python数据结构算法_python数据结构和算法
栈-先进后出
classStack():
def __init__(self):
self.items=[]
def push(self,item):
self.items.append(item)
def pop(self):returnself.items.pop()
def peek(self):return len(self.items)-1def isEmpty(self):return self.items ==[]
def size(self):returnlen(self.items)
stack=Stack()
stack.push(1)
stack.push(2)
stack.push(3)
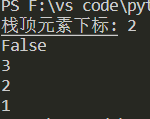
print('栈顶元素下标:',stack.peek())
print(stack.isEmpty())
print(stack.pop())
print(stack.pop())
print(stack.pop())
队列-先进先出
classQueue():
def __init__(self):
self.items=[]
def enqueue(self,item):
self.items.insert(0,item)
def dequeue(self):returnself.items.pop()
def isEmpty(self):return self.items ==[]
def size(self):returnlen(self.items)
q=Queue()
q.enqueue(1)
q.enqueue(2)
q.enqueue(3)
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())

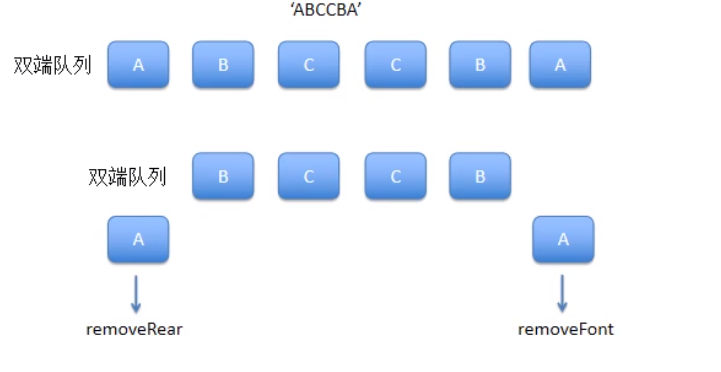
双向队列-头尾都能进出-实现判断回文
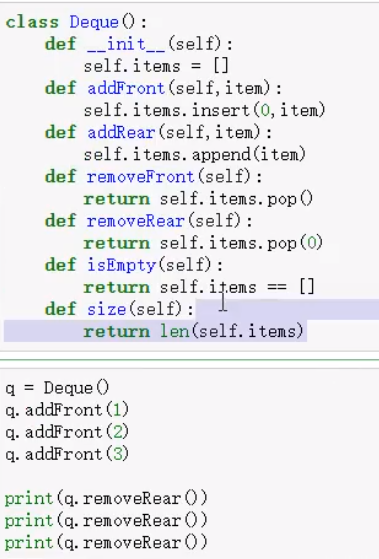
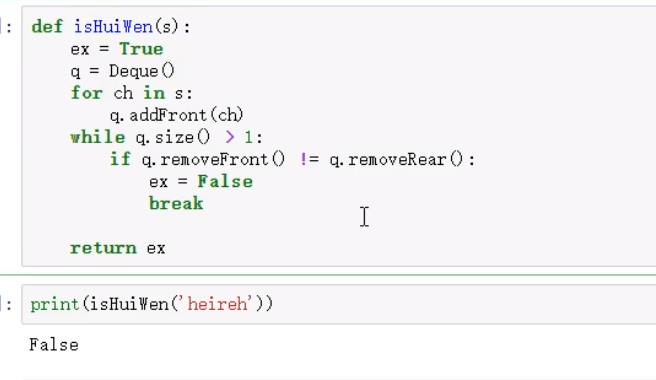
单链表-从头部插入节点
该数据结构主要是依靠head的不停改变,
classNode():
def __init__(self,item):
self.item=item
self.next=NoneclassLink():
def __init__(self):
#构造出一个空的链表
self._head=None
def add(self,item):
node=Node(item) #先创建一个节点,在内存中,再考虑怎样操作
node.next=self. _head
self._head=node
def travel(self):
cur=self._headwhilecur:
print(cur.item)
cur=cur.next
link=Link()
link.add(3)
link.add(4)
link.travel()
两个队列实现栈
队列是先进先出,栈是先进后出,所以只要把数据一个一个先进的后出即可
主要思想就是利用另一个队列来放主要数据队列的n-1个,然后主要数据队列就只剩下最后一个,取出即可,然后重复,就把最后的先出了
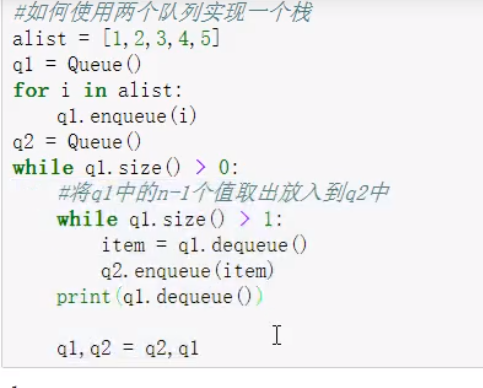
链表倒置

二叉树
classNode():
def __init__(self,item):
self.item=item
self.left=None
self.right=NoneclassTree():
def __init__(self):
self.root=None
def addNode(self,item):
node=Node(item)if self.root ==None:
self.root=nodereturncur=self.root
q=[cur] #用列表来进行遍历节点whileq:
nd= q.pop(0) #先把根结点取出if nd.left ==None:
nd.left=nodereturn
else:
q.append(nd.left)if nd.right ==None:
nd.right=nodereturn
else:
q.append(nd.right)
def travel(self):
cur=self.root
q=[cur]whileq:
nd= q.pop(0)
print(nd.item)ifnd.left:
q.append(nd.left)ifnd.right:
q.append(nd.right)
tree=Tree()
tree.addNode(1)
tree.addNode(2)
tree.addNode(3)
tree.addNode(4)
tree.addNode(5)
tree.addNode(6)
tree.addNode(7)
tree.travel()
排序二叉树

classNode():
def __init__(self,item):
self.item=item
self.left=None
self.right=NoneclassSortTree():
def __init__(self):
self.root=None
def addNode(self,item):
node=Node(item)
cur=self.rootif self.root ==None:
self.root=nodereturn
whilecur:
#向右插入if item>cur.item:if cur.right ==None:
cur.right=nodebreak
else:
cur=cur.right
#向左插入else:if cur.left ==None:
cur.left=nodebreak
else:
cur=cur.left
tree=SortTree()
alist= [3,8,5,7,6,2,9,4,1]fori in alist:
tree.addNode(i)
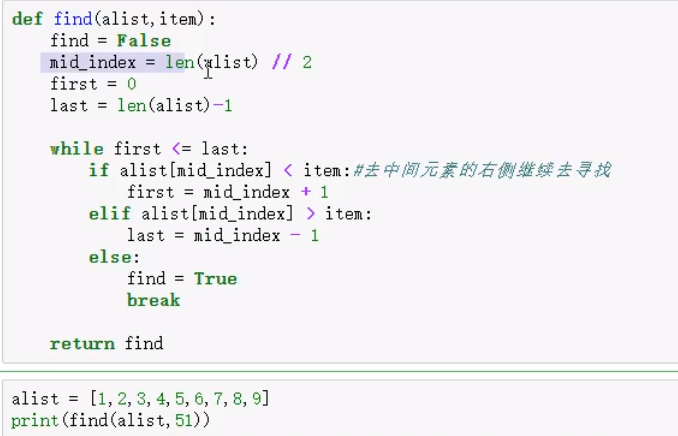
二分查找
排序
1 冒泡排序
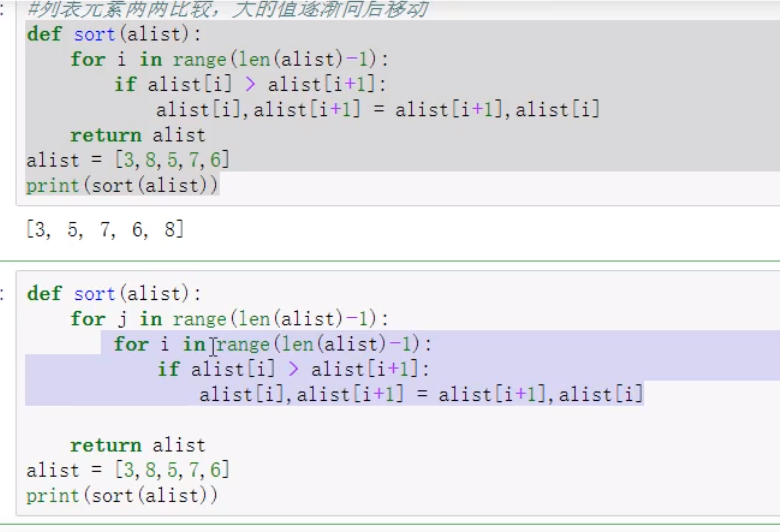
2 快速排序
def sort(alist):
#基数
mid= alist[0]
low= 0high=len(alist)while low
#偏移highwhile lowmid:
high-=1
else:
alist[low]=alist[high]break#偏移lowwhile low
low+=1
else:
alist[high]=alist[low]break
if low==high:
alist[low]=midbreak
returnalist
alist=[6,1,24,5,3,7,4]
print(sort(alist))
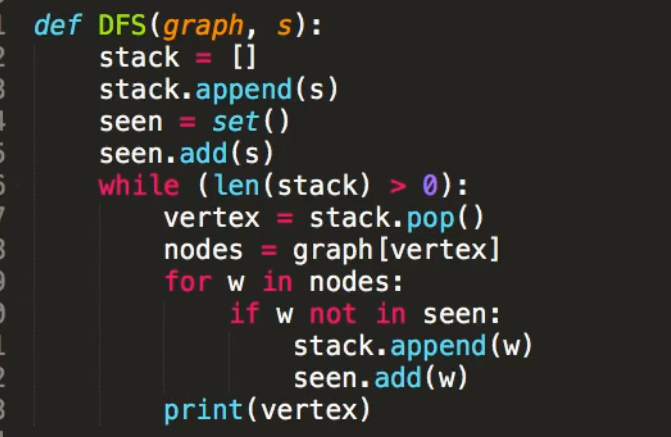
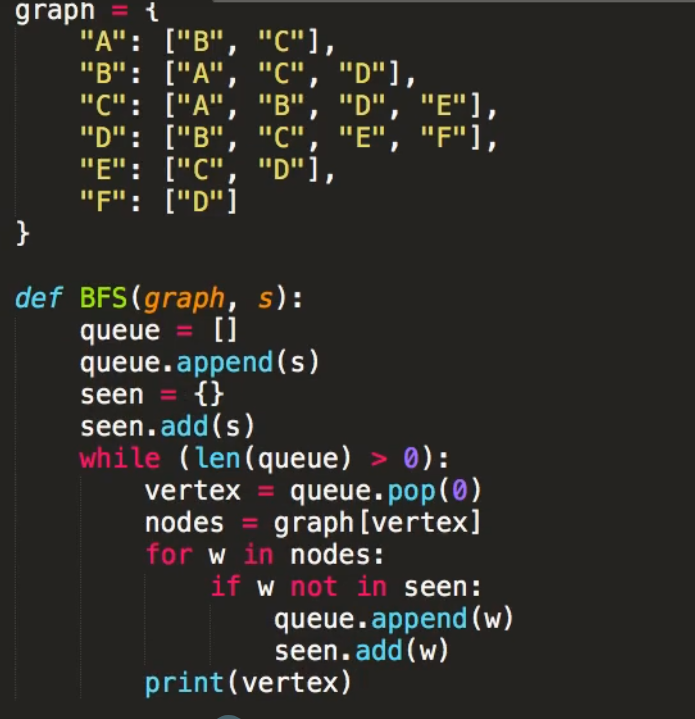
BFS(广度优先搜索)
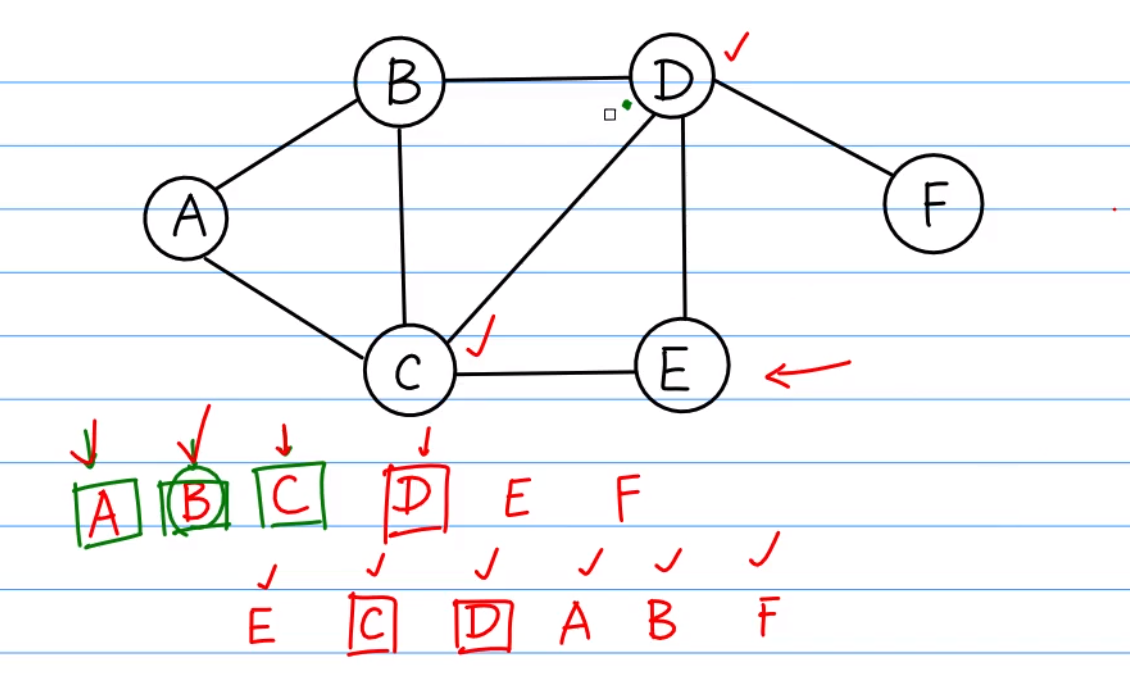
由谁先展开就需要把它的子节点先遍历出来,然后接子节点的遍历,当然节点也是不唯一的,如第一个的CB当然可以换,不过换了后面也要需要注意前面的子节点遍历
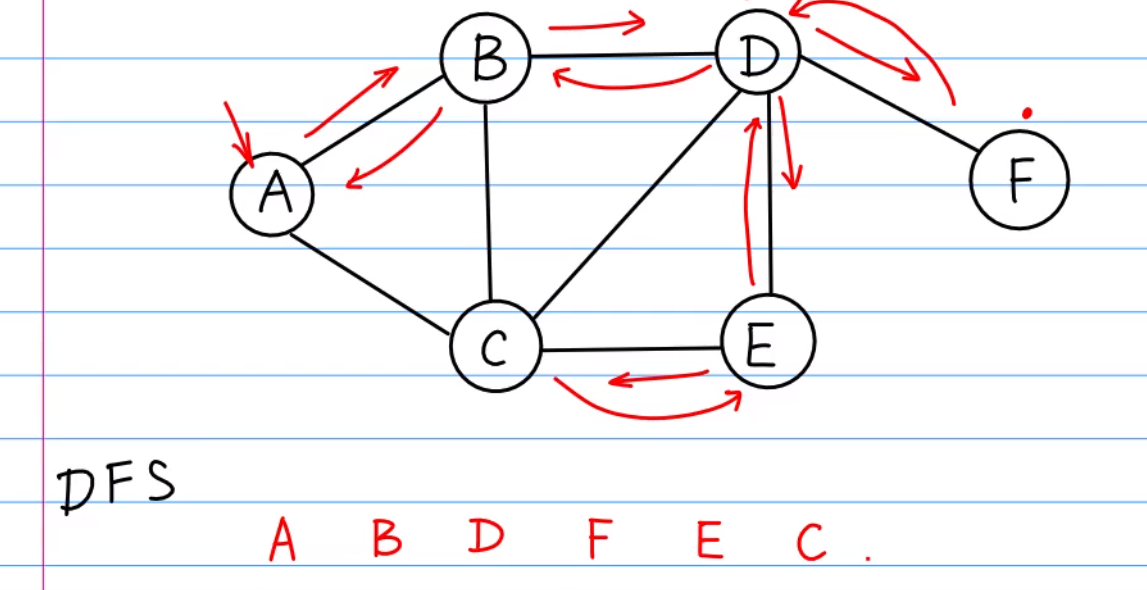
DFS(深度优先搜索)
一条路走到底,从头到尾的探索,结果也是不唯一的