TnT-LLM: Text Mining at Scale with Large Language Models
TnT-LLM: Text Mining at Scale with Large Language Models
相关链接:arxiv
关键字:Large Language Models (LLMs)、Text Mining、Label Taxonomy、Text Classification、Prompt-based Interface
摘要
文本挖掘是将非结构化文本转换为结构化和有意义的形式,这对于下游分析和应用是基础步骤。然而,大多数现有的标签分类法和基于文本的标签分类器的生成方法仍然严重依赖于领域专业知识和手动策划,使得这一过程昂贵且耗时。尤其是当标签空间未明确指定且大规模数据注释不可用时,这一挑战尤为突出。本文提出了TnT-LLM框架,利用LLMs基于提示的接口,以最小的人工努力自动化端到端标签生成和分配过程。在第一阶段,我们引入了一种零样本、多阶段推理方法,使LLMs能够迭代地产生和完善标签分类法。在第二阶段,LLMs被用作数据标注器,生成训练样本,以便构建轻量级的监督分类器,这些分类器可以可靠地进行大规模部署和服务。我们使用TnT-LLM对Bing Copilot(以前称为Bing Chat)的用户意图和会话领域进行分析,这是一个开放领域的基于聊天的搜索引擎。通过使用人工和自动评估指标进行的广泛实验表明,与最先进的基线相比,TnT-LLM能够生成更准确和相关的标签分类法,并在大规模分类的准确性和效率之间取得了有利的平衡。我们还分享了在实际应用中使用LLMs进行大规模文本挖掘的挑战和机遇的实践经验和见解。
核心方法
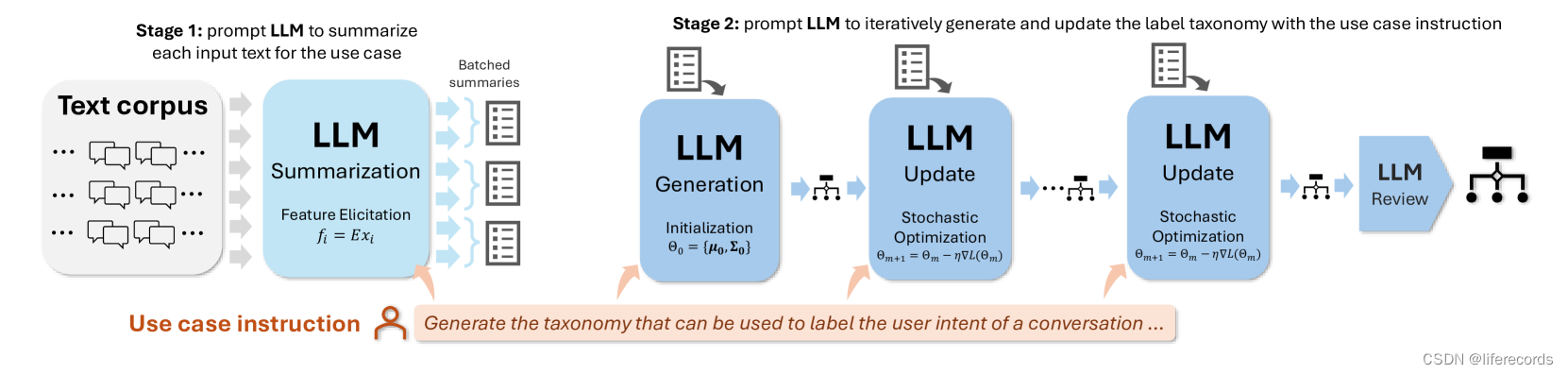
- 零样本、多阶段推理方法:在第一阶段,我们提出了一种方法,使LLMs能够迭代地产生和完善标签分类法,而不需要任何先验的标签样本。
- LLMs作为数据标注器:在第二阶段,LLMs被用作数据标注器,生成训练样本,这些样本用于训练轻量级的监督分类器,这些分类器可以大规模部署和服务。
- 端到端框架:TnT-LLM是一个端到端的两阶段框架,它结合了LLMs在两个阶段的独特优势,实现了标签生成和文本分类的自动化。
- 可定制性和模块化:该框架是可适应和模块化的,可以根据不同用例、文本语料库、LLMs和分类器进行定制,同时需要很少的人工干预或输入。
实验说明
实验结果数据使用以下Markdown表格展示:
| 指标 | 用例 | 人类标注者 vs. GPT-4标注者 |
|---|---|---|
| 准确度(意图) | 0.476* | 0.558* |
| 准确度(领域) | 0.478* | 0.578* |
| 相关性(意图) | 0.466* | 0.520* |
| 相关性(领域) | 0.379 | 0.288 |
*表示中度一致性及以上(> 0.4)。
数据要求:实验使用了来自Bing Copilot系统的对话记录,这些记录是多语言的、开放领域的,并经过隐私和内容过滤以确保质量和隐私。
数据来源:实验数据来自2023年8月6日至10月14日的10周内的1k对话样本,用于第一阶段的标签分类法生成,以及同一时间段的另外5k对话样本,用于第二阶段的标签分配。
结论
我们的TnT-LLM框架能够使用很少的人工指导或干预,从非结构化文本语料库中生成高质量的标签分类法。在对真实世界AI聊天对话的评估中,我们证明了该方法可以找到非结构化文本中的结构和组织。我们的方法在需要超出表面语义的深层推理时,优于传统的基于嵌入的聚类方法。我们还发现,尽管基于嵌入的聚类仍然有效,但它更容易受到建模选择或输入与用例对齐的影响。我们提倡仔细评估LLMs的潜在用例,平衡性能和效率,同时利用它们与常规机器学习分类器的成熟度、速度和成本相结合的力量。