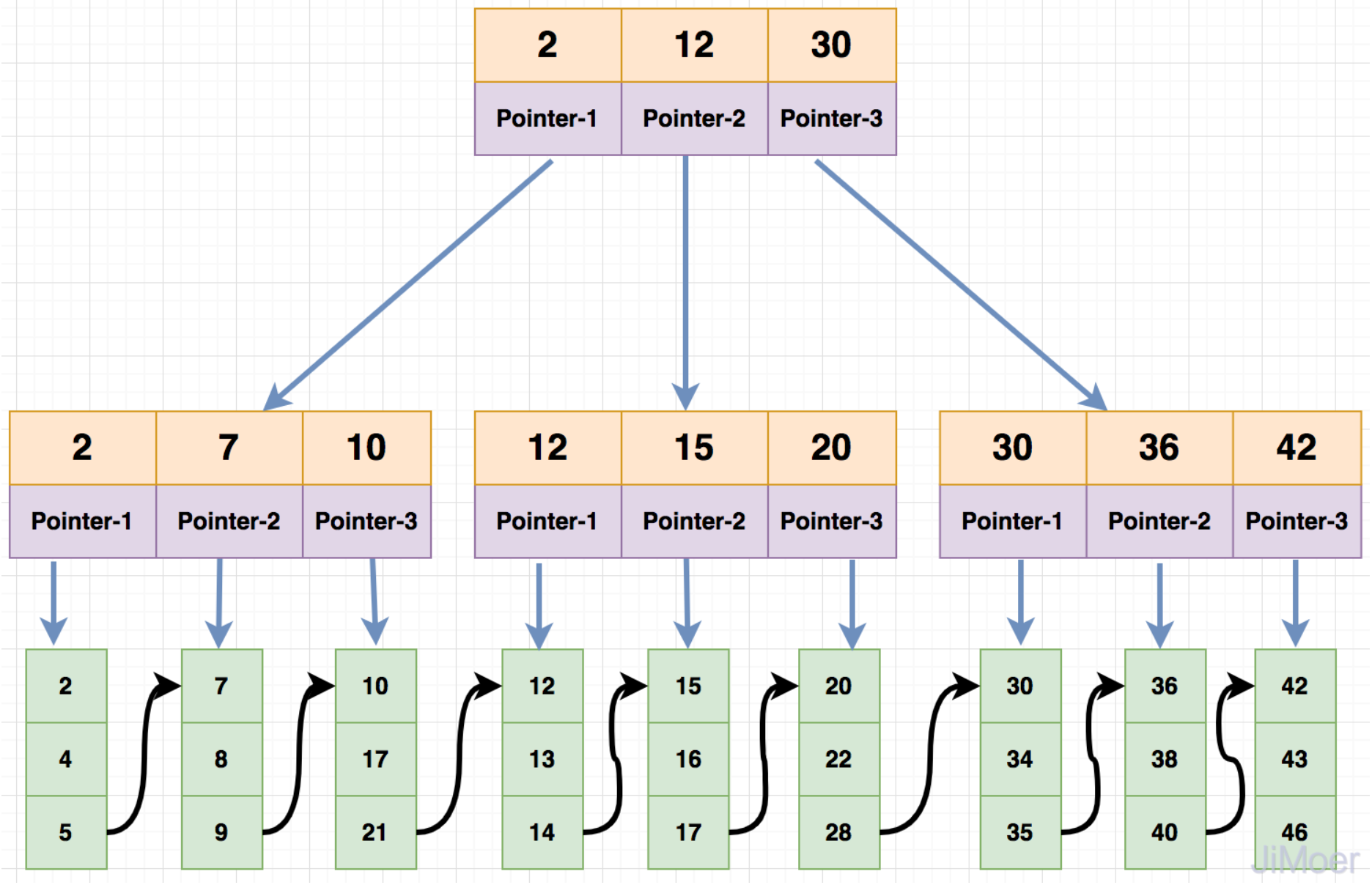
B+树优化了B树,将Key和数据统一放到根节点存储,子节点只用来存放Key和指针。相较于B树,B+在操作性能上更稳定起伏小。另外,B+树更容易顺序指定范围从前后往后扫描所有数据。B+树的这种特性非常适用于管理文件系统,现代文件系统NTFS和Ext4均使用B+树来实现。大型的关系型数据MySQL、SQL Serve、Oracle、PostgreSQL均使用B+树来存储管理其主要数据。
1.7. 跳表
跳表是对传统的有序链表进行优化,添加多层索引来加速搜索操作,简单来说它是一个空间换时间的策略。针对数据量的大小,以及对性能的要求,可以相应地设计索引层数。
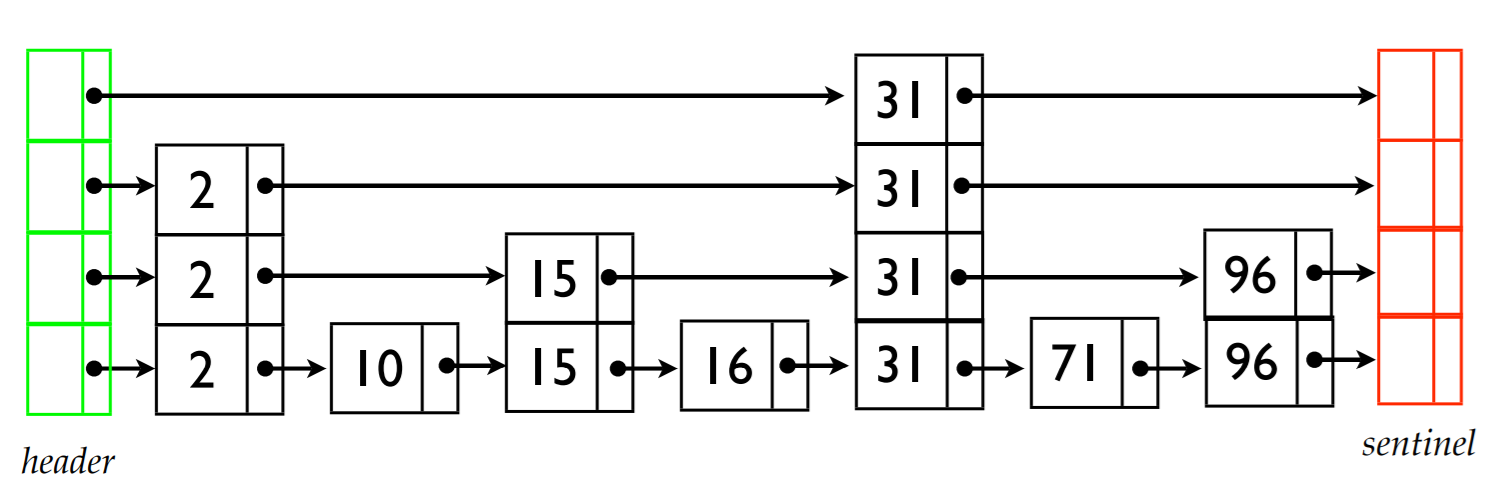
跳表相比红黑树,算法更简单,在索引层级足够的前提下,可以实现更好的搜索性能。在索引层级较多时,其空间相比红黑树会占用更大,具体取决于跳表层级的设计。
跳表需要预先分配空间,红黑树可以更好的动态扩大缩小。
算法复杂度上,跳表比较红黑树要简单,更容易理解。
红黑树的数据是有序的,缓存一致上能够做到比较好。跳表如果数据量比较大,其过多的层级索引和数据之间可能导致缓存一致性降低。
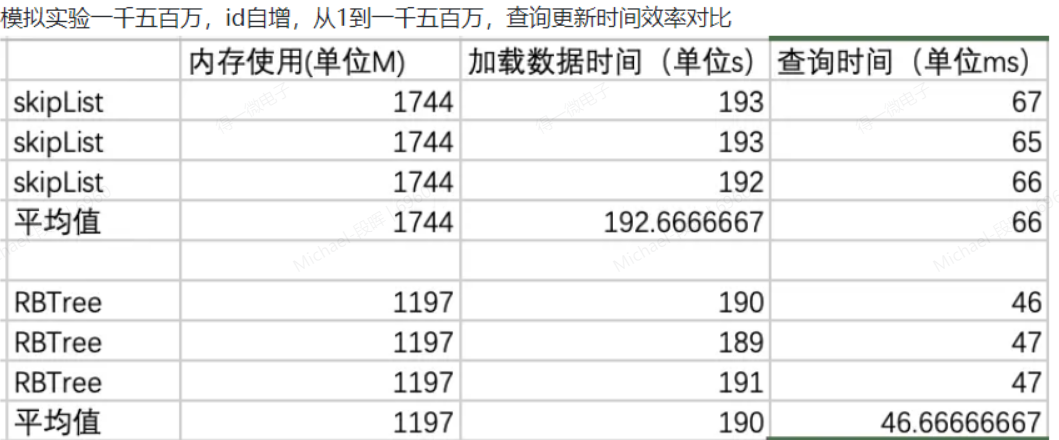
综合来讲,在40MB(对应1000万int类型数据)数据量以下,跳表的性能要略优于红黑树。如果数据量更多,跳表的性能因为其层级索引缓存一致性问题,性能逐渐不如缓存一致性更好的红黑树。所以相对于复杂的大型文件系统或是大型数据库,更适合使用B+树,数据量少一些的数据管理,更适合红黑树或跳表。内存数据库Redis、键值存储数据库LevelDB都是用跳表来实现主要数据的管理。
块状链表更数组属性,局部随机性表现会比跳表好,但是整体随机性比跳表差。综合来讲,在数据量1K以下,块状链表和跳表性能相当,在更大数据量,跳表性能更优。
1.8. 索引
索引是加快查找的重要方法,针对数据量,可以使用多级索引。根据数据类型,可以使用不同类型的索引。一个大型的数据管理系统一般会根据需求,针对性地创建不同的索引来加快查找、增删的性能。
1.8.1. 聚集索引和非聚集索引
- 聚集索引是以表中的可以作为唯一标记的列的内容进行排序,这样就可以快速通过聚集索引来进行查找,代价空间消耗大,聚集索引创建消耗时间大。
- 非聚集索引根据表中某一列的内容和行内容指令建立一个新的表,空间代价小,但是查找性能较聚集索引慢。非聚集索引可以根据不同列的信息来建立多个新的表,针对性的索引查找。
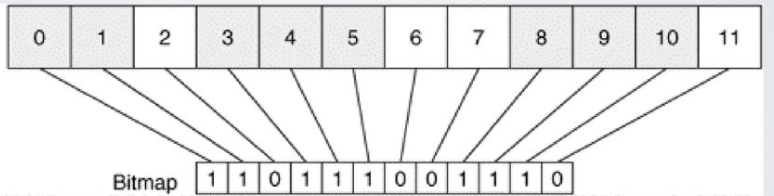
1.8.2. 位图索引
位图索引(Bitmap Index),即用比特来映射数据的状态。为了更好的数据管理实时性能,一般数据删除时,只是在另外的数据结构中标记其是否删除,并不执行真正的删除操作。等到下次需要添加数据时,只需要通过标记找到无效数据节点覆盖新数据即可。这样可以提高性能。更高效,更节省空间的标记数据结构就是位图索引。大型文件系统、数据库都有使用位图索引。
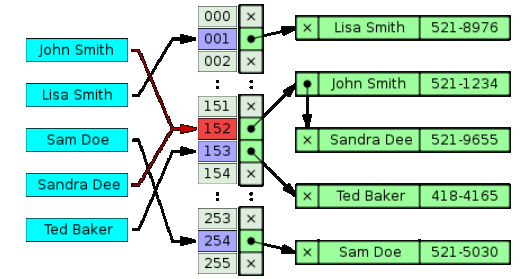
1.9. 哈希表
哈希表是一个存储Key-Value的数据结构。哈希表通过哈希函数将Key映射到存储数据的下标索引,这样就可以快速根据Key来访问对应的数据。哈希函数生成的哈希值下标有可能重复,那么可以用一个链表来记录哈希值相同的Key和数据以便二次查找,所以其空间消耗比红黑树高。但是其搜索性能远高于红黑树。哈希表的算法实现也比较红黑树简单。哈希表有大量的开源算法,可以根据数据类型、数据量、算法复杂度和性能综合选择哈希算法。
1.10. 图
图是由节点和连接节点的边组成的非线性数据结构,用于表示多个对象之间的关系。如果有多对多的复杂关系,且有最短路径这类需求的,可以考虑使用图数据结构。
1.11. 总结
一个大型的存储系统,一般会使用多种数据结构协调工作,甚至根据实际情况会在标准数据结构上进行变形优化。重点是要明白数据结构的特点和和其对应性能的表现,这样指导我们使用和优化数据结构。
参考资料:
Stack Data Structure and Implementation in Python, Java and C/C++
B 树 - OI Wiki
2. 常用算法
2.1. 排序算法
2.1.1. 实测结果
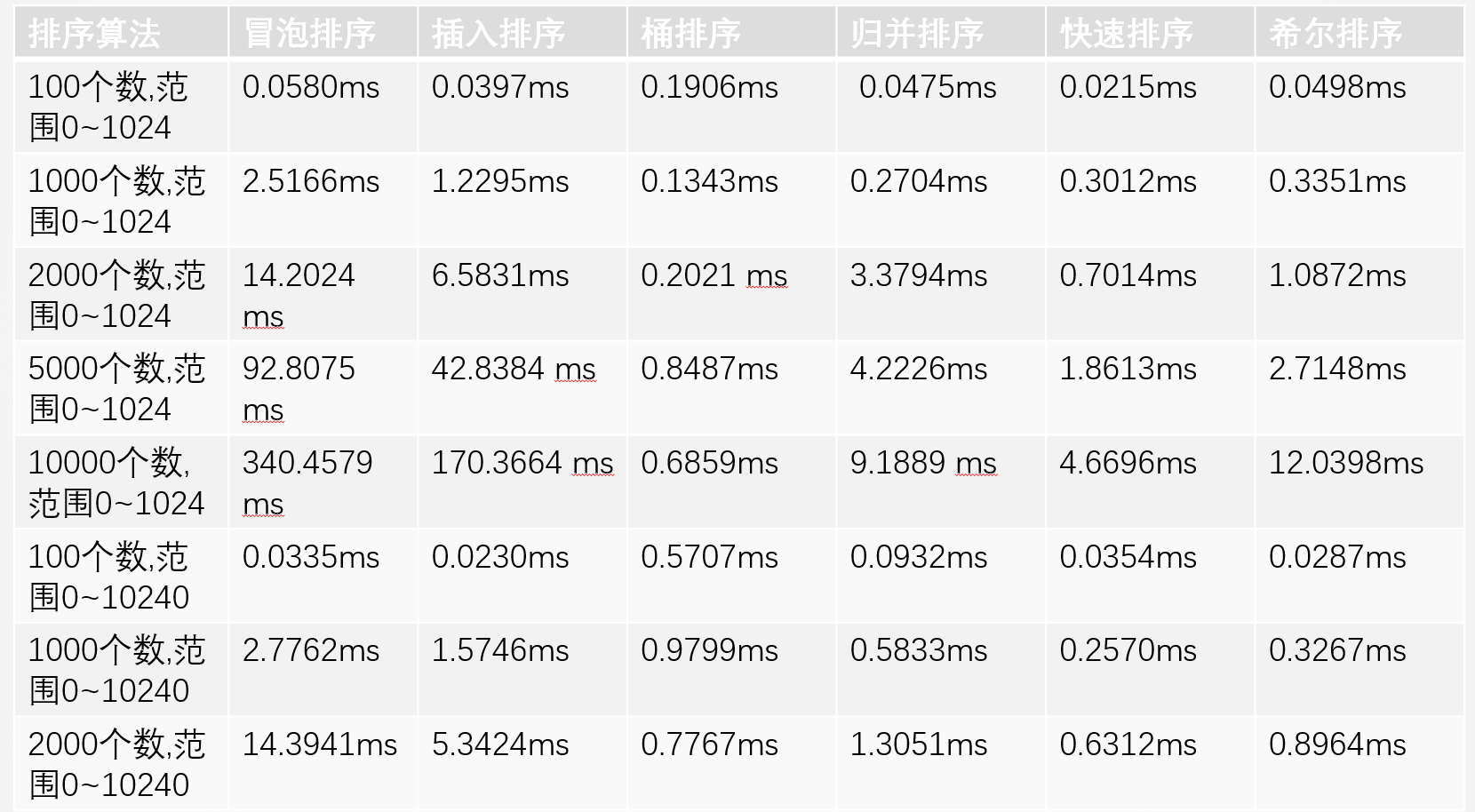
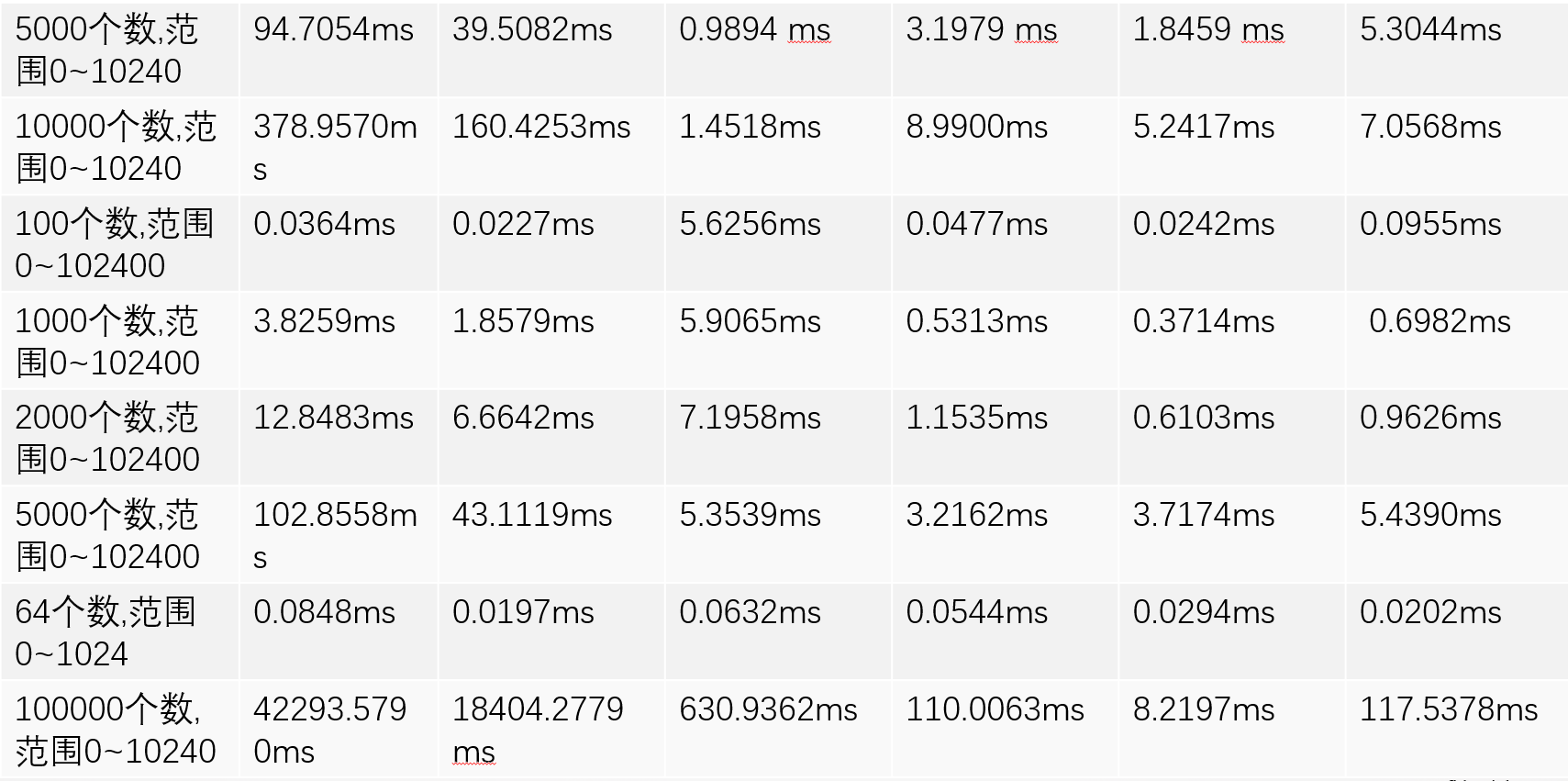
2.1.2. 总结
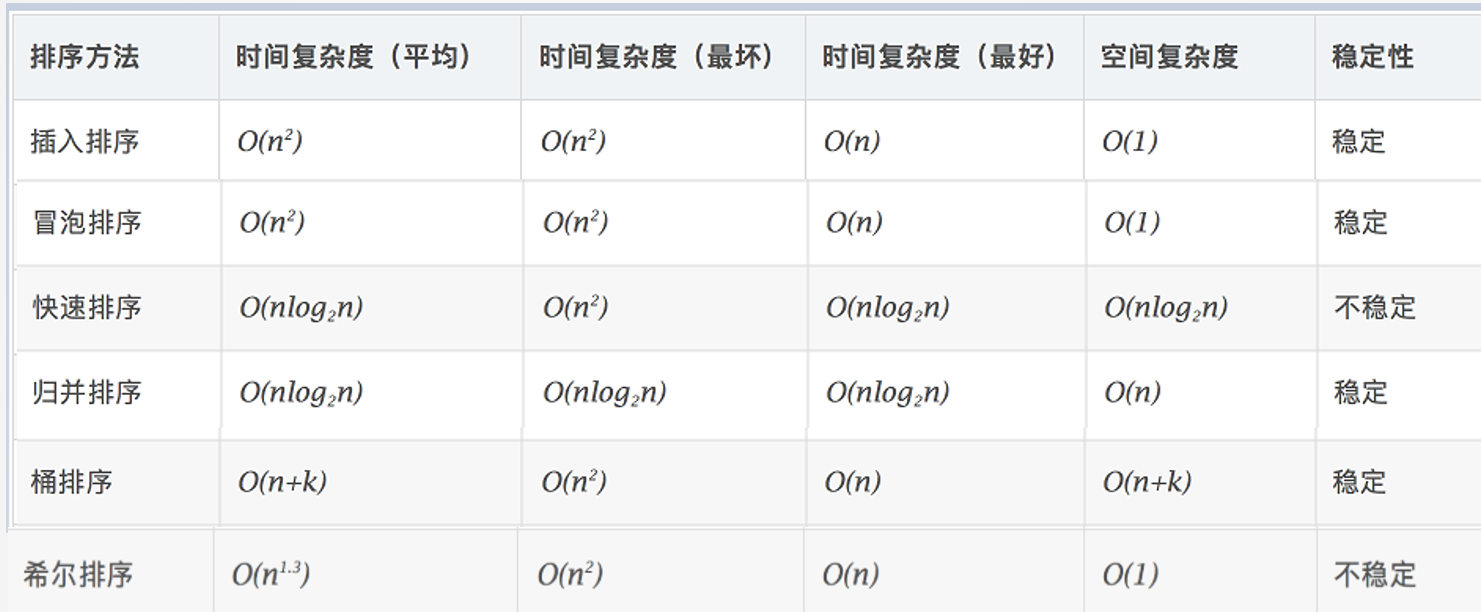
2.1.3. 结论
- 不推荐使用冒泡排序,插入排序极其简单,各方面性能均大幅优于冒泡排序。
- 其他还有一些选择排序、堆排序,以及基于归并排序、桶排序的一些改进算法,其实际测试的效果并没有快速排序和希尔排序效果好,所以此处不统计。
- 一般情况下,可以根据数据类型、数据量级选择多种排序混合使用。
- 桶排序适合于数据分布平均,且集中在一个不大的范围内。桶排序是以空间换时间。如果有4096范围内的数据需要排序,可以考虑用桶排序。并且针对桶排序有一些优化算法,如基数排序,计数排序。
- 希尔排序、归并排序、快速排序,都是同一级别,绝大多数情况下是快速排序效率更高。但是三者之中,只有归并排序是稳定排序算法。但是快速排序虽然效率好,但是空间复杂高较高,而希尔排序不需要额外的空间。
- 追求效率,用快速排序。
- 追求效率且要求稳定,用归并排序。
- 追求效度且尽量小占用空间,用希尔排序。
- 数据范围分布小,追求效率用桶排序。桶内排序,根据1,2,3选择相应排序算法。
- 数据量小于等于64时,使用插入排序,实际过程中快速排序的空间申请会影响整体的效率。
- 针对大部分数据都是有序的数据集,使用插入排序,快速排序此时性能最差。
2.2. 查找算法
2.2.1. 顺序查找
顺序查找,适用于数据量较小的无序数据集。
2.2.2. 二分查找
二分查找,适用于有序的数据集。
2.2.3. 插值查找
针对有均匀分布的有序数据集,可以优化二分查找法,可以通过公式估算采样位置进行查找。在数据量较小时,公式估算的性能开销会抵消插值查找优化的效果。
2.2.4. 斐波那契查找
针对有均匀分布的有序数据集,采用斐波那契数(黄金分割点分割,而不像二分法平分)分割数据进行查找,相比二分法能够更快地找到目标。针对不均匀的数据集,其效果也会远远好于插值查找。数据量较小时,算法额外开销会抵消其部分性能优势。
2.2.5. 二叉查找树查找
如果数据是以平衡二叉树存储的,那么就使用二叉查找树查找法来查找。
2.2.6. 分块查找
数据有序存储的开销较大,无序存储的查找开销大。分块查找,就是部分有序,将数据按大小分成几堆,每一堆中的数据不要求有序。这样初始的存储开销较有序存储低,查找性能较无序存储的高。分块查找要求能够比较准确地将数据分为大小相近的几堆。如果分类不够准确,加大了存储开销,却不能提升多少查找性能。
2.2.7. 哈希查找
哈希查找通过存储数据时建立哈希映射表,查找时通过哈希值来查找。因为哈希表存在冲突,所以哈希表需要存储额外的信息,导致空间消耗较大。所以哈希查找,适用于空间足够,且数据量较大,对查找性能追求的场景。
2.2.8. 表查找
表查找,利用位图索引来查找,速度非常快,但是空间消耗大,且要求数据唯一。针对需要重复快速查询的场景非常有效。如果手机号码是否使用等。如果有相关对应数据需求,可以建立索引表存储内容地址。
2.2.9 布隆过滤器查找
布隆过滤器根据要查询的数据建立一个相应的位图,存储数据时,将数据经过8个哈希算法,生成8个哈希索引,并在位图8个对应的索引上置1。存储其他数据时,也依次如此操作。我们知道哈希索引有冲突的概率,但是8个哈希索引都同时冲突的概率其实不大,但是依然有完全冲突的存在性。所以布隆过滤查找的结果为不存在时,就一定不存在。存在时,就有概率是误差。通过调整哈希算法的个数,可以减少冲突的概率。如邮件服务系统的垃圾邮件一般会使用布隆过滤器查找是否为垃圾邮件。
2.2.10. 结论
- 无序,且数据集较小(具体数量与CPU性能有关),且不需要频繁查找时,用顺序查找。
- 无序,且数据集较大,可以先排序,再根据数据特性选择其他有序查找算法。
- 有序,且数据集较小,使用二分法查找。
- 有序,且数据集较大,且数据分布均匀,使用插值查找。
- 有序,且数据集较大,且数据分布不一定均匀,使用斐波那契查找。
- 数据集为平衡二叉树结构,使用二叉查找树算法查找。
- 数据分块有序均匀存储,使用分块查找。
- 目标数据唯一,且有高频查询需求,使用表查找。
- 快速高频查询需求,且不追求绝对准确的查询是否存在的场景,使用布隆过滤器查找。
- 快速高频查询需求,且能容忍一定的内存消耗,使用哈希查找,如果只是查询是否存在,可以结合位图索引。
2.3. 其他算法
算法是一种思想,不必熟练到手写算法的程序。知道什么场景用什么算法,具体算法用的时候去查询即可。
- 分治算法,把一个复杂的问题分成两个或更多的相同或相似的子问题,利用递归来实现。其应用如二分查找,快速排序等。
- 动态规划,将一个复杂的问题分成多个类似的子问题,且使用额外变量记录每一子问题的结果,后续避免重复计算子问题结果。其应用如背包问题(装入的端口总价值最高)。
- 贪心算法,很贪心每次都要最优,贪心算法将在问题的每一步选择中都采取当前状态下最优的选择,以期望通过局部最优解最终达到全局最优解。
- 最短路径算法,其应用如地图两个位置的最短路线规划。
- 近似算法,有时追求最优解会耗费大量计算资源,而且追求近似解,可以节省大量计算资源用来在其他方面提升性能,最终达到综合性能的提升。