线性回归的从零开始实现
线性回归的从零开始实现
%matplotlib inline
import random
import torch
from d2l import torch as d2ldef synthetic_data(w,b,num_example):"""生成y=Xw+b+噪声"""X=torch.normal(0,1,(num_example,len(w)))y=torch.matmul(X,w)+by+=torch.normal(0,0.01,y.shape)return X,y.reshape((-1,1))
true_w=torch.tensor([2,-3.4])
true_b=4.2
features,labels=synthetic_data(true_w,true_b,1000)
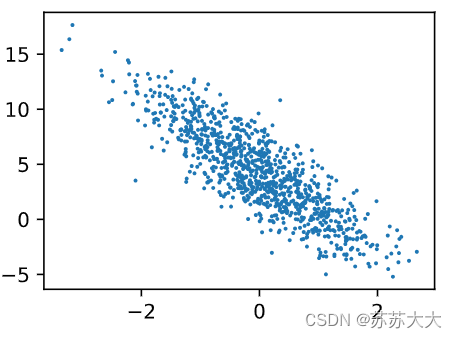
print('features的第0行:',features[0],'\nlabel的第0行:',labels[0])d2l.set_figsize()
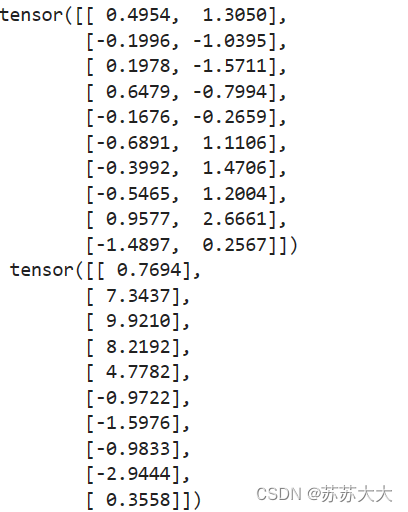
d2l.plt.scatter(features[:,1].detach().numpy(),labels.detach().numpy(),1);def data_iter(batch_size,features,labels):num_examples=len(features)indices=list(range(num_examples))random.shuffle(indices)for i in range(0,num_examples,batch_size):#每次跳batch_size大小batch_indices=torch.tensor(indices[i:min(i+batch_size,num_examples)])yield features[batch_indices],labels[batch_indices]batch_size=10for X,y in data_iter(batch_size,features,labels):print(X,'\n',y)break
#定义初始化模型参数
w=torch.normal(0,0.01,size=(2,1),requires_grad=True)
b=torch.zeros(1,requires_grad=True)
#定义模型def linreg(X,w,b):"""线性回归模型"""return torch.matmul(X,w)+b
def squared_loss(y_hat,y):"""均方损失"""return (y_hat-y.reshape(y_hat.shape))**2/2
#定义优化算法
def sgd(params,lr,batch_size):"""小批量随机梯度下降"""with torch.no_grad():for param in params:param-=lr*param.grad/batch_sizeparam.grad.zero_()
#训练
lr=0.01
num_epochs=3
net=linreg
loss=squared_lossfor epoch in range(num_epochs):for X,y in data_iter(batch_size,features,labels):l=loss(net(X,w,b),y)l.sum().backward()sgd([w,b],lr,batch_size)with torch.no_grad():train_l=loss(net(features,w,b),labels)print(f'epoch{epoch + 1},loss{float(train_l.mean()):f}')
print(f'w的估计误差:{true_w-w.reshape(true_w.shape)}')
print(f'b的估计误差:{true_b-b}')结果:
features的第0行: tensor([0.8573, 0.8461])
label的第0行: tensor([3.0247])
epoch1,loss2.173185
epoch2,loss0.282209
epoch3,loss0.036828
w的估计误差:tensor([8.6069e-05, 1.7047e-04], grad_fn=<SubBackward0>)
b的估计误差:tensor([0.0003], grad_fn=<RsubBackward1>)